第一章:opencv、pytorch、tensorflow、paddlex等环境配置大全总结【图像处理py版本】
第一章:opencv、pytorch、tensorflow、paddlex等环境配置大全总结
- 0 引言
- 一 、环境搭建
-
- 1.pycharm+anaconda安装
-
- 1.1 pycharm 安装
- 1.2 anaconda 安装
- 2.opencv 的的快速安装
- 3. 深度学习环境安装(win+CPU/GPU)
-
- 3.1 pytorch 环境安装
-
- 3.1.1 CPU版本安装
- 3.1.2 GPU版本安装
- 3.2 tensorflow环境安装
-
- 3.1.1 CPU版本安装
- 3.1.2 GPU版本安装
- 3.3 百度飞浆paddlex安装
- 3.4 标注软件labelme安装
-
- 1.标注软件介绍
- 2.软件的安装
- 3.5 eiseg图像分割快速标注软件的安装
-
- 1.软件介绍
- 2.软件的安装
- 3.6 环境安装技巧(适用多电脑同时配置环境)
- 3.7 标注软件的格式说明
- 3.8 如何批量转.json格式
0 引言
因为比较喜欢CSDN的笔记风格,为了更好地深入学习理解,我将根据网上资料以及自己的想法整理书写这篇博文,同时也是为了实验室师弟师妹得一个入门学习借鉴,为此我将根据个人得学习代码以及一些思路写成博文。因为个人水平,文章写得比较浅显,希望大家多多理解。(目前文章还在完成当中)
