论文笔记 | code representation(代码表示学习)系列
文章目录
-
- Associating Natural language comment and source code entities
-
- 研究动机
- 本文方法
- Deep Learning Similarities from Different Representations of Source Code
-
- 研究动机
- 具体方法
- 实验部分
- Learning Semantic Vector Representations of Source Code via a Siamese Neural Network
-
- 研究动机
- 具体方法
- 实验部分
-
- 数据
- Neural Code Comprehension: A Learnable Representation of Code Semantics
-
- 研究动机
- 本文内容
- 相关工作
- 其他内容
-
- GCC和LLVM
- 代码的中间表示IR
- Automated Vuluerability Detection in Source Code Using Deep Representation Learning
-
- 方法
- Hierarchical Learning of Cross-Language Mappings through Distributed Vector Representations for Code
-
- 研究动机
- 本文方法
- Deep Transfer Learning for Source Code Modeling
-
- 研究动机
- 本文方法
- PathMiner: A Library for Mining of Path-based Representations of Code
-
- 研究动机
- 本文内容
- code2vec: Learning Distributed Representations of Code
-
- 研究动机
- 本文方法
- 实验部分
-
- 数据集
- 实验评估
- 其他内容
- Code Representation 数据集
-
- BigCloneBench
- DeepAM: Migrate APIs with Multi-modal Sequence to Sequence Learning
-
- 研究动机
- 方法介绍
- A Novel Neural Source Code Representation Based on Abstract Syntax Tree
- Learning-based Recursive Aggregation of Abstract Syntax Trees for Code Clone Detection
-
- 研究动机
- 主要方法
- SAR: Learning Cross-Language API Mappings with Little Knowledge
-
- Motivation
- Domain Adaption
-
- Seed-based Domain Adaptation
- Unsupervised Domain Adaptation
- Methods
- 相关文章
- DeepBugs:A Learning Approach to Name-based Bug Detection
-
- Motivation
- Methods
-
- Create training data
- Learn representation of identifiers
- Graph4Code: A Machine Interpretable Knowledge Graph for Code
Associating Natural language comment and source code entities
AAAI 2020
Sheena Panthaplackel, Milos Gligoric, Raymond J. Mooney, Junyi Jessy Li
The University of Texas at Austin
论文pdf
data and code
研究动机
本文研究的是源代码和注释之间的精确匹配。与之相关的工作包括根据源代码生成注释,这类方法在生成特定的注释时,会估计代码中每个部分的attention值,从而得到符合当前需求的注释。但是这类方法不能实现源代码和注释之间的精确匹配。
作者想要做更细粒度的code和comment的匹配。也就是对于comment中的词,判断代码中的token是否和该词有关,即建模为分类问题。数据集中包含每个token是否有关的标注。
该任务的挑战在于:
- 无标注数据集
- 无此任务的baseline
本文方法
针对以上两个挑战,作者的解决方案是:
-
训练模型的时候使用github commit log,其中记录了每次提交的comment修改和code修改内容,共包含776条数据。测试模型的时候,使用人工标注的117条数据。
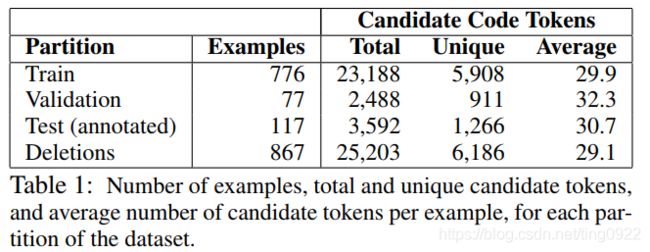
在Github中提交代码时,提交者一般会对其修改内容进行注释,也就是commit message。作者利用这一特性,将每次Github上修改的代码内容和commit message进行关联。从而得到代码中特定部分是否与commit message相关的数据(这个数据是含有噪声的,但作者后面验证了这样的噪声数据对于训练网络来说,是有好处的)。
下图列出了一些例子:

得到了这样的数据之后,作者将这个问题建模为分类问题,对应两个模型。一个是二分类模型,一个是序列标注模型。
其中,二分类问题是指,给定一系列的code tokens和自然语言的注释,我们单独的判断每个token是否与注释相关;序列标注是指联合判断一系列的code tokens和注释是否相关。 -
针对没有baseline的问题,作者使用的是基本的分类算法,包含随机分类,带权分类等。

待改进的点:
- 训练和测试的数据集都太小
- 用到的分类模型分别是二分类和CRF,比较的baseline太弱
Deep Learning Similarities from Different Representations of Source Code
会议:IEEE MSR 2018(C类)
作者:Michele Tufano, Cody Watson, Gabriele Bavota, Massimiliano Di Penta, Martin White, Denys Poshyvanyk
机构:College of William and Mary, University della Svizzera Italiana, University of Sannio
关键词:code similarity, different representations of code
论文pdf
研究动机
