NLP学习笔记3--Lecture/Decision Tree 、Random Forest、 XGboost
WHAT'S NLP?
目录
WHAT'S NLP?
NLP技术四个维度:
NLP的应用场景:
决策树
熵
ID3算法
C4.5算法
CART Tree
ensemble learning
随机森林
XGBoost 陈天奇的设计理念
bias variance tradeoff
如何做ensemble?
训练中试图优化的是什么东西??
如何去学习每一个树 (fk)
如何定义目标函数?
如何做gradient boosting?
重点:如何定义XGBoost里面的一棵树?
如何衡量一棵树的复杂程度?//如何表示正则项
但我们不可能遍历所有的树的结构,如何解决?
如何在搜索树的过程中做优化?
对于离散的变量怎么办?
最后回顾一下 XGBoost算法是怎么设计的?
summary
NLP = NLU + NLG//自然语言理解+自然语言生成
NLP相关会议 先看已发表的论文 优先顶会 引用量
NLP:ACL,EMNLP,NAACL,Coling,TACL
DM:KDD,WSDM,SIGIR,WWW,CIKM
ML:NIPS,ICML,ICLR,AISTATS,UAI,JMLR,PAMI(新的模型和方法)
AI:AAAI,IJCAI
NLP技术四个维度:
Semantic(语义)情感分析 机器翻译
Syntax(句子结构)CFG CCG
Morphology(单词) 分词 单词形态变化 语言学
Phonetics(声音)文本转语音
NLP的应用场景:
问答系统/对话系统 (终极目标) 使用文本输入输出交流 目前针对于具体小任务 阿里小蜜等等
数据挖掘/情感分析 淘宝收集商品评论 分析评论
机器翻译 中英互译等等
文本摘要 自动生成一段摘要 更有描述性
信息抽取 在一段文字中抽取出合适的信息扔给下游任务
决策树

决策树 把这些if else规则可视化 一个决策树定义在特征空间与类空间上的条件概率分布 把特征划分成不同的区域 给不同的区域不同的概率
整个过程可视化 分类过程快
包含三个步骤: 特征选择 》》》决策树生成》》》决策树修剪
从根节点开始 寻找从根节点到叶子节点的路径
怎么构建一个决策树?
从训练数据里归纳出来一套if-else规则
怎么排不同特征的优先级 一个递归过程
熵
可以衡量不确定性 不确定性越大 熵越大

information gain: 一旦特征确定可以带来多少熵的增益
于是就可以计算每一个特征的信息增益 选择信息增益最大的一项 就是最优特征
信息增益比:information gain ratio
ID3算法

从根节点开始 选择信息增益最大的特征 进行分裂 由特征的不同建立不同的子节点
C4.5算法
把信息增益换成信息增益比的话就是C4.5算法
选择信息增益比的好处 可以一定程度上正则化那些可以有很多不同选择的特征

用递归的方法生成决策树 一般来说对训练数据分类较为准确 但是对未知数据预测并不太准
如何防止过拟合?
考虑限制决策树的复杂度
1.pre-pruning 在生长树的过程中 随时在一个测试数据集上验证准确性
一旦准确性开始下降或者达到一定目标就stop 不会继续生长 相当于提前停止训练
2.post-pruning 先不考虑过拟合 先长出来一棵树 先构造出一套规则 尽量拟合我们的数据
然后进行剪枝 对效果不好的分支cut掉 (尝试去掉 测试准确性 如果有提升 则剪枝正确 反之)
以上为较为简单的决策树 一般用于比较简单的分类 但仍有一些回归任务需要解决 如明天的温度
就此有了
CART Tree
和决策树的区别:1.假设每一个分类都是一个二叉树(分为两类 二分的差分)
2.如果用在分类任务上 用什么准则选择最优特征?用Gini指数 (可以替换信息增益) 计算信息增益时 计算对数计算量大 所以出现了Gini系数 计算更快
同时Gini系数是信息增益的一个很好的近似 而且可以做回归任务

ensemble learning
试图在一个训练数据上 取出不同子集训练多个决策树 sample M个子集 M个树为base learner 然后组合起来生成一个更强的分类器 这一过程也叫bagging
Bagging: Train multiple independent Learners 可以很大程度提高泛化性
Boosting:Train multiple dependent Learner
由此引出
随机森林
如何训练每一个base learner
其中一个最简单的方式 :随机采样训练每一个子树 bootstrap :从训练数据集中采样固定个数个样本 每次采样batchsize个样本组成Dbs 用采样出来的子集去训练 学习得到一个baselearner 一直重复t次 然后采用多数投票的方式 融合起来 ---------图中的63.8% 是指用于训练的数据 而其余未被用到的数据称为out of bag 袋外数据 一定程度上也可以增加模型的泛化能力 相当于dropout
另一种 feature bagging :不采样数据 采样特征 一共收集到N个feature 对于每个base learner 用采样出来的feature训练base learning 然后bagging起来

