AiTrust下预训练和小样本学习在中文医疗信息处理挑战榜CBLUE表现
项目链接:
https://aistudio.baidu.com/aistudio/projectdetail/4592515?contributionType=1
如果有图片缺失参考项目链接
0.项目背景
CBLUE又是一个CLUE榜单,大家都知道近年来NLP领域随着预训练语言模型(下面简称PTLM)的兴起又迎来了一波迅猛发展,得益于PTLM技术的推动,催生出一批多任务的benchmark榜单,代表性的工作是GLUE,在中文领域也有CLUE。CBLUE的全名是Chinese Biomedical Language Understanding Evaluation,是目前国内首个医疗AI方向的多任务榜单,相信这个榜单的推出会促进医疗语言模型的发展和医疗NLP领域的发展。榜单的官网介绍如下:
中文医疗信息处理评测基准CBLUE(Chinese Biomedical Language Understanding Evaluation)是中国中文信息学会医疗健康与生物信息处理专业委员会在合法开放共享的理念下发起,由阿里云天池平台承办,并由医渡云(北京)技术有限公司、平安医疗科技、阿里夸克、腾讯天衍实验室、北京大学、鹏城实验室、哈尔滨工业大学(深圳)、郑州大学、同济大学、中山大学、复旦大学等开展智慧医疗研究的单位共同协办,旨在推动中文医学NLP技术和社区的发展。 榜单在设计上综合考虑了任务类型和任务难度两个维度,目标是建设一个任务类型覆盖广、同时也要保证任务的难度的benchmark,因此榜单在吸收往届CHIP/CCKS/CCL等学术评测任务的同时也适当增加了业界数据集,业务数据集的特点是数据真实且有噪音,对模型的鲁棒性提出了更高的要求。CBLUE评测基准2.0包括医学文本信息抽取(实体识别、关系抽取、事件抽取)、医学术语归一化、医学文本分类、医学句子关系判定和医疗对话理解与生成共5大类任务14个子任务。
blog.csdnimg.cn/ef2cb516bcfa481ab30b0f345c4bf11a.png)
中文领域也有CLUE:
https://www.cluebenchmarks.com/index.html
英文
https://gluebenchmark.com/
官网介绍榜单一共包含了4大类8细类任务,下面分别介绍:
- 医学信息抽取:
主要包含了实体识别NER任务和关系抽取RE两个数据集:
CMeEE(Chinese Medical Entity Extraction):是由“北京大学”、“郑州大学”、“鹏城实验室”和“哈尔滨工业大学(深圳)”联合提供。共包括9大类实体:疾病(dis),临床表现(sym),药物(dru),医疗设备(equ),医疗程序(pro),身体(bod),医学检验项目(ite),微生物类(mic)和科室(dep),其中“临床表现”实体类别中允许嵌套,该实体内部允许存在其他八类实体。嵌套实体一向是NER任务中一个难点。
CMeIE(Chinese Medical Information Extraction):和CMeEE任务一样,也是由“北京大学”、“郑州大学”、“鹏城实验室”和“哈尔滨工业大学(深圳)”联合提供的。共包括53类关系类型(具体类型参见官网介绍),这个任务需要打榜选手完成端对端的模型预测,即输入是原始的句子,选手需要完成实体识别和关系抽取两个任务。从关系种类的数量53类来看,且标注规范中有提及到关系可能是跨句子分布的(“Combined”字段为false),这是一个比较难的任务。
- 医学术语归一化:
这个任务按照我的理解是应该归属到信息抽取这个大类的,都属于知识图谱构造的关键技术,不知道官方为什么单独划分为一类,可能是有其他考虑。包括了一个数据集:
CHIP-CDN(CHIP - Clinical Diagnosis Normalization dataset):CHIP这个名字一开始比较困惑,Google上查找了半天也没有找到是什么,后来仔细看官方文档才发现CHIP就是这个榜单的发起单位组织的专业会议(历史经验告诉我们任何时候都要认真读文档),CHIP表示中国健康信息处理会议,全称是China Health Information Processing Conference,是中国中文信息学会医疗健康与生物信息处理专业委员会主办的关于医疗、健康和生物信息处理和数据挖掘等技术的年度会议,是中国健康信息处理领域最重要的学术会议之一,这个会议已经连续举办了六届,最近几届都发布了医疗方向的学术评测任务,这个榜单很多以CHIP开头的数据集就是来源于大会上发布的评测任务。言归正传,CHIP-CDN数据集是由北京医渡云公司提供的,这是一个标准的实体标准化/归一化任务,将给定的医学症状实体映射到医学标准字典(ICD-10)上。这是一个很有实际意义的任务,医生在书写病历的时候,同一个术语往往有多种不同的写法,甚至一个症状可能是多个标准症状的叠加(如官网中的例子:“右肺结节转移可能大” -> “肺占位性病变##肺继发恶性肿瘤##转移性肿瘤”),非常的复杂。这类任务一般不能只靠模型来解决,需要结合具体的行业知识来做判定。
