自然语言处理实战-基于LSTM的藏头诗和古诗自动生成
自然语言处理实战-基于LSTM的藏头诗和古诗自动生成
第一次写也是自己的第一篇博客,分享一下自己做的实验以及遇到的一些问题和上交的结课作业。资源都是开源的,参考文章写的很好,菜鸟的我也能理解。原文链接基于LSTM网络的藏头诗和古诗自动生成(附完整代码和数据)_一路狂奔的猪的博客-CSDN博客_lstm生成唐诗r
如果有问题欢迎大家交流。
一、自然语言处理基础与实战
自然语言处理( Natural Language Processing, NLP)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系,但又有重要的区别。自然语言处理并不是一般地研究自然语言,而在于研制能有效地实现自然语言通信的计算机系统,特别是其中的软件系统。因而它是计算机科学的一部分。
自然语言处理主要应用于机器翻译、舆情监测、自动摘要、观点提取、文本分类、问题回答、文本语义对比、语音识别、中文OCR等方面。自己这学期也上了语音识别课程,后面有时间可以更新一下自己做的语音识别试验。
二、实验
1.中文分词的应用
读取文本,加载停用词,分词,打印样本,分词结果,高频词。代码如下
import jieba
def word_extract():
corpus = []
path = 'D:/python/data/flightnews.txt'
content = ''
for line in open(path, 'r', encoding='utf-8', errors='ignore'):
line = line.strip()
content += line
corpus.append(content)
stop_words = []
path = 'D:/python/data/stopwords.txt'
for line in open(path, encoding='utf-8'):
line = line.strip()
stop_words.append(line)
# jieba分词
split_words = []
word_list = jieba.cut(corpus[0])
for word in word_list:
if word not in stop_words:
split_words.append(word)
dic = {}
word_num = 10
for word in split_words:
dic[word] = dic.get(word, 0) + 1
freq_word = sorted(dic.items(), key = lambda x: x[1],
reverse=True) [: word_num]
print('样本:' + corpus[0])
print('样本分词效果:' + '/ '.join(split_words))
print('样本前10个高频词:' + str(freq_word))
word_extract()结果展示
2. 词性标注命名体识别
中文命名实体识别的流程,CRF条件随机场命名实体识别的使用。 代码如下
from sklearn_crfsuite import metrics
import joblib
import sklearn_crfsuite
class CorpusProcess(object):
# 由词性提取标签
def pos_to_tag(self, p):
t = self._maps.get(p, None)
return t if t else 'O'
# 标签使用BIO模式
def tag_perform(self, tag, index):
if index == 0 and tag != 'O':
return 'B_{}'.format(tag)
elif tag != 'O':
return 'I_{}'.format(tag)
else:
return tag
#全角转半角
def q_to_b(self, q_str):
b_str = ""
for uchar in q_str:
inside_code = ord(uchar)
if inside_code == 12288: # 全角空格直接转换
inside_code = 32
elif 65374 >= inside_code >= 65281: # 全角字符(除空格)根据关系转化
inside_code -= 65248
b_str += chr(inside_code)
return b_str
# 语料初始化
def initialize(self):
lines = self.read_corpus_from_file(self.process_corpus_path)
words_list = [line.strip().split(' ') for line in lines if line.strip()]
del lines
self.init_sequence(words_list)
# 初始化字序列、词性序列
def init_sequence(self, words_list):
words_seq = [[word.split('/')[0] for word in words] for words in words_list]
pos_seq = [[word.split('/')[1] for word in words] for words in words_list]
tag_seq = [[self.pos_to_tag(p) for p in pos] for pos in pos_seq]
self.tag_seq = [[[self.tag_perform(tag_seq[index][i], w)
for w in range(len(words_seq[index][i]))]
for i in range(len(tag_seq[index]))]
for index in range(len(tag_seq))]
self.tag_seq = [[t for tag in tag_seq for t in tag] for tag_seq in self.tag_seq]
self.word_seq = [[''] + [w for word in word_seq for w in word]
+ [''] for word_seq in words_seq]
def segment_by_window(self, words_list=None, window=3):
words = []
begin, end = 0, window
for _ in range(1, len(words_list)):
if end > len(words_list):
break
words.append(words_list[begin: end])
begin = begin + 1
end = end + 1
return words
# 特征提取
def extract_feature(self, word_grams):
features, feature_list = [], []
for index in range(len(word_grams)):
for i in range(len(word_grams[index])):
word_gram = word_grams[index][i]
feature = {'w-1': word_gram[0],
'w': word_gram[1], 'w+1': word_gram[2],
'w-1:w': word_gram[0] + word_gram[1],
'w:w+1': word_gram[1] + word_gram[2],
'bias': 1.0}
feature_list.append(feature)
features.append(feature_list)
feature_list = []
return features
# 训练数据
def generator(self):
word_grams = [self.segment_by_window(word_list) for word_list in self.word_seq]
features = self.extract_feature(word_grams)
return features, self.tag_seq
class CRF_NER(object):
# 初始化CRF模型参数
def __init__(self):
self.algorithm = 'lbfgs'
self.c1 = '0.1'
self.c2 = '0.1'
self.max_iterations = 100 # 迭代次数
self.model_path = 'D:/python/data/model.pkl'
self.corpus = CorpusProcess() # 加载语料预处理模块
self.model = None
# 定义模型
def initialize_model(self):
self.corpus.pre_process() # 语料预处理
self.corpus.initialize() # 初始化语料
algorithm = self.algorithm
c1 = float(self.c1)
c2 = float(self.c2)
max_iterations = int(self.max_iterations)
self.model = sklearn_crfsuite.CRF(algorithm=algorithm, c1=c1, c2=c2,
max_iterations=max_iterations,
all_possible_transitions=True)
# 模型训练
def train(self):
self.initialize_model()
x, y = self.corpus.generator()
x_train, y_train = x[500: ], y[500: ]
x_test, y_test = x[: 500], y[: 500]
self.model.fit(x_train, y_train)
labels = list(self.model.classes_)
labels.remove('O')
y_predict = self.model.predict(x_test)
metrics.flat_f1_score(y_test, y_predict, average='weighted', labels=labels)
sorted_labels = sorted(labels, key=lambda name: (name[1: ], name[0]))
print(metrics.flat_classification_report(
y_test, y_predict, labels=sorted_labels, digits=3))
# 保存模型
joblib.dump(self.model, self.model_path)
def predict(self, sentence):
# 加载模型
self.model = joblib.load(self.model_path)
