目标检测的Tricks | 【Trick7】数据增强——Mosaic(马赛克)
如有错误,恳请指出。
在之前的博客中也有提及到mosaic这种数据增强,然后用这篇博客来进行详细介绍。
文章目录
- 1. Mosaic概要介绍
- 2. Mosaic算法步骤
- 3. Mosaic实现代码
- 4. Mosaic代码说明
1. Mosaic概要介绍
mosaic是yolov4提出的一个tricks,其思路就是将四张图片进行随机裁剪,再拼接到一张图上作为训练数据。这样做的好处是丰富了图片的背景,并且四张图片拼接在一起变相地提高了batch_size,在进行batch normalization的时候也会计算四张图片,所以对本身batch_size不是很依赖,单块GPU就可以训练YOLOV4。

Mosaic数据增强方法有一个优点:拥有丰富检测目标的背景,并且在BN计算的时候一次性会处理四张图片
2. Mosaic算法步骤
- 在 [img_size x 0.5 : img_size x 1.5] 之间随机选择一个拼接中心的坐标(xc, yc)。需要注意的是这里的img_size是我们需要的图片的大小, 而mosaic初步增强得到的图片的shape应该是2倍的img_size.
- 从 [0, len(label)-1] 之间随机选择3张图片的index, 与传入的图片index共同组成4张照片的集合indices.
- for 4张图片:
- 如果是第一张图片,就初始化mosaic图片img4
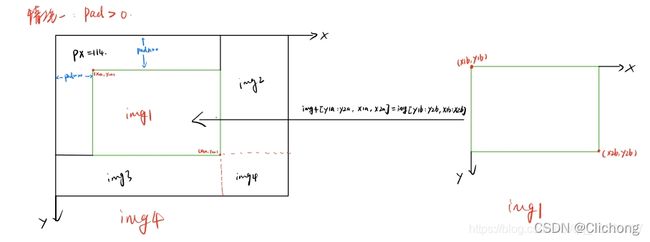
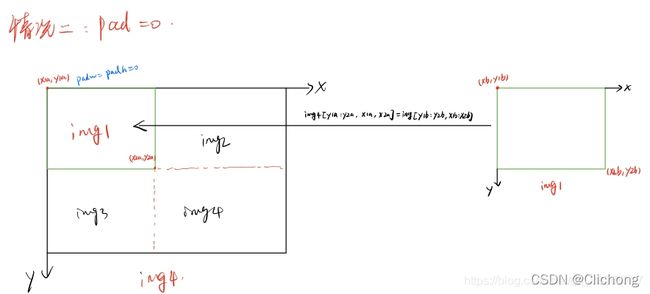
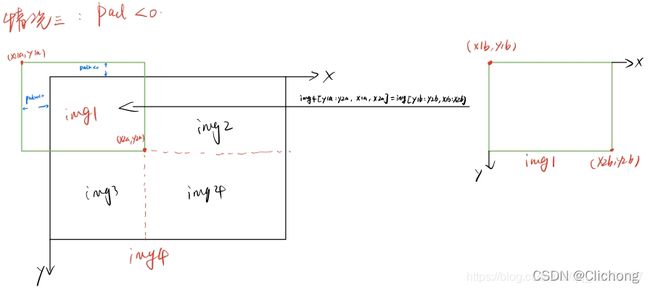
- 得到mosaic图片的坐标信息(这个坐标区域是用来填充图像的):左上角(x1a, y1a), (x2a, y2a)右下角
- 得到截取的图像区域的坐标信息:(x1b,y1b)左上角 (x2b,y2b)右下角
- 将图像img的【(x1b,y1b)左上角 (x2b,y2b)右下角】区域截取出来填充到马赛克图像的【(x1a,y1a)左上角 (x2a,y2a)右下角】 注:这里的填充有三种可能的情况,后面会仔细的讨论。
- 计算当前图像边界与马赛克边界的距离,用于后面的label映射
- 拼接4张图像的labels信息为一张labels4
- Concat labels4与clip labels4, 以防止其越界
- 其他的数据增强,random_affine仿射变换(affine Augment),将img4[2 x img_size, 2 x img_size, 3]=>img4 [img_size, img_size, 3],到这里就得到了img4[img_size, img_size, 3]
- 最后retrun img4[img_size, img_size, 3] 和 labels4(相对img4的)
补充:4张图片进行拼接的时候,通常会出现如下三种情况,分别是pad>0(此时存在空缺补丁) | pad=0(刚好吻合,出现情况比较少) | pad<0(贴过来的图像比较大,不需要补丁)
3. Mosaic实现代码
YOLOv3-SPP代码:
# 根据index索引来导入图像
# 返回:图像本身,图像的原始宽高,图像改变后的宽高
def load_image(self, index):
# loads 1 image from dataset, returns img, original hw, resized hw
img = self.imgs[index]
# 没有缓存
if img is None: # not cached
# 根据index索引从路径列表中获取当前图片的路径: eg: './my_yolo_dataset/train/images/2009_002404.jpg'
path = self.img_files[index]
# 根据路径读取图像,cv会读取成BGR格式, img.shaoe: (333, 500, 3)
img = cv2.imread(path) # BGR
assert img is not None, "Image Not Found " + path
# 获取图像的原始宽高
h0, w0 = img.shape[:2] # orig hw
# self.img_size 设置的是预处理后输出的图片尺寸, 这里设置为736
r = self.img_size / max(h0, w0) # resize image to img_size
# 如果图像的宽高与self.img_size不一致,则将较长边设置为self.img_size, 较短边按比例缩放
# 缩放比例为: (int(w0 * r), int(h0 * r))
if r != 1: # if sizes are not equal
# interp = cv2.INTER_LINEAR
interp = cv2.INTER_AREA if r < 1 and not self.augment else cv2.INTER_LINEAR