- 医学文本分类:
包括两个任务:
CHIP-CTC(CHiP - Clinical Trial Criterion dataset):是由同济大学生命科学与技术学院提供,主要针对临床试验筛选标准进行分类,所有文本数据均来自于真实临床试验,也是一个有真实意义的任务。 从技术上看,这是一个典型的短文本多分类问题,共有44个类别(具体类别请参照官网),分类任务研究相对较多,一般需要注意的是类别比例的分布。
KUAKE-QIC(KUAKE-Query Intention Classification dataset),是由夸克浏览器提供。这也是一个文本分类问题,共有11种分类(具体分类请查看官网),和CHIP-CTC数据集的区别是这个任务的输入均来自于真实的用户query,数据存在大量的噪音。
- 医学句子关系判定/医学QA:
包括3个数据集:
CHIP-STS(CHIP - Semantic Textual Similarity dataset):是由平安医疗科技公司提供。是一个典型的语义相似度判断问题,数据集共包含5大类疾病,输出结果是0/1两类标签。这个任务应该不算太难,其中疾病的类别信息也是一个输入,模型在设计的时候要把这个feature考虑进去。
KUAKE-QTR(KUAKE-Query Title Relevance dataset):也是由夸克公司提供,搞搜索推荐算法的小伙伴们一看就知道是一个QT match的问题,相比CHIP-STS,这个数据集是一个4分类问题(共0~3分 4档)。官网给的例子还是挺有难度区分的,感觉模型不太容易跑出高性能。
KUAKE-QQR(KUAKE-Query Query Relevance dataset):也是由夸克公司提供。和KUAKE-QTR类似,是一个典型的Query-Query match问题,是一个3分类问题(共0~2分 3档)。难点同QTR。
1.数据集加载&安装环境
KUAKE-QIC(KUAKE-Query Intention Classification dataset),是由夸克浏览器提供。这也是一个文本分类问题,共有11种分类(具体分类请查看官网),和CHIP-CTC数据集的区别是这个任务的输入均来自于真实的用户query,数据存在大量的噪音。
!wget https://paddlenlp.bj.bcebos.com/datasets/KUAKE_QIC.tar.gz
!tar -zxvf KUAKE_QIC.tar.gz
!mv KUAKE_QIC data
!rm KUAKE_QIC.tar.gz
!pip install --upgrade paddlenlp
!pip install scikit-learn
数据集展示
心肌缺血如何治疗与调养呢? 治疗方案
19号来的月经,25号服用了紧急避孕药本月5号,怎么办? 治疗方案
什么叫痔核脱出?什么叫外痔? 疾病表述
您好,请问一岁三个月的孩子可以服用复方锌布颗粒吗? 其他
多发乳腺结节中药能治愈吗 疾病表述
有了中风怎么样治最好 治疗方案
输卵管粘连的基本检查 其他
尖锐湿疣吃什么中草药好 治疗方案
细胞病理学诊断非典型鳞状细胞,意义不明确。什么意思 指标解读
性生活后白带有酸味是怎么回事? 病情诊断
会是胎动么? 其他
经常干呕恶心,这是生病了吗 其他
标签合集:
病情诊断
治疗方案
病因分析
指标解读
就医建议
疾病表述
后果表述
注意事项
功效作用
医疗费用
其他
2 预训练模型微调
2.1 知识点:学习率warm-up
由于神经网络在刚开始训练的时候是非常不稳定的,因此刚开始的学习率应当设置得很低很低,这样可以保证网络能够具有良好的收敛性。但是较低的学习率会使得训练过程变得非常缓慢,因此这里会采用以较低学习率逐渐增大至较高学习率的方式实现网络训练的“热身”阶段,称为 warmup stage。但是如果我们使得网络训练的 loss 最小,那么一直使用较高学习率是不合适的,因为它会使得权重的梯度一直来回震荡,很难使训练的损失值达到全局最低谷。
在实际中,由于训练刚开始时,训练数据计算出的梯度 grad 可能与期望方向相反,所以此时采用较小的学习率 learning rate,随着迭代次数增加,学习率 lr 线性增大,增长率为 1/warmup_steps;迭代次数等于 warmup_steps 时,学习率为初始设定的学习率;
