c++11并发与多线程
视频连接
并发
早期计算机是单核cpu,只能同时执行一个任务,所以就快速切换任务主体,实现“同时”做多个任务,造成一个并发的假象;
后来多核cpu的计算机出现了,可以实现真正的并行任务执行;即支持硬件并发;
使用并发主要是为了挺高性能
线程和进程
每一个可执行程序就对应一个进程;
每一个进程里只能包含一个主线程,并且这个主线程随着可执行程序的启动而启动;
比如c的main函数就是一个主线程,程序启动时,先启动main部分
并行的实现方式
可以使用多进程实现并行,或者多线程实现并行。
进程之间:在同一电脑上使用管道,文件、共享内存、消息队列进行交互
在不同电脑上使用socket通信技术;
对于多线程,一个进程内的线程共享内存,全局变量、指针都可以共享,所以其开销小于多进程;
但是多线程也会带来数据一致性的问题,例如线程A和线程B都对一个变量进行操作,那么一定要有一个先后之分;
后续的讲解主要使用多线程进行;
c++11标准
早期c++标准库不支持多线程,因此使用第三方库完成,但是win和linux下的库存在差异;如下
win:创建线程CreateThreat()
linux:pthread_create(),
即无法跨平台使用;
如今的c++库支持多线程了;
范例演示:线程的开始和结束
首先主线程是从main()函数开始执行的,因此其他线程也许要一个函数来启动,进而实现创建线程,我们把这个函数成为初始函数,一旦这个函数运行完毕,这个线程也就结束了;
整个程序是是否执行完毕的标志是main(0函数是否执行完毕,如果主线程执行完毕,其他子线程还没结束,那么子线程会被操作系统强制结束(一般情况下);
创建线程
创建线程需要一个可调用对象,这里调用的是一个函数;后面还有把类作为调用对象的例子
#include输出结果如下:

显然还可以套娃使用,在线程里面加线程;
 -
-
但是这时候发现如果在子线程里加上while(true)发现子线程不结束的话,主线程的语句也就打不出来;据说是一个用户级线程,一个线程阻塞,那么所有线程就都阻塞了;
join()函数
join函数:加入,通俗说就是阻塞主线程,在主线程的某个位置创建子线程,线程开始运行,然后用join()标记一个位置,主线程就会在此处等待子线程执行完毕;子线程执行完毕后,主线程才会继续;最终程序在主线程退出;
detach()函数
中文分离的意思:就是说主线程和子线程分离。主线程可以提前结束,无需等待子线程进度;
场景:存在许多子线程,主线程等待的话就很耗费时间。但是实际上,主线程等待子线程才是最稳定的。
这种情况下,主线程无需等待,那么主线程结束后,子线程也还是会在后台执行了。
void myThreadStart();
void myThreadStart()
{
cout<<"子线程开始"<<endl;
while(1);
cout<<"子线程结束"<<endl;
}
int main()
{
cout << "主线程开始" << endl;
thread MyFirstThread(myThreadStart);
//thread是一个对象,对象名称叫做MyFirstThread,构造函数的参数是上面我们自定义的函数myThreadStart
//MyFirstThread.join();
//join表示把创建的线程加入到进程中
MyFirstThread.detach();
//detach表示分离,主线程无需等待子线程
cout << "主线程结束" << endl;
return 0;
}
这里子线程是一个死循环,无法结束;主线程直接结束。如下图:

joinable()
这个函数用来判断线程是否可以join到主线程中。比如新建的线程是可以使用join的,返回true;使用过detache的线程就不可以join了;
用类来启动线程
class First
{
public:
void operator()()//这里不要带参数
{
cout<<"我是类First的一个函数"<<endl;
}
};
int main()
{
cout << "主线程开始" << endl;
First first1;
thread MyFirstThread1(first1);
MyFirstThread1.join();
cout << "主线程结束" << endl;
return 0;
}
一个问题–带参数类启动线程
如果构造的类的构造函数利用了主线程的里的参数,比如下面的这个:
class First
{
public:
int &m_i;
First( int &i):m_i(i)
{
cout<<"构造完成,m_i的值是:"<<m_i<<endl;
}
void operator()()//这里不要带参数
{
cout<<"我是类First的一个函数"<<endl;
cout<<"m_i是"<<m_i<<endl;
cout<<"m_i是"<<m_i<<endl;
cout<<"m_i是"<<m_i<<endl;
cout<<"m_i是"<<m_i<<endl;
};
};
int main()
{
cout << "主线程开始" << endl;
int temp = 6;
First first1(temp);
thread MyFirstThread1(first1);
MyFirstThread1.detach();
cout << "主线程结束" << endl;
return 0;
}
就是简单的给类的一个成员赋值,这时候如果使用detach的话,那么可能出现,主线程和子线程同时进行,最终无法输出正确的结果;如下图,这个类已经构造完成了,m_i也被赋值为6 ,但是operator函数确无法输出,因为主线程结束的时候,temp这个内存已经被回收了,那么m_i绑定的内存也就被回收了;

引用是深拷贝,直接连接到内存空间上。
疑问-主线程结束,对主线程里对象的影响
由于主线程结束,在主线程里创建的对象,会调用析构函数,被取消掉;但是子线程里需要使用主线程对象的地方没有影响,是因为这个对象已经被复制到子线程里,与主线程分离了;
First(const First &first1):m_i(first1.m_i)
{
cout<<"拷贝函数被调用"<<endl;
}
~First()
{
cout<<"我这个类啊,析构了啊!寄了!"<<endl;
}
给类加上拷贝构造函数和析构函数的提示语