一 、环境搭建
1.pycharm+anaconda安装
1.1 pycharm 安装
pass
1.2 anaconda 安装
-
1.百度网盘下载anaconda 3 安装包,因为官网下载比较慢,这里我就放在网盘里面,大家直接下载就可以啦。百度网盘提取链接,提取码:bmg7.
-
2.安装步骤:
双击运行
选择下一步

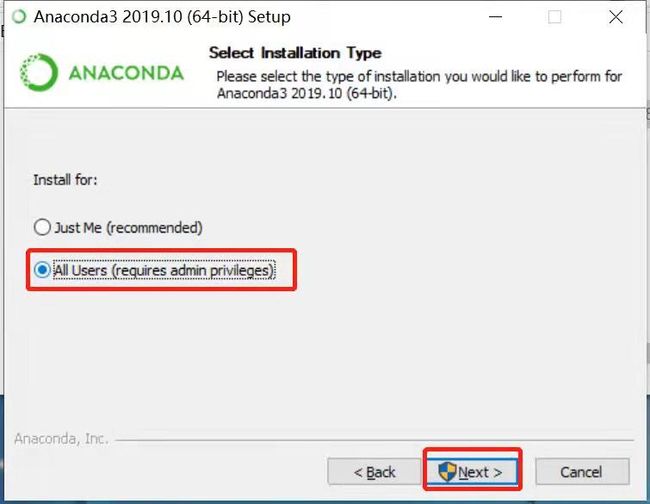
选择所有用户 (两个选一个都可以)
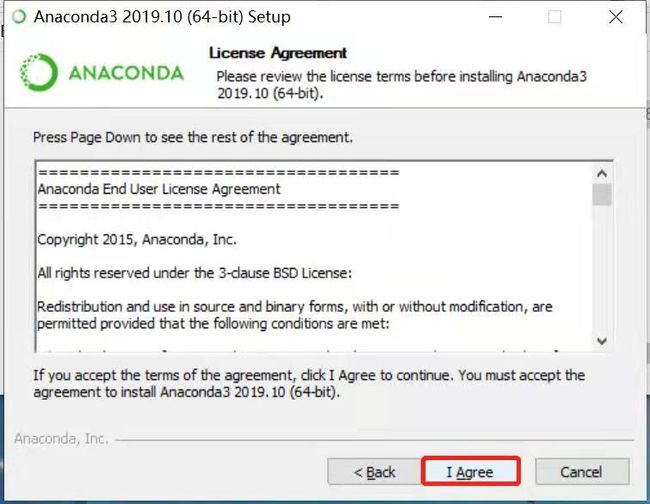
选择同意
更改安装路径
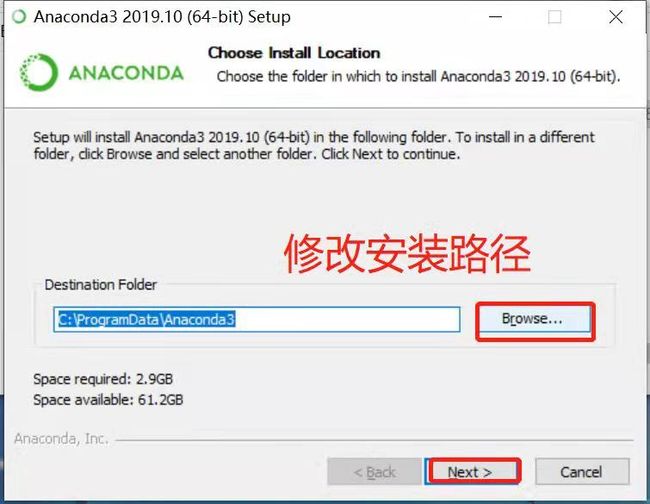
这里我个人比较喜欢直接更改前面盘符
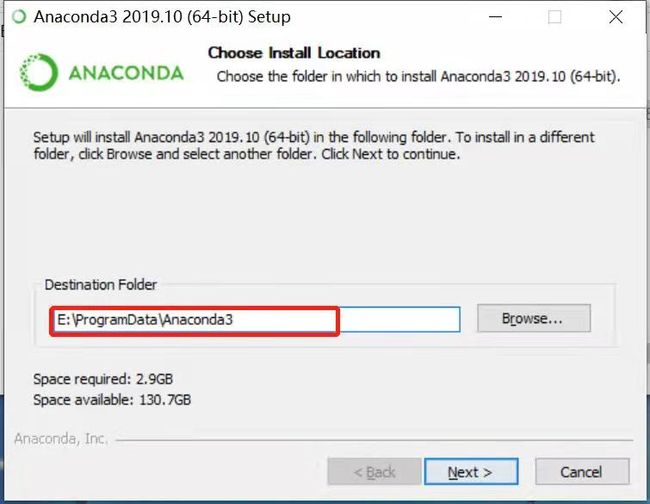
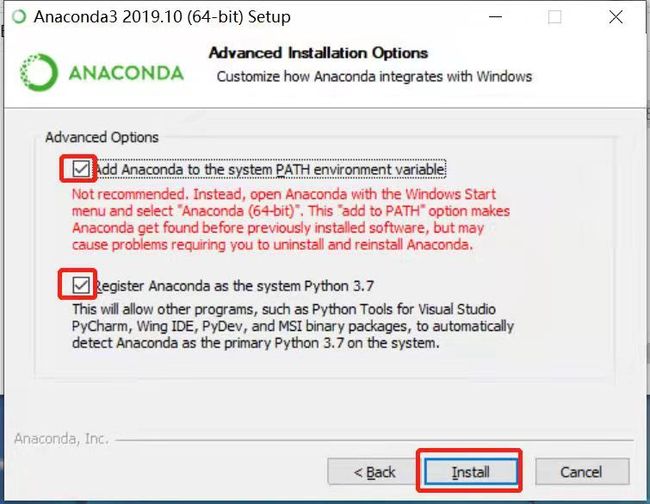
图1.2.6 大家记住两个都要勾上,不然后面需要添加环境路径比较麻烦,第一个是自动把anaconda添加到系统的环境中,下一个是用python3.7的编译器
下一步
下载完成
- 3.参考链接:
anaconda 安装详细教程.