另一种原因是由于刚开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择Warmup预热学习率的方式,可以使得开始训练的几个epoches内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
迭代次数超过warmup_steps时,学习率逐步衰减,衰减率为1/(total-warmup_steps),再进行微调。
常见的warmup方式有三种:constant,linear和exponent。
- constant:在warmup期间,学习率 。ResNet论文中就使用了这种方式,在cifar10上训练ResNet 101时,先用0.01的学习率训练直到训练误差低于80%(大概训练了400个steps),然后使用0.1的学习率进行训练。
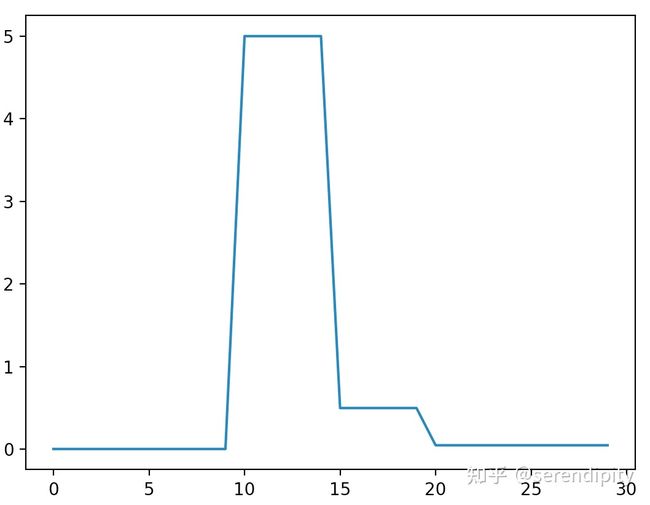
- linear:constant的不足之处在于从一个很小的学习率一下变为比较大的学习率可能会导致训练误差突然增大。linear方式可以避免这种问题,在warmup期间,学习率从 线性增长到 。
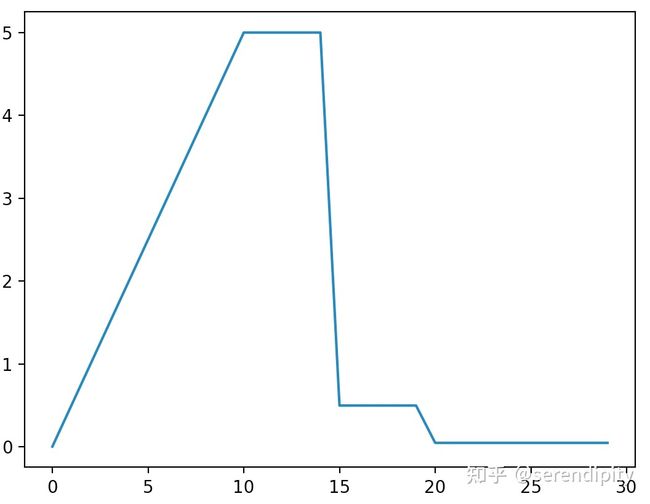
- exponent:在warmup期间,学习率从 指数增长到 。
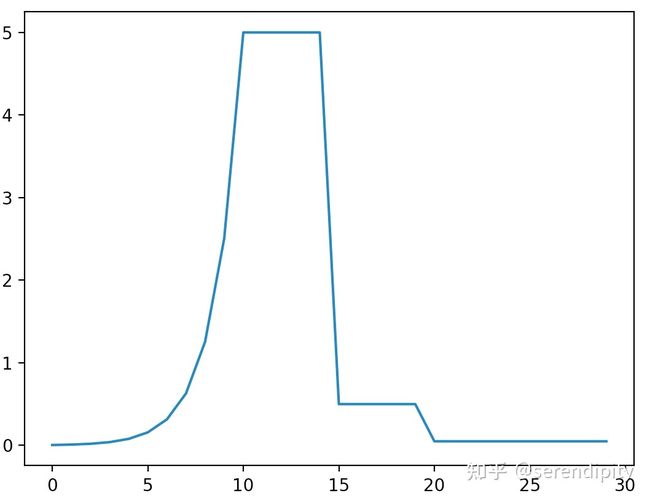
参考链接:https://zhuanlan.zhihu.com/p/508953700
warmup 方法的优势:
有助于减缓模型在初始阶段对mini-batch的提前过拟合现象,保持分布的平稳
有助于保持模型深层的稳定性
paddlenlp参考文档:
https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/optimizer/lr/LinearWarmup_cn.html#linearwarmup

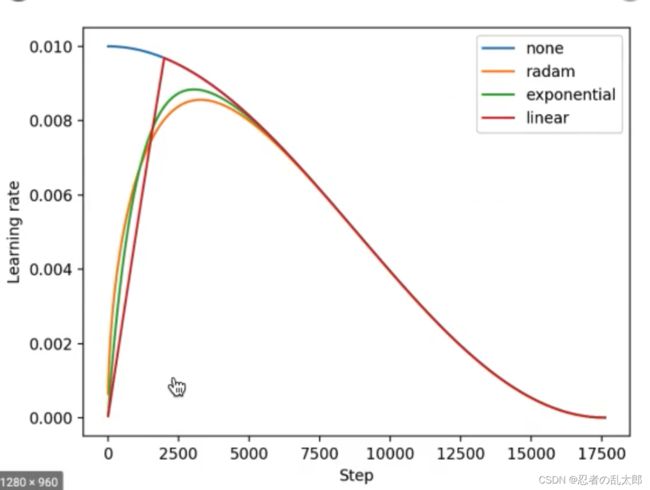
2.2 模型训练和预测
!python train.py \
--dataset_dir "data/KUAKE_QIC" \
--device "gpu" \
--save_dir "./checkpoint" \
--max_seq_length 256 \
--model_name "ernie-3.0-xbase-zh" \
--batch_size 32 \
--learning_rate 3e-5 \
--early_stop \
--early_stop_nums 5 \
--epochs 20 \
--warmup \
--warmup_steps 1000 \
--weight_decay 0.01 \
--logging_steps 50 \
--valid_steps 100
save_dir:保存训练模型的目录;默认保存在当前目录checkpoint文件夹下。
- train_file:本地数据集中训练集文件名;默认为"train.txt"。
- dev_file:本地数据集中开发集文件名;默认为"dev.txt"。
- label_file:本地数据集中标签集文件名;默认为"label.txt"。
device: 选用什么设备进行训练,选择cpu、gpu、xpu、npu。如使用gpu训练,可使用参数–gpus指定GPU卡号;默认为"gpu"。
dataset_dir::本地数据集路径,数据集路径中应包含train.txt,dev.txt和label.txt文件;默认为None。
dataset_dir:本地数据集路径,数据集路径中应包含train.txt,dev.txt和label.txt文件;默认为None。
max_seq_length:分词器tokenizer使用的最大序列长度,ERNIE模型最大不能超过2048。请根据文本长度选择,通常推荐128、256或512,若出现显存不足,请适当调低这一参数;默认为128。
model_name:选择预训练模型,可选"ernie-1.0-large-zh-cw",“ernie-3.0-xbase-zh”, “ernie-3.0-base-zh”, “ernie-3.0-medium-zh”, “ernie-3.0-micro-zh”, “ernie-3.0-mini-zh”, “ernie-3.0-nano-zh”, “ernie-2.0-base-en”, “ernie-2.0-large-en”,“ernie-m-base”,“ernie-m-large”;默认为"ernie-3.0-medium-zh"。