u_sent = self.corpus.q_to_b(sentence)
word_lists = [[''] + [c for c in u_sent] + ['']]
word_grams = [
self.corpus.segment_by_window(word_list) for word_list in word_lists]
features = self.corpus.extract_feature(word_grams)
y_predict = self.model.predict(features)
entity = ''
for index in range(len(y_predict[0])):
if y_predict[0][index] != 'O':
if index > 0 and(
y_predict[0][index][-1] != y_predict[0][index - 1][-1]):
entity += ' '
entity += u_sent[index]
elif entity[-1] != ' ':
entity += ' '
return entity
ner=CRF_NER()
sentence1 = '2020年9月23日,’1+X‘证书制度试点第四批职业教育培训评价组织和职业技能等级公证书公示,其中广东泰迪智能' \
'科技股份有限公司申请的大数据应用开发(python)位列其中。'
output1 = ner.predict(sentence1)
print(output1)
import jieba.posseg as psg # 加载jieba库中的分词函数
sent = '我爱黄河科技学院'
for w, t in psg.cut(sent):
print(w, '/', t)
结果展示

3.关键词提取算法
TF-IDF,,extRank,LSI三种算法的实现,以及一些文本预处理的方法。在实验过程中,安装gensim第三方库的时候遇到了一个问题,就是版本不匹配问题,自己搜的别人博客上说的是gensim版本与numpy的版本不匹配,需要把这两个库卸载重新安装就可以了,我试了试还是不行,因为我发现卸载之后重新默认安装的第三方库的版本和之前的版本是一样的。我的python是3.6版本的,但是默认安装的gensim版本是最新的,我的numpy库在之前也是正常使用的,因为不知道版本之间的对应关系在哪里查,就降版本安装,没想到第一次就成功了,我在命令行使用pip命令安装的指定版本gensim3.6。然后就可以运行了。(可能不规范但的确是这样解决的)
上代码
import jieba
import jieba.posseg
import numpy as np
import pandas as pd
import math
import operator
'''
提供Python内置的部分操作符函数,这里主要应用于序列操作
用于对大型语料库进行主题建模,支持TF-IDF、LSA和LDA等多种主题模型算法,提供了
诸如相似度计算、信息检索等一些常用任务的API接口
'''
from gensim import corpora, models
text = '广州地铁集团工会主席钟学军在开幕式上表示,在交通强国战略的指引下,我国城市轨道' \
'交通事业蓬勃发展,城轨线路运营里程不断增长,目前,全国城市轨道交通线网总里程' \
'接近5000公里,每天客运量超过5000万人次。城市轨道交通是高新技术密集型行业,' \
'几十个专业纷繁复杂,几十万台(套)设备必须安全可靠,线网调度必须联动周密,' \
'列车运行必须精准分秒不差。城市轨道交通又是人员密集型行业,产业工人素质的好坏、' \
'高低,直接与人民生命安全息息相关。本届“国赛”选取的列车司机和行车值班员,' \
'正是行业安全运营的核心、关键工种。开展职业技能大赛的目的,就是要弘扬' \
'“工匠精神”,在行业内形成“比、学、赶、帮、超”的良好氛围,在校园里掀起' \
'“学本领、争上游”的学习热潮,共同为我国城市轨道交通的高质量发展和交通强国' \
'建设目标的全面实现做出应有的贡献。'
# 获取停用词
def Stop_words():
stopword = []
data = []
f = open('D:/python/data/stopwords.txt', encoding='utf8')
for line in f.readlines():
data.append(line)
for i in data:
output = str(i).replace('\n', '')
stopword.append(output)
return stopword
# 采用jieba进行词性标注,对当前文档过滤词性和停用词
def Filter_word(text):
filter_word = []
stopword = Stop_words()
text = jieba.posseg.cut(text)
for word, flag in text:
if flag.startswith('n') is False:
continue
if not word in stopword and len(word) > 1:
filter_word.append(word)
return filter_word
# 加载文档集,对文档集过滤词性和停用词
def Filter_words(data_path = 'D:/python/data/corpus.txt'):
document = []
for line in open(data_path, 'r', encoding='utf8'):
segment = jieba.posseg.cut(line.strip())
filter_words = []
stopword = Stop_words()
for word, flag in segment:
if flag.startswith('n') is False:
continue
if not word in stopword and len(word) > 1:
filter_words.append(word)
document.append(filter_words)
return document
# TF-IDF 算法
def tf_idf():
# 统计TF值
tf_dict = {}
filter_word = Filter_word(text)
for word in filter_word:
if word not in tf_dict:
tf_dict[word] = 1
else:
tf_dict[word] += 1
for word in tf_dict:
tf_dict[word] = tf_dict[word] / len(text)
# 统计IDF值
idf_dict = {}
document = Filter_words()
doc_total = len(document)
for doc in document:
for word in set(doc):
if word not in idf_dict:
idf_dict[word] = 1
else:
idf_dict[word] += 1
for word in idf_dict:
idf_dict[word] = math.log(doc_total / (idf_dict[word] + 1))
# 计算TF-IDF值
tf_idf_dict = {}
for word in filter_word:
if word not in idf_dict:
idf_dict[word] = 0
tf_idf_dict[word] = tf_dict[word] * idf_dict[word]
# 提取前10个关键词
keyword = 10
print('TF-IDF模型结果:')
for key, value in sorted(tf_idf_dict.items(), key=operator.itemgetter(1),
reverse=True)[:keyword]:
print(key + '/', end='')
def TextRank():
window = 3
win_dict = {}
filter_word = Filter_word(text)
length = len(filter_word)
# 构建每个节点的窗口集合
for word in filter_word:
index = filter_word.index(word)
# 设置窗口左、右边界,控制边界范围
if word not in win_dict:
left = index - window + 1
right = index + window
if left < 0:
left = 0
if right >= length:
right = length
words = set()
for i in range(left, right):
if i == index:
continue
words.add(filter_word[i])
win_dict[word] = words
# 构建相连的边的关系矩阵
word_dict = list(set(filter_word))
lengths = len(set(filter_word))
matrix = pd.DataFrame(np.zeros([lengths,lengths]))
for word in win_dict:
for value in win_dict[word]:
index1 = word_dict.index(word)
index2 = word_dict.index(value)
matrix.iloc[index1, index2] = 1
matrix.iloc[index2, index1] = 1
summ = 0
cols = matrix.shape[1]
rows = matrix.shape[0]
# 归一化矩阵
for j in range(cols):
for i in range(rows):
summ += matrix.iloc[i, j]
matrix[j] /= summ
# 根据公式计算textrank值
d = 0.85
iter_num = 700
word_textrank = {}
textrank = np.ones([lengths, 1])
for i in range(iter_num):
textrank = (1 - d) + d * np.dot(matrix, textrank)
# 将词语和textrank值一一对应
for i in range(len(textrank)):
word = word_dict[i]
word_textrank[word] = textrank[i, 0]
keyword = 10
print('------------------------------')
print('textrank模型结果:')
for key, value in sorted(word_textrank.items(), key=operator.itemgetter(1),
reverse=True)[:keyword]:
print(key + '/', end='')
def lsi():
# 主题-词语
document = Filter_words()
dictionary = corpora.Dictionary(document) # 生成基于文档集的语料
corpus = [dictionary.doc2bow(doc) for doc in document] # 文档向量化
tf_idf_model = models.TfidfModel(corpus) # 构建TF-IDF模型
tf_idf_corpus = tf_idf_model[corpus] # 生成文档向量
lsi = models.LsiModel(tf_idf_corpus, id2word=dictionary, num_topics=4)
# 构建lsiLSI模型,函数包括3个参数:文档向量、文档集语料id2word和
# 主题数目num_topics,id2word可以将文档向量中的id转化为文字
# 主题-词语
words = []
word_topic_dict = {}
for doc in document:
words.extend(doc)
words = list(set(words))
for word in words:
word_corpus = tf_idf_model[dictionary.doc2bow([word])]
word_topic= lsi[word_corpus]
word_topic_dict[word] = word_topic
# 文档-主题
filter_word = Filter_word(text)
corpus_word = dictionary.doc2bow(filter_word)
text_corpus = tf_idf_model[corpus_word]
text_topic = lsi[text_corpus]
# 计算当前文档和每个词语的主题分布相似度
sim_dic = {}
for key, value in word_topic_dict.items():
if key not in text:
continue
x = y = z = 0
for tup1, tup2 in zip(value, text_topic):
x += tup1[1] ** 2
y += tup2[1] ** 2
z += tup1[1] * tup2[1]
if x == 0 or y == 0:
sim_dic[key] = 0
else:
sim_dic[key] = z / (math.sqrt(x * y))
keyword = 10
print('------------------------------')
print('LSI模型结果:')
for key, value in sorted(sim_dic.items(), key=operator.itemgetter(1),
reverse=True)[: keyword]:
print(key + '/' , end='')
tf_idf()
TextRank()
lsi()
结果展示

4.文本向量化算法
自己训练的语料数据太少,在计算词的相似度的时候就出现了没有在预料中出现的情况,也有可能是自己设置的重复低于5词的词没有计算的原因,还有用词向量计算文本相似度时,不知道哪里有问题,计算的明明是三国志和西游记文本的相似度,最后输出的是-100%,不太明白,也没解决。
import jieba
import jieba.posseg
import os
from gensim.corpora import WikiCorpus
import warnings
warnings.filterwarnings(action='ignore',category=UserWarning,module='gensim')
import gensim
from gensim.models.word2vec import LineSentence
from gensim.models import Word2Vec
def Stop_words():
stopword = []
data = []
f = open('D:/python/data/stopword.txt', encoding='utf8')
for line in f.readlines():
data.append(line)
for i in data:
output = str(i).replace('\n', '')
stopword.append(output)
return stopword
# 采用jieba进行词性标注,对当前文档过滤词性和停用词
def Filter_word(text):
filter_word = []
stopword = Stop_words()
text = jieba.posseg.cut(text)
for word, flag in text:
if flag.startswith('n') is False:
continue
if not word in stopword and len(word) > 1:
filter_word.append(word)
return filter_word
# 加载文档集,对文档集过滤词性和停用词
def Filter_words(data_path = 'D:/python/data/word2vec_train_words.txt'):
document = []
for line in open(data_path, 'r', encoding='utf8'):
segment = jieba.posseg.cut(line.strip())
filter_words = []
stopword = Stop_words()
for word, flag in segment:
if flag.startswith('n') is False:
continue
if not word in stopword and len(word) > 1:
filter_words.append(word)
document.append(filter_words)
return document
def train():
wk_news = open('D:/python/data/word2vec_train_words.txt','r',encoding='utf-8')
model = Word2Vec(LineSentence(wk_news),sg=0,size=192,window=5,min_count=5,workers=9)
model.save('D:/python/data/zhwk_news.word2vec')
if __name__ == '__main__':
if os.path.exists('D:/python/data/zhwk_news.word2vec') == False:
print('开始训练模型')
train()
print('模型训练完毕')
model = gensim.models.Word2Vec.load('D:/python/data/zhwk_news.word2vec')
print(model.similarity('番茄','西红柿'))
print(model.similarity('卡车','汽车'))
import sys
import gensim
import numpy as np
import pandas as pd
from jieba import analyse
def keyword_extract(data):
tfidf = analyse.extract_tags
keywords = tfidf(data)
return keywords
def segment(file,keyfile):
with open(file,'r',encoding='utf-8') as f,open(keyfile,'w',encoding='utf-8') as k:
for doc in f:
keywords = keyword_extract(doc[:len(doc)-1])
for word in keywords:
k.write(word + '')
k.write('\n')
def get_char_pos(string,char):
chPos = []
chPos = list(((pos) for pos,val in enumerate(string) if (val == char)))
return chPos
def word2vec(file_name,model):
wordve_size = 192
with open(file_name,'r',encoding='utf-8') as f:
word_vec_all = np.zeros(wordve_size)
for data in f:
space_pos = get_char_pos(data,'')
try:
first_word = data[0: space_pos[0]]
except:
continue
if model.__contains__(first_word):
word_vec_all = word_vec_all + model[first_word]
for i in range(len(space_pos)-1):
word = data[space_pos[i]:space_pos[i+1]]
if model.__contains__(word):
word_vec_all = word_vec_all + model[word]
return word_vec_all
def similarity(a_vect,b_vect):
dot_val = 0.0
a_nom = 0.0
b_nom = 0.0
cos = None
for a,b in zip(a_vect,b_vect):
dot_val += a * b
a_nom += a ** 2
b_nom += a ** 2
if a_nom == 0.0 or b_nom == 0.0:
cos = -1
else:
cos = dot_val / ((a_nom * b_nom)**0.5)
return cos
def test_model(keyfile1,keyfile2):
print('导入模型')
model_path = 'D:/python/data/zhwk_news.word2vec'
model = gensim.models.Word2Vec.load(model_path)
vect1 = word2vec(keyfile1,model)
vect2 = word2vec(keyfile2,model)
print(sys.getsizeof(vect1))
print(sys.getsizeof(vect2))
cos = similarity(vect1,vect2)
print('相似度:%0.2f%%' % (cos * 100))
if __name__ == '__main__':
