【自然语言处理】【多模态】FLAVA:一个基础语言和视觉对齐模型
论文地址:https://arxiv.org/pdf/2112.04482.pdf
相关博客:
【自然语言处理】【多模态】多模态综述:视觉语言预训练模型
【自然语言处理】【多模态】CLIP:从自然语言监督中学习可迁移视觉模型
【自然语言处理】【多模态】ViT-BERT:在非图像文本对数据上预训练统一基础模型
【自然语言处理】【多模态】BLIP:面向统一视觉语言理解和生成的自举语言图像预训练
【自然语言处理】【多模态】FLAVA:一个基础语言和视觉对齐模型
【自然语言处理】【多模态】SIMVLM:基于弱监督的简单视觉语言模型预训练
【自然语言处理】【多模态】UniT:基于统一Transformer的多模态多任务学习
【自然语言处理】【多模态】Product1M:基于跨模态预训练的弱监督实例级产品检索
【自然语言处理】【多模态】ALBEF:基于动量蒸馏的视觉语言表示学习
【自然语言处理】【多模态】VinVL:回顾视觉语言模型中的视觉表示
【自然语言处理】【多模态】OFA:通过简单的sequence-to-sequence学习框架统一架构、任务和模态
【自然语言处理】【多模态】Zero&R2D2:大规模中文跨模态基准和视觉语言框架
一、简介
大规模预训练视觉语言 Transformer \text{Transformer} Transformer已经在各种下游任务上带来了令人印象深刻的性能改善。特别地,像 CLIP \text{CLIP} CLIP和 ALIGN \text{ALIGN} ALIGN这样的对比方法已经证明自然语言监督能够带来高质量的视觉模型。
然而,纯对比学习方法有重要的缺点。由于多模态问题需要同时处理两种模态,因此跨模态的性质并不能轻易应用在多模态问题中。这些方法需要大规模的数据集,而研究社区仍然无法获得CLIP和ALIGN的数据集。
相反,近期研究中有各种各种的 Transformer \text{Transformer} Transformer模型,这些模型通过早期融合和交叉模型共享注意力来处理多模态视觉语言领域。然而,在这些例子中纯视觉模态或者纯语言模型任务经常被忽略。
这个领域未来的工作主要是具有不同能力的“基础”或者"通用" Transformer \text{Transformer} Transformer模型,那么下面的限制需要被克服:在视觉和语言空间中真正的基础模型不能仅仅在视觉、或者语言、或者视觉-语言问题上表现好,其需要同时在三种类型任务上都表现好。
将不同模态的信息合并至统一架构是有希望的,不仅仅是因为它与人类理解世界的方式类似,也是因为其可能带来更好的样本效率和更丰富的表示。
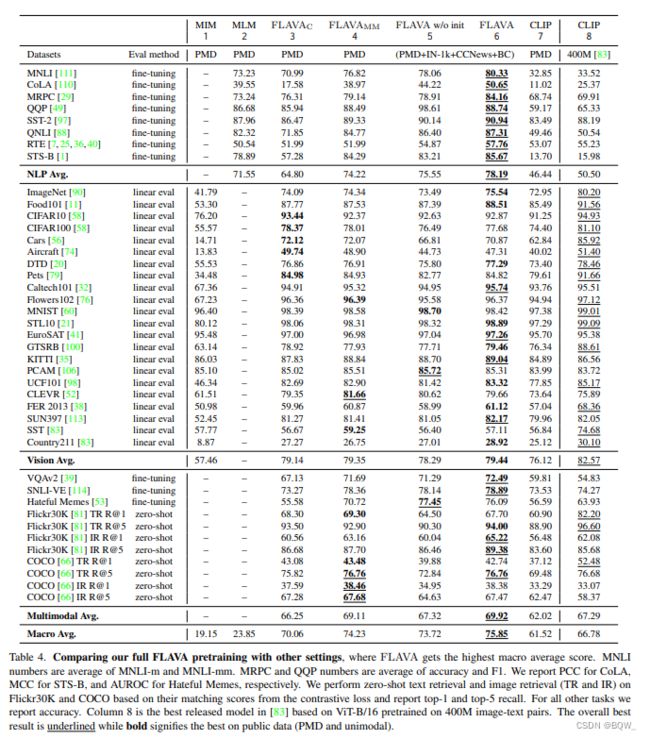
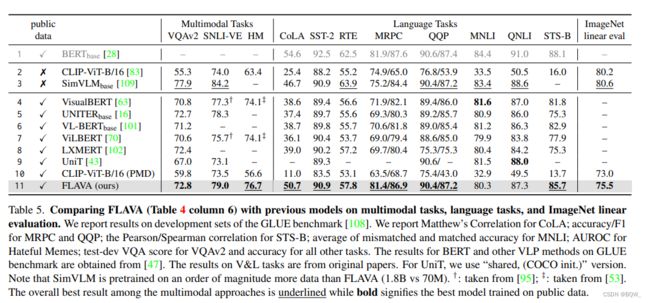
在本文中,作者带来了一个称为 FLAVA \text{FLAVA} FLAVA的基础语言和视觉对齐模型,该模型明确的针对视觉、语言以及它们的多模态组合。 FLAVA \text{FLAVA} FLAVA通过联合在单模态和多模态数据上预训练,能够学习到很好的向量表示。作者在35个跨视觉、自然语言处理和多模态任务上评估了 FLAVA \text{FLAVA} FLAVA,并展示了显著的改进。本文方法的一个重要优点是仅在公开可获取数据集上训练,该数据集的规模要比其他模型的数据小一个数量集的数据。
二、背景
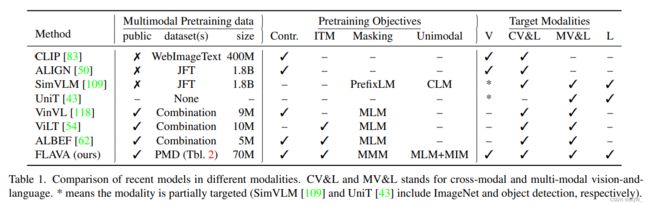
自监督预训练范式已经显著改进了各种领域的state-of-the-art,包括自然语言处理、计算机视觉、语音识别以及视觉语言理解这样的多模态领域。尽管这些进步都是基于在 Transformer \text{Transformer} Transformer上共享的自监督方法,但是在构建能够在不同领域和模态上良好工作的基础模型方面仍然没有取得大的进展。