batch_size:批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为32。
learning_rate:Fine-tune的最大学习率;默认为3e-5。
weight_decay:控制正则项力度的参数,用于防止过拟合,默认为0.0。可以设置小点 如0.01等
** epochs:** 训练轮次,使用早停法时可以选择100;默认为10。
early_stop:选择是否使用早停法(EarlyStopping);模型在开发集经过一定epoch后精度表现不再上升,训练终止;默认为False。
early_stop_nums:在设定的早停训练轮次内,模型在开发集上表现不再上升,训练终止;默认为4。
warmup:是否使用学习率warmup策略,使用时应设置适当的训练轮次(epochs);默认为False。
warmup_proportion:学习率warmup策略的比例数,如果设为0.1,则学习率会在前10%steps数从0慢慢增长到learning_rate, 而后再缓慢衰减;默认为0.1。
**warmup_steps:**学习率warmup策略的比例数,如果设为1000,则学习率会在1000steps数从0慢慢增长到learning_rate, 而后再缓慢衰减;默认为0。
logging_steps: 日志打印的间隔steps数,默认5。
init_from_ckpt: 模型初始checkpoint参数地址,默认None。
seed:随机种子,默认为3。
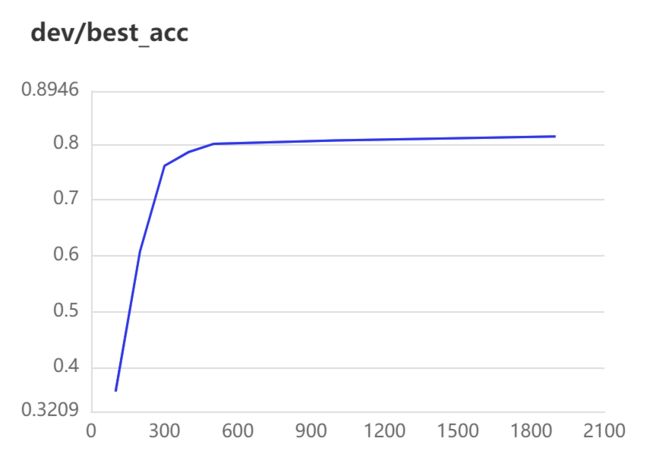
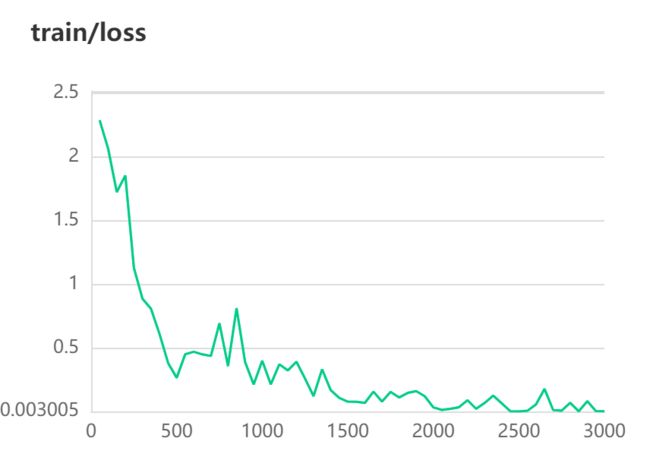
训练结果:
[2022-09-24 23:46:42,282] [ INFO] - global step 2900, epoch: 14, batch: 79, loss: 0.08345, speed: 4.60 step/s
[2022-09-24 23:46:47,353] [ INFO] - eval loss: 1.06234, acc: 0.80102
[2022-09-24 23:46:47,355] [ INFO] - Current best accuracy: 0.81330
[2022-09-24 23:46:58,502] [ INFO] - global step 2950, epoch: 14, batch: 129, loss: 0.00550, speed: 3.09 step/s
[2022-09-24 23:47:10,650] [ INFO] - global step 3000, epoch: 14, batch: 179, loss: 0.00378, speed: 4.12 step/s
[2022-09-24 23:47:15,735] [ INFO] - eval loss: 1.13159, acc: 0.80767
[2022-09-24 23:47:15,737] [ INFO] - Current best accuracy: 0.81330
[2022-09-24 23:47:23,969] [ INFO] - Early stop!
[2022-09-24 23:47:23,969] [ INFO] - Final best accuracy: 0.81330

!python predict.py \
--device "gpu" \
--max_seq_length 128 \
--batch_size 32 \
--dataset_dir "data/KUAKE_QIC" \
--params_path "./checkpoint/" \
--output_file "output.txt"
预测结果
text label
黑苦荞茶的功效与作用及食用方法 功效作用
交界痣会凸起吗 疾病表述
检查是否能怀孕挂什么科 就医建议
鱼油怎么吃咬破吃还是直接咽下去 其他
幼儿挑食的生理原因是 病因分析
3.小样本学习
提示学习(Prompt Learning)适用于标注成本高、标注样本较少的文本分类场景。在小样本场景中,相比于预训练模型微调学习,提示学习能取得更好的效果。
提示学习的主要思想是将文本分类任务转换为构造提示中掩码 [MASK] 的分类预测任务,也即在掩码 [MASK]向量后接入线性层分类器预测掩码位置可能的字或词。提示学习使用待预测字的预训练向量来初始化分类器参数(如果待预测的是词,则为词中所有字的预训练向量平均值),充分利用预训练语言模型学习到的特征和标签文本,从而降低样本需求。提示学习同时提供 R-Drop 和 RGL 策略,帮助提升模型效果。
.