file1 = 'D:/python/data/三国志.txt'
file2 = 'D:/python/data/西游记.txt'
keyfile1 = 'D:/python/data/三国志_key.txt'
keyfile2 = 'D:/python/data/西游记_key.txt'
segment(file1,keyfile1)
segment(file2,keyfile2)
test_model(keyfile1,keyfile2)

5.文本分类和文本聚类
代码
import os
import re
import jieba
import numpy as np
import pandas as pd
# from scipy.misc import imread
import imageio
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics import confusion_matrix, classification_report
# 读取数据
data = pd.read_csv('D:/python/data/message80W.csv', encoding='utf-8', index_col=0, header=None)
data.columns = ['类别', '短信']
data.类别.value_counts()
temp = data.短信
temp.isnull().sum()
# 去重
data_dup = temp.drop_duplicates()
# 脱敏
l1 = data_dup.astype('str').apply(lambda x: len(x)).sum()
data_qumin = data_dup.astype('str').apply(lambda x: re.sub('x', '', x))
l2 = data_qumin.astype('str').apply(lambda x: len(x)).sum()
print('减少了' + str(l1-l2) + '个字符')
# 加载自定义词典
jieba.load_userdict('D:/python/data/newdic1.txt')
# 分词
data_cut = data_qumin.astype('str').apply(lambda x: list(jieba.cut(x)))
# 去停用词
stopword = pd.read_csv('D:/python/data/stopword.txt', sep='ooo', encoding='gbk',
header=None, engine='python')
stopword = [' '] + list(stopword[0])
l3 = data_cut.astype('str').apply(lambda x: len(x)).sum()
data_qustop = data_cut.apply(lambda x: [i for i in x if i not in stopword])
l4 = data_qustop.astype('str').apply(lambda x: len(x)).sum()
print('减少了' + str(l3-l4) + '个字符')
data_qustop = data_qustop.loc[[i for i in data_qustop.index if data_qustop[i] != []]]
# 词频统计
lab = [data.loc[i, '类别'] for i in data_qustop.index]
lab1 = pd.Series(lab, index=data_qustop.index)
def cipin(data_qustop, num=10):
temp = [' '.join(x) for x in data_qustop]
temp1 = ' '.join(temp)
temp2 = pd.Series(temp1.split()).value_counts()
return temp2[temp2 > num]
data_gar = data_qustop.loc[lab1 == 1]
data_nor = data_qustop.loc[lab1 == 0]
data_gar1 = cipin(data_gar, num=5)
data_nor1 = cipin(data_nor, num=30)
num = 10000
adata = data_gar.sample(num, random_state=123)
bdata = data_nor.sample(num, random_state=123)
data_sample = pd.concat([adata, bdata])
cdata = data_sample.apply(lambda x: ' '.join(x))
lab = pd.DataFrame([1] * num + [0] * num, index=cdata.index)
my_data = pd.concat([cdata, lab], axis=1)
my_data.columns = ['message', 'label']
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(
my_data.message, my_data.label, test_size=0.2, random_state=123) # 构建词频向量矩阵
# 训练集
cv = CountVectorizer() # 将文本中的词语转化为词频矩阵
train_cv = cv.fit_transform(x_train) # 拟合数据,再将数据转化为标准化格式
train_cv.toarray()
train_cv.shape # 查看数据大小
cv.vocabulary_ # 查看词库内容
# 测试集
cv1 = CountVectorizer(vocabulary=cv.vocabulary_)
test_cv = cv1.fit_transform(x_test)
test_cv.shape
# 朴素贝叶斯
nb = MultinomialNB() # 朴素贝叶斯分类器
nb.fit(train_cv, y_train) # 训练分类器
pre = nb.predict(test_cv) # 预测
# 评价
cm = confusion_matrix(y_test, pre)
cr = classification_report(y_test, pre)
print(cm)
print(cr)

import re
import os
import json
import jieba
import pandas as pd
from sklearn.cluster import KMeans
import joblib
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
# 数据读取
files = os.listdir('D:/python/data/json/') # 读取文件列表
train_data = pd.DataFrame()
test_data = pd.DataFrame()
for file in files:
with open('D:/python/data/json/' + file, 'r', encoding='utf-8') as load_f:
content = []
while True:
load_f1 = load_f.readline()
if load_f1:
load_dict = json.loads(load_f1)
content.append(re.sub('[\t\r\n]', '', load_dict['contentClean']))
else:
break
contents = pd.DataFrame(content)
contents[1] = file[:len(file) - 5]
# 划分训练集与测试集
train_data = train_data.append(contents[:400])
test_data = test_data.append(contents[400:])
def seg_word(data):
corpus = [] # 语料库
stop = pd.read_csv('D:/python/data/stopwords.txt', sep='bucunzai', encoding ='utf-8', header=None)
stopwords = [' '] + list(stop[0]) # 加上空格符号
for i in range(len(data)):
string = data.iloc[i, 0].strip()
seg_list = jieba.cut(string, cut_all=False) # 结巴分词
corpu = []
# 去除停用词
for word in seg_list:
if word not in stopwords:
corpu.append(word)
corpus.append(' '.join(corpu))
return corpus
train_corpus = seg_word(train_data) # 训练语料
test_corpus = seg_word(test_data) # 测试语料
# 将文本中的词语转换为词频矩阵,矩阵元素a[i][j]表示j词在i类文本下的词频
vectorizer = CountVectorizer()
# 统计每个词语的tf-idf权值
transformer = TfidfTransformer()
# 第一个fit_transform是计算tf-idf,第二个fit_transform是将文本转为词频矩阵
train_tfidf = transformer.fit_transform(vectorizer.fit_transform(train_corpus))
test_tfidf = transformer.fit_transform(vectorizer.fit_transform(test_corpus))
# 将tf-idf矩阵抽取出来,元素w[i][j]表示j词在i类文本中的tf-idf权重
train_weight = train_tfidf.toarray()
test_weight = test_tfidf.toarray()
# K-Means聚类
clf = KMeans(n_clusters=4) # 选择4个中心点
# clf.fit(X)可以将数据输入到分类器里
clf.fit(train_weight)
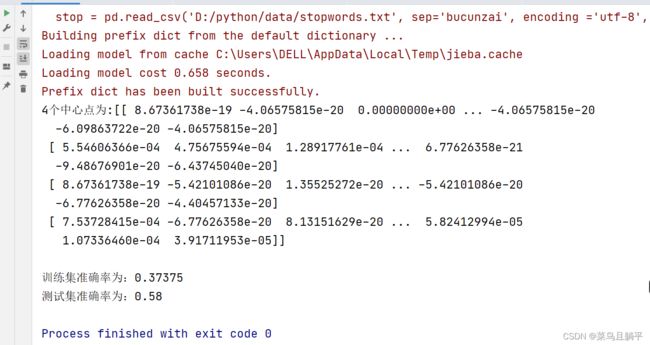
# 4个中心点
print('4个中心点为:' + str(clf.cluster_centers_))
# 保存模型
joblib.dump(clf, 'km.pkl')
train_res = pd.Series(clf.labels_).value_counts()
s = 0
for i in range(len(train_res)):