img = cv2.resize(img, (int(w0 * r), int(h0 * r)), interpolation=interp)
# 返回:图像本身,图像的原始宽高,图像改变后的宽高
return img, (h0, w0), img.shape[:2] # img, hw_original, hw_resized
# 从缓存中直接读取
else:
return self.imgs[index], self.img_hw0[index], self.img_hw[index] # img, hw_original, hw_resized
# 使用mosaic来实现数据增强
def load_mosaic(self, index):
"""
将四张图片拼接在一张马赛克图像中
:param self:
:param index: 需要获取的图像索引
:return: img4: mosaic和仿射增强后的一张图片
labels4: img4对应的target
"""
# loads images in a mosaic
labels4 = [] # 用于存放拼接图像(4张图拼成一张)的label信息
s = self.img_size # s=736
# 随机初始化拼接图像的中心点坐标 [s*0.5, s*1.5]之间随机取2个数作为拼接图像的中心坐标
xc, yc = [int(random.uniform(s * 0.5, s * 1.5)) for _ in range(2)] # mosaic center x, y (xc, yc)=(989, 925)
# 从dataset中随机寻找三张图像进行拼接 [14, 26, 2, 16] 再随机选三张图片的index
indices = [index] + [random.randint(0, len(self.labels) - 1) for _ in range(3)] # 3 additional image indices
# 遍历四张图像进行拼接 4张不同大小的图像 => 1张[1472, 1472, 3]的图像
for i, index in enumerate(indices):
# load image # 每次拿一张图片 并将这张图片resize到self.size(h,w)
img, _, (h, w) = load_image(self, index)
# place img in img4
if i == 0: # top left 原图[375, 500, 3] load_image->[552, 736, 3] hwc
# 创建马赛克图像 [1472, 1472, 3]=[h, w, c]
img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # only_yolov3 image with 4 tiles
# 计算马赛克图像中的坐标信息(将图像填充到马赛克图像中) w=736 h = 552 马赛克图像:(x1a,y1a)左上角 (x2a,y2a)右下角
x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
# 计算截取的图像区域信息(以xc,yc为第一张图像的右下角坐标填充到马赛克图像中,丢弃越界的区域) 图像:(x1b,y1b)左上角 (x2b,y2b)右下角
x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
elif i == 1: # top right
# 计算马赛克图像中的坐标信息(将图像填充到马赛克图像中)
x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
# 计算截取的图像区域信息(以xc,yc为第二张图像的左下角坐标填充到马赛克图像中,丢弃越界的区域)
x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
elif i == 2: # bottom left
# 计算马赛克图像中的坐标信息(将图像填充到马赛克图像中)
x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
# 计算截取的图像区域信息(以xc,yc为第三张图像的右上角坐标填充到马赛克图像中,丢弃越界的区域)
x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, max(xc, w), min(y2a - y1a, h)
elif i == 3: # bottom right
# 计算马赛克图像中的坐标信息(将图像填充到马赛克图像中)
x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
# 计算截取的图像区域信息(以xc,yc为第四张图像的左上角坐标填充到马赛克图像中,丢弃越界的区域)
x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