可以看到这里主线程的类被拷贝了两次,析构了三次;
因为这个类是被复制的,所以只要类里不用引用指针就会好很多
线程号获取
std::thread::id id = std::this_thread::get_id();
std::cout<<"主线程 id is "<<id<<std::endl;
int temp = 6;
First first1(temp);
thread MyFirstThread1(first1);
cout<<"子线程id是:"<<MyFirstThread1.get_id()<<endl;
用lambda表达式启动线程
lambda简介
从C++11起,开始提供了匿名函数的支持,一个lambda表达式形如:[capture] (parameters) specifiers -> return_type { body };
lambda表达式又称匿名函数(Anonymous function),其构造了一个可以在其作用范围内捕获变量的函数对象。
lambda表达式实际为一个仿函数functor,编译器后会生成一个匿名类(注:这个类重载了()运算符);
lambda表达式自己的参数列表
若lambda函数没有形参且没有被mutable等修饰,则参数的空圆括号可以省略。如:auto a = []{ ++g_Value; }
与普通函数相比,lambda表达式的参数有如下限制
① 参数不能有缺省值 如:int Add1(int a, int b=10)
② 不能有可变长参数列表 如:int Add2(int count, …)
③ 不能有无名参数 如:int Add3(int a, int b, int) // 第三个参数为无名参数,用于以后扩展
lambda启动代码
auto mylambda = []
{
cout<<"我的lambda线程启动函数"<<endl;
//...
cout<<"我的子线程结束"<<endl;
};
int main()
{
cout << "主线程开始" << endl;
std::thread::id id = std::this_thread::get_id();
std::cout<<"主线程 id is "<<id<<std::endl;
thread MyThread2(mylambda);
cout<<"lambda子线程号是:"<<MyThread2.get_id()<<endl;
MyThread2.join();
cout << "主线程结束" << endl;
return 0;
}
临时对象作为参数启动线程讲解
void myprint (const int &i ,const char *paybuf)
{
cout<<endl;
cout<<"i的值是:"<<i<<endl;
cout<<"子线程里i的地址是:"<<&i<<endl;
cout<<"paybuf是:"<<paybuf<<endl;
cout<<"子线程里paybuf的地址是:"<<&paybuf<<endl;
cout<<endl;
}
int main()
{
cout << "主线程开始" << endl;
thread::id id = this_thread::get_id();
cout<<"主线程的id是:"<<id<<endl;
int mvar = 1;
cout<<"主线程里mvar的地址是:"<<&mvar<<endl;
int &mvary = mvar;
cout<<"主线程里mvary的地址是:"<<&mvary<<endl;
char mybuf[] = "this is a test!";
cout<<"主线程里paybuf的地址是:"<<&mybuf<<endl;
thread mythread1(myprint,mvar,mybuf);
//子线程的myprint函数,使用的参数是mvar和mybuf;
thread::id id1 = mythread1.get_id();
cout<<"mythread1的线程号是:"<<id1<<endl;
mythread1.join();
cout <<"主线程结束"<<endl;
return 0;
}
如下图,可以看到主线程main里的地址和传递进子线程里的地址是不同的,虽然是使用的引用;这里和视频讲解不同,视频里paybuf 的地址和主线程里mybuf的地址是一样的。。。我这里不一样,不知道为什么。

从这里来看。上面好像毫无问题啊、
假设上面那个指针的地址是一样的
那么就会存在字符串还未赋值进去,主线程就销毁了mybuf的情况,作出以下修改
void myprint (const int &i ,string paybuf)
//线程调用函数的参数中,paybuf使用string类型
thread mythread1(myprint,mvar,string(mybuf));
//传参之前,使用临时对象string(mybuf)
这一块看的晕乎乎
#include 上述代码如果用join的话,一切正常,但是如果用detach的话,因为类A 需要主线程的mypaybuf来构造,会出现什么都不输出的情况,就是类A还没来得及构造,主线程就结束了;
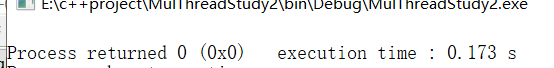
同样适用临时对象A试试
只需要改动一个地方:thread mythread1(myprint,myi,A(mypaybuf));,这时候就可以看到子线程运行完毕了!

都加上地址看看,我也没看懂这里是啥意思,视频里只有两个构造函数,我这里有三个、可能是因为使用的的mingw编译器吧;

总结,1.如果是使用int类型的简单参数,那么直接使用值传递
2.如果要传递类对象,那么要避免隐式类类型转换,在创建线程的遗憾代码中就构建出临时对象,然后在函数参数用引用来承接这个临时变量;
l利用线程id测试
上述使用临时对象的方法,测试结果如下:发现临时对象A是在主线程里构造的, 而且还多了两个拷贝构造;

如果不使用临时对象A,结果如下:发现A是在子线程里进行构造的,也就对应了上面说的如果变量被销毁,A 无法在子线程里构造;

ref的用处
上面可知,子线程里的对象和主线程里的对象地址不一样,尽管使用了引用,系统还是会使用拷贝构造函数;因此显然可知,在子线程里修改对象的成员变量,对主线程是没有影响的;
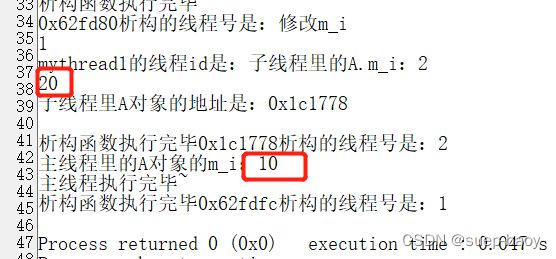
但是用了ref后,就真的用了引用了,子线程和主线程里的地址一样;
只需要在创建线程的时候,给对象A 加上ref即可,比如主线程里的A.m_i=10;在子线程里将其修改为20;
使用ref后,效果如下:

不使用ref的效果如下:
用类的函数来启动线程
class A
{
public:
void threadstart(int num )
{
cout<<"这是A类的一个成员函数"<<endl;
cout<<"传入的参数是:"<<num<<endl;
}
};
int main()
{
thread::id id = this_thread::get_id();
cout<<"主线程的id是:"<<id<<endl;
A objA(10);
thread mythread2(&A::threadstart,objA,50);
mythread2.join();
cout<<"主线程执行完毕~"<<endl;
return 0;
}
这里的线程启动的格式是thread 线程名(类成员函数地址,对象名,成员函数传入参数);
执行的效果如下:

同理,如果这里在 thread mythread2(&A::threadstart,objA,50);的obja前面加ref的话,那么就不会有拷贝构造的过程;也就是主线程和子线程的对象是一致的;
创建和等待多个线程
还是使用myprint作为启动线程的调用函数;格式同上,
void myprint(int num)
{
cout<<"线程"<<this_thread::get_id()<<"打印的num是"<<num<<endl;
cout<<"线程"<<this_thread::get_id()<<"结束!"<<endl;
}
在主函数中利用vector作为存放线程的容器;格式如 vectore my thread pools;
注意把thread对象放到容器里管理,比较方便,可以快速删除或者。。。
调用循环,创建10个线程,并且每个线程的编号从1-10
vector<thread> mythreadpool;
for(int i =0;i<10;++i)
{
mythreadpool.push_back(thread(myprint,i));
}
cout<<"线程创建完毕!"<<endl;
使用迭代器循环吧上一步创建的线程join到主线程;
for(auto iter = mythreadpool.begin();iter!= mythreadpool.end();++iter)
{
iter->join();
}
结果如图:可以看到线程顺序和num顺序不一样,是乱的