├── train.py # 模型组网训练脚本
├── utils.py # 数据处理工具
├── infer.py # 模型部署脚本
└── README.md
## 3.1 知识点:Rdrop技术(Regularized Dropout)
对比学习 RDrop: Regularized Dropout for Neural Networks
每个数据样本重复经过带有Dropout的同一个模型,再使用KL散度约束两次的输出,使得尽可能一致,而由于 Dropout的随机性,可以近似把输入X走过两次的路径网络当作两个略有不同的模型,如下图所示:
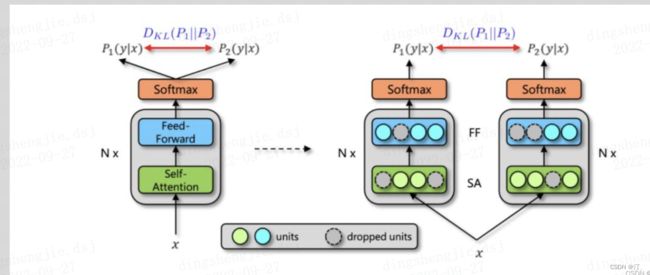
R-Dropout的原理
简单地说,就是模型中加入dropout,训练阶段的预测预测两次,要求两次的结果尽可能接近,这种接近体现在损失函数上。
那么,这个“接近”用的是什么呢?作者用的是KL散度。数学上的KL散度是用来对比两个分布是否相同,其连续型和离散型的公式分别是:
OK,有这个基础,来继续看R-Dropout就更清晰了,我们要让两次预测结果的KL散度尽可能小,那么这部分的损失函数就可以构造出来了:
KL散度本身是不具有自反性的,所以要用第一次预测对第二次的KL散度和第二次预测对第一次预测的KL散度的均值来进行计算。
这部分损失可以加入到整体损失里面作为最终优化的一部分,例如是log loss(当然,其他任务可以用其他的损失):
为什么R-Dropout会有用
其实dropout的本质就是给模型加一些扰动,而R-dropout就是要扰动,更要保证这种扰动对结果尽可能小,毕竟这里还优化了两次预测的KL散度,所以其实这种训练就让模型的稳定性大幅提升。最近是遇到一些问题,一句话改一两个字意思还一样但是结果差距很大,这个r-dropout应该可以缓解这个问题,甚至说解决。
但是注意,这里是稳定性提升,我的感觉是并没有拉高模型本身的上限,甚至可能拉低上限。我们知道模型是存在不稳定性的,同一套数据的不同顺序,参数的不同初始化,不同的dropout都会导致模型效果存在波动,而且这个波动还不小,R-dropout本质上即使控制这种波动对结果的影响,从而保证了稳定性。而有关拉低上限,我的解释是最终的参数估计预测,相比不带有新的loss子项,这应该是一个有偏估计,还是可能一定程度拉低上限的。
为什么用KL散度
KL散度本质上是一个对比分布的函数,这与R-Dropout的初衷一致的,要求两次预测尽可能相同,这里是指完全相同,例如多分类下要求的是所有预测的对应概率也是一致的,相比于交叉熵的只针对最优值的prob,这个对比会更加全面和完整。
知识点参考链接:
https://blog.csdn.net/Jiana_Feng/article/details/123573686
https://blog.csdn.net/baidu_25854831/article/details/120136660?spm=1001.2101.3001.6650.4&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-4-120136660-blog-123573686.t0_edu_mlt&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-4-120136660-blog-123573686.t0_edu_mlt&utm_relevant_index=5
https://zhuanlan.zhihu.com/p/391881979
3.2 模型训练与预测
!python few-shot/train.py \
--device gpu \
--data_dir ./data/KUAKE_QIC \
--output_dir ./checkpoints_shot/ \
--prompt "这个分类是" \
--max_seq_length 128 \
--learning_rate 3e-5 \
--ppt_learning_rate 3e-4 \
--do_train \
--do_eval \
--use_rdrop \
--num_train_epochs 20 \
--eval_steps 200 \
--logging_steps 50 \
--per_device_eval_batch_size 32 \
--per_device_train_batch_size 32 \
--load_best_model_at_end \
--weight_decay 0.01 \
--save_steps 600 \
--warmup_ratio 0.15
# --warmup_steps 1000 \
#warm_up_ratio = 0.1 # 定义要预热的step
#num_warmup_steps = warm_up_ratio * total_steps, num_training_steps = total_steps
# --max_steps 5000 \ 可以选择epochs or steps
# --do_predict \
# --do_export
# --save_steps 500 #默认500
#--warmup_ratio
#--warmup_steps
#--weight_decay
model_name_or_path: 内置模型名,或者模型参数配置目录路径。默认为ernie-3.0-base-zh。
data_dir: 训练数据集路径,数据格式要求详见数据准备。
output_dir: 模型参数、训练日志和静态图导出的保存目录。
prompt: 提示模板。定义了如何将文本和提示拼接结合。
soft_encoder: 提示向量的编码器,lstm表示双向LSTM, mlp表示双层线性层, None表示直接使用提示向量。默认为lstm。
use_rdrop: 使用 R-Drop 策略。
use_rgl: 使用 RGL 策略。
encoder_hidden_size: 提示向量的维度。若为None,则使用预训练模型字向量维度。默认为200。
max_seq_length: 最大句子长度,超过该长度的文本将被截断,不足的以Pad补全。提示文本不会被截断。
learning_rate: 预训练语言模型参数基础学习率大小,将与learning rate scheduler产生的值相乘作为当前学习率。
