【论文阅读】Deep Code Search
论文阅读:Deep Code Search
发表:ICSE 2018 - CCF A
领域:代码搜索 (Code Search),代码表示 (Code Representation)
相关链接:
- Homepage: Xiaodong Gu
- Paper: https://sci-hub.wf/10.1145/3180155.3180167
- Github: https://github.com/guxd/deep-code-search
文章目录
- 论文阅读:Deep Code Search
- Abstract
- 2 Backround
-
- 2.1 Embedding Techniques
- 2.2 RNN for Sequence Embedding
- 2.3 Joint Embedding of Heterogeneous Data
- 3 CODEnn Architecture
-
- 3.1 Code Embedding Network
- 3.2 Description Embedding Network
- 3.3 Similarity Module
- 3.4 Model Training
- 4 DeepCS
-
- 4.1 Training Corpus
- 4.2 Training CODEnn Model
- 5 Evaluation
- 6 Conclusion
Abstract
目前,许多开发人员通过搜索大规模代码库来重用以前编写好的代码片段。现有的代码搜索工具通常将源代码视为文本文档,并利用信息检索模型来检索与给定 Query 相匹配的代码片段。这种方法主要依赖源代码与自然语言查询 (Query) 之间的文本相似性,缺乏对查询和源代码语义的深入理解。
本文提出了一种名为 CODEnn (代码描述嵌入神经网络)的新型深度神经网络。CODEnn 将代码片段和自然语言描述联合嵌入到高维向量空间中,使得代码片段及其对应的描述拥有相似的向量表示。为了验证 CODEnn,本文使用 CODEnn 实现了一个名为 DeepCS 的代码搜索工具,从 GitHub 收集了一个大规模代码库并用此评估 DeepCS。实验结果表明,本文提出的方法可以有效地检索相关的代码片段,并且优于前人的工作。
据作者所知,他们是第一个提出基于深度学习的代码搜索工具的人。
2 Backround
2.1 Embedding Techniques
Embedding 又称为分布式表示,该技术旨在学习实体(单词、句子、图片等)的向量表示,使得相似实体具有彼此接近的向量表示。
一种经典的 Embedding 技术是词嵌入 (word embedding),它将 word 表示为固定长度的向量,以便相似的 word 在向量空间中彼此靠近。同理,句子也可以被 Embedding 为一个向量,一种简单的方式是:将句子拆分为单词,将词向量拼接作为句向量。
2.2 RNN for Sequence Embedding
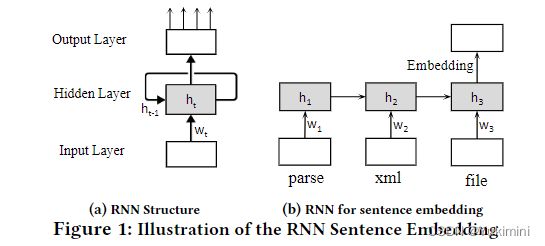
RNN 即循环神经网络,是一种广泛使用的神经网络。该神经网络包括三层,输入层将每个输入映射到一个向量,循环隐藏层在读取每个输入后循环计算和更新隐藏状态,输出层将隐藏状态用于特定任务。与传统的前馈神经网络不同,RNN 可以使用其内部存储器嵌入顺序输入,例如句子。
图 1b 显示了 RNN 如何将句子嵌入向量中。RNN 一个一个地读取句子中的单词,并在每个时间步记录一个隐藏状态。当它读取第一个单词时,它将单词映射到向量 w 1 w_ 1 w1 并使用 w 1 w_ 1 w1 计算当前隐藏状态 h 1 h_ 1 h1。然后,读取第二个单词,将其嵌入到 w 2 w_ 2 w2 中,并使用 w 2 w_ 2 w2 将隐藏状态 h 1 h_ 1 h1 更新为 h 2 h_ 2 h2。该过程继续进行,直到 RNN 接收到最后一个单词并获得最终状态 h 3 h_ 3 h3 。最终状态 h 3 h_ 3 h3 可以作为整个句子的嵌入 c c c。