2.opencv 的的快速安装
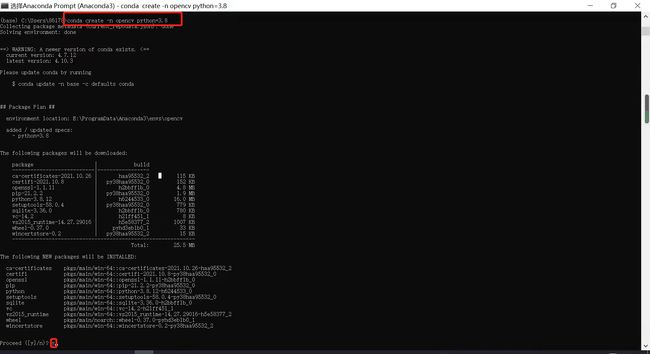
1.创建一个虚拟环境,这里环境名为opencv,大家可以自行根据命名法更改,
conda create -n opencv python=3.8
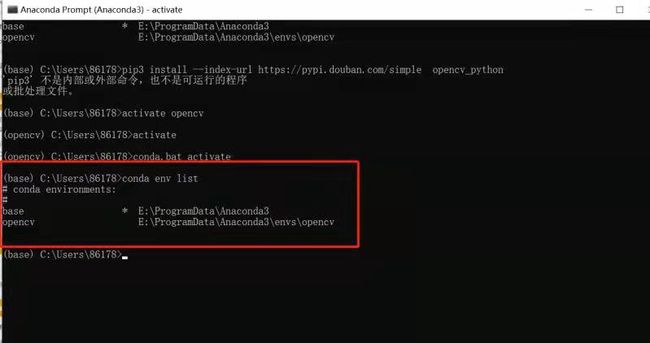
- 查看目前的虚拟环境有哪些
conda env list
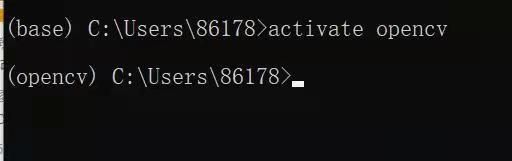
3.激活当前创建的环境,后面需要什么包直接在此环境或者pycharm的终端直接pip就可以了,但是前提pycharm的编译器必须要用到创建环境的python.exe,后面也会进行说明。
4.环境中安装opencv库,大家在安装的时候一定是要输入库的全程,这里是opencv-python。
pip install --index-url https://pypi.douban.com/simple opencv-python
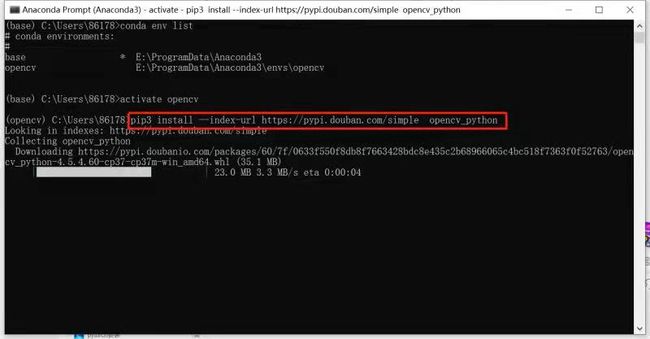 5. 打开pycharm,创建一个新的项目。
5. 打开pycharm,创建一个新的项目。 
6.下一步就是设置代码的存放位置,以及选择环境的编译器。
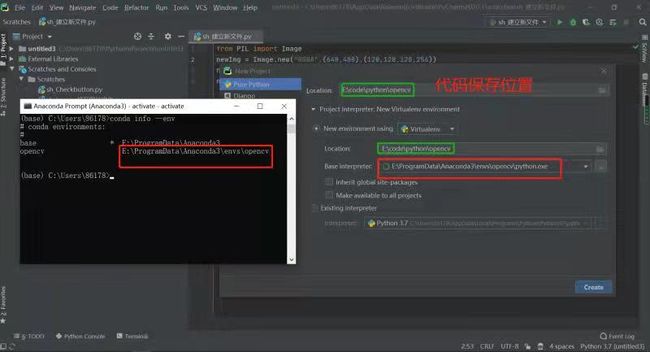
如果大家不知道环境的编译器在哪,大家可以输入一下指令。
conda info --env

7.创建一个py文件之后,进行环境验证。如果没有报错就证明环境安装成功。
import cv2 as cv
import cv2 as cv