源代码可以被表示成不同形式,比如:identifiers, AST, CFG, DFG, Bytecode等。作者认为这些形式提供了对于一个代码块的不同方面的表示。但目前别的方法很多都是只使用一种形式来得到代码的表示。所以作者想要知道这些表示以及它们的组合是否对于代码的表示和代码的相似度计算有作用。
具体方法
作者选取了四种表示形式:identifiers, AST, CFG, Bytecode。文中第三部分描述了这四种形式的extraction 和 normalization。其中,identifier, AST, Bytecode提取后经过规范化,都是得到一个sequence。CFG得到的是一个图。
提取出来这四种形式之后,就需要针对其中的token和代码块进行表示。针对sequence和graph,作者也有两种不同的学习表示的方式。
sequence的表示分为两步:1)先用RNN学习每个token的表示;2)利用RNN autoencoder学这个sequence的表示,但是这里是每次对一对token联合表示,然后再decode。所以如果想要得到一个sequence的表示,就需要递归使用autoencoder,直到最后一层只剩下一个向量表示。第一层的autoencoder如下图所示:
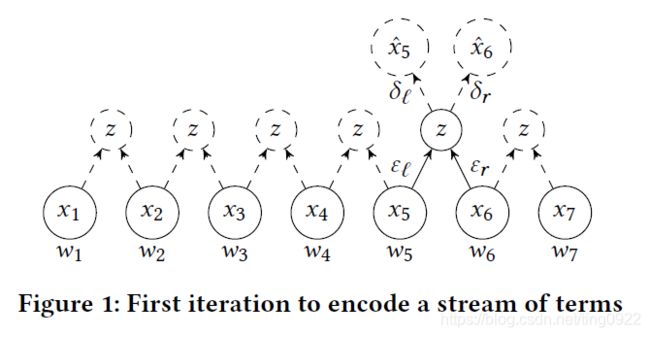
graph的表示是利用HOPE得来的,首先得到每个节点的表示,然后利用mean pooling得到整个图的表示。
下一步是要计算两个代码块的相似度,针对多种表示,每种表示利用欧氏距离计算,然后加权相加,得到最终两个代码块的距离。
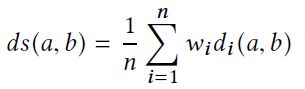
实验部分
实验中用到的是java projects 和 java libraries的数据集。以class和method为单位。java projects数据集统计如下(共十个):
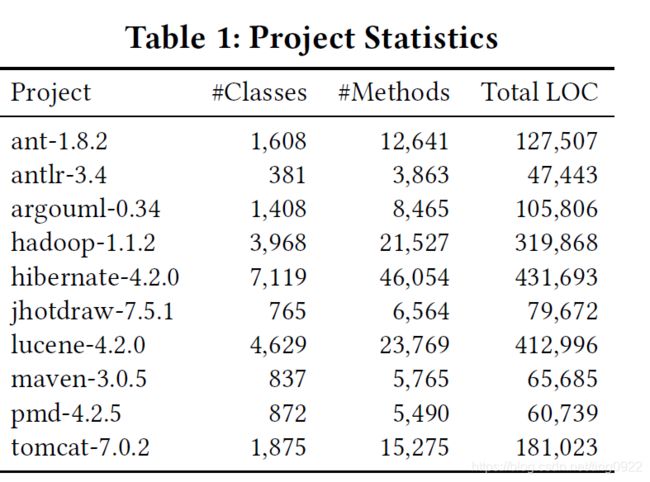
【数据集规模不大,并且这些数据中,被标注为相似的代码对有多少,论文中没有说明】
实验中,验证了各种表示对于检测代码相似度的作用,以及两种表示的相互作用。从实验可以看出,多种表示结合是可以提升效果的,并且各种表示关注的点不一样。
论文的总结中说,这篇文章主要是在评估各种表示对于检测代码克隆的性能,并且证明了such representations are orthogonal and complementary to each other. 从下图可以看出,AST和CFG的组合对于学习代码表示的贡献是最大的。
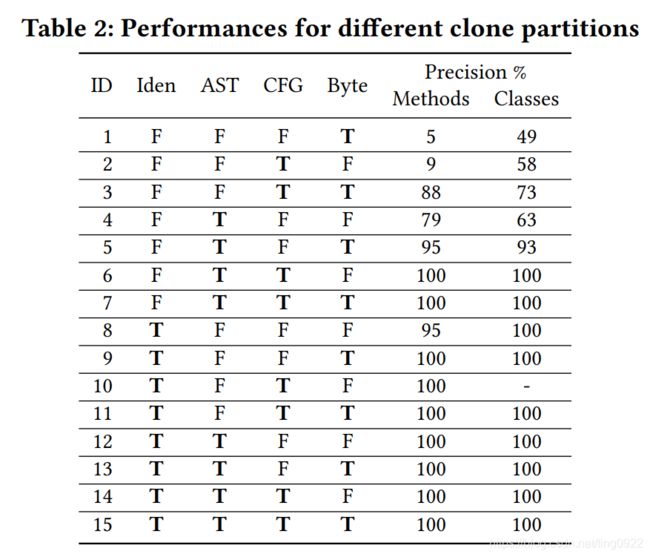
待改进的点:
- 数据集规模小,并且数据集中有多少相似的代码对没有说明
- 在进行sequence表示时,递归多层autoencoder才能得到最终的代码块表示,复杂度高,并且经过了多层,不一定准确
Learning Semantic Vector Representations of Source Code via a Siamese Neural Network
会议:CoRR 2019
作者:David Wehr, Halley Fede, Eleanor Pence, Bo Zhang, Guilherme Ferreira, John Walczyk, Joseph Hughes
机构:Iowa State University, Rensselaer Polytechnic Institute, Massachusetts Institute of Technoloigy, IBM
关键词:AST转换sequence,autoencoder预训练,代码相似度,Siamese NN
论文pdf
研究动机
自然语言技术的发展和可用的开源代码数据量巨大,所以作者希望结合nlp技术学习代码的表示。
但代码方面各任务有标签的数据量都不大,所以作者想要利用上无标签的大量代码,预训练一个RNN的网络,可用在后续特征任务上,用来学习当前代码的表示。
具体方法
本文的方法有两个部分,一部分是孪生网络,也就是用在计算两个代码块相似度的任务上,其中关注的是学到代码的语义表示,然后根据语义表示计算两个代码的相似度。这一部分的框架图如下:
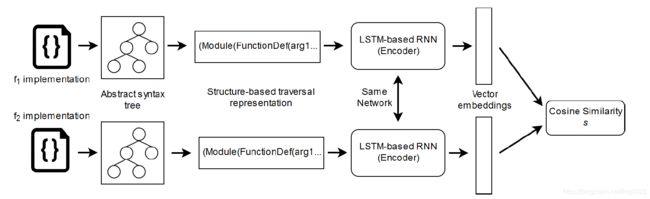
首先,给定一个代码,构建其抽象语法树AST,然后利用structure-based traversal [11](这是一种深度优先遍历的方法,基本可以保持原代码的结构信息,在构建一个子树之后,会插入分隔符,避免歧义)的方法将AST转换为序列。然后利用LSTM-based RNN处理序列,得到最后一个隐状态的表示作为该代码段的向量表示。
另一个部分是预训练,因为标注的数据量小,想要训练好网络较为困难,所以作者利用大量无标签的数据,训练LSTM-based RNN。这一部分的做法是,将LSTM-based RNN作为encoder,预训练阶段在这之后加上一个decoder,希望能够解码出输入进encoder的structure-based traversal representation。也就是一个自编码器,损失就是重建误差。这样之后,就可以学到encoder部分网络的参数。
实验部分
数据
预训练部分,使用了github上star数多于100的python代码,获取到1.3million的样本。
孪生网络部分,是利用HackerRank[21] 提供的数据,共有86个竞赛题目,每个题目包含约5000个solutions。
不足之处:
- 文中总结部分说,利用AST转换为的sequence,然后学习代码表示,学到的是代码的语义表示。这里我不太理解语义表示和结构表示的区别是什么?我觉得AST更多的是获得结构表示。
- 只包含python一种语言
Neural Code Comprehension: A Learnable Representation of Code Semantics
会议:NIPS 2018
作者:Tal Ben-Nun, Alice Shoshana Jakobovits, Torsten Hoefler
机构:ETH Zurich
关键词:representation of code semantics, LLVM IR, inst2vec, high-level task
论文pdf
研究动机
现有方法在处理代码时,是将代码视为自然语言,直接使用sequence或者语法树进行表示。这种方式忽略了结构特征,不能学到一个基于语义的鲁棒的表示。
比如:
NLP-based:将输入的代码处理为token或者其他的表示[18, 4, 7, 53],然后得到一个连续的低维空间向量。其中利用word2vec思想进行表示的方法是[47, 48],也就是基于token的邻居对其进行表示。这种模型被成功用于类似nlp的任务,比如:代码总结[6],函数名称预测[7]还有算法分类[49]。
本文内容
尽管nlp-based方法也在以上任务上取得了不错的效果,但仍然存在两个问题:1)之前的工作中,代码语言是固定的,不能泛化到其他语言中;2)利用序列化的方式处理代码,没有考虑代码结构信息。
