NLP冻手之路(2)——文本数据集的下载与各种操作(Datasets)
✅ NLP 研 0 选手的学习笔记
文章目录
- 一、需要的环境
- 二、数据集的了解
- 三、数据集的获取
-
- 3.1 方法一:直接调用函数获取
- 3.2 方法二:官网下载获取
- 四、数据集的操作
-
- 4.1 排序与打乱
- 4.2 选择和过滤
- 4.3 切分和分桶
- 4.4 列的新增、删除和重命名
- 4.5 map 函数
- 4.6 保存与加载
- 五、小结
- 六、补充说明
上一篇文章链接: NLP冻手之路(1)——中文/英文字典与分词操作(Tokenizer)
一、需要的环境
● python 需要 3.6+,pytorch 需要 1.10+
● 本文使用的库基于 Hugging Face Transformer,官网链接:https://huggingface.co/docs/transformers/index 【一个很不错的开源网站,针对于 transformer 框架做了很多大集成,目前 github 72.3k ⭐️】
● 安装 Hugging Face Transformer 的库只需要在终端输入 pip install transformers【这是 pip 安装方法】;如果你用的是 conda,则输入 conda install -c huggingface transformers
● 本文除了要安装上述配置,还要安装名为 datasets 的数据集处理包,只需要在终端输入 pip install datasets【这是 pip 安装方法】;如果你用的是 conda,则输入 conda install -c huggingface -c conda-forge datasets
二、数据集的了解
● 这里我用了 pprint 函数来打印,它比 print 打印出来的内容更整洁。
import datasets
from pprint import pprint
my_datasets_list = datasets.list_datasets()
print("Number of datasets in the Datasets library: ", len(my_datasets_list))
pprint(my_datasets_list[:20], compact=True) # 打印数据集列表中的前 20 个来看看
输出结果:
Number of datasets in the Datasets library: 12173
['acronym_identification', 'ade_corpus_v2', 'adversarial_qa', 'aeslc',
'afrikaans_ner_corpus', 'ag_news', 'ai2_arc', 'air_dialogue',
'ajgt_twitter_ar', 'allegro_reviews', 'allocine', 'alt', 'amazon_polarity',
'amazon_reviews_multi', 'amazon_us_reviews', 'ambig_qa', 'americas_nli', 'ami',
'amttl', 'anli']
● 从结果可以看到,截止目前 2022年10月20日,目前数据库已有 12172 个数据集。
● 接着,我们来了解一下一个 中文情感分析的数据集,即 seamew/ChnSentiCorp。注意,后面所有的实验都将基于这个数据集。一般这里面的数据集都有 description,但是这个没有,我大致说一下,就是这个数据集全是一段一段的文本,每一段文本都是用户针对于某件事、某个东西等的评价。
index = my_datasets_list.index('seamew/ChnSentiCorp') # 获取该数据集在 my_datasets(其 type 为list) 的位置
info = datasets.list_datasets(with_details=True)[index] # 通过设置 with_details 为 True 来获得数据集的详细信息
pprint(info)
输出:
DatasetInfo: {
id: seamew/ChnSentiCorp
sha: 5fad0d07523f9c5fc76b8babaca9ab6fdeb6af2d
lastModified: 2021-06-22T08:58:53.000Z
tags: []
private: False
author: seamew
description: None
citation: None
cardData: None
siblings: None
gated: False
downloads: 1512
likes: 8
}
三、数据集的获取