path = ".\\1.jpg" # 图片的路径,可以是相对路径或者是绝对路径,第二章会详细介绍
img = cv.imread(path)
# 创建一个窗口名为img的窗口,0或者cv.WINDOW_NORMAL表示可以缩放窗口大小
cv.namedWindow("img",0)
# 显示图片,创建的窗口名要跟图片窗口名字一样。
cv.imshow("img",img)
# 参数0表示程序停止在改行代码上,如果是n,就是延迟n ms之后执行下一条指令
cv.waitKey(0)
# 读取图片后并关闭之后要释放内存
cv.destroyAllWindows()
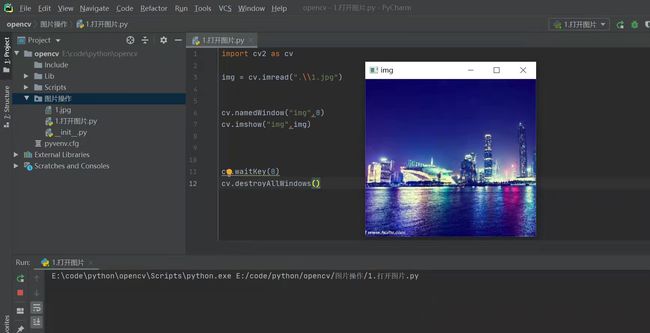
3. 深度学习环境安装(win+CPU/GPU)
3.1 pytorch 环境安装
3.1.1 CPU版本安装
- 1.在电脑左下角找到Anaconda Prompt,创建虚拟pytorch_CPU虚拟环境

# pytorch_CPU为环境名,大家可以根据变量命名方法自行更改。
# python=3.8 为使用编译器版本,大家可以自行调整,这里是以3.8为例子。
conda create -n pytorch_CPU python=3.8

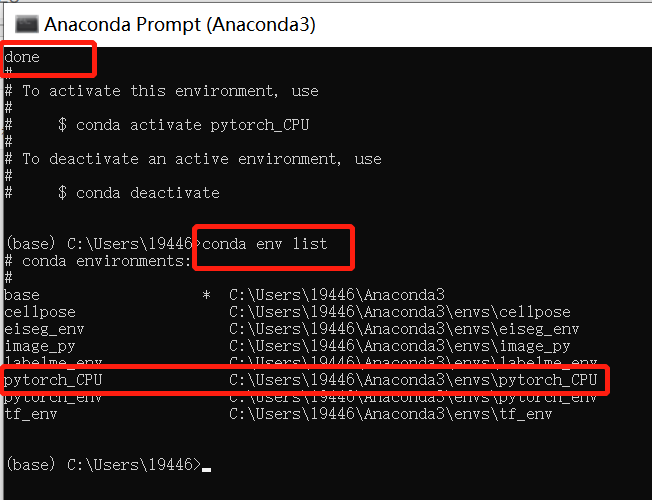
- 2.查看已有环境,并激活环境
# 查看已有环境
conda env list
# 激活刚刚创建的环境用来下载pytorch cpu版本框架
activate pytorch_CPU
- 3.在已经激活的环境中下载pytorch 框架【pytorch官网获取下载链接】.