这里如果我pushback一个就join一个,会不会不一样?
发现是不行的,直接报错了

线程间数据共享问题
只读数据
对于只读的数据,每一个线程的读取没有问题;
比如 共享数据是 vector pubdata = {1,2,3};
然后用上一步创建的是个线程,读这个共享的容器;
共享数据声明时,放在main函数外;
有读有写的数据
比如两个线程写,8个线程读;这种情况下程序容易崩溃;
最简单的方法就是让线程之间不能同时读写;
共享数据的保护案例
情景:有两个线程,线程1收集玩家命令(用数字代替),并把命令写到队列(用list);线程2 从队列中取出命令,并解析执行;
list
双向链表,对于频繁的顺序插入和删除效率很高;对比用数组结构的vector来说,list在这里更优;vector更适合随机的插入和删除数据;
案例
class A
{
public:
void msgReciveQueue()
{
//命令输入
cout<<"命令输入线程运行"<<endl;
for(int i =0; i<1000; i++)
{
m_command.push_back(i);
}
};
void msgOutQueue()
{
//命令取出
for(int i =0; i<1000; i++)
{
if(!m_command.empty())
{
int command = m_command.front();
cout<<"取出命令"<<command<<endl;
m_command.pop_front();
}
else
{
cout<<"命令列表为空!"<<endl;
}
}
}
private:
list<int> m_command;
};
在main函数中启动两个线程
int main()
{
cout << "主线程开始!" << endl;
A obja;
thread myInThread(&A::msgReciveQueue,&obja);
myInThread.join();
thread myOutThread(&A::msgOutQueue,&obja);
myOutThread.join();
cout<<"主线程结束"<<endl;
return 0;
}
在codeblocks中运行是没有问题的,但是在vs中会报错;
互斥量Mutex
以上面的例子为例,把命令队列m_command锁住;
互斥量的概念
每个线程在对资源操作前都尝试先加锁,成功加锁才能操作,操作结束解锁。通过“锁”就将资源的访问变成互斥操作,而后与时间有关的错误也不会再产生了。
应注意:同一时刻,只能有一个线程持有该锁。
当A线程对某个全局变量加锁访问,B在访问前尝试加锁,拿不到锁,B阻塞。C线程不去加锁,而直接访问该全局变量,依然能够访问,但会出现数据混乱。
所以,互斥锁实质上是操作系统提供的一把“建议锁”(又称“协同锁”),建议程序中有多线程访问共享资源的时候使用该机制。但,并没有强制限定。
因此,即使有了mutex,如果有线程不按规则来访问数据,依然会造成数据混乱。
在访问共享资源前加锁,访问结束后立即解锁。锁的“粒度”应越小越好。但是加锁是个技术活,锁的代码多了,影响效率,锁的代码少了,没有作用;
lcok()和unlock()
加锁和解锁函数;成功返回true;
==两个函数成对出现!==要注意排查这个问题导致的错误;
lock_guard()
相比于mutex功能,lock_guard具有创建时加锁,析构时解锁的功能,类似于智能指针,为了防止在线程使用mutex加锁后异常退出导致死锁的问题,建议使用lock_guard代替mutex
格式:lock_guard lock_guard对象(mutex对象)
原理:在构造lock_guard对象的构造函数里使用了lock,在其析构函数里使用了unlock,所以在一个函数内实现了锁,但是锁的范围变大了,不像自定义的那么灵活;它会在离开作用域{}的时候析构,进而解锁;
并且一个函数内使用lock_guard之后就不能用lock和unlock了
void print_block (int n, char c) {
// critical section (exclusive access to std::cout signaled by locking mtx):
std::lock_guard<std::mutex> mylockguard(mtx);//这里就是构建了一个lock_guard对象
//mtx.lock();
std::cout<<"线程:"<<std::this_thread::get_id()<<"加锁完成!"<<std::endl;
for (int i=0; i<n; ++i) { std::cout << c; }
std::cout << '\n';
//mtx.unlock();
std::cout<<"线程:"<<std::this_thread::get_id()<<"解锁完成!"<<std::endl;
}
unique lock
lock_guard能做到的unique_lock一定可以,其功能更强大,后面再看;
创建时可以不锁定(通过指定第二个参数为std::defer_lock),而在需要时再锁定
可以随时加锁解锁
案例
#include // std::cout
#include // std::thread
#include // std::mutex
std::mutex mtx; // mutex for critical section
void print_block (int n, char c) {
// critical section (exclusive access to std::cout signaled by locking mtx):
mtx.lock();
std::cout<<"线程:"<<std::this_thread::get_id()<<"加锁完成!"<<std::endl;
for (int i=0; i<n; ++i) { std::cout << c; }
std::cout << '\n';
mtx.unlock();
std::cout<<"线程:"<<std::this_thread::get_id()<<"解锁完成!"<<std::endl;
}
int main ()
{
std::thread th1 (print_block,50,'*');
std::thread th2 (print_block,50,'$');
th1.join();
th2.join();
return 0;
}
对于公共的cout,上述代码使用锁,输出结果是不乱的
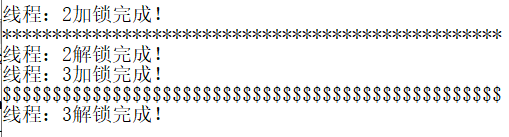
如果把加锁和解锁注释掉,结果如下,顺序乱了

死锁
死锁是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
例如,如果线程A锁住了记录1并等待记录2,而线程B锁住了记录2并等待记录1,这样两个线程就发生了死锁现象。
死锁的原因
1.忘记释放锁;
mutex _mutex;
void func()
{
_mutex.lock();
if (xxx)
return;
_mutex.unlock();//解锁放在return后了
}
2.单线程重复申请锁
mutex _mutex;
void func()
{
_mutex.lock();
//do somrthing....
_mutex.unlock();
}
void data_process() {
_mutex.lock();
func();//这个函数里还有一个锁
_mutex.unlock();
}
3.双线程多锁申请
就是线程A锁住了记录1并等待记录2,而线程B锁住了记录2并等待记录1,这样两个线程就发生了死锁现象。
mutex _mutex1;
mutex _mutex2;
void process1() {
std::cout<<"线程1启动"<<std::endl;
_mutex1.lock();//把1锁好之后,线程切换到2
_mutex2.lock();//这时候2已经被2锁了,这一步就没法继续了
//do something1...
_mutex2.unlock();
_mutex1.unlock();
std::cout<<"线程1正常解锁!"<<std::endl;
}
void process2() {
std::cout<<"线程2启动"<<std::endl;
_mutex2.lock();//线程2把2锁了,线程切换到1
_mutex1.lock();//这里同理
//do something2...
_mutex1.unlock();
_mutex2.unlock();
std::cout<<"线程2正常解锁!"<<std::endl;
}
这样子,有时候就会出现下图的情况,两个线程同时锁,然后程序无法继续;