s += abs(train_res[i] - 400)
acc_train = (len(train_res) * 400 - s) / (len(train_res) * 400)
print('\n训练集准确率为:' + str(acc_train))
#print('\n每个样本所属的簇为', i + 1, ' ', clf.labels_[i])
# for i in range(len(clf.labels_)):
# print(i + 1, ' ', clf.labels_[i])
test_res = pd.Series(clf.fit_predict(test_weight)).value_counts()
s = 0
for i in range(len(test_res)):
s += abs(test_res[i] - 100)
acc_test = (len(test_res) * 100 - s) / (len(test_res) * 100)
print('测试集准确率为:' + str(acc_test))
6.文本情感分析
基于词典的文本情感分析方法,基于朴素贝叶斯的文本情感分析方法和基于SnowNLP的文本情感分析方法以及基于LDA主题模型的文本情感分析方法
import re
import jieba
import codecs
from collections import defaultdict # 导入collections用于创建空白词典
def seg_word(sentence):
seg_list = jieba.cut(sentence)
seg_result = []
for word in seg_list:
seg_result.append(word)
stopwords = set()
stopword = codecs.open('D:/python/data/stopwords.txt', 'r',
encoding='utf-8') # 加载停用词
for word in stopword:
stopwords.add(word.strip())
stopword.close()
return list(filter(lambda x: x not in stopwords, seg_result))
def sort_word(word_dict):
sen_file = open('D:/python/data/BosonNLP_sentiment_score.txt', 'r+',
encoding='utf-8') # 加载Boson情感词典
sen_list = sen_file.readlines()
sen_dict = defaultdict() # 创建词典
for s in sen_list:
s = re.sub('\n', '', s) # 去除每行最后的换行符
if s:
# 构建以key为情感词,value为对应分值的词典
sen_dict[s.split(' ')[0]] = s.split(' ')[1]
not_file = open('D:/python/data/否定词.txt', 'r+',
encoding='utf-8') # 加载否定词词典
not_list = not_file.readlines()
for i in range(len(not_list)):
not_list[i] = re.sub('\n', '', not_list[i])
degree_file = open('D:/python/data/程度副词(中文).txt', 'r+',
encoding='utf-8') # 加载程度副词词典
degree_list = degree_file.readlines()
degree_dic = defaultdict()
for d in degree_list:
d = re.sub('\n', '', d)
if d:
degree_dic[d.split(' ')[0]] = d.split(' ')[1]
sen_file.close()
degree_file.close()
not_file.close()
sen_word = dict()
not_word = dict()
degree_word = dict()
# 分类
for word in word_dict.keys():
if word in sen_dict.keys() and word not in not_list and word not in degree_dic.keys():
sen_word[word_dict[word]] = sen_dict[word] # 情感词典中的包含分词结果的词
elif word in not_list and word not in degree_dic.keys():
not_word[word_dict[word]] = -1 # 程度副词词典中的包含分词结果的词
elif word in degree_dic.keys():
# 否定词典中的包含分词结果的词
degree_word[word_dict[word]] = degree_dic[word]
return sen_word, not_word, degree_word # 返回分类结果
def list_to_dict(word_list):
data = {}
for x in range(0, len(word_list)):
data[word_list[x]] = x
return data
def socre_sentiment(sen_word, not_word, degree_word, seg_result):
W = 1 # 初始化权重
score = 0
sentiment_index = -1 # 情感词下标初始化
for i in range(0, len(seg_result)):
if i in sen_word.keys():
score += W * float(sen_word[i])
sentiment_index += 1 # 下一个情感词
for j in range(len(seg_result)):
if j in not_word.keys():
score *= -1 # 否定词反转情感
elif j in degree_word.keys():
score *= float(degree_word[j]) # 乘以程度副词
return score
def setiment(sentence):
# 对文本进行分词和去停用词,去除跟情感词无关的词语
seg_list = seg_word(sentence)
# 对分词结果进行分类,找出其中的情感词、程度副词和否定词
sen_word, not_word, degree_word = sort_word(list_to_dict(seg_list))
# 计算并汇总情感词的得分
score = socre_sentiment(sen_word, not_word, degree_word, seg_list)
return seg_list, sen_word, not_word, degree_word, score
if __name__ == '__main__':
print(setiment('电影比预期要更恢宏磅礴'))
print(setiment('煽情显得太尴尬'))
import nltk.classify as cf
import nltk.classify.util as cu
import jieba
def setiment(sentences):
# 文本转换为特征及特征选取
pos_data = []
with open('D:/python/data/pos.txt', 'r+', encoding='utf-8') as pos: # 读取积极评论
while True:
words = pos.readline()
if words:
positive = {} # 创建积极评论的词典
words = jieba.cut(words) # 对评论数据结巴分词
for word in words:
positive[word] = True
pos_data.append((positive, 'POSITIVE')) # 对积极词赋予POSITIVE标签
else:
break
neg_data = []
with open('D:/python/data/neg.txt', 'r+', encoding='utf-8') as neg: # 读取消极评论
while True:
words = neg.readline()
if words:
negative = {} # 创建消极评论的词典
words = jieba.cut(words) # 对评论数据结巴分词
for word in words:
negative[word] = True
neg_data.append((negative, 'NEGATIVE')) # 对消极词赋予NEGATIVE标签
else:
break
# 划分训练集(80%)与测试集(20%)
pos_num, neg_num = int(len(pos_data) * 0.8), int(len(neg_data) * 0.8)
train_data = pos_data[: pos_num] + neg_data[: neg_num] # 抽取80%数据
test_data = pos_data[pos_num: ] + neg_data[neg_num: ] # 剩余20%数据
# 构建分类器(朴素贝叶斯)
model = cf.NaiveBayesClassifier.train(train_data)
ac = cu.accuracy(model, test_data)
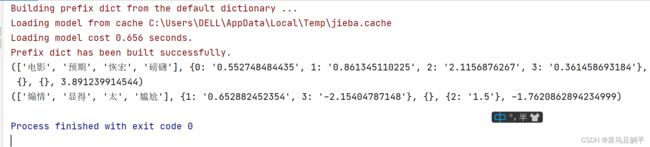
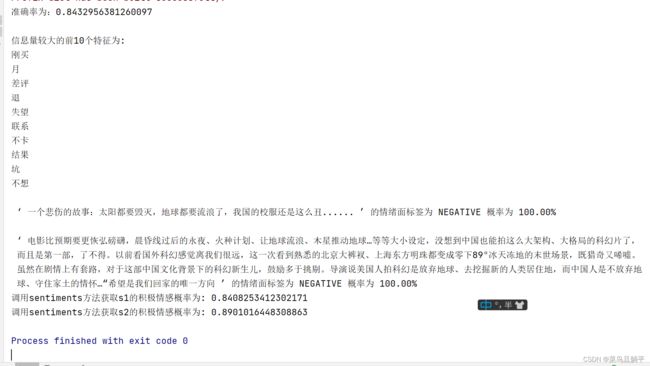
print('准确率为:' + str(ac))
tops = model.most_informative_features() # 信息量较大的特征
print('\n信息量较大的前10个特征为:')
for top in tops[: 10]:
print(top[0])
for sentence in sentences:
feature = {}
words = jieba.cut(sentence)
for word in words:
feature[word] = True
pcls = model.prob_classify(feature)
sent = pcls.max() # 情绪面标签(POSITIVE或NEGATIVE)
prob = pcls.prob(sent) # 情绪程度
print('\n','‘',sentence,'’', '的情绪面标签为', sent, '概率为','%.2f%%' % round(prob * 100, 2))
if __name__ == '__main__':
# 测试
sentences = ['一个悲伤的故事:太阳都要毁灭,地球都要流浪了,我国的校服还是这么丑....'