根据电脑系统以及版本选择好后复制指令进行输入
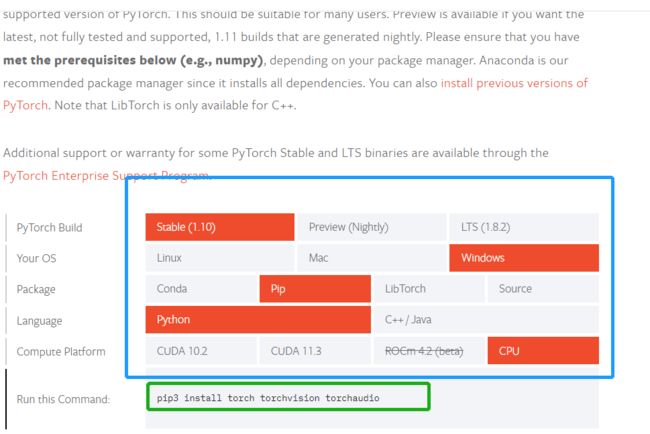
# 官网指令是用默认源进行下载,有什么会因为网速的问题出现time out报错,所以大家还是都用豆瓣进行下载。
pip3 install torch torchvision torchaudio
# 豆瓣源下载
pip3 install --index-url https://pypi.douban.com/simple torch torchvision torchaudio

- 3 环境验证
# 在环境中输入python
python
# 然后导出pytorch框架验证,没有报错就是安装完成
import torch

- 4.结语
前面文章也有详细介绍 如何在win系统中安装CPU的pytorch环境。大家可以进入我的主页进行观看。如果觉得文章写得不错,不妨点个赞支持一下!
3.1.2 GPU版本安装
pass
3.2 tensorflow环境安装
3.1.1 CPU版本安装
pass
3.1.2 GPU版本安装
-
1.电脑有GPU的同学,可以通过下面链接,查看CUDA的版本,后面指令下载中就可以选择对应的型号。(如果指令中没有对应的型号,找一个版本下载就可以,我试了几次都能成功安装)如何查看CUDA型号.
-
2.创建tensorflow_GPU虚拟环境,环境名大家可以自由更改,但要符合命名规范。
conda create - n tensorflow_GPU python=3.8
# 若过程中有Proceed ([y]/n)?
# 输入y就可以
- 3.激活环境,需要激活pip下载之后的包才会在此环境里面。
activate tensorflow_GPU
- 4.下载GPU版本的tensorflow
4.1 技巧说明,如果不知道下载的包有说明版本,大家只需要随便输入一个版本,然后就会博报错,提示有什么版本可以下载,这时候大家就可以根据里面的版本选择进行下载。
pip install --index-url https://pypi.douban.com/simple tensorflow gpu==2.1111

4.2 选择里面的版本进行下载
pip install --index-url https://pypi.douban.com/simple tensorflow gpu==2.3.1
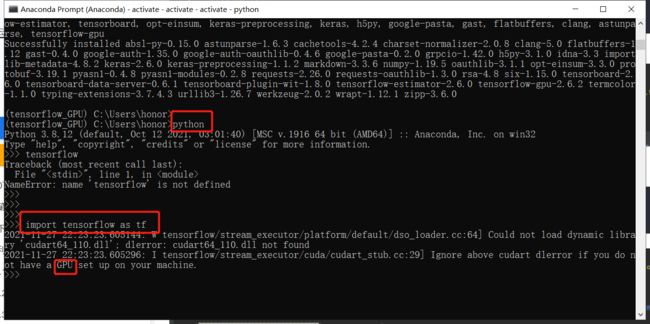
4.3 下载成功之后,输入python
python
4.4 环境验证
# 输入
import tensorflow as tf
3.3 百度飞浆paddlex安装
3.4 标注软件labelme安装
1.标注软件介绍
无论是深度学习中的目标检测、图像的语义分割、实例分割,都是需要人工标定数据集给神经网络去学习,就像我们小时候一样,父母教我们认识一样物体,假如是动物狗,他们想让我们认识狗的方式就是多次看到不同类型的狗,都会跟小孩说一下这是什么动物(这里只是简单做个假设),通过学习之后,后面遇到什么动物,我们根据特征就能找到这是一条狗还是其他动物了。同样标注软件就是起来这个作用,我们将狗这一类比标注出来,将猫这一类表框选出来,然后给神经网络去训练,通过学习之后,给出新的图片,就能根据训练好的模型知道这是猫还是狗了。