ppt_learning_rate: 提示相关参数的基础学习率大小,当预训练参数不固定时,与其共用learning rate scheduler。一般设为learning_rate的十倍。
do_train: 是否进行训练。
do_eval: 是否进行评估。
do_predict: 是否进行预测。
do_export: 是否在运行结束时将模型导出为静态图,保存路径为output_dir/export。
max_steps: 训练的最大步数。此设置将会覆盖num_train_epochs。
eval_steps: 评估模型的间隔步数。
device: 使用的设备,默认为gpu。
logging_steps: 打印日志的间隔步数。
per_device_train_batch_size: 每次训练每张卡上的样本数量。可根据实际GPU显存适当调小/调大此配置。
per_device_eval_batch_size: 每次评估每张卡上的样本数量。可根据实际GPU显存适当调小/调大此配置。
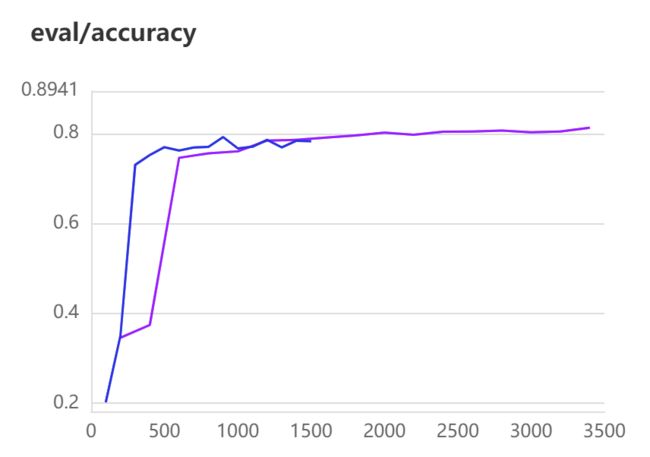
部分训练结果展示:
跑了两次:最优acc为0.81279-3400steps

4. 模型优化:TrustAI、数据增强
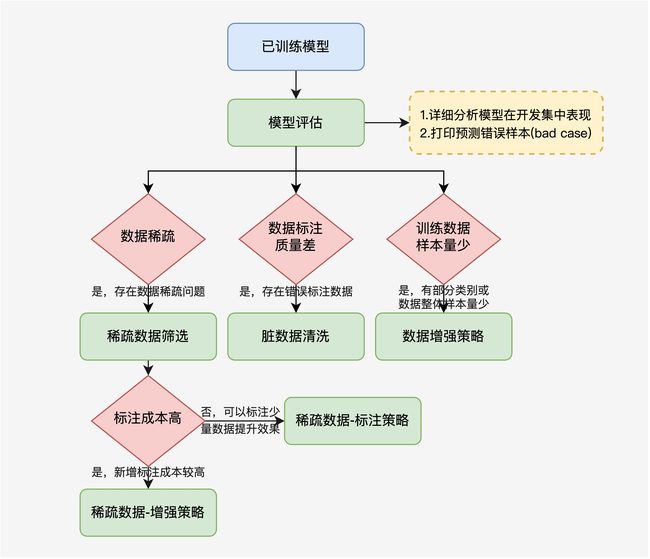
训练后的模型我们可以使用 模型分析模块 对每个类别分别进行评估,并输出预测错误样本(bad case),默认在GPU环境下使用,在CPU环境下修改参数配置为–device “cpu”:
模型表现常常受限于数据质量,在analysis模块中基于TrustAI的稀疏数据筛选、脏数据清洗、数据增强三种优化方案助力开发者提升模型效果,更多模型评估和优化方案细节详见训练评估与模型优化指南。
analysis/
├── evaluate.py # 评估脚本
├── sparse.py # 稀疏数据筛选脚本
├── dirty.py # 脏数据清洗脚本
├── aug.py # 数据增强脚本
└── README.md # 多分类训练评估与模型优化指南
参考链接:
多分类训练评估与模型优化指南:
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/applications/text_classification/multi_class/analysis/README.md
Data Augmentation API:
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/dataaug.md
TrustAI:
https://github.com/PaddlePaddle/TrustAI
4.1 模型评估
使用训练好的模型计算模型的在开发集的准确率,同时打印每个类别数据量及表现:
!python analysis/evaluate.py \
--device "gpu" \
--max_seq_length 128 \
--batch_size 32 \
--bad_case_path "./bad_case.txt" \
--dataset_dir "data/KUAKE_QIC" \
--params_path "./checkpoint"
验证结果部分展示:
[2022-09-24 23:54:13,923] [ INFO] - -----Evaluate model-------
[2022-09-24 23:54:13,923] [ INFO] - Train dataset size: 6931
[2022-09-24 23:54:13,923] [ INFO] - Dev dataset size: 1955
[2022-09-24 23:54:13,923] [ INFO] - Accuracy in dev dataset: 81.38%
[2022-09-24 23:54:13,924] [ INFO] - Top-2 accuracy in dev dataset: 92.02%
[2022-09-24 23:54:13,925] [ INFO] - Top-3 accuracy in dev dataset: 97.19%
[2022-09-24 23:54:13,925] [ INFO] - Class name: 病情诊断
[2022-09-24 23:54:13,925] [ INFO] - Evaluation examples in train dataset: 877(12.7%) | precision: 97.65 | recall: 99.43 | F1 score 98.53
[2022-09-24 23:54:13,925] [ INFO] - Evaluation examples in dev dataset: 288(14.7%) | precision: 82.26 | recall: 88.54 | F1 score 85.28
[2022-09-24 23:54:13,925] [ INFO] - ----------------------------
[2022-09-24 23:54:13,925] [ INFO] - Class name: 治疗方案
[2022-09-24 23:54:13,926] [ INFO] - Evaluation examples in train dataset: 1750(25.2%) | precision: 98.48 | recall: 99.77 | F1 score 99.12
[2022-09-24 23:54:13,926] [ INFO] - Evaluation examples in dev dataset: 676(34.6%) | precision: 88.86 | recall: 93.20 | F1 score 90.97
[2022-09-24 23:54:13,926] [ INFO] - ----------------------------
…
可以看出不同类别识别难度不一:
预测错误的样本保存在bad_case.txt文件中:
0.98 病情诊断 其他 最近好像有感冒,身上感觉不定位不定时的痛特别的左边背上还长了一个大包,右眼酸胀。我这样严重吗
0.98 注意事项 其他 月经来后能否继续用月经前用的药
0.97 治疗方案 其他 外阴骚痒,每次跟老公做完事后就有点痒,后来老公说是以前大腿内侧得过皮炎,请问是不是这个造成的,该如何..