'..', '电影比预期要更恢弘磅礴,晨昏线过后的永夜、火种计划、让地球流浪、木'
'星推动地球…等等大小设定,没想到中国也能拍这么大架构、大格局的科幻片了,'
'而且是第一部,了不得。以前看国外科幻感觉离我们很远,这一次看到熟悉的北京大裤衩、'
'上海东方明珠都变成零下89°冰天冻地的末世场景,既猎奇又唏嘘。虽然在剧情上有套路,'
'对于这部中国文化背景下的科幻新生儿,鼓励多于挑剔。导演说美国人拍科幻是放弃地球、'
'去挖掘新的人类居住地,而中国人是不放弃地球、守住家土的情怀…“希望是我们回家的唯一方向']
setiment(sentences)
from snownlp import SnowNLP # 调用情感分析函数
# 创建snownlp对象,设置要测试的语句
s1 = SnowNLP('电影比预期要更恢宏磅礴')
s2 = SnowNLP('华语正真意义上的第一部科幻大片')
print('调用sentiments方法获取s1的积极情感概率为:',s1.sentiments)
print('调用sentiments方法获取s2的积极情感概率为:',s2.sentiments)
import pandas as pd
import jieba
from snownlp import SnowNLP
data = pd.read_csv('D:/python/data/流浪地球.csv', sep=',', encoding='utf-8', header=0)
comment_data = data.loc[: , ['content']] # 只提取评论数据
# 去除重复值
comment_data = comment_data.drop_duplicates()
# 短句删除
comments_data = comment_data.iloc[: , 0]
comments = comments_data[comments_data.apply(len) >= 4] # 剔除字数少于4的数据
# 语料压缩,句子中常出现重复语句,需要进行压缩
def yasuo(string):
for i in [1, 2]:
j = 0
while j < len(string) - 2 * i:
if string[j: j + i] == string[j + i: j + 2 * i] and (
string[j + i: j + 2 * i] == string[j + i: j + 3 * i]):
k = j + 2 * i
while k + i < len(string) and string[j: j + i] == string[j: j + 2 * i]:
k += i
string = string[: j + i] + string[k + i:]
j += 1
for i in [3, 4, 5]:
j = 0
while j < len(string) - 2 * i:
if string[j: j + i] == string[j + i: j + 2 * i]:
k = j + 2 * i
while k + i < len(string) and string[j: j + i] == string[j: j + 2 * i]:
k += i
string = string[: j + i] + string[k + i:]
j += 1
if string[: int(len(string) / 2)] == string[int(len(string) / 2):]:
string = string[: int(len(string) / 2)]
return string
comments = comments.astype('str').apply(lambda x: yasuo(x))
from gensim import corpora, models, similarities
# 情感分析
coms = []
coms = comments.apply(lambda x: SnowNLP(x).sentiments)
# 情感分析,coms在0~1之间,以0.5分界,大于0.5,则为正面情感
pos_data = comments[coms >= 0.6] # 正面情感数据集,取0.6是为了增强情感
neg_data = comments[coms < 0.4] # 负面情感数据集
# 分词
mycut = lambda x: ' '.join(jieba.cut(x)) # 自定义简单分词函数
pos_data = pos_data.apply(mycut)
neg_data = neg_data.apply(mycut)
pos_data.head(5)
neg_data.tail(5)
print(len(pos_data))
print(len(neg_data))
# 去停用词
stop = pd.read_csv('D:/python/data/stopwords.txt', sep='bucunzai', encoding='utf-8', header=None)
stop = ['', ''] + list(stop[0]) # 添加空格符号,pandas过滤了空格符
pos = pd.DataFrame(pos_data)
neg = pd.DataFrame(neg_data)
pos[1] = pos['content'].apply(lambda s: s.split(' ')) # 空格分词
pos[2] = pos[1].apply(lambda x: [i for i in x if i not in stop]) # 去除停用词
neg[1] = neg['content'].apply(lambda s: s.split(' '))
neg[2] = neg[1].apply(lambda x: [i for i in x if i not in stop])
# 正面主题分析
pos_dict = corpora.Dictionary(pos[2]) # 建立词典
pos_corpus = [pos_dict.doc2bow(i) for i in pos[2]] # 建立语料库
pos_lda = models.LdaModel(pos_corpus, num_topics=3, id2word=pos_dict) # LDA模型训练
for i in range(3):
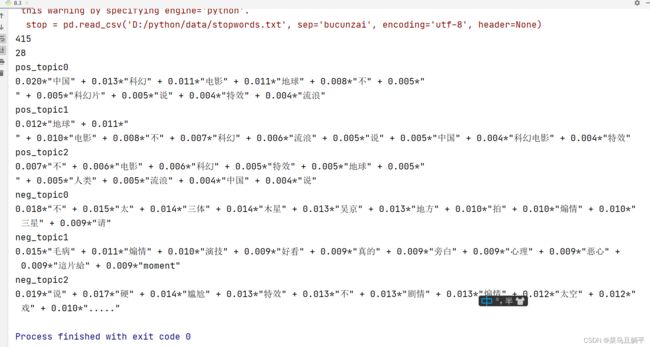
print('pos_topic' + str(i))
print(pos_lda.print_topic(i)) # 输出每个主题
# 负面主题分析
neg_dict = corpora.Dictionary(neg[2]) # 建立词典
neg_corpus = [neg_dict.doc2bow(i) for i in neg[2]] # 建立语料库,bag of word
neg_lda = models.LdaModel(neg_corpus, num_topics=3, id2word=neg_dict) # LDA模型训练
for i in range(3):
print('neg_topic' + str(i))
print(neg_lda.print_topic(i)) # 输出每个主题
三、LSTM藏头诗生成
具体讲解参考基于LSTM网络的藏头诗和古诗自动生成(附完整代码和数据)_一路狂奔的猪的博客-CSDN博客_lstm生成唐诗
训练模型,训练数据为34,646首唐诗。只做展示
import collections
import numpy as np
import tensorflow as tf
'''
Train the model
author: wangyi
Date: 2022.5.17
'''
#-------------------------------数据预处理---------------------------#
poetry_file ='D:/python/LSTM/data/poetry.txt'
poetrys = []
with open(poetry_file, "r",encoding='UTF-8') as f:
for line in f:
try:
line = line.strip(u'\n') #删除左右全部空格
title, content = line.strip(u' ').split(u':')
content = content.replace(u' ',u'')
if u'_' in content or u'(' in content or u'(' in content or u'《' in content or u'[' in content:
continue
if len(content) < 5 or len(content) > 79:
continue
content = u'[' + content + u']'
poetrys.append(content)
except Exception as e:
pass
poetrys = sorted(poetrys,key=lambda line: len(line))
print('The total number of the tang dynasty: ', len(poetrys))
# 统计每个字出现次数
all_words = []
for poetry in poetrys:
all_words += [word for word in poetry]
counter = collections.Counter(all_words)
count_pairs = sorted(counter.items(), key=lambda x: -x[1])
words, _ = zip(*count_pairs)
# 取前多少个常用字
words = words[:len(words)] + (' ',)
# 每个字映射为一个数字ID
word_num_map = dict(zip(words, range(len(words))))
# 把诗转换为向量形式,参考TensorFlow练习1
to_num = lambda word: word_num_map.get(word, len(words))
poetrys_vector = [ list(map(to_num, poetry)) for poetry in poetrys]
#[[314, 3199, 367, 1556, 26, 179, 680, 0, 3199, 41, 506, 40, 151, 4, 98, 1],
#[339, 3, 133, 31, 302, 653, 512, 0, 37, 148, 294, 25, 54, 833, 3, 1, 965, 1315, 377, 1700, 562, 21, 37, 0, 2, 1253, 21, 36, 264, 877, 809, 1]
#....]