XGBoost 陈天奇的设计理念
Review of key concepts of supervised learning
Regression Tree and Ensemble(What are we learning)
Gradient Boosting(How do we learn)
interpretation 解释,理解 

Training Loss 衡量我们的模型拟合训练数据的程度 Regularization 正则项 衡量模型复杂度
还有Ridge regression 、Lasso 、逻辑回归 component n.组成部分、成分 tradeoff 权衡
都会涉及到
bias variance tradeoff
偏差和方差的权衡 以下为通俗理解
如何做ensemble?
直接把base learner 得到的预测分数加起来
优点 不需要手工选择特征 能很好地防止过拟合(随机sampling)
能很好地学习特征之间的交互(被选中特征的关联程度)
scalable 可扩展 工业上很好扩展
训练中试图优化的是什么东西??
1.树本身的结构
2.每一个叶子结点的得分
1.2 可以确定出唯一的树
更加抽象的来看 可以直接把每个树作为优化的参数 这些树本身就是需要优化的参数

如何去学习每一个树 (fk)
每个回归树f(i)本质上就是一个函数 学习的过程就是最优化的过程
定义一个目标函数 然后优化
example : 是否喜欢听浪漫的音乐
随着时间的增加 浪漫音乐的喜好程度不同
定义树的结构 在哪个特征进行分裂
每一个分裂完之后的取值
如何定义目标函数?
training loss可以衡量bias 简单理解为准(比较预测值与真实值)
加 regularization可以衡量variance 简单理解为不发散 或者种类少 不复杂(如何衡量复杂程度:此处1.在几个点进行分裂(树的节点的数量) 2.计算对于这些height的L2norm)

信息熵增益 》》 减少训练误差
pruning 》》减少正则误差
max depth/ early stop 》》给搜索空间加限定
smoothing leaf value 限定取值不会有很大偏差 》》相当于给leaf weights加上L2norm
针对不同的任务需要定义不同的目标函数
在XGBoost里面 我们是如何学习各个回归树的?
如何做gradient boosting?

我们要学习的是一个树 而不是连续向量 故不能使用sgd 如何解决?
solution:Additive training (boosting算法) 用boosting做ensemble
在定好初始值之后 每一步添加一个新的树 每次一学习等到一个新的树 得到的新树和之前的值加起来可以得到一个更优的结果 (每一次学到的新的树都是依赖于之前学到的树)
相较于bagging 这里引入之前bagging的解释 bagging学到的每一个决策树都是独立的(因为独立采样出来不同的子集)
但boosting在前一个时间的结果上进行进一步迭代 (联想到rnn)
ensemble learning
试图在一个训练数据上 取出不同子集训练多个决策树 sample M个子集 M个树为base learner 然后组合起来生成一个更强的分类器 这一过程也叫bagging
Bagging: Train multiple independent Learners 可以很大程度提高泛化性
Boosting:Train multiple dependent Learner
选择使训练目标损失下降最大的树

提到一种方法 用泰勒展开优化目标函数 用近似的思想去掉高阶项 简化目标函数
得到的新目标函数
在这里插入一下 在知乎里看到的一个评论

就是说 在这里 理论上 我们用近似的思想 将目标函数简化成一个二次函数的形式看似是非常的完美 但在实际应用中 参数量和理论中所用到的参数量根本不在一个量级
就是这里省去的泰勒公式高阶项 在真实参数量非常大的情况下 可能已经不能被看做是一个近似值了