# 将截取的图像区域填充到马赛克图像的相应位置 img4[h, w, c]
# 将图像img的【(x1b,y1b)左上角 (x2b,y2b)右下角】区域截取出来填充到马赛克图像的【(x1a,y1a)左上角 (x2a,y2a)右下角】区域
img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
# 计算pad(当前图像边界与马赛克边界的距离,越界的情况padw/padh为负值) 用于后面的label映射
padw = x1a - x1b # 当前图像与马赛克图像在w维度上相差多少
padh = y1a - y1b # 当前图像与马赛克图像在h维度上相差多少
# Labels 获取对应拼接图像的labels信息
x = self.labels[index]
labels = x.copy() # 深拷贝,防止修改原数据
if x.size > 0: # Normalized xywh to pixel xyxy format
# 计算标注数据在马赛克图像中的
# w * (x[:, 1] - x[:, 3] / 2): 将相对原图片(375, 500, 3)的label映射到load_image函数resize后的图片(552, 736, 3)上
# w * (x[:, 1] - x[:, 3] / 2) + padw: 将相对resize后图片(552, 736, 3)的label映射到相对img4的图片(1472, 1472, 3)上
labels[:, 1] = w * (x[:, 1] - x[:, 3] / 2) + padw
labels[:, 2] = h * (x[:, 2] - x[:, 4] / 2) + padh
labels[:, 3] = w * (x[:, 1] + x[:, 3] / 2) + padw
labels[:, 4] = h * (x[:, 2] + x[:, 4] / 2) + padh
labels4.append(labels)
# Concat/clip labels4 把labels4([(2, 5), (1, 5), (3, 5), (1, 5)] => (7, 5))压缩到一起
if len(labels4):
labels4 = np.concatenate(labels4, 0)
# label[:, 1:]中的所有元素的值(位置信息)必须在[0, 2*s]之间,小于0就令其等于0,大于2*s就等于2*s out: 返回
np.clip(labels4[:, 1:], 0, 2 * s, out=labels4[:, 1:]) # use with clip 防止越界
# 测试代码 测试前面的mosaic效果
# plt.figure(figsize=(20, 16))
# img4 = img4[:, :, ::-1] # BGR -> RGB
# plt.subplot(1, 2, 1)
# plt.imshow(img4)
# plt.title('仿射变换前 shape={}'.format(img4.shape), fontsize=25)
# affine Augment 随机仿射变换 [1472, 1472, 3] => [736, 736, 3]
# img4 = img4[s // 2: int(s * 1.5), s // 2:int(s * 1.5)] # center crop (WARNING, requires box pruning)
img4, labels4 = random_affine(img4, labels4,
degrees=self.hyp['degrees'],
translate=self.hyp['translate'],
scale=self.hyp['scale'],
shear=self.hyp['shear'],
border=-s // 2) # 这里的s是期待输出图片的大小
# 测试代码 测试random_affine随机仿射变换效果
# plt.subplot(1, 2, 2)
# plt.imshow(img4)
# plt.title('仿射变换后 shape={}'.format(img4.shape), fontsize=25)
# plt.show()
return img4, labels4
# 自定义数据集
class LoadImagesAndLabels(Dataset): # for training/testing
def __init__(self,
...
batch_size=16,
augment=False, # 训练集设置为True(augment_hsv),验证集设置为False
hyp=None, # 超参数字典,其中包含图像增强会使用到的超参数
rect=False, # 是否使用rectangular training
...
# 注意: 开启rect后,mosaic就默认关闭
self.mosaic = self.augment and not self.rect # load 4 images at a time into a mosaic (only during training)
...