0.99 后果表述 其他 雌二醇在排卵期会怎样?
1.00 病情诊断 其他 白带变黄异味重,怎么会事
0.76 病情诊断 指标解读 孕酮低是不是更年期到了要绝经了
0.98 疾病表述 其他 喉癌的高发人群与先兆
0.99 疾病表述 注意事项 忧郁症的表现及注意点
0.79 功效作用 其他 医师您好:VE是什么,VE真的可以除去黑...
0.53 注意事项 治疗方案 如何预防春天感冒
0.92 病情诊断 其他 四个月大的宝宝喜欢反手抓人正常吗?
可以看到有364条预测错误,占比不少有待改进
4.2 TrustAI:稀疏数据筛选方案
总结为样本多样性丰富度不够!
稀疏数据:指缺乏足够训练数据支持导致低置信度的待预测数据,简单来说,由于模型在训练过程中没有学习到足够与待预测样本相似的数据,模型难以正确预测样本所属类别。
本项目中稀疏数据筛选基于TrustAI(可信AI)工具集,利用基于特征相似度的实例级证据分析方法,抽取开发集中样本的支持训练证据,并计算支持证据平均分(通常为得分前三的支持训练证据均分)。分数较低的样本表明其训练证据不足,在训练集中较为稀疏,实验表明模型在这些样本上表现也相对较差。
稀疏数据筛选旨在开发集中挖掘缺乏训练证据支持的稀疏数据,通常可以采用数据增强或少量数据标注的两种低成本方式,提升模型预测效果。
实例级证据分析:
https://github.com/PaddlePaddle/TrustAI/blob/main/trustai/interpretation/example_level/README.md
实例级证据分析旨在从训练数据中找出对当前预测起重要作用的若干条实例数据。开发者基于实例级证据可对训练数据中的问题进行分析,如识别训练集中的脏数据、识别数据稀疏等。
本工具包含多种实例级证据分析方法,如表示点方法、基于梯度的相似度方法、基于特征的相似度方法等。
- 表示点方法
- 基于梯度的相似度方法
- 基于特征的相似度方法
表示点方法 【脏数据清洗】
表示点方法(Representer Point)将训练数据对当前预测数据的重要度影响(即表征值),分解为训练数据对模型的影响和训练数据与预测数据的语义相关度。对于一条给定的测试数据和测试结果,表征值为正的训练数据表示支持该预测结果,相反,表征值为负的训练数据表示不支持该预测结果。同时,表征值的大小表示了训练数据对测试数据的影响程度。
在真实情况下,众包标注的语料通常掺杂噪音(标注错误),易干扰模型预测。表示点方法倾向于召回梯度较大的训练数据,因此开发者不仅可以使用实例级证据分析方法了解模型行为,也可以通过人工检测标注数据错误,提升模型效果。
基于梯度的相似度方法
基于梯度的相似度方法(Grad-Cosin, Grad-Dot)通过模型的梯度挑选对当前测试数据产生正影响和负影响的数据。
基于梯度的相似度方法召回了在梯度意义上对测试数据有正影响和负影响的实例数据。召回的正影响数据往往是与测试数据语义上比较相似且标签一致的数据,负影响数据通常可能是标注错误的、类别模糊的甚至是存在冲突的数据。
基于特征的相似度方法 【稀疏数据识别】
基于特征的相似度方法(Feature-Cosin, Feature-Dot, Feature-Euc)通过模型的特征挑选对当前测试数据有正影响和负影响的数据。
基于特征的相似度方法召回了在特征意义上对测试数据有正影响和负影响的实例数据。召回的正影响数据与GC方法相似,负影响数据更倾向于召回和测试数据字面不相似的数据。
详细demo见参考文档
4.2.1稀疏数据识别–数据增强
这里我们将介绍稀疏数据识别–数据增强流程,
-
首先使用数据增强脚本挖掘开发集中的稀疏数据
-
然后筛选训练集中对稀疏数据的支持数据进行数据增强,
-
最后将得到的数据增强后的支持数据加入到训练集中进行训练。
现在我们进行稀疏数据识别–数据增强,得到新增训练数据:
4.2.2稀疏数据识别–数据标注
这里我们将介绍稀疏数据识别–数据标注流程,
- 首先使用数据增强脚本挖掘开发集中的稀疏数据,
- 然后筛选对稀疏数据支持的未标注数据,
- 最后将得到支持数据进行标注后加入到训练集中进行训练。
现在我们进行稀疏数据识别–数据标注,得到待标注数据:
annotate:选择稀疏数据识别–数据标注模式;默认为False。
unlabeled_file: 本地数据集中未标注数据文件名;默认为"data.txt"。
[2022-09-25 20:52:35,898] [ INFO] - Sparse data saved in ./data/KUAKE_QIC/sparse.txt
[2022-09-25 20:52:35,898] [ INFO] - Accuracy in sparse data: 41.00%
[2022-09-25 20:52:35,898] [ INFO] - Average score in sparse data: 0.7830
[2022-09-25 20:52:35,902] [ INFO] - We are using to load './checkpoint/'.
[2022-09-25 20:52:40,282] [ INFO] - We are using to load './checkpoint/'.
Extracting feature from given dataloader, it will take some time...
[2022-09-25 20:52:40,878] [ ERROR] - The index is out of range, please reduce support_num or increase support_threshold. Got 1 now.