2.软件的安装
- 1.前面大家已经安装了anaconda,接下来我们将开始用anacaonda进行虚拟环境的创建。首先在设置找到Anaconada Prompt,点击运行
*
- 2.创建新的环境
# conda env list #查看环境列表
# labelme_env :环境名
# python=3.8使用Python3.8编译器
conda create -n labelme_nev python=3.8
# 若过程中有Proceed ([y]/n)?
# 输入y就可以
- 3 安装pyqt库,因为lableme 其实就是一个由pyqt写的界面,运行这个软件其实就是运行它的.py文件,需要进行安装对应的库。
conda install pyqt
* 4.用豆瓣源进行安装lableme(经过与其他源对比,个人决定豆瓣源下载速度是最快的),大家下载什么库都可以,只需要copy下面代码,将lableme换成所需要的库即可。
pip install --index-url https://pypi.douban.com/simple labelme
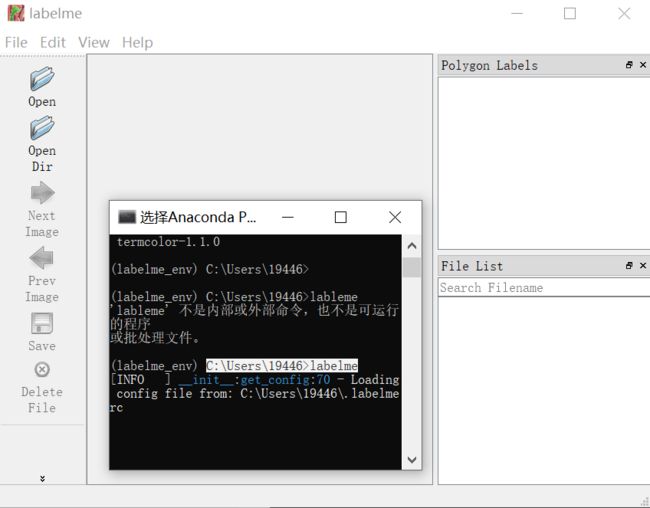
- 5.在Anaconda Prompt输入labelme就可以打开了
labelme
- 6.显示效果
- 参考链接:
1.关于CSDN大小、位置调整文章.
2.labelme安装教程.
3.关于anaconda创建环境、安装库、删除指令参考链接.
3.5 eiseg图像分割快速标注软件的安装
1.软件介绍
前面安装的labelme可以用来标注目标检测、以及图像分割的数据集,其中语义分割或者实力分割的数据集都需要用鼠标将物体的轮廓框选出来。如果图片数量较大、以及需要框选物体较多的时候,就会耗时耗力,所以有没有一种软件,可以辅助制作数据集呢?答案是有的,eiseg是由百度飞浆开发用来辅助制作数据集的一个开源软件。用这个软件,只需要点击目标区域,微调参数就能快速选取了物体的轮廓。
2.软件的安装
- 1.大家可以同labelme创建新的环境。或者在已有的环境进行安装。这里就直接在前面创建的labelme_env环境下进行安装。
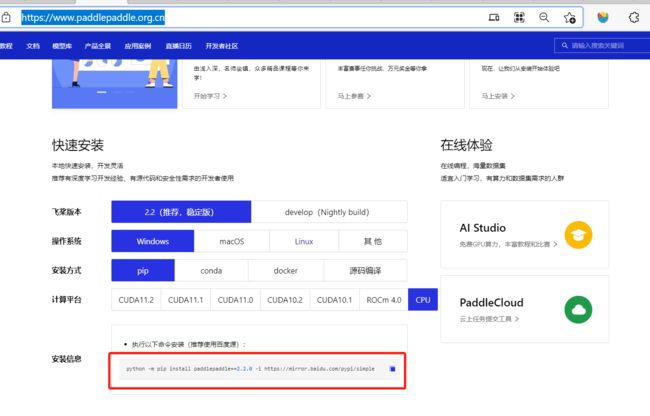
- 2.安装paddlepaddlel大家点击链接查看官方文档,copy指令就可以下载了.