4.环形锁
假设有A、B、C、D四个人在一起吃饭,每个人左右各有一只筷子。所以,这其中要是有一个人想吃饭,他必须首先拿起左边的筷子,再拿起右边的筷子。现在,我们让所有的人同时开始吃饭。那么就很有可能出现这种情况。每个人都拿起了左边的筷子,或者每个人都拿起了右边的筷子,为了吃饭,他们现在都在等另外一只筷子。此时每个人都想吃饭,同时每个人都不想放弃自己已经得到的一那只筷子。所以,事实上大家都吃不了饭
死锁的解决方法
避免线程死锁归结为一个重要概念就是:A线程不要等待B线程,如果B线程有可能等待A线程。
1.避免嵌套锁定
这一条是最简单的,你已经锁定了一个mutex的时候,你最好不要再次锁定。如果你遵守了这条规则,因为一个线程只有一个锁的情况下不会造成死锁。但是也有其它原因会造成死锁(比如一个线程在等待另一个线程),如果你要锁定多个,你就用std::lock。
2.在已经持有锁的时候不要调用用户自义的代码
因为用户自定义的代码是无法预知的,谁知道他的代码里会不会也想要锁定这个lock。有时候无法避免不调用用户定义代码,这种情况下,你需要注意。
3.按固定顺序锁定
如果你要锁定两个以上的mutex而你又不能用std::lock。那么最好的建议就按固定顺序去锁定。
std::lock函数模板
原理,可以在参数里填多个mutex对象,如果有一个上锁失败了,就会解锁上锁成功的mutex对象,保证不出现死锁问题;
void process1()
{
std::cout<<"线程1启动"<<std::endl;
std::lock(_mutex1,_mutex2);
_mutex2.unlock();
_mutex1.unlock();
std::cout<<"线程1正常解锁!"<<std::endl;
}
void process2()
{
std::cout<<"线程2启动"<<std::endl;
std::lock(_mutex1,_mutex2);
_mutex1.unlock();
_mutex2.unlock();
std::cout<<"线程2正常解锁!"<<std::endl;
}
和上面的图一样,即使线程1和2同时上锁,但是还是可以继续执行下去;

配合lock_guard的adoptlock参数实现自动释放锁
void process1()
{
std::cout<<"线程1启动"<<std::endl;
std::lock(_mutex1,_mutex2);
std::lock_guard<std::mutex> mylockguard1(_mutex1,std::adopt_lock);
//std::adopt_lock作用是声明互斥量已在本线程锁定,std::lock_guard只是保证互斥量在作用域结束时被释放
std::lock_guard<std::mutex> mylockguard2(_mutex2,std::adopt_lock);
std::cout<<"线程1正常解锁!"<<std::endl;
}
void process2()
{
std::cout<<"线程2启动"<<std::endl;
std::lock(_mutex1,_mutex2);
std::lock_guard<std::mutex> mylockguard1(_mutex1,std::adopt_lock);
std::lock_guard<std::mutex> mylockguard2(_mutex2,std::adopt_lock);
std::cout<<"线程2正常解锁!"<<std::endl;
}
unique_lock
unique_lock的介绍
互斥锁保证了线程间的同步,但是却将并行操作变成了串行操作,这对性能有很大的影响,所以我们要尽可能的减小锁定的区域,也就是使用细粒度锁。
这一点lock_guard做的不好,不够灵活,lock_guard只能保证在析构的时候执行解锁操作,lock_guard本身并没有提供加锁和解锁的接口,但是有些时候会有这种需求。
class LogFile {
std::mutex _mu;
ofstream f;
public:
LogFile() {
f.open("log.txt");
}
~LogFile() {
f.close();
}
void shared_print(string msg, int id) {
{
std::lock_guard<std::mutex> guard(_mu);
//do something 1
}
//do something 2
{
std::lock_guard<std::mutex> guard(_mu);
// do something 3
f << msg << id << endl;
cout << msg << id << endl;
}
}
};
上面的代码中,一个函数内部有两段代码需要进行保护,这个时候使用lock_guard就需要创建两个局部对象来管理同一个互斥锁(其实也可以只创建一个,但是锁的力度太大,效率不行),修改方法是使用unique_lock。它提供了lock()和unlock()接口,能记录现在处于上锁还是没上锁状态,在析构的时候,会根据当前状态来决定是否要进行解锁(lock_guard就一定会解锁)。上面的代码修改如下:
class LogFile {
std::mutex _mu;
ofstream f;
public:
LogFile() {
f.open("log.txt");
}
~LogFile() {
f.close();
}
void shared_print(string msg, int id) {
std::unique_lock<std::mutex> guard(_mu);
//do something 1
guard.unlock(); //临时解锁
//do something 2
guard.lock(); //继续上锁
// do something 3
f << msg << id << endl;
cout << msg << id << endl;
// 结束时析构guard会临时解锁
// 这句话可要可不要,不写,析构的时候也会自动执行
// guard.ulock();
}
};
上面的代码可以看到,在无需加锁的操作时,可以先临时释放锁,然后需要继续保护的时候,可以继续上锁,这样就无需重复的实例化lock_guard对象,还能减少锁的区域。同样,可以使用std::defer_lock设置初始化的时候不进行默认的上锁操作
格式 std::unique_lockstd::mutex 对象名(参数);
defer_lock参数
在这里如果使用adopt_lock的话,不报异常,因此这个参数应该是无效的;前面还没上锁,后面就解锁了,怎么可能不报异常呢?
明天看,adopt_lock指的是该线程已经后去了mutex的所有权,即已经加锁成功了!
使用std::defer_lock设置初始化的时候不进行默认的上锁操作,结果就是合理的;这里则是不管他加锁成功还是不成功,我在此处都不加锁;然后在后面再自己加锁;
有个对比的文章关于锁的小文章
try_to_lock()参数
尝试枷锁,如果枷锁失败的话也会返回,不会卡死;然后会继续尝试加锁,直至成功;直至加锁成功这一部分我没有测试出来,加锁失败就直接退出了,==!!!==原因是他在外层加了循环,让他一直加锁。。。
比如县城A给一个mutex加锁,然后sleep()20s,在这20秒之内,线程b无法给统一mutex加锁,他会一直尝试;
使用owns_lock()函数可以判断是否加锁成功,成功返回true!
void MyUniqueLock::m_try_to_lock()
{
unique_lock<mutex> myunilock1(mtx1,try_to_lock);
if(myunilock1.owns_lock())
{
cout<<"加锁成功!"<<endl;
}
else
{
cout<<"加锁失败"<<endl;
}
}
lock()成员函数
就是构造unique_lock对象时,没有加锁,后期使用这个函数自己加锁;
unlock()成员函数
就是想灵活地解开锁;不使用的话,会在对象的析构函数里解锁;
try_lock()成员函数
类似上面的try_to_lock参数,就是尝试加锁,加锁成功返回true,失败返回false
void MyUniqueLock::m_try_lock()
{
unique_lock<mutex> myunilock1(mtx1,defer_lock);//先不加锁创建对象
//mtx1.lock();//注释和不注释这句看效果
if(myunilock1.try_lock())
{
cout<<"拥有所有权,即绑定成功,加锁成功"<<endl;
}
else
{
cout<<"没有所有权,即绑定失败,加锁失败"<<endl;
}
}
release()函数
明天测试
返回它管理的mutex指针,释放其所有权,这个和unlock()是不同的;
比如构造unique_lock对象的时候,传入的mutex对象是mtx1,那么这两者是绑定的,lock对象可以管理mutex对象,这种关系可以用release来解绑;并且release返回的是mutex对象指针;
那么有什么可以重新绑定回来吗现在没看到绑定回来的函数
unique_lock所有权的传递
一个mutex和一个lock绑定,所有权不可以复制,但是可以用move进行转移;
lock_guard不可以复制,不可以转移。
void MyUniqueLock::m_move()
{
unique_lock<mutex> myunilock1(mtx1);
if(myunilock1.owns_lock())
{
cout<<"lcok1拥有所有权!"<<endl;
}
else
{
cout<<"lcok1没有所有权"<<endl;
}
cout<<"所有权传递开始!"<<endl;
unique_lock<mutex> myunilock2(move(myunilock1));
if(myunilock1.owns_lock())
{
cout<<"lcok1拥有所有权!"<<endl;
}
else
{
cout<<"lcok1没有所有权"<<endl;
}
if(myunilock2.owns_lock())
{
cout<<"lock2拥有所有权!"<<endl;
}
else
{
cout<<"lcok1没有所有权"<<endl;
}
}
结果:
类的构造函数
lcok1拥有所有权!
所有权传递开始!
lcok1没有所有权
lock2拥有所有权!
单例设计模式共享数据分析
设计模式大概谈
“”设计模式“”:主要是代码的一些写法, 程序灵活,便于个人维护;但是别人维护起来很难;
对于新手来说,设计模式无需强求;
最好是活学活用,不用也行,不要生搬硬套!!
单例设计模式
单例设计模式使用频率较高;
单例设计模式指的是,某个特殊类,我只创建一个属于这个类的对象,并且只创建一个;
比如说文件读写类,一个对象就可以进行文件读写,多人共同开发时,就实例化一个对象就好了;
静态成员变量
C++静态成员变量:
必须在外部定义和赋值;
不能在 main() 函数中定义
不能在类的构造函数中定义
必须要定义静态变量,否则该变量没有内存空间(类中只是申明) ;
类本身可以直接调用静态变量
静态变量依旧符合public、private、protect特性
例子
.h
class DesienPattern//这是一个单例类
{
public:
//DesienPattern();//原来的构造函数是public的,可以创建多个对象
virtual ~DesienPattern();
private:
DesienPattern();//现在把构造函数改成private的
private:
static DesienPattern *m_instance;//然后定义一个静态成员变量--指针指向单例对象
public:
static DesienPattern *getinstance();//返回对象指针的函数,用来创建对象
};
.cpp
DesienPattern::DesienPattern()
{
cout<<"构造函数"<<endl;
}
DesienPattern::~DesienPattern()
{
//dtor
}
DesienPattern* DesienPattern::getinstance()
{
if(m_instance == NULL)
{
m_instance = new DesienPattern;
}
else{
cout<<"单例已经存在!"<<endl;
}
return m_instance;
}
main.cpp
DesienPattern *DesienPattern::m_instance = NULL;//静态成员变量的初始化方法要注意
int main()
{
DesienPattern *myDesignpattern = DesienPattern::getinstance();
DesienPattern *myDesignpattern1 = DesienPattern::getinstance();
return 0;
}
结果如下;