作者提出一个基于语义的代码表示方式Neural Code Comprehension (NCC),并且不依赖于具体的编程语言。
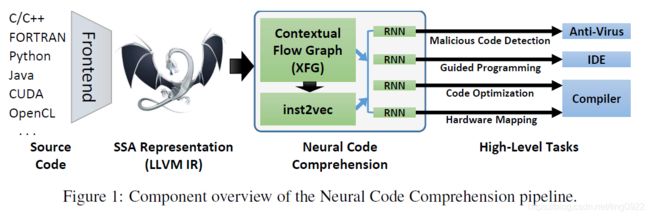
图中展示了该模型的pipeline流程。首先由源代码经过LLVM Compiler Infrastructure,得到不依赖于语言的中间表示IR;接着构建一个上下文流图contextual flow graphs (XFGs),XFGs是根据程序中的数据流和控制流来构建的,所以很自然的支持循环和函数调用的表示。XFGs也被用于训练语句的embedding,这个过程称为inst2vec(利用skip-gram方法)。然后将得到的定长embedding输入进RNN,得到的表示用于后续的任务。
在评估方面,作者从多个角度对NCC进行了评估。首先,作者评估了embedding本身的效果,也就是用t-SNE可视化了embedding。然后利用了三个high-level的任务评估了方法的性能。
数据集中包含多个语言写的CPU和GPU的代码。
作者说的贡献:
1)formulate a robust distributional hypothesis for code. 并在此基础上,基于上下文流和LLVM IR,构建了一个代码的新的分布式表示。
2)叙述了如何构建XFG,这是第一个专门为结合数据流和控制流的语言embedding而设计的。
3)利用clustering, analogies, semantic tests还有三个任务来评估代码表示。
4)使用简单的LSTM架构和预训练好的embedding,就可以和其他最好的方法相当甚至超出。
相关工作
为了根据一个token的上下文对其进行表示,一些工作依赖于lexicographical locality或者代码的结构特征,如Data Flow Graph, Control Flow Graph, AST, path in AST或者augmented AST。没有工作尝试使用compiler IRs去训练embedding。
值得借鉴的点:
- 各种语言的统一中间表示(编译层面)
- XFG结合了data and control flow
- 利用t-SNE方式可视化了embedding的结果,从embedding本身对表示方法进行评估
不足之处:
- 将代码中的所有部分都考虑在内,可能引入噪声,因为代码中有一些共有或者不重要的部分,对于表示不会有太大作用。
- 只讲了怎样进行statement的表示,没有叙述怎样对整个代码进行表示,或者说如何整合这些statement的表示,以形成一个整体表示。
- 从XFG中选出窗口大小的内容,利用skip-gram学习embedding,这种方式可以改进。
其他内容
GCC和LLVM
传统编译器
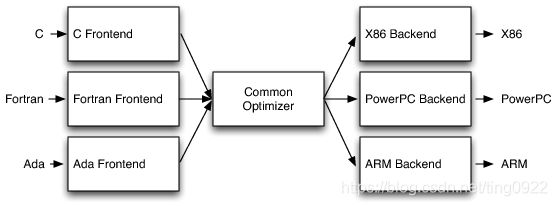
传统编译器的工作原理基本是三段式的,可以分为前端(Frontebd)、优化器(Optimizer)、后端(Backend)。前端负责解析源代码,检查语法错误,并将其转化为抽象的语法树(AST)。优化器对这一中间代码进行优化,试图使代码更高效。后端则负责将优化器优化过的中间代码转换为目标机器的代码,这一过程后端会最大化利用目标及其的特殊指令,以提高代码的性能。
事实上,不光静态语言如此,动态语言也符合上面这个模型。例如:Java。Java Virtual Machine也利用上面这个模型,将Java代码翻译为Java bytecode。
这一模型的好处是,当我们要支持多种语言时,只需要添加多个前端就可以了。当需要支持多种目标机器时,只需要添加多个后端就可以了。对于中间的优化器,我们可以使用通用的中间代码。
这种三段式的结构还有一个好处,开发前端的人只需要知道如何将源代码转换为优化器能够理解的中间代码就可以了,他不需要知道优化器的工作原理,也不需要了解目标代码的知识。这大大降低了编译器的开发难度,事更多开发人员可以参与进来。
虽然这种三段式的编译器有很多优点,但实际上这种结构从来没有被完美实现过。做的比较好的应该属Java和.Net虚拟机。虚拟机可以将目标语言转化为bytecode,所以理论上我们可以将任何语言都翻译为bytecode,然后输入虚拟机中运行。但是这一动态语言的模型并不太适合C语言,所以硬是将C语言翻译为bytecode并实现机制的效率非常低。
GCC也将三段式做的比较好,并且实现了很多前端,支持了很多语言。

更细化一些,如下图:
但是GCC有一个致命缺陷,它被设计成一个整体的应用,导致它无法被拆分成单独的库来使用,有时候我们只想使用它的某个特性,却不得不引入整个编译器的代码。这里面的原因有很多,比如内部使用了大量的全局变量、不合理的数据结构设计、大量的宏定义以避免重复编译、代码耦合度高、log不清晰不明确。
尽管这样,GCC依然是现在跨平台软件编译器的首选。
LLVM最初是Low Level Virtual Machine的缩写,定位是一个比较底层的虚拟机。它的出现正是为了解决编译器代码重用的问题。制定了LLVM IR这一中间代码表示语言。LLVM IR充分考虑了各种应用场景,例如在IDE中调用LLVM进行实时的代码语法检查,对静态语言、动态语言的编译、优化等。
LLVM与其他编译器最大的差别在于,它不仅仅是Compiler Collection,也是Libraries Collection。举个例子,比如我要写一个XYZ语言的优化器,我自己实现了PassXYZ算法,用以处理XYZ语言与其他语言共性的优化算法。那么我可以选择XYZ优化器在链接的时候把LLVM提供的算法链接进来。LLVM不仅仅是编译器,也是一个SDK。
LLVM的几大优势:
- 良好的架构设计,模块复用性高
- 引入IR(中间表示)的概念,兼容性高
- 错误和警告信息提示友好,日志文件可读性强
- 与目标语言和平台无关
- 与IDE配合良好
这里解释一下IR,LLVM编译器在传统的三层模型中加入了中介码,前端完成源码解析编译后,转成中介码,LLVM编译器针对中介码进行优化和改良,然后将中介码送入目标平台编译器生成目标代码,整个编译过程中都是中介码在参与,所以说跟目标语言和平台无关。他们的结构如下:

GUN、GCC、LLVM和Clang
GCC和LLVM
代码的中间表示IR
这方面的研究在做什么?是要研究各种语言的统一表示吗?编译优化又是如何做的?
论文中提出有PDG和Sea of Node。
Automated Vuluerability Detection in Source Code Using Deep Representation Learning
会议:ICMLA 2018(Core C)
作者:Rebecca L. Russell, Louis Kim, Lei H. Hamilton, Tomo Lazovich…
机构:Draper, Boston University
关键词:Vulnerability Detection, CNN, random forest classifier, data supplement.