[2022-09-25 20:52:40,879] [ INFO] - support data saved in ./data/KUAKE_QIC/support.txt
[2022-09-25 20:52:40,879] [ INFO] - support average scores: 0.7153
简单来讲就是标注一些困哪样本
4.3 脏数据清洗方案
训练数据标注质量对模型效果有较大影响,但受限于标注人员水平、标注任务难易程度等影响,训练数据中都存在一定比例的标注较差的数据(脏数据)。当标注数据规模较大时,数据标注检查就成为一个难题。
本项目中脏数据清洗基于TrustAI(可信AI)工具集,利用基于表示点方法的实例级证据分析方法,计算训练数据对模型的影响分数,分数高的训练数据表明对模型影响大,这些数据有较大概率为脏数据(标注错误样本)。
现在我们进行脏数据识别,脏数据保存在"train_dirty.txt",剩余训练数据保存在"train_dirty_rest.txt":
4.4 数据增强策略方案
在数据量较少或某些类别样本量较少时,也可以通过数据增强策略的方式,生成更多的训练数据,提升模型效果。
Data Augmentation API:https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/dataaug.md
词级别数据增强策略
- 词替换
- 词插入
- 词删除
- 词交换
采取替换就好:
同义词替换、同音词替换、本地词表替换、随机词替换
上下文替换:上下文替换是随机将句子中单词进行掩码,利用中文预训练模型ERNIE 1.0,根据句子中的上下文预测被掩码的单词。相比于根据词表进行词替换,上下文替换预测出的单词更匹配句子内容,数据增强所需的时间也更长。
基于TF-IDF的词替换:TF-IDF算法认为如果一个词在同一个句子中出现的次数多,词对句子的重要性就会增加;如果它在语料库中出现频率越高,它的重要性将被降低。我们将计算每个词的TF-IDF分数,低的TF-IDF得分将有很高的概率被替换。
train_path:待增强训练数据集文件路径;默认为"…/data/train.txt"。
aug_path:增强生成的训练数据集文件路径;默认为"…/data/train_aug.txt"
。
aug_strategy:数据增强策略,可选"mix", “substitute”, “insert”, “delete”, “swap”,“mix"为多种数据策略混合使用;默认为"substitute”。
aug_type:词替换/词插入增强类型,可选"synonym", “homonym”, “mlm”,建议在GPU环境下使用mlm类型;默认为"synonym"。同义词、同音词、mlm:上下文替换
create_n:生成的句子数量,默认为2。
aug_percent:生成词替换百分比,默认为0.1。
device: 选用什么设备进行增强,选择cpu、gpu、xpu、npu,仅在使用mlm类型有影响;默认为"gpu"。
WordSubstitute 参数介绍:
aug_type(str or list(str)):
词替换增强策略类别。可以选择"synonym"、"homonym"、"custom"、"random"、"mlm"或者
前三种词替换增强策略组合。
custom_file_path (str,*可选*):
本地数据增强词表路径。如果词替换增强策略选择"custom",本地数据增强词表路径不能为None。默认为None。
create_n(int):
数据增强句子数量。默认为1。
aug_n(int):
数据增强句子中被替换词数量。默认为None
aug_percent(int):
数据增强句子中被替换词数量占全句词比例。如果aug_n不为None,则被替换词数量为aug_n。默认为0.02。
aug_min (int):
数据增强句子中被替换词数量最小值。默认为1。
aug_max (int):
数据增强句子中被替换词数量最大值。默认为10。
tf_idf (bool):
使用TF-IDF分数确定哪些词进行增强。默认为False。
tf_idf_file (str,*可选*):
用于计算TF-IDF分数的文件。如果tf_idf为True,本地数据增强词表路径不能为None。默认为None。
4.5数据增强后进行预训练+小样本训练
把final_data放回到data进行训练
5.总结
本项目主要讲解了再主流中文医疗信息处理评测基准CBLUE榜单的一个多分类任务,并对warmup、Rdrop等技术进行简单介绍,使用预训练,小样本学习并通过AITrust可信分析提升模型性能,结果如下:
| 模型 | acc |
|---|---|
| 预训练 ernie3.0 | 0.81330 |
| 小样本 ernie3.0 | 0.81279 |
| 预训练 ernie3.0 +数据增强(aitrust) | 0.81688 |
| 小样本 ernie3.0+数据增强(aitrust) | 0.81764 |
可以看出在样本量还算大的情况下,预训练方式更有优势(准确率略高一点且训练更快一些),通过AITrust可信分析:稀疏数据筛选、脏数据清洗、数据增强等方案看到模型性能都有提升;
这里提升不显著的原因是,这边没有对筛选出来数据集进行标注:因为没有特定背景知识就不花时间操作了,会导致仍会有噪声存在。相信标注完后能提升3-5%点
-
对于大多数任务,我们使用预训练模型微调作为首选的文本分类方案:准确率较高,训练较快
-
提示学习(Prompt Learning)适用于标注成本高、标注样本较少的文本分类场景。在小样本场景中,相比于预训练模型微调学习,提示学习能取得更好的效果。对于标注样本充足、标注成本较低的场景,推荐使用充足的标注样本进行文本分类预训练模型微调
为了增加性能—可以做成持续学习: 参考如下图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GxqipqCM-1664249547079)(https://ai-studio-static-online.cdn.bcebos.com/fb138bc1013b489a96ec0ac8803d9085a1e565125492409cbc522168f3a68814)]
项目链接:
https://aistudio.baidu.com/aistudio/projectdetail/4592515?contributionType=1
如果有图片缺失参考项目链接
具体代码fork项目即可