2.3 Joint Embedding of Heterogeneous Data
如前文所述,源代码和查询是两种异质的数据,学习这两种异质数据间的相关性是很困难的。因此,作者采取 Joint Embedding (联合嵌入) 的方式将两种数据关联起来进行学习。
联合嵌入,也称为多模态嵌入,是一种将异构数据联合嵌入/关联到统一向量空间中的技术,以便两种模态中语义相似的概念在向量空间中相接近。

3 CODEnn Architecture
图 4 显示了 CODEnn 的整体架构。CODEnn 由三个模块组成,分别是:
- 一个代码嵌入网络 (CoNN),将源代码嵌入向量中。
- 一个描述嵌入网络 (DeNN),将自然语言描述嵌入向量中。
- 一个相似度模块,用于测量代码和描述之间的相似程度。

3.1 Code Embedding Network
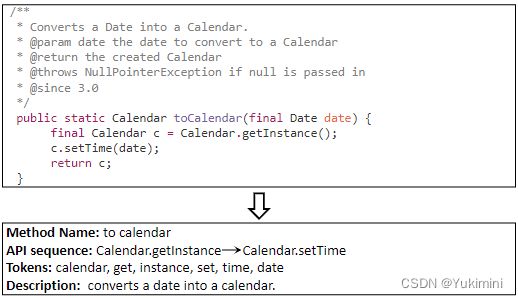
源代码不仅仅是单纯的文本,而是包含了多方面的信息,例如 token、控制流和 API。CoNN考虑了三方面信息:函数名、API 调用序列和 token。对于每一个函数级别 (method level) 的源代码,作者首先抽取这三方面的信息,每一部分的信息先单独做 Embedding,然后再组合成一个向量 c 用以表示整个源代码。
3.2 Description Embedding Network
DeNN 使用带有 maxpooling 的 RNN 将描述嵌入到向量 d 中。
3.3 Similarity Module
使用余弦定理来度量源代码向量与其对应描述向量之间的相似度。
c o s ( c , d ) = c T d ∣ ∣ c ∣ ∣ ∣ ∣ d ∣ ∣ cos(c ,d) = \frac{c^T d}{||c|| ||d||} cos(c,d)=∣∣c∣∣∣∣d∣∣cTd
3.4 Model Training
采用构造负例的方法进行训练。本文将每个训练实例构造为三元组
训练采用排名损失 (Ranking Loss),其作用是促使代码片段与其正确描述之间的余弦相似度上升,与其错误描述之间的余弦相似度下降。
L ( θ ) = ∑ < C , D + , D − > m a x ( 0 , ϵ − c o s ( c , d + ) + c o s ( c , d − ) ) L(\theta) = \sum_{
4 DeepCS
DeepCS 为给定的自然语言查询推荐前 K 个最相关的代码片段。它包括三个主要阶段:离线训练、离线代码嵌入和在线代码搜索。图 5 显示了整体架构。
首先收集一个 Java 语言的大型语料库,用该数据训练 CODEnn 模型;然后,对于用户希望从中搜索代码片段的给定代码库,DeepCS 为搜索代码库中的每个 Java 方法提取代码元素,并使用经过训练的 CODEnn 模型的 CoNN 模块计算代码向量;最后,当用户查询 (Query) 到达时,DeepCS 首先使用 CODEnn 模型的 DeNN 模块计算 Query 的向量表示,然后返回向量接近 Query 向量的代码片段。

4.1 Training Corpus
通过从 Github 上爬取 Java method 构建数据集。对于每一个 Java method,选取其文档注释的第一句话作为其自然语言描述,因为根据 Javadoc 指南,第一句话通常是一个方法的摘要。最终,获得了一个包含 18,233,872 个注释 Java method 的语料库。
对于获取到的函数,抽取其三元组