论文pdf
方法
这篇文章做的是function-level vulnerability detection,并且增加了现有的这类任务的数据集规模。
方法建模:分类问题,分为两类,代码段的label分别为Vulnerable和Not vulnerable两类。
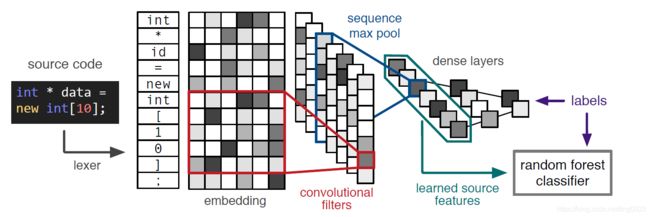
步骤为:
- 将源代码按照每一个token分解出来,然后将每一个token表示成一个k维向量,这个向量是根据分类任务训练出来的。
- 得到源代码的embedding矩阵后,利用CNN提取特征,然后进行max-pooling
- 得到的向量输入到一个全连接网络,得到的特征输入到随机森林分类器,与label进行比较,得到loss
值得借鉴的点:
- 数据集的贡献
不足之处:
- 数据集如何得到,没有看到详细说明
- 创新性不足
- 只利用到了token的信息,没有任何结构信息的加入
Hierarchical Learning of Cross-Language Mappings through Distributed Vector Representations for Code
会议:ICSE NIER 2018(短文,4页)
作者:Nghi D. Q. Bui, Lingxiao Jiang
机构:Singopore Management University
关键词:cross-language code representation, code assignment (method-level, token-level), Bilingual skip gram model, hierarchical embedding
论文pdf
研究动机
现有方法在做多语言之间的mapping的时候,分为两类。一类是基于语法规则的匹配,这类方法精确,但泛化能力不高,无法适用于定义之外的语言和规则。另一类是统计方法,需要考虑多种类型的上下文,比如数据依赖、控制依赖,共现关系等。
作者受到Neural Machine Translation(NMT)的启发,想要将代码转换为distributed representation,这样会增强泛化性。
本文方法
本文主要做的是代码的对齐,模型整体架构如下:

具体的步骤为:
- 首先根据方法名称对两个语言中的方法进行对齐
- 经过Normalization之后,进行token-level的对齐,这里用到的是Berkeley aligner工具[8]
- 利用BiSkip model学习token embedding
- 根据结构信息,从token embeding 得到method embedding
Deep Transfer Learning for Source Code Modeling
会议:IJSEKE 2020 (CCF C类)
作者:Yasir Hussain, Zhiqiu Huang, Yu Zhou, Senzhang Wang
机构:Nanjing University of Aeronautics and Astronautics
关键词:Transfer Learning, code representation, code completion task
论文pdf
研究动机
现有的深度学习方法在处理源代码问题的时候存在两个问题,一个是专为任务设计,这导致一个任务上学习好的模型,很难用于其他任务,在做其他相关任务的时候,也需要从头开始训练一个模型。另一个问题是需要大量标注数据。
作者希望通过迁移学习,预训练出一个通用的模型,学习代码的表示。在用于特定任务的时候,可以通过微调的方式,以较少的标注数据,取得不错的效果。
本文方法
文章中提出的方法的整体架构如下:
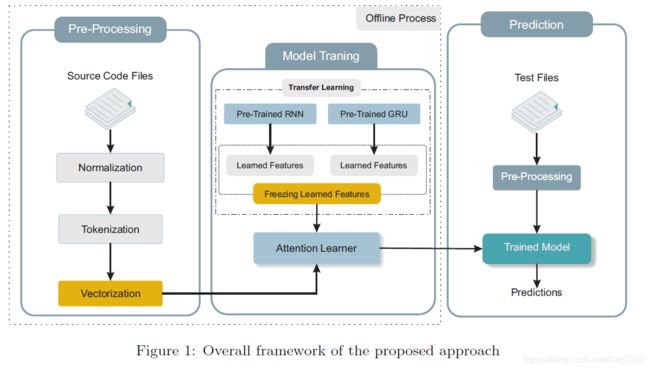
预训练和微调的过程图示如下(我的理解是在预训练阶段学习的是embedding和RNN、GRU的网络参数,然后固定住,微调阶段是改变后面部分的网络参数):

整个预训练和微调的总结如下:
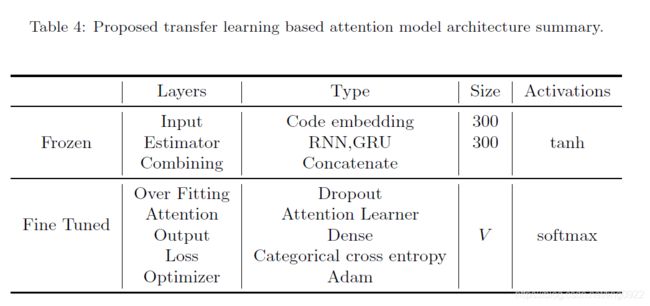
PathMiner: A Library for Mining of Path-based Representations of Code
会议:MSR 2019 (IEEE/ACM 16th International Conference on Mining Software Repositories, CCF C类)
作者:Vladimir Kovalenko, Egor Bogomolov, Timofey Bryksin, Alberto Bacchelli
机构:Delft University of Technology, JetBrains Research, University of Zurich
关键词:Path extraction tools, AST paths, code2vec
论文pdf
研究动机
在之前的研究中,有工作验证了path-based representation的方式能够很好的获取到代码的结构语义,据此对代码进行表示,在一些下游任务有性能的提升。
虽然有工作是在做给定代码,基于AST提取paths,然后进行代码表示。但没有这方面的toolkit,导致一些研究人员在做下游任务的时候,需要自己去实现这部分代码,也给初学者增加了难度。所以作者想要实现这样一个toolkit,给定不同编程语言的代码,经过解析和提取path,输出类似code2vec中的path格式(path中的terminal node和中间路径都是由index表示)
本文内容
整体架构如下:
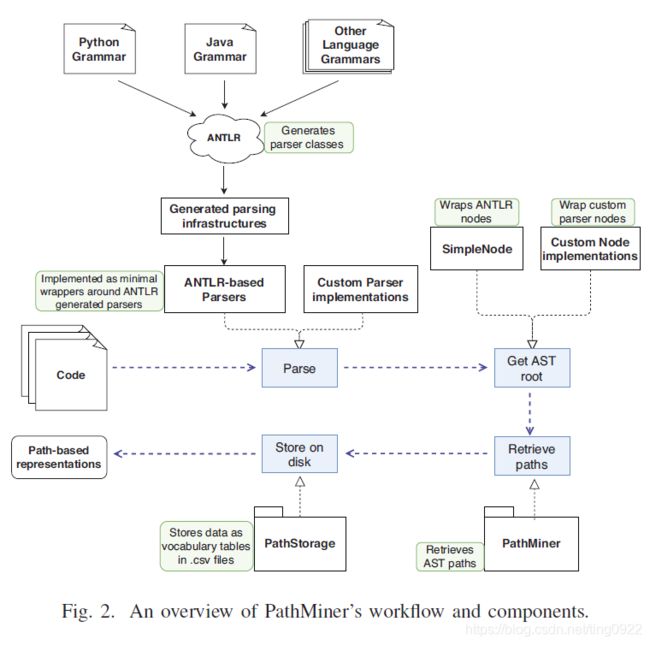
这样一个工具主要分为三个部分:Parsing(从代码到AST),Extracting paths(从AST中提取符合height和width要求的path),Output(输出的内容如下图所示,保存在csv文件中)

文中作者对这三个部分对应的代码给出了介绍。其中,对于一种新的语言,需要自己将该语言的解析器进行特定的一些操作,以生成对应的AST。开源代码链接:https://github.com/JetBrains-Research/astminer/tree/pathminer
code2vec: Learning Distributed Representations of Code
会议:POPL 2019 (软件工程/系统软件/程序设计语言 CCF A类)
作者:Uri Alon, Meital Zilberstein, Omer Levy, Eran Yahav
机构:Technion, Facebook AI Research
关键词:code representation, method’s name prediction, AST path, path-based attention
论文pdf
demo url
code url
研究动机
这篇文章主要是在做方法名预测,所以做的是method-level representaion。首先是将代码块表示成一个定长的向量,然后预测该代码块的方法名称是什么。
在此之前的方法要么是手动提取特征,要么是直接使用AST结构特征。但AST中的每一条路径对于预测方法名的重要性是不同的,所以作者给每一条路径不同的权重,学习到一个更高效的代码表示。
本文方法
本文提出path-based attention的方法,计算从AST中提取出来的每一条path的权重,然后将各条path的表示按照权重相加,得到整个代码块的表示,最终经过一层神经网络进行方法名的预测。
整体的架构图如下:
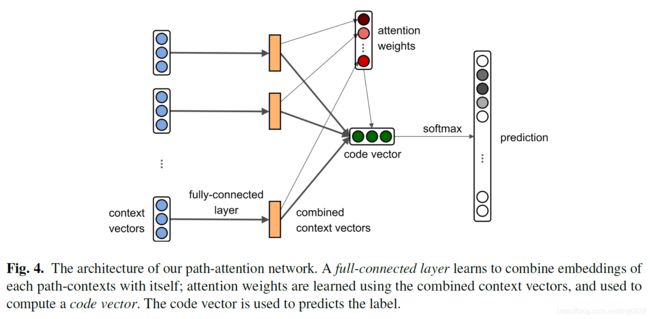
具体的步骤为:
-
给定源代码片段,解析为AST