# 进行自定义数据增强
def __getitem__(self, index):
hyp = self.hyp
# 训练过程使用mosaic来进行数据增强
if self.mosaic:
img, labels = load_mosaic(self, index)
shapes = None
# 推断过程使用Rectangular inference加快推理速度
else:
img, (h0, w0), (h, w) = load_image(self, index)
...
# 判断是否使用数据正确
if self.augment:
# 因为mosaic里已经进行了仿射变换,所以训练过程中不需要再进行一次仿射变换,推理阶段可以使用,或者训练阶段不使用mosaic的时候也可以使用
if not self.mosaic:
img, labels = random_affine(img, labels,
degrees=hyp["degrees"],
translate=hyp["translate"],
scale=hyp["scale"],
shear=hyp["shear"])
# 随机hsv增强:亮度(Value)、饱和度(Saturation)、色度(Hue)
augment_hsv(img, h_gain=hyp["hsv_h"], s_gain=hyp["hsv_s"], v_gain=hyp["hsv_v"])
...
4. Mosaic代码说明
第一张图像填充到mosaic中的图像示例:
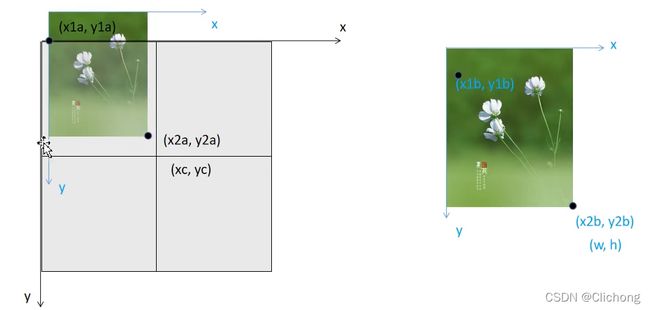
# 计算马赛克图像中的坐标信息(将图像填充到马赛克图像中) w=736 h = 552 马赛克图像:(x1a,y1a)左上角 (x2a,y2a)右下角
x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
# 计算截取的图像区域信息(以xc,yc为第一张图像的右下角坐标填充到马赛克图像中,丢弃越界的区域) 图像:(x1b,y1b)左上角 (x2b,y2b)右下角
x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
# 将截取的图像区域填充到马赛克图像的相应位置 img4[h, w, c]
img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
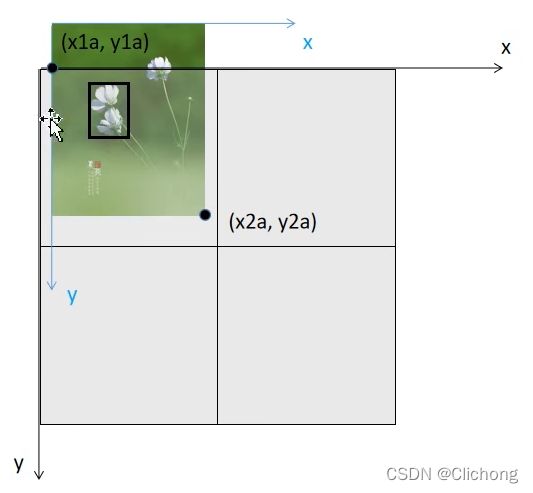
# 计算pad(当前图像边界与马赛克边界的距离,越界的情况padw/padh为负值) 用于后面的label映射
padw = x1a - x1b # 当前图像与马赛克图像在w维度上相差多少
padh = y1a - y1b # 当前图像与马赛克图像在h维度上相差多少
下面是我进行手动推算的过程:
同时还可以注意到,训练阶段一般是对一个batch的数据进行处理的,这里我设置的batch-size为4,也就是4张图像为一批数据。但是在__getitem__函数中,每次都是只取一个图像的索引。但是,使用了mosaic数据增强之后,每个图像又会随机的在lalslist中另外找3张图像来进行拼接成一个马赛克图像。所以,当执行了4次__getitem__函数后,就会执行collate_fn函数,将刚刚处理好的数据包装成一个batch数据。
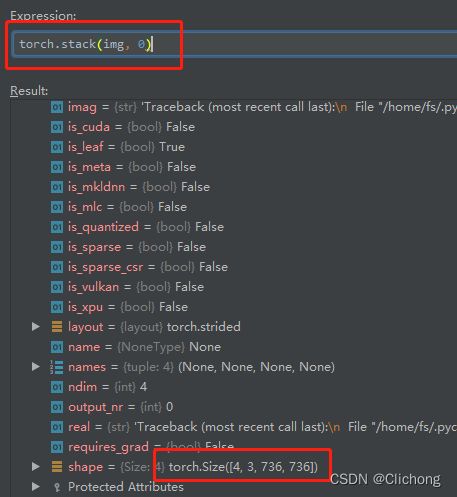
首选,对batch数据进行解剖,这里经过load_mosaic(self, index)所返回的图像大小是(736, 736, 3)的,那么一个batch为4,所以当调转到collate_fn函数时,img应该是一个包含4个子列表的列表,每个子列表就代表了一个图像,对于label来说可以将他们全拼接成一起,不过需要记录好当前批次的label是对应哪个图像的,debug结果如下:
- img参数:
- label参数:
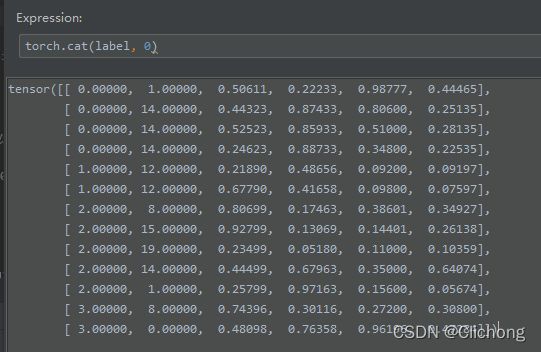
在collate_fn函数中会对img与labe进行拼接成一个batch后返回,代码如下:
@staticmethod
def collate_fn(batch):
img, label, path, shapes, index = zip(*batch) # transposed
for i, l in enumerate(label):
l[:, 0] = i # add target image index for build_targets()
return torch.stack(img, 0), torch.cat(label, 0), path, shapes, index
但是,在刚刚进行mosaic处理后,慢慢马赛克的图像大小是(1472,1472)的宽高大小的,为什么返回的时候又只剩下(736,736)大小了呢?应该是在仿射变换中进行了处理。然后我查看了一下仿射变换,果然,他将图像有重新resize成(736,736)大小了,部分代码如下:
# train阶段默认为:
# img:(1472, 1472, 3), targets:(k, 5), degrees: 0.0, translate: 0.0, scale=0.0, shear:0.0, border=-368
def random_affine(img, targets=(), degrees=10, translate=.1, scale=.1, shear=10, border=0):
# 最终输出的图像尺寸,等于img4.shape / 2
height = img.shape[0] + border * 2
width = img.shape[1] + border * 2
# 生成旋转以及缩放矩阵
R = np.eye(3) # 生成对角阵
a = random.uniform(-degrees, degrees) # 随机旋转角度
s = random.uniform(1 - scale, 1 + scale) # 随机缩放因子
R[:2] = cv2.getRotationMatrix2D(angle=a, center=(img.shape[1] / 2, img.shape[0] / 2), scale=s)
# 生成平移矩阵
T = np.eye(3)
T[0, 2] = random.uniform(-translate, translate) * img.shape[0] + border # x translation (pixels)
T[1, 2] = random.uniform(-translate, translate) * img.shape[1] + border # y translation (pixels)
# 生成错切矩阵
S = np.eye(3)
S[0, 1] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # x shear (deg)
S[1, 0] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # y shear (deg)
# Combined rotation matrix
M = S @ T @ R # ORDER IS IMPORTANT HERE!!
if (border != 0) or (M != np.eye(3)).any(): # image changed
# 进行仿射变化
img = cv2.warpAffine(img, M[:2], dsize=(width, height), flags=cv2.INTER_LINEAR, borderValue=(114, 114, 114))
...
所以,在yolov3spp使用mosaic进行数据增强时,还使用了一些仿射变换,随机旋转,缩放,平移以及错切,当然对图像进行了仿射变化,相应的label也需要进行处理,这一部分我在下一篇博客中会介绍到。
参考资料:
- https://www.bilibili.com/video/BV1t54y1C7ra(b站的视频讲解比较清楚)
- https://blog.csdn.net/qq_38253797/article/details/117961285