上表展示了流行和最近模型的广泛比较。最近的工作主要有:(i) 专注在单个目标领域,例如: ViLT \text{ViLT} ViLT和 VinVL \text{VinVL} VinVL;(ii) 针对特征的单模态领域和联合视觉语言领域,例如: ALIGN \text{ALIGN} ALIGN和 CLIP \text{CLIP} CLIP;(iii) 针对所有领域,但是仅在特定领域的特定任务上。
SimVLM \text{SimVLM} SimVLM, ALIGN \text{ALIGN} ALIGN和 CLIP \text{CLIP} CLIP已经通过训巨大的私有的成对image-text语料上训练基于 Transformer \text{Transformer} Transformer模型展示了显著的成果,先前的视觉语言模型 VinVL \text{VinVL} VinVL和 ViLT \text{ViLT} ViLT则相反,其是在较小的公共成对数据集上训练的。
一般来说,在视觉语言空间的模型能够被为两种类别:(i) 图像和文本分别使用独立的编码器进行编码,然后跟一个浅的交互层用于下游任务;(ii) 使用自注意力跨模块融合编码器。双编码器方法在单模态任务以及跨模态检索任务上工作的很好,但是由于缺乏融合导致在涉及到视觉推理和问答的任务上效果不好,而融合编码器方式则会表现好很多。
在融合编码器类别中,还可以进一步划分为模型是否使用单个编码器进行早期且无约束的融合(例如: VisualBERT \text{VisualBERT} VisualBERT, UNITER \text{UNITER} UNITER, VLBERT \text{VLBERT} VLBERT, OSCAR \text{OSCAR} OSCAR)或者仅在特定的共注意力 Transformer \text{Transformer} Transformer层允许交叉注意力(例如: LXMERT \text{LXMERT} LXMERT, ViLBERT \text{ViLBERT} ViLBERT, ERNIE-ViL \text{ERNIE-ViL} ERNIE-ViL)。不同模型之间的另一个区分因素是图像特征的使用,即使用区域特征、patch嵌入、卷积或者是网格特征。
双编码器使用对比预测来从 N 2 N^2 N2个可能的样本中预测出 N N N个正确的样本对。另一方面,融合编码器受单模态预训练启发,例如:masked language modeling、masked image modeling和causal language modeling。大量的预训练任务被提出:(i) 用于视觉语言的Masked Language Modeling(MLM),其会遮蔽caption中的单词,然后利用成对的图片进行预测;(ii) prefixLM,令在图像的帮助下完成caption;(iii) image-text匹配,模型会预测给定的文本和图片是否匹配;(iv) masked region modeling,模型预测图像的特征或者预测目标的类型。
相比于先前的工作, FLAVA \text{FLAVA} FLAVA能够在视觉、语言、视觉-语言领域的广泛任务上工作。 FLAVA \text{FLAVA} FLAVA使用一个共享的主干,该主干仅在公开可获取的成对数据集上进行预训练。 FLAVA \text{FLAVA} FLAVA合并了双编码器和融合编码器方法至一个整体的模型中,该模型可以利用新的 FLAVA \text{FLAVA} FLAVA预训练方案进行预训练。 FLAVA \text{FLAVA} FLAVA能够同时利用单模态数据和多模态成对数据,最终的模型能够处理单模态任何和检索任务,也能处理跨模态和多模态视觉语言任务。
三、 FLAVA \text{FLAVA} FLAVA
本工作的目标是,在单个预训练语言模型中学习到基础的语言和视觉表示,其既能应用在单模态视觉和语言理解,也能用于多模态推理。本文展示如何使用一个简单、优雅的基于 Transformer \text{Transformer} Transformer的架构实现这个目标,该架构在image-data数据上合并了多模态预训练损失函数,并在单模态数据上合并了单模态损失函数。