-
从AST中提取path,每一条path都是从一个terminal node 到另一个terminal node 的路径。path不仅记录了经过的节点标识,还记录了从当前节点到下一个节点是自底向上还是自顶向下,用上下箭头表示。
图示如下(截于:PLDI18 A General Path-Based Representation for Predicting Program Properties)
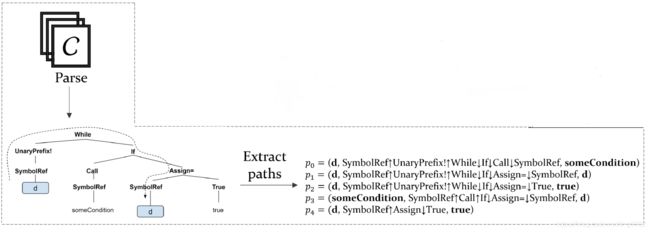
-
接下来,要对path进行向量表示,其中涉及到三个部分,分别是源节点的向量表示、中间路径的表示、终止节点的向量表示。将这三部分拼接,得到整个代码块的表示。
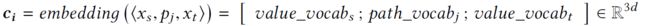
其中,terminal node和中间路径的表示是分别从两个矩阵中提取出来的,这两个矩阵在训练过程中学习得到。(也就是说,一个矩阵学习的是每一个terminal node的表示,维度为:|terminal node| * d;另一个矩阵学习的是每一个中间路径(不包括源节点和终止节点)的表示,维度为|中间路径| * d) -
经过一个全连接层,将terminal node 和中间路径的表示结合起来
-
目前每个完整的path有一个向量表示,然后计算每一个path的attention weight
-
将每一个完整path的表示乘以attention weight,再相加,得到最终的code vector
-
经过一层神经网络和softmax,得到预测为每个方法名的概率
实验部分
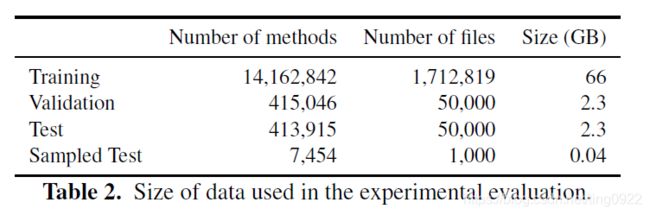
数据集
dataset of 10072 Java Github repositories, originally introduced by Alon et al.[2018]
数据集规模如下:
实验评估
- 实验验证了该方法的性能、训练时间,均优于三个baselines(CNN+attention, LSTM+attention, Paths+CRFs)
- 消融实验,比较了No-attention, Hard-attention以及本文的attention方法的性能
- 消融实验,验证了完整path中的三部分内容的必要性
- attention的解释性、通过方法名之间的实际关系和他们之间的向量计算得到的关系进行对比,得到了该方法学到的表示是能够表达出语义特征的。
值得借鉴的点:
- AST path的提取
- path-based attention
- 有demo和开源代码
不足之处:
- 较大的方法,path的数量会很大。且总体的稀疏性高(每两个terminal node pair之间的path 都不一样,即使共享了很多中间节点)
- path embedding是直接从path embedding matrix中提取出来的,直接学习path的表示,而不关注path中的节点信息,这一点也造成了path稀疏性和path embedding matrix的规模较大。
- 方法名标签词典是封闭的,也就是当有一个新的方法名不在词典中,就不可能预测出来
- 有些terminal node pair 不需要有path,比如每个代码几乎都有的部分。虽然attention能够给这些path低权重,但仍然存在一些噪音。
- 本文是method-level的表示,对于一个文件内部,多个method,它们之间存在调用关系的话,无法对文件进行表示。
其他内容
这篇文章是在该作者之前发表的一篇文章的基础上修改的,那篇文章是《PLDI18 A General Path-Based Representation for Predicting Program Properties》,其中的AST path就是在这篇文章中提出的。
本文的改进在于,path-based attention,使得每个path的权重不同。之前的方法是直接用CRF或者word2vec方法进行预测的。
Code Representation 数据集
BigCloneBench
DeepAM: Migrate APIs with Multi-modal Sequence to Sequence Learning
会议:IJCAI 2017
作者:Xiaodong Gu, Hongyu Zhang, Dongmei Zhang, Sunghun Kim
机构:The Hong Kong University of Science and Technology, The Univeristy of Newcastle, Microsoft Research
关键词:seq2seq learning architecture,automatic mining APIs mappings
论文pdf
研究动机
软件开发过程中,API在各语言之间的迁移是非常重要的。比如利用Java语言开发了一个API,同样也想要在python语言下实现同样功能的API。但人工迁移费时费力,现有的迁移工具也不能完全满足要求。所以作者想要开发一个能够自动完成API在各语言之间迁移的工具。
现有的工具包括:Java2CSharp,StaMiner (Nguyen et al. 2014) …
这些工具存在一些挑战:
- 需要人工定义一些mapping rules
- 现有mapping的数据量小,比如:作者收集从2008年到2014年Github上的11K个Java项目,其中仅有15个是人工迁移到C#版本了。
基于这些挑战,作者提出DeepAM,他将两种语言的API sequence都表示为同样维度的向量,并且认为如果两个API sequence有相似的embedding,那么它们对应的自然语言描述也是类似的。这样就可以通过自然语言描述,为两个语言的API sequence建立连接。从而自动学习mapping rules。
方法介绍
本文的目标是学习一个从source API sequence 到 target API sequence的映射。 A S \mathcal{A_S} AS表示source API sequences的集合, A T \mathcal{A_T} AT表示target API sequences的集合。学习的映射如下:
f : A S → A T f: \mathcal{A}_{S} \rightarrow \mathcal{A}_{T} f:AS→AT
但因为 A S \mathcal{A_S} AS和 A T \mathcal{A_T} AT是异构的,所以很难直接学习上面的映射关系。
如果将API和对应的自然语言描述联系起来,那么就可以通过以下的方式学习mapping:
A S → ϕ V → τ D ← τ V ← ψ A T \mathcal{A}_{S} \stackrel{\phi}{\rightarrow} V \stackrel{\tau}{\rightarrow} \mathcal{D} \stackrel{\tau}{\leftarrow} V \stackrel{\psi}{\leftarrow} \mathcal{A}_{T} AS→ϕV→τD←τV←ψAT
其中,V表示API sequence的向量空间,D表示自然语言描述。
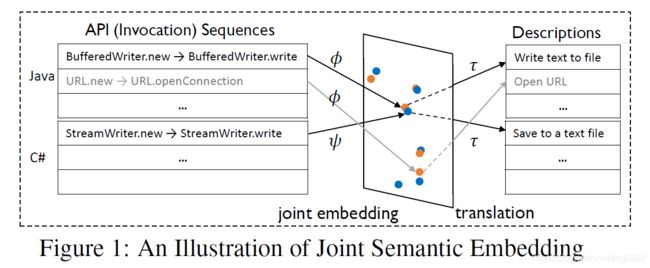
模型整体的架构如下:

具体操作步骤为:
-
首先从代码语料库中抽取API sequence,并且自动将API sequence和对应的代码注释对齐。形成
的数据对。
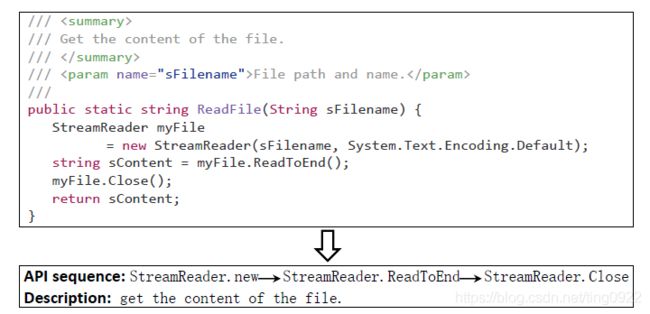
-
利用seq2seq架构,将每一个API sequence表示为定长的向量。(通过jointly embedding将source API sequence和target API sequence映射到同样的向量空间)