以上还有漏洞,没有delete对象;
可以通过类中类来删除new处的对象,添加代码如下:
class release//类中类,用来释放对象
{
public:
~release()//类中类的析构函数
{
if(DesienPattern::m_instance)
{
delete DesienPattern::m_instance;
m_instance = NULL;
cout<<"new对象已经删除"<<endl;
}
};
};
总结分为四个步骤;
1.原来的共有构造函数变为私有
2.添加一个私有的静态成员变量*m_instance —指向对象的指针
3.增加私有的 静态 getinstance函数,返回指针,如果指向对象的指针为空,就new一个对象(用私有的构造函数)
4.增加一个类中类,用来delete步骤3中new的对象,并把步骤二的指针重新指向NULL;
5.初始化静态成员变量
单例设计模式共享数据问题分析和解决
首先,强烈建议使用单例模式的时候,在创建线程之前,在主线程里就把单例类的成员变量初始化;
如果要在子线程里创建单例类对象,并且子线程数目可能大于1;
这里以两个子线程为例;可能会分别在子线程里创建单例对象,比如下图,单例对象构造了两次;

解决办法–加mutex,还是双重锁定提高效率
先在类外成名全局锁mtx;
DesienPattern* DesienPattern::getinstance()
{
if(m_instance == NULL)
{//双重检查,第一重,检查是否是第一次初始化
cout<<"是初始化,加锁!"<<endl;
unique_lock<mutex> mylock1(mtx1);
if(m_instance == NULL)
{//第二重,是第一次的化,就在锁的保护下,创建对象。
cout<<"加锁完成"<<endl;
m_instance = new DesienPattern;
static release rel1;
}
else
{
cout<<"单例已经存在!"<<endl;
}
}
return m_instance;
}
结果:

std::call_once()函数
功能:保证函数只能被调用一次,比如两个线程,每个线程都调用a,但是用了call_once后,就可以保证只被调用一次,和上面的mute具备相同作用,并且资源消耗更少;
需要配合标记结合使用std::once_flag;函数调用成功后,标记设为已调用;
例子:在全局外声明全局标志g_flag,然后把上面getinstance的部分代码封装成createinstance,然后只调用一次;
void DesienPattern::createinstance()
{
m_instance = new DesienPattern;
static release rel1;
}
static std::once_flag g_flag;//需要声明一个once_flag
DesienPattern* DesienPattern::getinstance()
{
std::call_once(g_flag,createinstance);
return m_instance;
}
原理线程1执行createinstance时,线程2等待,线程1 执行完毕后,线程2根据g_flag判断是否要再次调用creatinstance;
条件变量
线程同步之条件变量
C++标准库在< condition_variable >中提供了条件变量,借由它,一个线程可以唤醒一个或多个其他等待中的线程。原则上,条件变量的运作如下:
你必须同时包含< mutex >和< condition_variable >,并声明一个mutex和一个condition_variable变量;
那个通知“条件已满足”的线程(或多个线程之一)必须调用notify_one()或notify_all(),以便条件满足时唤醒处于等待中的一个条件变量;
那个等待"条件被满足"的线程必须调用wait(),可以让线程在条件未被满足时陷入休眠状态,当接收到通知时被唤醒去处理相应的任务;
反例
void ConditionVar::msgReciveQueue()
{
cout<<"命令输入线程运行"<<endl;
for(int i =0; i<10; i++)
{
mtx.lock();
m_command.push_back(i);
mtx.unlock();
Sleep(2000);
}
}
void ConditionVar::msgOutQueue()
{
cout<<"命令取出线程运行!"<<endl;
while(true)
{
unique_lock<mutex> locker(mtx);
if(!m_command.empty())
{
int command = m_command.front();
cout<<"取出命令"<<command<<endl;
m_command.pop_front();
locker.unlock();
Sleep(1000);
}
else
{
cout<<"命令列表为空!"<<endl;
locker.unlock();
this_thread::sleep_for(chrono::milliseconds(500));//通过延时,来减少明林列表为空时的资源消耗
}
}
}
两个线程,一个写入,一个读出,显然需要加锁,来保护共享数据;运行结果如图:发现比较难的是设置轮询周期,造成资源浪费,是否可以用提醒的方式,来告知消费者,生产者已经准备好数据呢?
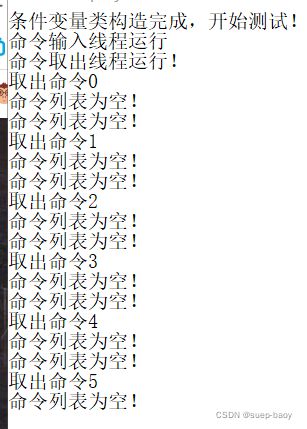
wait()和notify_one()和notify_all()
wait()的第一个参数是uniqude_lock对象,第二个参数是true或者false,默认是false;
如果第二个参数是false的话,就解锁lock对象,然后堵塞在此处,等待通知;
如果为true就尝试获取锁的所有权,获取到了才会进行下一步。
notify_one()随机通知一个线程,解除他的wait()状态;然后被解除的wait的线程就会尝试获取锁,获取到了才会进行下一步的代码;
如果你notify_one()一个线程的时候,这个线程并没有处于wait()状态,那么这个唤醒没有用;就是说线程B的执行时间比较长比如10s,大于线程A两次唤醒的间隔比如7s,A先唤醒B,B还在操作,A又来唤醒B,那这次的唤醒无效;无效的示意图如下:

notify_all(0通知所有线程;针对上述说的时间造成数据积压的问题,可以通过启动多个线程来解决,那么就要用notify_all来通知所有线程,如果启动了两个取数线程,效果如下:
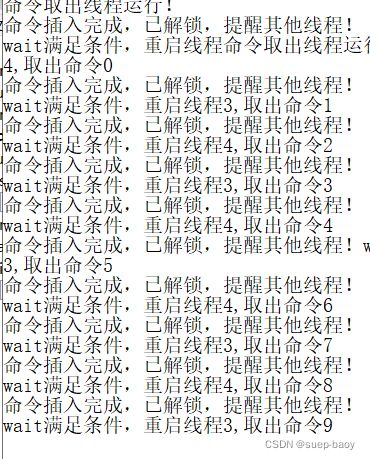
void ConditionVar::msgReciveQueue()
{
//使用条件变量的命令取出函数
cout<<"命令输入线程运行"<<endl;
for(int i =0; i<10; i++)
{
unique_lock<mutex> locker(mtx);
m_command.push_back(i);
locker.unlock();
cout<<"命令插入完成,已解锁,提醒其他线程!"<<endl;
cond.notify_one();//提醒别的线程,有数据了
Sleep(2000);
}
}
void ConditionVar::msgOutQueue()
{
//使用条件变量的命令取出函数
cout<<"命令取出线程运行!"<<endl;
while(true)
{
unique_lock<mutex> locker(mtx);
while(m_command.empty())
{
//这里也可用lambda表示来进行是否满足条件
cond.wait(locker);//解锁lcoker并等待同志
}
cout<<"wait满足条件,重启线程,";
int command = m_command.front();
cout<<"取出命令"<<command<<endl;
m_command.pop_front();
locker.unlock();
}
}
std::async和std::future
参考资料
参考资料2
参考资料2细看
async的功能:启动异步任务:第二个参数接收一个可调用对象(仿函数、lambda表达式、类成员函数、普通函数…)作为参数,然后启动一个线程,执行那个可调用对象。
返回结果std::future的状态:
(1)、deffered:异步操作还没有开始;
(2)、ready:异步操作已经完成;
(3)、timeout:异步操作超时。
线程休眠操作
std::chrono::milliseconds sleeptime(5000);//包含头文件chrono
或者std::chrono::seconds sleeptime(5);//时长5s
std::this_thread::sleep_for(sleeptime);
绑定关系
一个future和一个async启动的线程绑定,使用future.get(),就会等待async调用函数的结果,得不到就会阻塞线程;
如果有func1()+func2(),那么操作时间是函数1运算时间+函数2运算时间+相加消耗时间;
使用async(func1())可以将函数1和函数2并行运算
使用std::future result(async(func1())),将函数1和future对象result绑定;
然后函数结果相加就可以写成 resule.get()+func2();
std::future::get()
随着get被调用,以下三件事情一定会发生:
1.如果func1()被async()启动于一个分离线程中并且已结束,你会立即获得结果
2.如果func1()被启动但尚未结束,get()会引发停滞等待func1()结束后获得结果
3.如果func1()尚未启动,会被强迫启动如同一个同步调用;get()会引发停滞直至结果产生
这样的行为非常重要,原因如下:如果当async()无法启动新线程时,程序仍能正常运作
get()只能调用一次;因为这是一个移动语句,get把future里的结果转移了,如果二次调用的话,就没办法移动了,因此程序就报错了;
wait()
和get类似,但是只是将线程阻塞,等待结果,但是并不返回结果;
针对get()只能使用一次的情况,future提供了wait()接口,可以调用多次,进行结果等待;
async的参数
asyn(执行策略,调用对象,传参);
执行策略分为:
(1)、std::launch::async 传递的可调用对象异步执行;
(2)、std::launch::deferred 传递的可调用对象同步执行;
(3)、std::launch::async | std::launch::deferred 可以异步或是同步,取决于操作系统,我们无法控制;
(4)、如果我们不指定策略,则相当于(3)
对于defered:如果不调用get(),则线程根本不会创建,就算调用了get(),实际上还是在主线程上调用的线程入口函数。
比如下图,不使用get的话,程序直接结束,使用get的话,也没有创建线程,线程号还是和主线程一致;就和直接在主线程里调用函数类似;