- Method Name Extraction:抽取其 method name,并按驼峰命名法将其拆分为 token。例如:listFiles 将被拆分为 list files。
- API Sequence Extraction:使用 Eclipse JDT 编译器解析生成 AST 并遍历 AST。方法与 Deep API Learning 一致。
- Token Extraction:tokenizer 每一个函数 body,并且删除重复的token、停用词 (in 和 the 等) 以及 Java 关键字 (因为它们经常出现在源代码中并且没有区别)。
对于注释的提取,本文使用 Eclipse JDT 编译器从 Java 方法中解析 AST 并从 AST 中提取 JavaDoc 注释。
4.2 Training CODEnn Model
所有的 RNN 均使用 bi-direction LSTM。LSTM 的每个方向有 200 个隐藏单元,词向量的维度是 100。
MLP有两种,分别用于 embedding code token 以及合并各部分 embedding。前者有 100 个隐藏单元,后者有 400 个隐藏单元。
其他相关参数:batchsize = 128,viocabsize = 10000。
5 Evaluation
从 StackOverFlow上按条件筛选出 50 个 Java-tagged 的问题,采用了四种度量方法: FRank、Success-Rate@k、Precision@k、MRR。作者将 DeepCS 与 CodeHow 和传统的基于 Lucene 的代码搜索工具进行比较。
表 1 显示了基准中每个查询的 DeepCS 和相关方法的评估结果。问题 ID 列显示了 Stack Overflow 中查询来自的问题的原始 ID。 FRank 列显示了每种方法的 FRank 结果。符号"NF"代表未找到,这意味着在前 K 个结果中没有返回相关结果(K=10)。
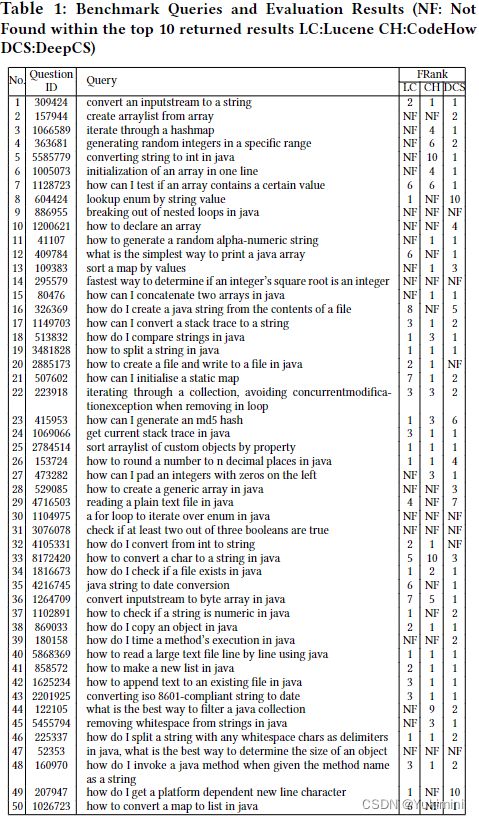
表 2 显示了三种方法的整体性能,以 SuccessRate@k、Precision@k 和 MRR 衡量。 R@1、R@5 和 R@10 列分别显示了当 k 为 1、5 和 10 时 SuccessRate@k 的结果。 P@1、P@5 和 P@10 列分别显示了当 k 分别为 1、5 和 10 时所有查询的平均 Precision@k 的结果。 MRR 列显示了三种方法的 MRR 值。结果表明,DeepCS 返回的相关代码片段比 CodeHow 和 Lucene 更多。例如,R@5 值为 0.76,这意味着对于 76% 的查询,可以在前 5 个返回结果中找到相关的代码片段。 P@5 值为 0.5,这意味着前 5 个结果中有 50% 被认为是准确的。对于 SuccessRate@k,对 CodeHow 的改进分别为 21%、31% 和 30%。对于 Precision@k,CodeHow 的改进分别为 21%、72% 和 75%。对于 MRR,CodeHow 的改进是 33%。总的来说,我们的方法提高了相关技术在所有指标上的准确性。

6 Conclusion
本文提出了一种名为 CODEnn 的新型深度神经网络用于代码搜索。 CODEnn 不是匹配文本相似性,而是学习源代码和自然语言查询的统一向量表示,以便可以根据它们的向量检索与查询语义相关的代码片段。作为一个概念验证应用程序,本文基于所提出的 CODEnn 模型实现了一个代码搜索工具 DeepCS。实验研究表明,所提出的方法是有效的,并且优于现有相关方法。未来,作者将研究源代码的更多方面,例如控制结构,以更好地表示源代码的高级语义。本文设计的深度神经网络也可能有益于其他软件工程问题,例如,故障定位。