两个优点:1.可以清楚地看到优化目标长什么样子,在一定程度上衡量什么时候可以coverage
2.刚才的得到的优化目标 和训练的loss函数是独立的 可以分别封装loss函数和优化过程 如果两种boosted tree 的训练 就可以只改变loss函数的部分 不改变优化的部分
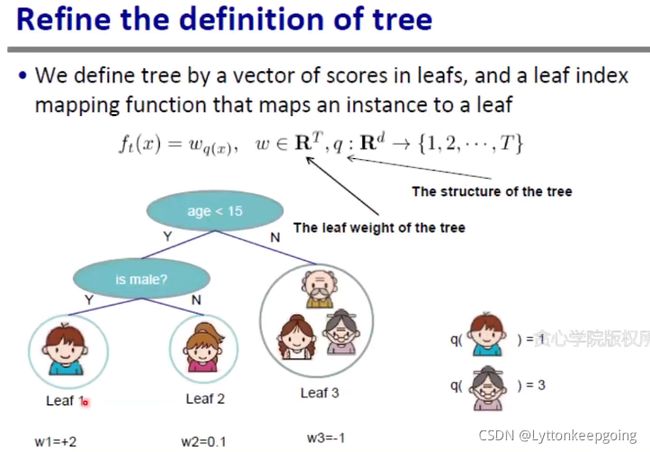
重点:如何定义XGBoost里面的一棵树?
我们用两个变量表示一棵树
1.一个向量 向量表示 各个叶子节点对应的值
2.映射函数 把每一个输入映射到一个叶子节点中去 不需要care中间的结构 给定一个x 就能得到这个x对应哪一个叶子节点
1.就代表之前说的 每一个叶子节点对应的weight
2.就代表树的结构
只需要定义这两个变量就可以确定一棵唯一的树
如何衡量一棵树的复杂程度?//如何表示正则项

numbers of leaves 和L2norm of leaves scores(尽量接近于原点)
引入一个j 把目标函数 进行一个代换 就可以简化为一个关于wj的二次函数!!

再简化!
如果我们的树的形状是固定的 我们就可以直接套用二次函数的结果 得到目标函数的最优值
我们可以用目标函数的最小值 衡量出我们树的结构好不好
比较最优的目标函数的值 哪个最小 更小及更优 可以通过这个方法搜索我们树的结构
我们可以遍历所有树的结构 对于每一个树都算一个最优函数值 然后取最小的一个 作为当前树的结构
但我们不可能遍历所有的树的结构,如何解决?
提出一种贪心算法 试图做一个近似 尽量选择出一个尽量优的结构
先假设这个树只有一个节点 对于每一个特征都会增加一个分裂(二分)
提出一个gain的定义 做这个分裂 我们可以得到什么好处?
我们用 分裂之后目标函数的最优值减去分裂之前目标函数的最优值 定义这个gain值
选择最优分裂

如何在搜索树的过程中做优化?
1.对于每一个特征 可以先排个序
2.搜索分类的时候只需要做一个线性的扫描 就可以找到一个最优点

trick
对于离散的变量怎么办?
和我想的一样 one-hot编码 把离散的特征做一个embedding
在优化的过程中可能得到一个熵的负增益 Gain为负值
如何调整?

和之前一样 early stopping 和剪枝两种方法
最后回顾一下 XGBoost算法是怎么设计的?

1.首先它是一个回归树的ensemble算法 学习出一堆回归树 最后的结果就是这一堆回归树的加和
2.在每次迭代过程中学习出一个新的树:在每次迭代的过程中计算出一些常量(损失函数关于y的一二阶导)
3.我们根据这两个常量搜索出一个最优的树的结构:对于每一个树的结构 我们都能计算出一个目标函数的最优值 最优值最小的结构 就是我们要的最优结构 同时在搜索的过程中用到了贪心算法 定义一个gain 去选择我们需要搜索的树的结构
4. 我们得到的最优树的结构 再用boost算法 讲新得到的ft(x)加上上一时刻得到的输出 生成一个新的输出 然后再衡量一下我们新得到的结果能不能满足我们的需求 选择是否early stopping
trick 加上一个参数 给新旧输出加一个权重 尽量降低之前输出的权重 并增加新输出的权重
summary
1.我们把模型 参数 目标函数 或者说损失函数和正则项 这些概念分开考虑 可以给我们时间带来很多方便 ---简单理解 哪里不对调哪里
2.对于bias-variance 的tradeoff 简单理解 一个模型在训练数据集上的性能和在测试数据集上的性能的tradeoff // 但在实际应用中可能很多都更偏向于过拟合 只要数据足够大就可以把一切都拟合
简单理解 学的越多 我就越厉害 性能就越好 我管你是不是过拟合
3.以一个非常好的角度介绍了设计理念 且代码可复用性高 //广泛应用于各种比赛
还有一些boost树的变种 LightGBM,CatBoost 遇到了再学
争取下周复现一下这个代码。。