# 每次取64首诗进行训练
batch_size = 64
n_chunk = len(poetrys_vector) // batch_size
print('n_chunk:',n_chunk)
class DataSet(object):
def __init__(self,data_size):
self._data_size = data_size
self._epochs_completed = 0
self._index_in_epoch = 0
self._data_index = np.arange(data_size)
def next_batch(self,batch_size):
start = self._index_in_epoch
if start + batch_size > self._data_size:
np.random.shuffle(self._data_index)
self._epochs_completed = self._epochs_completed + 1
self._index_in_epoch = batch_size
full_batch_features ,full_batch_labels = self.data_batch(0,batch_size)
return full_batch_features ,full_batch_labels
else:
self._index_in_epoch += batch_size
end = self._index_in_epoch
full_batch_features ,full_batch_labels = self.data_batch(start,end)
if self._index_in_epoch == self._data_size:
self._index_in_epoch = 0
self._epochs_completed = self._epochs_completed + 1
np.random.shuffle(self._data_index)
return full_batch_features,full_batch_labels
def data_batch(self,start,end):
batches = []
for i in range(start,end):
batches.append(poetrys_vector[self._data_index[i]])
length = max(map(len,batches))
xdata = np.full((end - start,length), word_num_map[' '], np.int32)
for row in range(end - start):
xdata[row,:len(batches[row])] = batches[row]
ydata = np.copy(xdata)
ydata[:,:-1] = xdata[:,1:]
return xdata,ydata
#---------------------------------------RNN--------------------------------------#
#tf.nn.rnn_cell,tf.contrib.rnn.
input_data = tf.placeholder(tf.int32, [batch_size, None])
output_targets = tf.placeholder(tf.int32, [batch_size, None])
# 定义RNN
def neural_network(model='lstm', rnn_size=128, num_layers=2):
if model == 'rnn':
cell_fun = tf.contrib.rnn.BasicRNNCell
elif model == 'gru':
cell_fun = tf.contrib.rnn.GRUCell
elif model == 'lstm':
cell_fun = tf.contrib.rnn.BasicLSTMCell
cell = cell_fun(rnn_size, state_is_tuple=True)
cell = tf.contrib.rnn.MultiRNNCell([cell] * num_layers, state_is_tuple=True)
initial_state = cell.zero_state(batch_size, tf.float32)
with tf.variable_scope('rnnlm'):
softmax_w = tf.get_variable("softmax_w", [rnn_size, len(words)])
softmax_b = tf.get_variable("softmax_b", [len(words)])
with tf.device("/cpu:0"):
embedding = tf.get_variable("embedding", [len(words), rnn_size])
inputs = tf.nn.embedding_lookup(embedding, input_data)
outputs, last_state = tf.nn.dynamic_rnn(cell, inputs, initial_state=initial_state, scope='rnnlm')
output = tf.reshape(outputs,[-1, rnn_size])
logits = tf.matmul(output, softmax_w) + softmax_b
probs = tf.nn.softmax(logits)
return logits, last_state, probs, cell, initial_state
def load_model(sess, saver,ckpt_path):
latest_ckpt = tf.train.latest_checkpoint(ckpt_path)
if latest_ckpt:
print ('resume from', latest_ckpt)
saver.restore(sess, latest_ckpt)
return int(latest_ckpt[latest_ckpt.rindex('-') + 1:])
else:
print ('building model from scratch')
sess.run(tf.global_variables_initializer())
return -1
#训练
def train_neural_network():
logits, last_state, _, _, _ = neural_network()
targets = tf.reshape(output_targets, [-1])
#tf.contrib.legacy_seq2seq.sequence_loss_by_example tf.nn.seq2seq.sequence_loss_by_example
loss = tf.contrib.legacy_seq2seq.sequence_loss_by_example([logits], [targets], [tf.ones_like(targets, dtype=tf.float32)], len(words))
cost = tf.reduce_mean(loss)
learning_rate = tf.Variable(0.0, trainable=False)
tvars = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(cost, tvars), 5)
#optimizer = tf.train.GradientDescentOptimizer(learning_rate)
optimizer = tf.train.AdamOptimizer(learning_rate)
train_op = optimizer.apply_gradients(zip(grads, tvars))
Session_config = tf.ConfigProto(allow_soft_placement=True)
Session_config.gpu_options.allow_growth = True
trainds = DataSet(len(poetrys_vector))
with tf.Session(config=Session_config) as sess:
with tf.device('/gpu:2'):
sess.run(tf.initialize_all_variables())
saver = tf.train.Saver(tf.all_variables())
last_epoch = load_model(sess, saver,'model/')
for epoch in range(last_epoch + 1,100):
sess.run(tf.assign(learning_rate, 0.002 * (0.97 ** epoch)))
#sess.run(tf.assign(learning_rate, 0.01))
all_loss = 0.0
for batche in range(n_chunk):
x,y = trainds.next_batch(batch_size)
train_loss, _ , _ = sess.run([cost, last_state, train_op], feed_dict={input_data: x, output_targets: y})
all_loss = all_loss + train_loss
if batche % 50 == 1:
#print(epoch, batche, 0.01,train_loss)
print(epoch, batche, 0.002 * (0.97 ** epoch),train_loss)
saver.save(sess, 'model/poetry.module', global_step=epoch)
print (epoch,' Loss: ', all_loss * 1.0 / n_chunk)
if __name__=='__main__':
train_neural_network()
训练好的模型

藏头诗生成
import collections
import numpy as np
import tensorflow as tf
'''
This one will produce a poetry with heads.