-
将source API sequence和target API sequence中向量最相似的API sequence进行对齐。
-
根据这些已经对齐的API sequence对,利用SMT(Statistical Machione Translation)学习通用的API mapping。
值得借鉴的点:
- 数据集:通过在各编程语言的语料中收集
对,然后利用描述将两种语言的API sequence联系起来。克服了之前研究工作中,没有充足的mapping数据的问题。最终收集到9880169个 对,其中java pairs有5271526个,C# pairs有4608643个。 - 自动学习映射规则,而不用人工定义
不足之处:
-
学到的是API sequence的mapping,但最终目标是每一个API的mapping。文中使用统计方法,用API的共现概率大于阈值0.5来得到终mapping结果。这种方式存在学习和目标的偏差。
共现概率的计算是:p(t | s) = count(s, t) / (count(s) + 1) -
利用seq2seq学习API sequence的表示,当API sequence中的API个数很少时,学习的效果不佳。从实验中也可以看出,当API sequence的长度为1时,DeepAM方法比baseline方法表现要差很多。但在长度增加后,效果逐渐变好。
A Novel Neural Source Code Representation Based on Abstract Syntax Tree
会议:ICSE 2019
作者: Jian Zhang, Xu Wang, Hongyu Zhang, Hailong Sun, Kaixuan Wang, Xudong Liu
机构: Beihang University, The University of Newcastle
论文pdf
主要内容:这篇文章做的主要是代码表示,研究表明,基于AST的神经模型能更好的表示源代码。但AST规模通常较大,现有的模型会出现长期依赖问题。所以作者提出一种新的基于AST的神经网络,叫做ASTNN。将每个AST划分为一系列小的语法树,并通过捕获语句的词法和语法知识将语法树编码为向量。
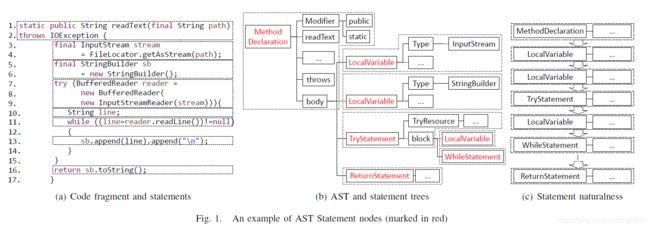
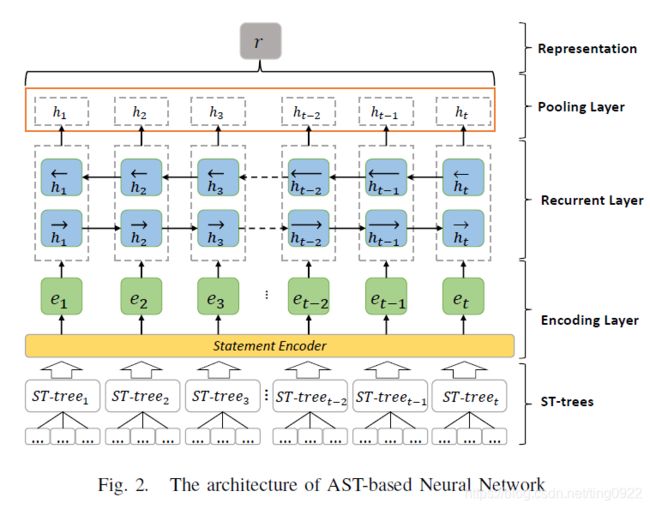
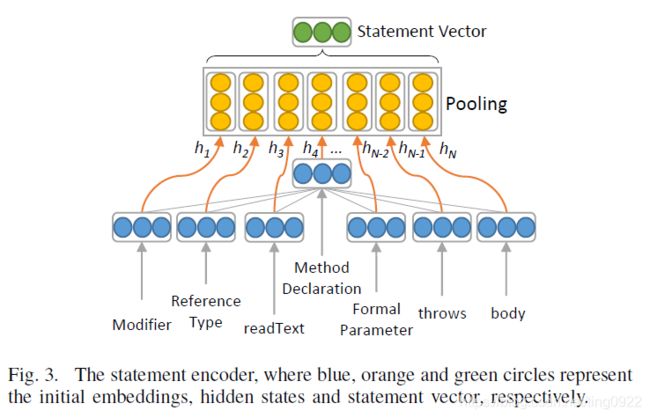
做法主要是,先将代码转换为AST,然后根据AST划分成多个小的部分,也就是多个子树,将每个子树输入进Statement Encoder,得到每个子树的表示,然后经过RNN,再经过pooling,得到代码的表示。
该方法主要是用在两个任务上,一个是Source Code Classification,另一个是Code Clone Detection。分别有两个公开的数据集:Mou等人提出的OJ上的数据集,BigCodeBench。
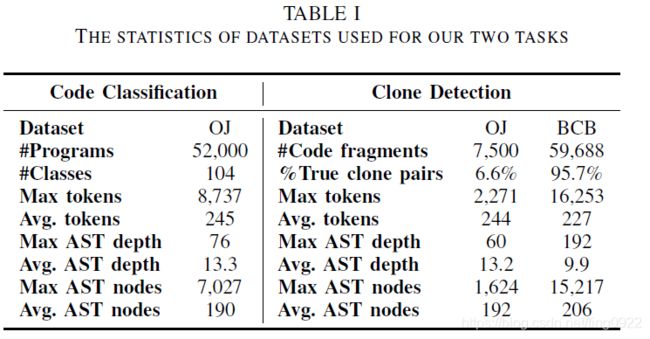
这两个数据集对应着两种语言,分别是C和java。文中分别用pycparser和javalang tools将它们解析成AST。这两个工具都有链接,可用。
在将节点的embedding结合表示成整个代码的embedding时,是利用max-pooling的方式,找到节点在每个维度上的最大值,保存下来,作为整个代码的embedding,再进行后续的任务。
Learning-based Recursive Aggregation of Abstract Syntax Trees for Code Clone Detection
会议:SANER 2019
作者:Lutz Buch, Artur Andrzejak
机构:Heidelberg University
关键词:code clone detection, Abstract syntax trees, tree-LSTM, pre-trained embedding
论文pdf
研究动机
本文做的是代码克隆检测的任务,主要解决了两个问题,分别是:
- clone pair 和 non-clone pair两个类别样本数量不均衡;
- 由节点表示到整个代码的表示的高效聚合。
此外,文中有大量篇幅在做验证性的工作,包括:
- 验证预训练AST中节点对于性能的影响,得出预训练的重要性;
- 通过clone cluster精细划分训练集和测试集的重要性。
主要方法
模型整体是一个孪生网络的架构,网络的输入是一个code pair,每个code pair也对应一个标签:clone/non-clone。孪生网络的两边分别对两个代码进行处理,得到该段代码的表示,然后根据cosine相似度计算两个向量的相似度,再根据误差反向传播,调整模型中的参数。
模型架构如图:

具体步骤为:
- 首先将代码转换为AST(作者对于AST做了一些调整,使其成为一个二叉树)
- 利用Recursive NN处理AST(如上右图所示),每个节点的表示由三部分组成,是:孩子节点的表示、该节点自己的类型表示、该节点自己的内容表示(后两部分的表示是预训练得到的,用的时候直接通过lookup取出)
- 最终,一个AST根节点的表示被视为该AST的整体表示,也就是整段代码的表示
- 得到了两段代码的表示后,通过定义的损失函数计算损失(这里的目标是希望label为clone的代码对的表示尽可能相似,label为non-clone的代码对相似度更低)
- 误差反向传播,调整参数。
针对clone pair 和 non-clone pair两个类别样本数量不均衡的问题,作者提出error scaling的方法,也就是将non-clone pair得到的误差除以该类样本数量,以起到减少因为负样本数量大而造成的误差大的问题。
针对节点表示到整个代码表示的高效聚合方法,这里作者说的是提出了一种非线性的聚合方法,也就是上文中的Recursive NN层次的处理AST,最终整合所有节点的表示到根节点。
这里用到的克隆检测数据集是BigCloneBench。
不足之处:
- 动机不强
- 为了模型处理的需要,将AST处理为二叉树,损失一部分信息
- 针对AST中的节点表示预训练,基本是使用word2vec的方法,其中做出了一点改动,无法验证改动的有效性
SAR: Learning Cross-Language API Mappings with Little Knowledge
FSE 2019
作者:Nghi D. Q. Bui, Yijun Yu, Lingxiao Jiang
机构:Singapore Management University, The Opern University
关键词:Cross-Language API Mapping, GAN, domain adaption, word embedding, vector space alignment
论文pdf
Motivation
自动实现不同语言的API之间的转化,对于开发者而言是非常实用的。这意味着开发者只需要用一种语言编写API,当需要在其他语言上应用时,直接通过转换的方式,将该API 匹配到其他语言的API。
现有的方法在实现API mapping任务时,基本是通过大量的平行语料(语料中包含源语言API和匹配的目标语言API),学习一个映射关系。
但是平行语料的数量是比较少的,所以,较难学习到一个好的映射。
作者提出:Can a model to built to minimize the need of parallel data to map APIs across languages?