1. 模型架构
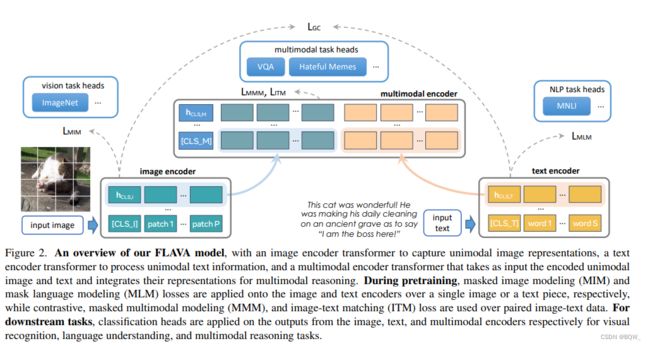
模型架构如上图所示。模型用于抽取单模态图像表示的图像编码器image encoder,用于获得单模态文本表示的文本编码器text encoder,以及用于融合和对齐图像和文本表示来进行多模态推理的多模态编码器,这些都是基于 Transformer \text{Transformer} Transformer的。
1.1 图像编码器
图像编码器采用 ViT \text{ViT} ViT架构。给定一个输入图像,将其缩放为固定的尺寸并将图像分割为patches,这些patches被线性嵌入并输入至 Transformer \text{Transformer} Transformer。图像编码器的输出是图像的隐藏状态向量列表 { h I } \{\textbf{h}_I\} {hI},每个隐藏状态都对应一个图像的patches,为特殊token [CLS_I]插入一个 h C L S , I \textbf{h}_{CLS,I} hCLS,I。这里图像编码器使用 ViT-B/16 \text{ViT-B/16} ViT-B/16。
1.2 文本编码器
给定一个文本输入片段,对齐进行tokenize并嵌入成一个词向量列表。然后应用 Transformer \text{Transformer} Transformer模型将词向量编码为隐藏状态向量列表 { h T } \{\textbf{h}_T\} {hT},包含一个分类token [CLS_T]的隐藏状态 h C L S , T \textbf{h}_{CLS,T} hCLS,T。重要的是,不同于先前的工作,文本编码器与视觉编码器具有完全相同的结构,即对于图像编码器和文本编码器都使用相同的 ViT \text{ViT} ViT架构。
1.3 多模态编码器
使用一个单独的 Transformer \text{Transformer} Transformer来融合图像和文本的隐藏状态。特别地,在 { h I } \{\textbf{h}_I\} {hI}和 { h T } \{\textbf{h}_T\} {hT}中的每个隐藏状态都会被应用2个可学习的线性投影,然后将它们合并至单个列表并添加额外的[CLS_M]token。这个合并的列表被输入至多模态 Transformer \text{Transformer} Transformer编码器(也是基于 ViT \text{ViT} ViT的架构),在投影后的单模型图像和文本表示上应用交叉注意力,并融合两个模态。多模态编码器的输出是隐藏状态列表 { h M } \{\textbf{h}_M\} {hM},每个都对应于 { h I } \{\textbf{h}_I\} {hI}或者 { h T } \{\textbf{h}_T\} {hT}的单模态向量。
1.4 应用于下游任务
FLAVA \text{FLAVA} FLAVA能够直接应用在多模态或者单模态任务上。对于视觉识别任务,会在视觉编码器的单模态输出 h C L S , I \textbf{h}_{CLS,I} hCLS,I上应用分类头。类似地,对于语言理解和多模型推理任务,在文本编码器的输出 h C L S , T \textbf{h}_{CLS,T} hCLS,T或者多模态编码器输出 h C L S , M \textbf{h}_{CLS,M} hCLS,M上应用分类头。单独预训练模型 FLAVA \text{FLAVA} FLAVA,然后独立的在每个任务上进行评估。
2. 多模态预训练目标
目标是通过单模态数据和多模态数据预训练来获得更好的向量表示。 FLAVA \text{FLAVA} FLAVA预训练涉及下面的多模态目标函数:
-
Global contrastive(GC) loss
本文的