author: wangyi
Date: 2022.5.17
'''
#-------------------------------数据预处理---------------------------#
poetry_file ='D:/python/LSTM/data/poetry.txt'
# 诗集
poetrys = []
with open(poetry_file, "r",encoding='UTF-8') as f:
for line in f:
try:
line = line.strip(u'\n')
title, content = line.strip(u' ').split(u':')
content = content.replace(u' ',u'')
if u'_' in content or u'(' in content or u'(' in content or u'《' in content or u'[' in content:
continue
if len(content) < 5 or len(content) > 79:
continue
content = u'[' + content + u']'
poetrys.append(content)
except Exception as e:
pass
# 按诗的字数排序
poetrys = sorted(poetrys,key=lambda line: len(line))
print('The total number of the tang dynasty: ', len(poetrys))
# 统计每个字出现次数
all_words = []
for poetry in poetrys:
all_words += [word for word in poetry]
counter = collections.Counter(all_words)
count_pairs = sorted(counter.items(), key=lambda x: -x[1])
words, _ = zip(*count_pairs)
# 取前多少个常用字
words = words[:len(words)] + (' ',)
# 每个字映射为一个数字ID
word_num_map = dict(zip(words, range(len(words))))
# 把诗转换为向量形式,参考TensorFlow练习1
to_num = lambda word: word_num_map.get(word, len(words))
poetrys_vector = [ list(map(to_num, poetry)) for poetry in poetrys]
#[[314, 3199, 367, 1556, 26, 179, 680, 0, 3199, 41, 506, 40, 151, 4, 98, 1],
#[339, 3, 133, 31, 302, 653, 512, 0, 37, 148, 294, 25, 54, 833, 3, 1, 965, 1315, 377, 1700, 562, 21, 37, 0, 2, 1253, 21, 36, 264, 877, 809, 1]
#....]
# 每次取64首诗进行训练
batch_size = 1
n_chunk = len(poetrys_vector) // batch_size
print (n_chunk)
#数据的传入过程
class DataSet(object):
def __init__(self,data_size):
self._data_size = data_size
self._epochs_completed = 0
self._index_in_epoch = 0
self._data_index = np.arange(data_size)
def next_batch(self,batch_size):
start = self._index_in_epoch
if start + batch_size > self._data_size:
np.random.shuffle(self._data_index)
self._epochs_completed = self._epochs_completed + 1
self._index_in_epoch = batch_size
full_batch_features ,full_batch_labels = self.data_batch(0,batch_size)
return full_batch_features ,full_batch_labels
else:
self._index_in_epoch += batch_size
end = self._index_in_epoch
full_batch_features ,full_batch_labels = self.data_batch(start,end)
if self._index_in_epoch == self._data_size:
self._index_in_epoch = 0
self._epochs_completed = self._epochs_completed + 1
np.random.shuffle(self._data_index)
return full_batch_features,full_batch_labels
def data_batch(self,start,end):
batches = []
for i in range(start,end):
batches.append(poetrys_vector[self._data_index[i]])
length = max(map(len,batches))
xdata = np.full((end - start,length), word_num_map[' '], np.int32)
for row in range(end - start):
xdata[row,:len(batches[row])] = batches[row]
ydata = np.copy(xdata)
ydata[:,:-1] = xdata[:,1:]
return xdata,ydata
#---------------------------------------RNN--------------------------------------#
#
input_data = tf.placeholder(tf.int32, [batch_size, None])
output_targets = tf.placeholder(tf.int32, [batch_size, None])
# 定义RNN
def neural_network(model='lstm', rnn_size=128, num_layers=2):
# if model == 'rnn':
# cell_fun = tf.contrib.rnn.BasicRNNCell
# elif model == 'gru':
# cell_fun = tf.contrib.rnn.GRUCell
# elif model == 'lstm':
# cell_fun =tf.contrib.rnn.BasicLSTMCell
# cell = cell_fun(rnn_size, state_is_tuple=True)
cell=tf.contrib.rnn.BasicLSTMCell(rnn_size, state_is_tuple=True)
#堆叠RNNCell:MultiRNNCell
cell = tf.contrib.rnn.MultiRNNCell([cell] * num_layers, state_is_tuple=True)
initial_state = cell.zero_state(batch_size, tf.float32)
with tf.variable_scope('rnnlm'):
softmax_w = tf.get_variable("softmax_w", [rnn_size, len(words)])
softmax_b = tf.get_variable("softmax_b", [len(words)])
with tf.device("/cpu:0"):
embedding = tf.get_variable("embedding", [len(words), rnn_size])
inputs = tf.nn.embedding_lookup(embedding, input_data)
#一次执行多步:tf.nn.dynamic_rnn
outputs, last_state = tf.nn.dynamic_rnn(cell, inputs, initial_state=initial_state, scope='rnnlm')
output = tf.reshape(outputs,[-1, rnn_size])
logits = tf.matmul(output, softmax_w) + softmax_b
probs = tf.nn.softmax(logits)
return logits, last_state, probs, cell, initial_state
print('LSTM definition finish!')
#-------------------------------生成古诗---------------------------------#
# 使用训练完成的模型
def gen_head_poetry(heads, type):
if type != 5 and type != 7:
print('The second para has to be 5 or 7!')
return
def to_word(weights):
t = np.cumsum(weights)
s = np.sum(weights)
sample = int(np.searchsorted(t, np.random.rand(1)*s))
return words[sample]
_, last_state, probs, cell, initial_state = neural_network()
Session_config = tf.ConfigProto(allow_soft_placement = True)
Session_config.gpu_options.allow_growth=True
with tf.Session(config=Session_config) as sess:
with tf.device('/gpu:1'):
sess.run(tf.global_variables_initializer())#tf.initialize_all_variables()
saver = tf.train.Saver(tf.all_variables())
saver.restore(sess, 'model/poetry.module-99')
poem = ''
for head in heads:
flag = True
while flag:
state_ = sess.run(cell.zero_state(1, tf.float32))
x = np.array([list(map(word_num_map.get, u'['))])
[probs_, state_] = sess.run([probs, last_state], feed_dict={input_data: x, initial_state: state_})
sentence = head
x = np.zeros((1,1))
x[0,0] = word_num_map[sentence]
[probs_, state_] = sess.run([probs, last_state], feed_dict={input_data: x, initial_state: state_})
word = to_word(probs_)
sentence += word
while word != u'。':
x = np.zeros((1,1))
#print (x)
x[0,0] = word_num_map[word]
#print (x)
[probs_, state_] = sess.run([probs, last_state], feed_dict={input_data: x, initial_state: state_})
word = to_word(probs_)
sentence += word
if len(sentence) == 2 + 2 * type:
sentence += u'\n'
poem += sentence
flag = False
return poem
if __name__ == '__main__':
print(gen_head_poetry(u'美丽黄科大',5))
print('-----------Secondary creation by wangyi')
结果展示

修改代码可以对应生成五言或者七言藏头诗。