std::future_status
是一个枚举类型,如下:
(1)、deffered:异步操作还没有开始;
(2)、ready:异步操作已经完成;
(3)、timeout:异步操作超时。
std::cout<<"Async和Future测试!"<<std::endl;
std::cout<<"主线程启动!id:"<<std::this_thread::get_id()<<std::endl;
std::future<int> result = std::async(std::launch::async,&Test::StartThread1,this,4);//启动异步线程
std::cout<<"等待结果!"<<std::endl;
//std::cout<<"结果是"<<result.get()<<std::endl;
//当执行结果不是ready是,就循环wait
std::future_status status;
do
{
status = result.wait_for(std::chrono::seconds(1));
switch (status)
{
case std::future_status::ready:
std::cout << "Ready..." << std::endl;//执行完成
//获取结果
std::cout << "结果是:" << result.get() << std::endl;
break;
case std::future_status::timeout:
std::cout << "timeout..." << std::endl;//正在执行
break;
case std::future_status::deferred:
std::cout << "deferred..." << std::endl;//还未启动
break;
default:
break;
}
} while (status != std::future_status::ready);
线程运行时间是4秒,等待1s,结果如下:

std::package_task模板函数
参考文章
std::package_task<返回类型(调用对象参数)> task名(可调用对象);
主要功能:它允许传入一个函数,并将函数计算的结果传递给std::future,包括函数运行时产生的异常
可以用valid来判断是否是合法的task;
这个好像无法传入一个类的成员函数;
!!使用顺序
1.建立task
2.绑定future,task.get_future();
3.启动线程
4.future.get()
5.join();
std::packaged_task<int(int,int)> mytask(myplus);//std::package_task<返回类型(调用对象参数)> task名(可调用对象);
std::future<int> result1 = mytask.get_future();
std::thread mythread1(std::move(mytask),5,6);
std::cout<<result1.get()<<std::endl;
mythread1.join();
package_task的优势更多是它能够初始化所有的可调用对象,并且支持对该调用对象的异步访问机制。
srd::promise
参考资料
promise更多的优势是线程之间的变量的传递,同时返回future类的共享状态。同时它也能够支持多种共享状态的访问机制,惰性求值/立即执行。
流程:
1.新建promise对象pr1
2.新建future对线,fu1,并且和pr1绑定;
3.把pr1作为参数,和可调用对象1一起启动线程1
4.把fu1作为参数,和可调用对象2一起启动线程2
5.在线程1里使用pt1.set_value(),给fu1设值;
6.在线程2里使用fu1.get(),取出线程1设好的值;
void pr_func1(std::promise<int > &p,int value)
{
std::cout<<"设置数据函数,线程启动,id:"<<std::this_thread::get_id()<<std::endl;
std::chrono::milliseconds sleeptime(5000);//5000ms
std::this_thread::sleep_for(sleeptime);//休眠5s
p.set_value(value);
std::cout<<"设置数据完成"<<std::endl;
}
void pr_func2(std::future<int> &f)
{
std::cout<<"获取数据函数,线程启动,id:"<<std::this_thread::get_id()<<std::endl;
int value = f.get();
std::cout<<"获取数据完成,数值为:"<<value<<std::endl;
}
main里的
std::promise<int> pr1;
std::future<int> fu1 = pr1.get_future();
std::thread mythread2(pr_func1,std::ref(pr1),20);
std::thread mythread3(pr_func2,std::ref(fu1));
mythread2.join();
mythread3.join();
结果:
设置数据函数,线程启动,id:获取数据函数,线程启动,id:3
2
设置数据完成
获取数据完成,数值为:20
主线程结束
这里不仅可以传递int类型,还可以传递各种;
但是我感觉packeage_task也能实现这样的功能,流程十分类似,但是不用setvalue,而是直接return到future里;
总结
让程序更迅速的一般性做法是:修改程序使它受益于并行处理,但仍能够在单线程环境中正确运作。为了达到这个目标,你必须要这样做:
1.#include
3.将执行结果赋值给一个future
5.如果没有调用get()就不保证func1()一定会被调用.如果async()无法立即启动它收到的函数,就会推迟调用,使得当程序调用get()才被调用。如果没有这种明确请求,即使main()终止造成程序结束,也不会唤醒后台线程.
此外,还需要注意:你必须确保只在最必要时才请求被async()启动的那个函数的执行结果。
std::shard_future;
和future基本一致,但是其函数get()可以多次调用,并且这个share_future的对象可以被用来启动多个线程,而单纯的future对象则不可以;
void pr_func1(std::promise<int > &p,int value)//传入的是引用
{
std::cout<<"设置数据函数,线程启动,id:"<<std::this_thread::get_id()<<std::endl;
std::chrono::milliseconds sleeptime(3000);//3000ms
std::this_thread::sleep_for(sleeptime);//休眠3s
p.set_value(value);
std::cout<<"设置数据完成"<<std::endl;
}
void pr_func2(std::shared_future<int> &f)//传入的是引用
{
std::cout<<"获取数据函数,线程启动,id:"<<std::this_thread::get_id()<<std::endl;
while(true)
{
int value = f.get();
std::cout<<"获取数据完成,数值为:"<<value<<std::endl;
std::chrono::milliseconds sleeptime(2000);//2000ms
std::this_thread::sleep_for(sleeptime);//休眠2s
}
}
main
std::promise<int> pr1;
std::future<int> fu = pr1.get_future();//最原始的future
std::cout<<"fu:"<<std::boolalpha<<fu.valid()<<std::endl;
std::shared_future<int> fu1(fu.share());//这两个函数都可以把fu转移
std::cout<<"fu:"<<std::boolalpha<<fu.valid()<<std::endl;
std::cout<<"fu1:"<<std::boolalpha<<fu1.valid()<<std::endl;
std::thread mythread2(pr_func1,std::ref(pr1),20);//发命令
std::thread mythread3(pr_func2,std::ref(fu1));//接命令1
std::thread mythread4(pr_func2,std::ref(fu1));//接命令2
mythread2.join();
mythread3.join();
mythread4.join();
结合promise,体现使用两个线程,多次调用get(),结果如下: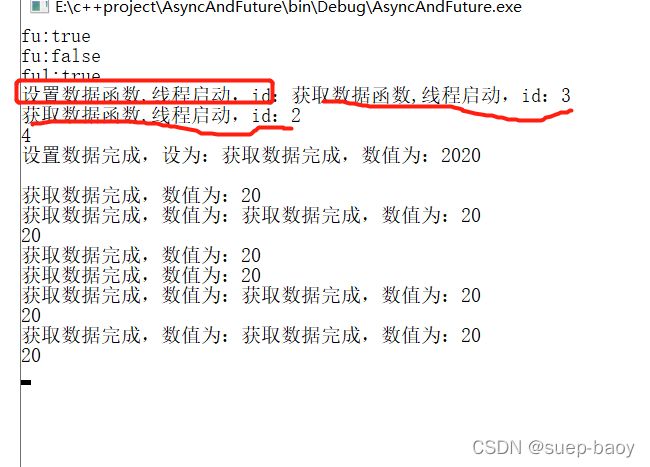
std::stomic
不借助互斥锁实现线程竞争的正当性;
场景设置
void Test::myplus()
{
for(int i =0;i<100000;i++)
{
this->m_plusresult++;
}
}
一个简单的函数,用这个作为启动函数,启动两个线程,结果应该是200000;