image-text对比损失函数类似于CLIP。给定一个batch的图像和文本,最大化正确匹配的文本和图像的cosine相似度,最小化其他不匹配的对。这是通过将 h C L S , I \textbf{h}_{CLS,I} hCLS,I和 h C L S , T \textbf{h}_{CLS,T} hCLS,T投影至嵌入空间,然后使用L2规范化,点积和带有温度系数的softmax损失函数。大模型通常会使用多
GPU数据并行,这样一个batch内的样本会被分割到不同的GPU上。当为了图像和文本对比目标函数收集embedding,CLIP仅反向传播局部GPU上对比损失函数。相反,通过补充实验可以发现,在所有GPU上执行完全的反向传播要比局部反向传播性能高很多。这里称之为全局对比损失函数 L G C L_{GC} LGC。 -
Masked multimodal modeling(MMM)
虽然先前的视觉语言预训练方法通过从多模态输入中重构被遮蔽的token来建模文本模态,它们中大多数并不涉及以端到端方式在像素级上直接进行模态的掩码学习。这里,作者引入了一个新颖的遮蔽多模态建模 MMM \text{MMM} MMM预训练目标函数 L M M M L_{MMM} LMMM,该目标函数同时会遮蔽图像的
patches和文本的tokens,并在两种模态中联合工作。特别地,给定一个图像和文本输入,首先会使用预训练的 dVAE \text{dVAE} dVAE tokenizer将输入图像转换为
patches,该tokenizer会将每个图像patch映射为类似词典的视觉codebook的一个索引。然后,基于 BEiT \text{BEiT} BEiT中的矩形块图像区域来替换图像patches的子集,像 BERT \text{BERT} BERT那样将15%的文本token使用[MASK]进行遮蔽。然后,基于多模态编码器输入 { h M } \{\textbf{h}_M\} {hM},应用多层感知机来预测被遮蔽图像patches的视觉codebook索引,或者是被遮蔽文本tokens的词典索引。这个目标函数被看作是多模态遮蔽语言模型的扩展,其合并了图像端的遮蔽。在本文实验中,作者发现处理对比损失预训练, MMM \text{MMM} MMM预训练还可以带来改善,特别是对 VQA \text{VQA} VQA这样的多模态下游任务。注意,在不适用任何
masking的情况下,在图像patches和文本tokens上应用全局对比损失函数,其会与 MMM \text{MMM} MMM损失分开传递至图像编码器和文本编码器。 -
Image-text matching(ITM)
最后,作者添加了一个
image-text匹配损失函数 L I T M L_{ITM} LITM,先前的预训练工作也会使用这个损失函数。在预训练过程中,会输入带有匹配和不匹配image-text对样本的batch。在多模态编码器的输出 h C L S , M \textbf{h}_{CLS,M} hCLS,M上应用一个分类器来决定输入图像和文本是否彼此匹配。
3. 单模型预训练目标
上面介绍了在image-text数据上预训练 FLAVA \text{FLAVA} FLAVA模型,绝大多数数据集都是没有成对数据的单模态数据集。为了有效的学习各种下游任务的表示,这里利用这些数据集,并在表示中合并单模态和不对齐信息。
在本文中,通过下面的方式引入了单模态数据集中的知识和信息:(1) 在单模态数据集上预训练图像编码器和文本编码器;(2) 在单模态和多模态数据集上联合训练整个 FLAVA \text{FLAVA} FLAVA模型;(3) 通过开始预训练编码器,然后联合训练的方式进行合并。当单独应用在图像或者文本数据,则分别在图像和文本编码器上采用遮蔽图像建模损失函数 MIM \text{MIM} MIM和遮蔽语言建模损失函数 MLM \text{MLM} MLM。
-
Masked image modeling(MIM)
在单模态图像数据集上,使用 BEiT \text{BEiT} BEiT中的矩阵块