作者利用领域自适应(domain adaptation)的思想,通过少量的平行语料,即可超越其他用到大量平行语料的方法。
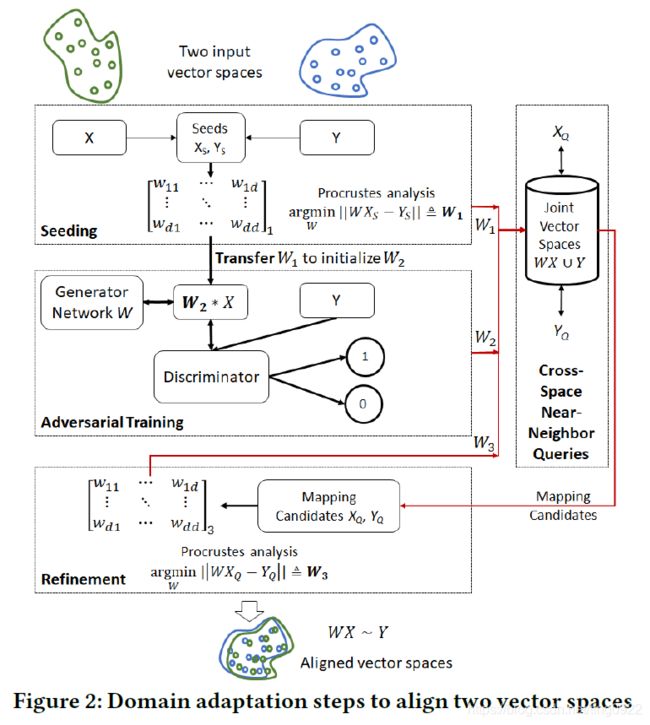
Domain Adaption
Domain Adaption的目标是学习一个映射矩阵,该映射矩阵与源语言的API embedding相乘(相当于进行转换)就得到了目标语言embedding空间上的表示。
领域自适应的方法可以分为两类:seed-based(有监督的) 和 无监督的。
Seed-based Domain Adaptation
对于两种语言 L 1 L_1 L1和 L 2 L_2 L2来说, X = x 1 , x 2 , ⋯ , x n , Y = y 1 , y 2 , ⋯ , y m X = {x_1, x_2, \cdots, x_n}, Y={y_1, y_2, \cdots, y_m} X=x1,x2,⋯,xn,Y=y1,y2,⋯,ym 表示两种语言的向量空间。
seed指的是功能相同的源语言API和目标语言API的集合 ( x s i , y s i ) s i ∈ { 1 , ∣ S ∣ } {(x_{s_i}, y_{s_i})}_{s_i \in \{1, |S|\}} (xsi,ysi)si∈{1,∣S∣}。
学习的目标函数是:
W ∗ ≜ a r g m i n W ∈ M ⊂ R d × d ∣ ∣ W X S − Y S ∣ ∣ W^* \triangleq argmin_{W \in M \subset R^{d \times d} } ||WX_S - Y_S|| W∗≜argminW∈M⊂Rd×d∣∣WXS−YS∣∣
目标函数表达的意思是:通过最小化目标函数,学到一个映射矩阵W,通过映射矩阵对 X S X_S XS进行转换,希望转换后的表示与 Y S Y_S YS的表示尽可能相近。
Unsupervised Domain Adaptation
无监督的方式学习映射矩阵,是通过GAN来做的【可参考GAN做机器翻译的工作[1]】
判别器和生成器的设计为:
- 生成器的目标是学到真实数据的分布,并且产生假的数据去蒙骗判别器。这里是要学到一个映射矩阵,参数即W。
- 判别器相当于一个分类器,以全连接神经网络为模型结构,参数为 θ D \theta_D θD。
判别器的目标函数为:
L D ( θ D ∣ W ) = − ∑ i = 1 n log P θ D ( source = 1 ∣ W x i ) − ∑ i = 1 m log P θ D ( source = 0 ∣ y i ) L_{D}\left(\theta_{D} \mid W\right)=-\sum_{i=1}^{n} \log P_{\theta_{D}}\left(\operatorname{source}=1 \mid W x_{i}\right)-\sum_{i=1}^{m} \log P_{\theta_{D}}\left(\operatorname{source}=0 \mid y_{i}\right) LD(θD∣W)=−i=1∑nlogPθD(source=1∣Wxi)−i=1∑mlogPθD(source=0∣yi)
生成器的目标函数为:
L W ( W ∣ θ D ) = − ∑ i = 1 n log P θ D ( source = 0 ∣ W x i ) − ∑ i = 1 m log P θ D ( source = 1 ∣ y i ) L_{W}\left(W \mid \theta_{D}\right)=-\sum_{i=1}^{n} \log P_{\theta_{D}}\left(\operatorname{source}=0 \mid W x_{i}\right)-\sum_{i=1}^{m} \log P_{\theta_{D}}\left(\operatorname{source}=1 \mid y_{i}\right) LW(W∣θD)=−i=1∑nlogPθD(source=0∣Wxi)−i=1∑mlogPθD(source=1∣yi)
从目标函数中可以看出,在给定映射矩阵W时,判别器试图分辨一个向量表示是源语言的API embedding,还是由生成器的映射参数转换而来的向量表示。在给定判别器参数时,生成器试图更新W,使得源语言的API embedding经过映射,就可以让判别器认为它是目标语言的API embedding。
Methods
以上的两种Domain Adaptation的方法有一定的缺陷:
- Seed-based domain adaptation: 需要大量的平行语料,才能学到一个不错的映射矩阵
- Unsupervised domain adaptation: 虽然不需要平行语料当做种子,但是两个向量空间的分布不一定相同,所以最终不一定可以优化到一个最优解。
作者认为如果给无监督对抗训练方法一个较好的初始化映射矩阵,会提升模型的性能。所以,作者结合了这两种方式的优点,首先通过少量种子,学到一个初始的映射矩阵。然后将这个映射矩阵作为对抗训练的初始化映射矩阵,在两种语言的大量非平行语料上训练,得到更新后的映射矩阵。
模型的架构如下:
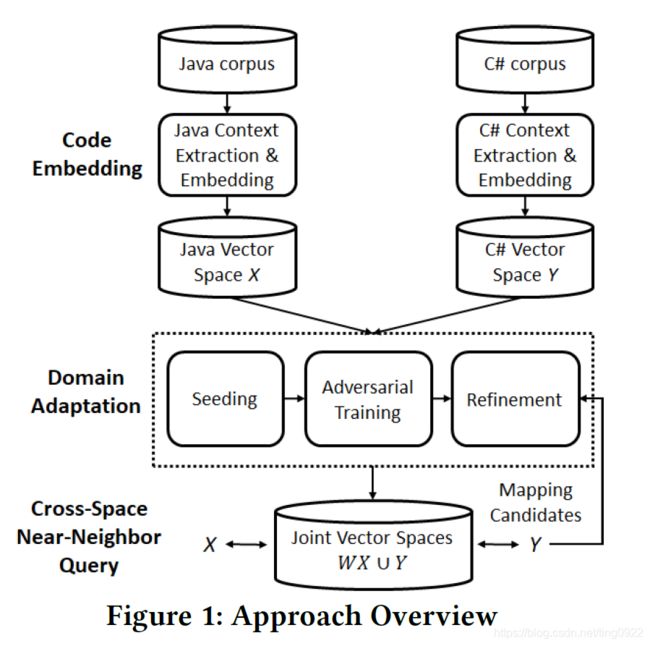
模型主要分为三个部分:
-
code embedding
将代码转换为AST,再通过先序遍历,得到一个序列,利用word2vec方法学到embedding -
