深度学习基础之BatchNorm和LayerNorm
文章目录
- BatchNorm
- LayerNorm
- 总结
- 参考
BatchNorm
Batch Normalization(下文简称 Batch Norm)是 2015 年提出的方法。Batch Norm虽然是一个问世不久的新方法,但已经被很多研究人员和技术人员广泛使用。实际上,看一下机器学习竞赛的结果,就会发现很多通过使用这个方法而获得优异结果的例子。
Batch Norm有以下优点。
(1) 可以使学习快速进行(可以增大学习率)。
(2)不那么依赖初始值(对于初始值不用那么神经质)。
(3)抑制过拟合(降低Dropout等的必要性)
Batch Norm,顾名思义,以进行学习时的mini-batch为单位,按mini-batch进行正规化。具体而言,就是进行使数据分布的均值为0、方差为1的正规化。用数学式表示的话,如下所示。

看公式,是不是有点像经典机器学习里为了消除量纲的标准化的操作。

这就是Batch Normalization的算法了。
简单来说,其实就是对一个batch的数据进行标准化操作。
我们可以使用pytorch为我们写好的方法直接调用验证一下:
import torch.nn as nn
import torch as th
data = [[[1,2,5],[2,5,8.5],[3,3,3]],
[[2,8,4],[1,3,9],[2,6,4]],
[[1,1,1],[1,3,5],[0.5,6,0.2]]]
data = th.tensor(data)
data_bn = nn.BatchNorm1d(3)(data)
data_ln = nn.LayerNorm(3)(data)
mean = th.sum(data_bn)
mu = th.sum(th.pow(data_bn-mean, 2) / 27)
print(data_bn)
print(mean)
print(mu)

众所周知,浮点数运算会飘,所以2.3842e-07就相当于是0了
方差差计算出来是1
正好符合计算的结果。
所以batch norm是对一个batch的所有数据一起进行标准化操作。

这是使用手写数据集进行的测试实验,发现初始化参数不同时,对学习效果的影响是很大的,但是使用了batch norm之后,受到的影响就比较小了。
batch norm主要用于CV领域
LayerNorm
layer norm也是一种标准化的方法,公式也差不多,不过是对每个batch(3维)里的每个样本的每行进行标准化,主要是用于NLP领域的。
话不多说,上代码:
import torch.nn as nn
import torch as th
data = [[[1,2,5],[2,5,8.5],[3,3,3]],
[[2,8,4],[1,3,9],[2,6,4]],
[[1,1,1],[1,3,5],[0.5,6,0.2]]]
data = th.tensor(data)
data_ln = nn.LayerNorm(3)(data)
print(data_ln)
for b in data_ln:
for line in b:
mean = th.sum(line)
mu = th.sum(th.pow(line-mean, 2))
print(mean, mu / line.shape[0])
输出:
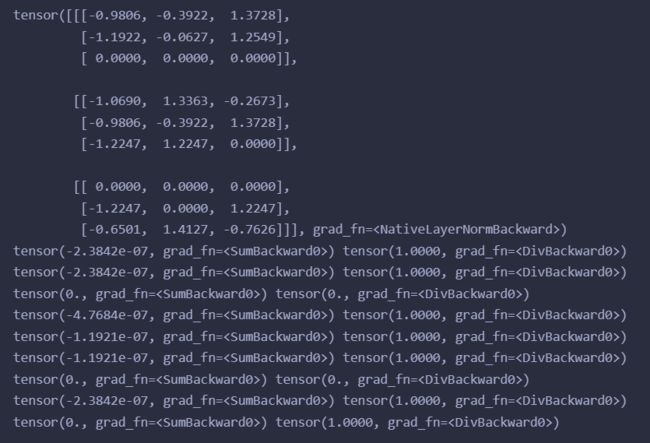
所有,使用layer norm 对应到NLP里就是相当于对每个词向量各自进行标准化。
总结
batch norm适用于CV,因为计算机视觉喂入的数据都是像素点,可以说数据点与点之间是可以比较的,所以使用batch norm可以有比较好的效果,而NLP里,每个词的词向量是一组向量表示一个词,一个词向量割裂开来看是没有意义的,因此不同词向量里的数据点是不能混为一谈的,所以batch norm之后可能会使得词损失语义,效果就可能不好了,但是使用layer norm只是让各个词向量进行标准化,就能够有比较理想的效果了。
参考
深度学习老师的课件