masking遮蔽图像的一部分patches并且从其他patches中重构他们。首先使用预训练的 dVAE \text{dVAE} dVAE tokenizer对输入图像进行tokenized,然后在图像编码器输出 { h I } \{\textbf{h}_I\} {hI}上应用一个分类器来预测被遮蔽patches。 -
Masked language modeling(MLM)
在独立的文本数据集上通过应用遮蔽语言建模损失函数(MLM)来预测训练文本编码器。输入的15%的
tokens被遮蔽,然后在单模态文本输出 { h T } \{\textbf{h}_T\} {hT}上应用分类器来从其他token预测被遮蔽的tokens。 -
使用单模态预训练初始化编码器
这里使用三种数据来源进行预训练:单模态图像数据集 ImageNet-1K \text{ImageNet-1K} ImageNet-1K、单模态文本数据集 CCNews \text{CCNews} CCNews和 BookCorpus \text{BookCorpus} BookCorpus、多模态
image-text对数据集。这里首先会使用 MLM \text{MLM} MLM目标函数在单模态文本数据集上预训练文本编码器。作者使用了与以往不同的方法来预训练图像编码器:使用 MIM \text{MIM} MIM或者 DINO \text{DINO} DINO目标函数在纯图像数据集上训练图像编码器,之后单模态和多模态数据集同时训练。然后,使用单模态预训练的编码器来初始化整个 FLAVA \text{FLAVA} FLAVA模型,或者随机初始化后从头训练。 -
单模态和多模态联合训练
在图像编码器和文本编码器单模态预训练完后,继续在三种类型的数据集上使用循环抽样来联合训练整个 FLAVA \text{FLAVA} FLAVA。在每次训练迭代中,根据采用比例选择一个数据集并获得一个
batch的样本。然后,依赖于数据集的类型,在图像数据上应用单模态 MIM \text{MIM} MIM,在文本数据上应用单模态 MLM \text{MLM} MLM,或者在image-text对数据上应用多模态损失函数。
4. 实现细节
在高效的预训练中优化器超参数扮演者至关重要的角色。大的batch size, 大的权重衰减,将长的warm up对于防止学习率发散非常重要(作者使用的batch size大小为8192, 学习率为1e-3,权重衰减为0.1,并且在预训练任务中与 AdamW \text{AdamW} AdamW优化器一起10000迭代warm up)。此外, ViT \text{ViT} ViT架构相比 BERT \text{BERT} BERT来说,能够在大学习率下为文本编码器提供更加鲁棒的学习。 FLAVA \text{FLAVA} FLAVA使用开源的 MMF \text{MMF} MMF和 fairseq \text{fairseq} fairseq库实现。此外,使用 FSDP(Fully-Sharded Data Parallel) \text{FSDP(Fully-Sharded Data Parallel)} FSDP(Fully-Sharded Data Parallel)和 FP16 \text{FP16} FP16精度进行训练,从而减少 GPU \text{GPU} GPU显存的消耗。
5. 数据:公开多模态数据集 PMD \text{PMD} PMD
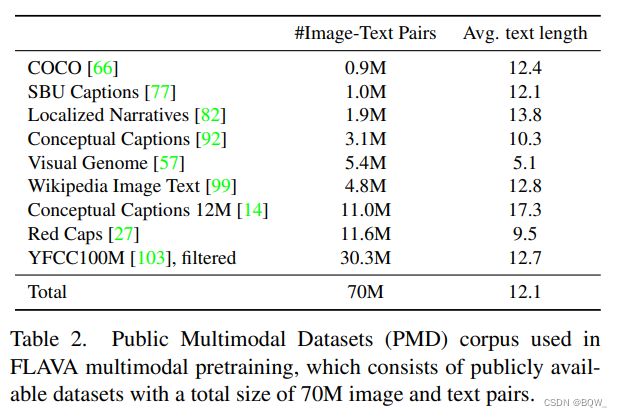
对于多模态预训练,作者从公共可获取的image-text数据源中构造了一个语料库。text-image对的总数量为70M,包括68M的唯一图片,并且caption的平均长度为12.1个单词。对于 YFCC100M \text{YFCC100M} YFCC100M数据集,通过抛弃非英语的captions并仅保留包含超过两个单词的captions来过滤image-text数据。这里首先会考虑每个图像的description字段,若没有通过过滤则考虑title字段。除此之外,没有做任何额外的过滤。重要的是,完全是由可以自由获得的开发数据集构成的,促进可复现性并支持社区未来的工作。
四、实验