# 这里默认是win10 CPU
pip install paddlepaddle
#这里选择的是win10 +cpu+wen+稳定版
python -m pip install paddlepaddle==2.2.0 -i https://mirror.baidu.com/pypi/simple
#
- 3.下载eiseg
# 默认是安装最新版本,目前是0.4
pip install eiseg
# 但是用最新版本后面会出现加载不了模型,所以需要安装低版本,目前总共有以下版本
# 0.1.3, 0.1.4, 0.1.5, 0.1.6, 0.2.0, 0.2.0.1, 0.3.0, 0.3.0.2, 0.3.1, 0.4.0
# 用0.3.1版本,同时用豆瓣源下载会更快
pip install --index-url https://pypi.douban.com/simple eiseg==0.3.1
- 4 打开eiseg
eiseg
-
5 显示效果
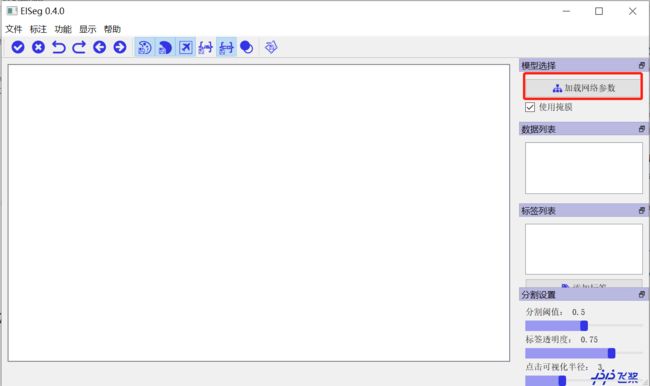
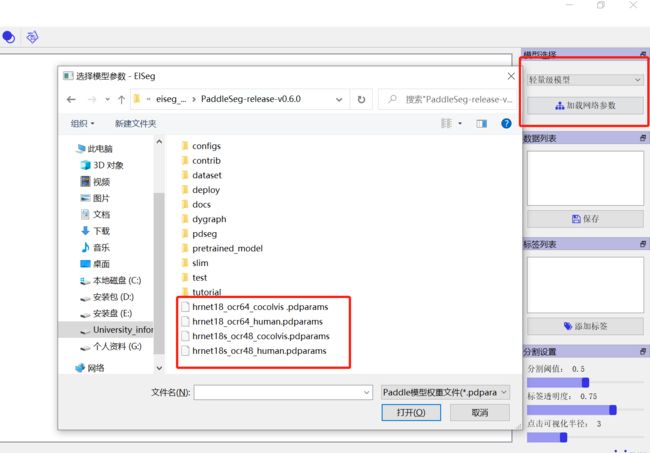
注意:先下载一下安装包,把下载模型放在安装包解压后的文件,后面打开的时候根据路径就能加载模型了,!!!要是没有放在解压后安装包里面,就会出现加载不了模型!!!。
github下载链接,点击克隆->ZIP就可以下载.
| 项目 | Value |
|---|---|
| 高精度模型 | hrnet18_ocr64_cocolvis.pdparams. |
| 轻量化模型 | hrnet18s_ocr48_cocolvis.pdparams. |
| 高精度模型 | hrnet18_ocr64_human.pdparams. |
| 轻量化模型 | hrnet18s_ocr48_human.pdparams. |
- 7 最终效果显示
- 8 参考链接:
EISeg分割标注软件使用.