● 数据集的获取有两种方法,第一种是直接调用 load_dataset 函数获取,第二种是从官网下载下来。
● 第一种方法可能需要一下 F墙 的 VPN,需注意的是,这个 VPN 要打开到 “网卡模式”,而不只是 “网页模式”。因为 “网页模式” 只能去看看 Youtube 等外网网页,并不能使得 Python编辑器 访问到外网。
3.1 方法一:直接调用函数获取
● 我们通过设置 cache_dir 来将数据集下载到 ./my_data 中。
import datasets
my_dataset_all = datasets.load_dataset(path='seamew/ChnSentiCorp', cache_dir='./my_data') # 获取整个数据集
my_dataset_train = my_dataset_all['train']
my_dataset_validation = my_dataset_all['validation']
my_dataset_test = my_dataset_all['test']
print("my_dataset_all:", my_dataset_all)
print("my_dataset_train:", my_dataset_train)
print("my_dataset_validation[0]:", my_dataset_validation[0]) # 打印第一个
print("my_dataset_test[:3]:", my_dataset_test[:3]) # 打印前三个
● 运行结果如下,其中 label 为 1 代表对应的那段评论是 积极 的,反之,若 label 为 0 则代表对应的那段评论是 消极 的。其中训练集有 9600 个样例,验证集和测试集分别有 1200 个样例。
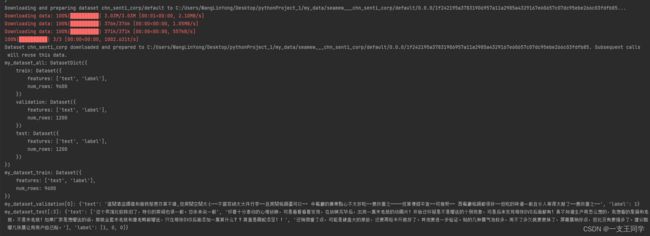
● 如果通过这种方法下载的数据集,即可通过 save_to_disk 函数来保存到本地,下一次加载数据集时,就不需要再重复到网上下载,直接加载本地的即可。加载函数详见 “2.2 方法二:官网下载获取” 的 load_from_disk。
my_dataset_all.save_to_disk(dataset_dict_path='./save_data')
3.2 方法二:官网下载获取
● 如果方法一行不通,就用这个方法。首先进入该数据集的网页:https://huggingface.co/datasets/seamew/ChnSentiCorp。
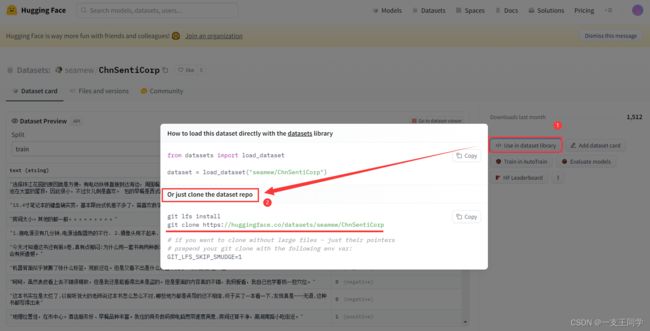
● 然后,依照上图打开对话框,接着使用 git clone https://huggingface.co/datasets/seamew/ChnSentiCorp 来将数据集下载到本地,如下图所示。
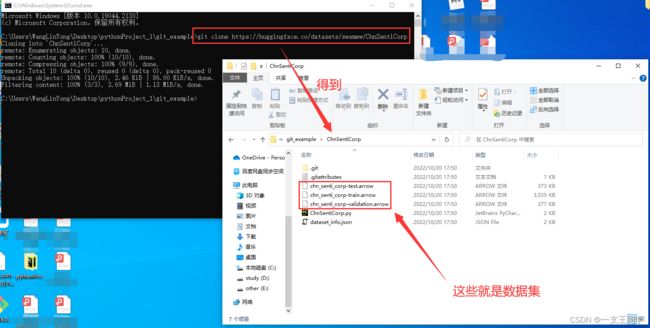
● 我们然后还有做一系列文件夹划分操作,以便代码调用:1. 首先,我们在 ChnSentiCorp 文件夹里新建一个 dataset.json 文件,其中写入 { "splits": ["train", "validation", "test"] } 即可。2. 然后,我们需要编辑三个文件夹,分别命名为 train、validation、test。然后需要将 dataset_info.json 复制三份,分别放到这三个文件夹中,同时,对应的 *.arrow 数据文件也放入其中。3. 最后,在这三个文件夹内新建一个 state.json 文件,其内容如下(以 train 为例,注意,对于不同的文件夹(train、validation和test),其 filename 和 _split 要做相应的改写):
{
"_data_files": [
{
"filename": "chn_senti_corp-train.arrow"
}
],
"_fingerprint": "24c4fd9824d8b978",
"_format_columns": null,
"_format_kwargs": {},
"_format_type": null,
"_indexes": {},
"_output_all_columns": false,
"_split": "train"
}
● 最后,ChnSentiCorp 文件夹里面的结构如下:
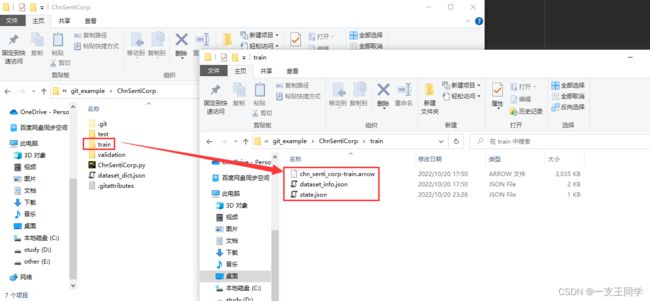
● 我们通过 load_from_disk 函数来将本地保存的数据集加载到内存:
my_dataset_all_git = datasets.load_from_disk('./git_example/ChnSentiCorp')