Domain adaptation
- 通过一些种子语料,根据图中的损失函数,学到一个初始的映射矩阵 W 1 W_1 W1
- 通过对抗学习,结合上面判别器和生成器的目标函数,得到更新后的映射矩阵 W 2 W_2 W2
-
refinement模块
对抗学习过程中,没有考虑到API出现的频率,作者认为两种语言中常出现的API更有可能匹配上。所以,作者设计了refinement模块。
首先找到两种语言中top-k个频繁出现的API,然后利用cosine相似度计算API embedding之间的距离,通过一个阈值选取相似度较高的API pair,作为候选(相当于前面的种子),根据图中的损失函数,更新映射矩阵 W 3 W_3 W3。【此过程迭代进行】
值得借鉴的点:
- 结合两种domain adaptation方法的优点,利用少量的平行语料即可达到最优的匹配性能。实验验证了给无监督对抗训练一个较好的初始化参数,对于模型性能有较大的提升。
- refinement的设计有利于出现频率较高的API之间的映射。
不足之处:
- 学习AST token的表示方式有待改进,未考虑结构信息
- 有些API有自然语言的描述信息,如果两个自然语言的描述相似,那么这两个API也有很大概率是相似的。这种信息没有利用上。
相关文章
[1] Alexis Conneau, Guillaume Lample, Marc’Aurelio Ranzato, Ludovic Denoyer, and Herve Jegou. 2017. Word Translation Without Parallel Data. CoRR abs/1710.04087(2017). arXiv:1710.04087 http://arxiv.org/abs/1710.04087
DeepBugs:A Learning Approach to Name-based Bug Detection
OOPSLA,2018 (CCF A)
作者:MICHAEL PRADEL, KOUSHIK SEN
机构:TU Darmstadt, University of California
关键词:bug detection, incorrect code generation, semantic representation of name
论文pdf
code
slides
video
Motivation
本文的目标是自动学习bug检测器。流程如下:
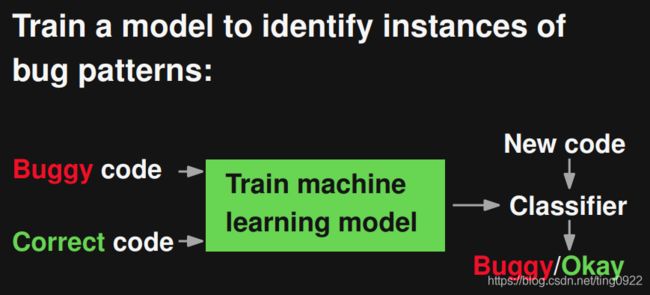
其中的关键问题是怎样得到大量的正负样本,正样本的获取相对简单,但较难收集到有bug的负样本。所以,作者想要通过代码语料自动生成正负样本,并且实验部分验证了这样做的可行性。作者将在自动生成的正负样本上训练得到的模型,用来预测真实世界中的代码是否有bug,取得了很好的结果。
第二个关键问题是作者认为代码中的变量命名等,包含很多信息。但是目前的bug detection工作,有的没有利用到这方面信息,有的仅关注变量的词法上的相似,比如:len和length有公共的子串,则认为他们相似,而认为length和count是不相似的,但是它们在语义方面是相似的。所以作者提出基于语义的变量表示。
本文主要关注三类bug,如下图所示:

Methods
模型整体流程如下:
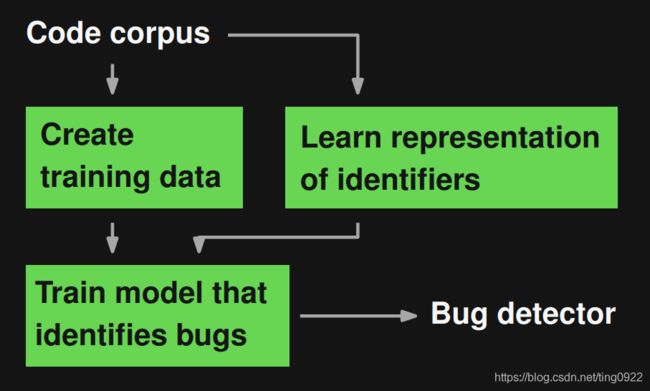
本文将bug检测问题建模为二分类问题,即判断一段代码是否有bug。
其中关键的两个部分是:Create training data 和 Learn representation of identifiers
Create training data
对于本文要检测的三种bug,每种bug有不同的错误样本生成的方式,这里以swapped arguments为例,主要做法是:将代码转换为AST,获取AST中有两个以上参数的函数调用,将其中的参数调换位置,即可生成此类错误的数据。

Learn representation of identifiers
作者所说的学习基于语义的变量表示,是获取identifier的上下文,然后利用CBOW学习identifier的表示。
上下文是指AST-based context,其中包括该identifier的parent, grand parent, sibling等,以及节点的类型,节点内容,还有相对位置的编码。
值得借鉴的点:
- 基于AST结构生成错误代码的方式,较合理。
不足之处:
- 对于每一种bug 都需要训练一个分类器
- 将bug检测问题建模为二分类问题,无法对bug进行定位
Graph4Code: A Machine Interpretable Knowledge Graph for Code
arxiv 2021
Ibrahim Abdelaziz, Julian Dolby, James P. McCusker, Kavitha Srinivas
构建了一个代码和自然语言描述相关联的知识图谱,文中提供了几种该知识图谱的用法(SPARQL查询)
Graph4Code构建过程:
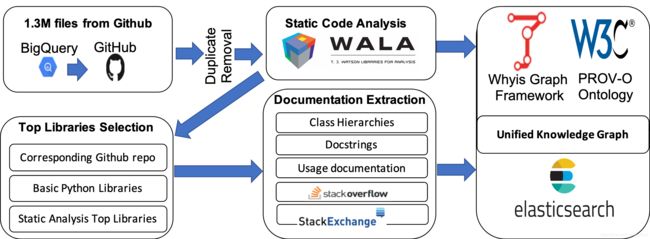
通过BigQuery获取Github上的1.3M python files,经过去重操作。
通过WALA对代码进行静态切片分析,
(程序切片:旨在程序中提取满足一定约束条件的代码片段,是一种用于分解程序的程序分析技术,被用于软件理解、维护和安全性分析等)