但是结果远小于20w,因为赋值语句在代码里看着是一句话,但是在低层编译的时候可能有两三句,两个线程有可能使赋值语句失效!
用mutex解决上述场景问题
可以通过加锁的方式解决,加锁之后,1亿次运算都不会出错;
不加锁效果:结果错误,用时0.567s
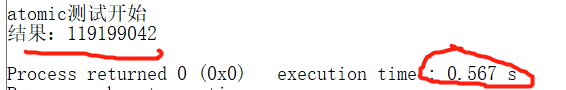
加锁效果:结果正确,用时11.013s,可见加锁非常影响效率;
用原子操作解决上述问题
原子操作是在多线程中不会被打断的代码句;他只要执行就会结束,不会出现中间状态;
理论上,原子操作比mutex的效率高的;
互斥量可以给一段、一片代码加锁;
原子操作只能针对单个变量;
std::atomic<int> m_atoplusresult = {0};;//原子变量,并且用结构体的方式赋值;
void Test::myatomicplus()
{
for( long int i =0;i<100000000;i++)
{//无需加锁
this->m_atoplusresult++;//这是一个原子操作
}
}

1亿次操作只用了2.054s,并且结果正确!;
原子操作心得
一般用于做计数或者统计,比如收到多少数据包,发送多少数据包;
原子变量还可以是其他类型,但是一般使用的比较少;
atomic一个小问题
void Test::myatomicplus()
{
for( long int i =0;i<100000000;i++)
{//无需加锁
this->m_atoplusresult++;//这是一个原子操作
//这里如果改成this->m_atoplusresult = this->m_atoplusresult +1;就不对了
}
}
看注释,知道原子操作对++,–等是支持的,但是对于a=a+1;就不对,使用的时候可以自己测试一下;
std::async深入谈
使用std::thread创建线程的时候,有可能因为资源紧张,导致创建线程失败,进而导致整个程序崩溃;
而std::async,我们称为创建一个异步任务,就是说他可能没有创建新的线程;
比如使用参数 std::launch::defered,这个参数就是延迟调用,并且不创建线程,直到有人调用std::future::get()函数;
使用参数std::launch::async,则强制将异步任务运行在新的线程里;
thread和async的区别
1、thread创建线程失败会导致程序崩溃
2、thread线程调用函数的返回值不容易获取;
3、async资源紧张时,就不会创建线程,直到调用get
windows临界区-Critical Section
就是windows系统下的互斥量,其功能和mutex类似,但是,只能用于windows的
- EnterCriticalSection(&mywinsec); //等同于mutex.lock()
- LeaveCriticalSection(&mywinsec);//等同于mutex.unlock()
以之前的写入命令代码为基础,修改如下:
void ConditionVar::msgReciveQueue()
{
//使用条件变量的命令取出函数
cout<<"命令输入线程运行"<<endl;
for(int i =0; i<20; i++)
{
#ifdef _WINDOWSJQ_
EnterCriticalSection(&my_winsec);
m_command.push_back(i);
LeaveCriticalSection(&my_winsec);
cout<<"win命令插入完成"<<endl;
#else
unique_lock<mutex> locker(mtx);
m_command.push_back(i);
locker.unlock();
cout<<"命令插入完成,已解锁,提醒其他线程!"<<endl;
cond.notify_all();//提醒别的线程,有数据了
#endif // _WINDOWSJQ_
Sleep(1000);
}
}
就是如果定义了window的开关,那么就是用临界区来完成两个线程的读写操作;
多次进入临界区
在一个线程中,可以连续是用两次enter,当然对应的要用两个leave;
与之对比,mutex.lcok不可以连续使用两次;
递归锁–recursive_mutex
递归的独占互斥量;
这个锁可以在同一个线程内多次lock();
void ConditionVar::my_recursive_mutex()
{
cout<<"这是一个递归锁的例子!"<<endl;
std::unique_lock<std::recursive_mutex> mylock(this->recmtx);
cout<<"加锁一次!"<<endl;
test();
}
void ConditionVar::test()
{
std::unique_lock<std::recursive_mutex> mylock(this->recmtx);
cout<<"加锁两次"<<endl;
}
死锁的原因里就有这种例子,现在可以通过递归锁来避免出现死锁;
缺点 :
多次调用锁程序比较繁琐,并且效率比单纯的mutex要大;
能用单纯mutex的情况下就使用mutex,不要使用recursive_mutex;
自动析构技术
回忆:std::lock_guard,这个可以完成自动加锁和自动解锁的功能;
那么可以通过自己写一个类,在构造函数里enter(),在析构函数里leave
std::timed_mutex带时限的锁;
同样还有std::timed_recursive_mutex,带时限的递归的独占锁;
成员函数
- try_lcok_for(时间);等待一段时间,拿到返回true,没拿到返回false,如果没拿到,也不阻塞
- try_lcok_until(未来的时间点),比如一直获取到明天10点,拿到返回true,没拿到返回false,如果没拿到,也不阻塞
try_lcok_for(时间);
启动两个线程,测试try_lcok_for(时间)的效果;
void ConditionVar::timed_mutex_test()
{
//拿锁线程1
while(true)
{
if(timemtx.try_lock_for(2s))
{
cout<<"线程1拿到锁了"<<endl;
timemtx.unlock();
cout<<"线程1已解锁"<<endl;
}
else
{
cout<<"5s内没拿到锁!"<<endl;
}
Sleep(1000);
}
}
void ConditionVar::timed_mutex_test2()
{
//拿锁线程1
while(true)
{
timemtx.lock();
cout<<"线程2已上锁"<<endl;
Sleep(3000);
timemtx.unlock();
cout<<"线程2已解锁"<<endl;
}
}
try_lcok_until(未来的时间点)
时间可以用std::chrono::steady_clock::now()
还是上面的代码:就修改一句话
if(timemtx.try_lock_until(std::chrono::steady_clock::now() + 2s))
表示直到现在之后的2s,等待获取锁;
一些补充知识
虚假唤醒
在使用notify_one()和wait()的情况下,可能出现虚假唤醒;
虚假唤醒可能导致数据积压;
原子操作
- 原子变量.load(),以原子操作读取原子变量的内容
- 原子变量.store(),以原子操作给原子变量设值
线程池
线程数量不能太多;
然后随便地在程序的任意部分时不时的创建线程,会导致稳定性问题;
线程池:把一对线程集中到一起,统一管理,用完不释放,循环使用;
实现方式
在程序启动时,一次性创建多个(100-200个)线程,当有线程需求时,就拿出空闲循环,用来执行任务;任务执行完毕,就把线程返回到线程池中;
可以参考这个资料;参考资料
参考资料2