print(my_dataset_all_git)
输出:
DatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 9600
})
validation: Dataset({
features: ['text', 'label'],
num_rows: 1200
})
test: Dataset({
features: ['text', 'label'],
num_rows: 1200
})
})
四、数据集的操作
4.1 排序与打乱
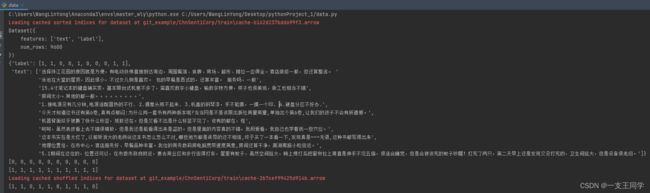
● 在实际训练的时候,我们常用到 排序(sort) 与 打乱(shuffle),具体操作如下:
my_dataset = datasets.load_from_disk('./git_example/ChnSentiCorp')['train'] # 获取 train 集
print(my_dataset) # 简单打印 train集 的信息
pprint(my_dataset[:10]) # 未排序的 label 是乱序的
my_dataset_sort = my_dataset.sort('label') # 排序之后 label 便有序了
print(my_dataset_sort['label'][:10]) # 前十个 label 的值
print(my_dataset_sort['label'][-10:]) # 最后十个 label 的值
shuffled_dataset = my_dataset.shuffle(seed=42) # 打乱顺序 seed 的值可调
print(shuffled_dataset['label'][:10])
● 运行结果:
4.2 选择和过滤
● 再介绍一下常用的选择函数 select 和 过滤函数 filter。
my_dataset = datasets.load_from_disk('./git_example/ChnSentiCorp')['train'] # 获取 train 集
x = my_dataset.select([1, 0, 10, 20, 30, 40, 50]) # 选择下标为 1、0、10、...、50 的数据
pprint(x)
def f(data):
return data['text'].startswith('很差') # 返回一个 true 或者 false
# 这里的 filter 函数需要用一个 lambda 函数
start_with_ar = my_dataset.filter(f)
print(len(start_with_ar), start_with_ar['text']) # 打印以 '很差' 开头的句子的数量和内容
输出:
Dataset({
features: ['label', 'text'],
num_rows: 7
})
2 ['很差,相当差,搞得我们的外国客人都发大火了!!!服务不符合四星级的酒店标准!', '很差劲的地方。是人都不要住。设施什么都不好还贵。真是晦气']
4.3 切分和分桶
● 如果我们还想对 train集 进行划分,可以用 train_test_split 函数,另外还有一个好用的均分函数 shard。
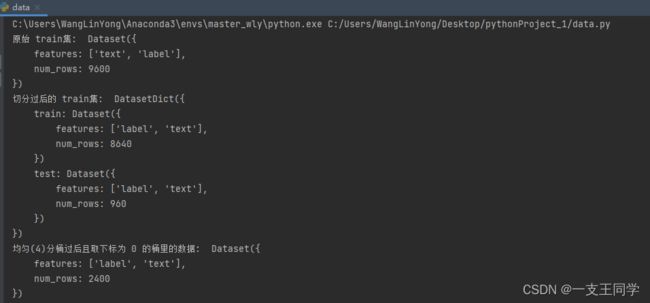
my_dataset = datasets.load_from_disk('./git_example/ChnSentiCorp')['train'] # 获取 train 集
x = my_dataset.train_test_split(test_size=0.1) # 按照 9:1 的比例对 train集 再划分为新的 'train集' 和 'test集'
print("原始 train集: ", my_dataset)
print("切分过后的 train集: ", x)
t = my_dataset.shard(num_shards=4, index=0) # 把数据均匀分配到 4 个桶中. 然后取下标为 0 的桶里的数据
print("均匀(4)分桶过后且取下标为 0 的桶里的数据: ", t)
● 运行结果:
4.4 列的新增、删除和重命名
● 如果我们想对数据集里面的每一个样例都多加一个标签,即列的新增,那就要用到 add_column,具体方法如下。另外还有常用的,列的删除 remove_columns 和列的重命名 rename_column。
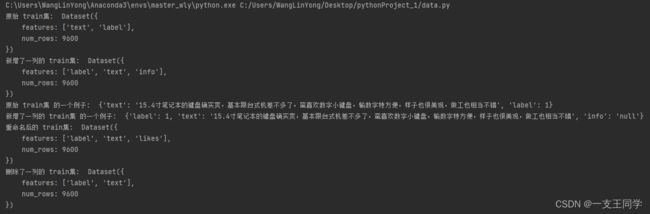
my_dataset = datasets.load_from_disk('./git_example/ChnSentiCorp')['train'] # 获取 train 集
new_column = ["null"] * len(my_dataset)
my_dataset_add = my_dataset.add_column("info", new_column)
print("原始 train集: ", my_dataset)
print("新增了一列的 train集: ", my_dataset_add)
print("原始 train集 的一个例子: ", my_dataset[1])
print("新增了一列的 train集 的一个例子: ", my_dataset_add[1])
my_dataset_newName = my_dataset_add.rename_column('info', 'likes')
print("重命名后的 train集: ", my_dataset_newName)
my_dataset_remove = my_dataset_newName.remove_columns(['likes'])
print("删除了一列的 train集: ", my_dataset_remove)
● 运行结果:
4.5 map 函数
● 这个 map 函数是比较重要的,说白了,可以用这个函数对数据集里面的内容进行了人为的修改。
my_dataset = datasets.load_from_disk('./git_example/ChnSentiCorp')['train'] # 获取 train 集
def m(data):
data['text'] = 'My sentence: ' + data['text']
return data
my_datatset_map = my_dataset.map(m) # 也是通过一个 lambda 函数来处理
pprint(my_datatset_map['text'][:5], width=300) # 打印前五个
print("原始 train集: ", my_dataset)
print("经过 map 后的 train集: ", my_datatset_map)
● 运行结果:

4.6 保存与加载
● 其实在 “3.1 方法一:直接调用函数获取” 中已经讲了一个保存的函数 save_to_disk,下面运行结果图中,文件夹里的 save_data 即为函数 my_dataset.save_to_disk(dataset_dict_path='./save_data') 运行后的结果。另外,如果保存为 .csv 或 .json 格式的文件,就要用到 to_csv 或 to_json 函数,加载的话,除了本地加载的 load_from_disk 函数,还有一个就是 load_dataset。
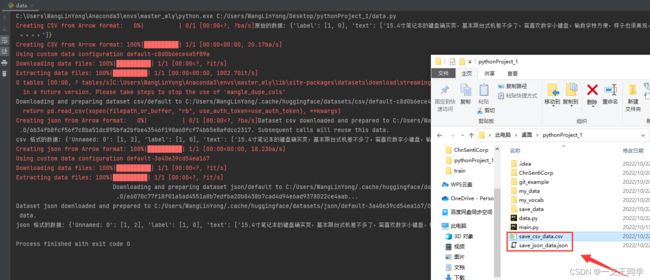
my_dataset = datasets.load_from_disk('./git_example/ChnSentiCorp')['train'] # 获取 train 集
print("原始的数据:", my_dataset[1:3], end='\n') # 打印 2 个例子看看
my_dataset.to_csv(path_or_buf='./save_csv_data.csv') # 导出为 csv 格式
csv_dataset = datasets.load_dataset(path='csv', data_files='./save_csv_data.csv', split='train') # 加载 csv 格式数据
print("csv 格式的数据:", csv_dataset[1:3], end='\n') # 打印 2 个例子看看
csv_dataset.to_json(path_or_buf='./save_json_data.json') # 导出为 json 格式
json_dataset = datasets.load_dataset(path='json', data_files='./save_json_data.json', split='train') # 加载 json 格式数据
print("json 格式的数据:", json_dataset[1:3], end='\n') # 打印 2 个例子看看
● 运行结果:
五、小结
● 关于数据集的操作不难,但是很重要,大致看一遍,过一遍即可。
六、补充说明
● 上一篇文章链接: NLP冻手之路(1)——中文/英文字典与分词操作(Tokenizer)
● 若有写得不对的地方,或有疑问,欢迎评论交流。
● 参考视频:HuggingFace简明教程,BERT中文模型实战示例.NLP预训练模型,Transformers类库,datasets类库快速入门.
● 参考资料:使用Hugging Face的数据集库
⭐️ ⭐️