BiLSTM+CRF实现AI诗人与长短记忆网络
BiLSTM+CRF实现AI诗人与长短记忆网络
所用程序说明:
main.py: 为主程序, 在命令行运行方式为:python main.py –-mode train 或 python main.py –-mode test或 python main.py –-mode head
makedata.py: 将三万首唐诗制作成若干批训练集。并将此诗集出现的所有汉字制成一个字典。
header.py: 一些全局参数的定义。
model.py: 构建模型。训练模型。测试模型。
本实训旨在通过AI诗人神经网络让学员了解如何用Tensorflow构建反馈网络。完成本实训项目大约需要100分钟。
实验目标:
1、熟悉自然语言处理及文本读取。
2、熟悉如何用向量表征语言。
3、掌握如何用Tensorflow编写反馈网络。
主要步骤:
1、 将三万多首唐诗通过makedata.py输入到模型中
2、 搭建训练模型
3、 构建训练过程
4、 编写写诗过程
step1 makedata.py
步骤一 将三万多首唐诗通过makedata.py输入到模型中。通过命令行一步一步熟悉如此处理文字文件和数据。
具体的过程实现如下图所示:
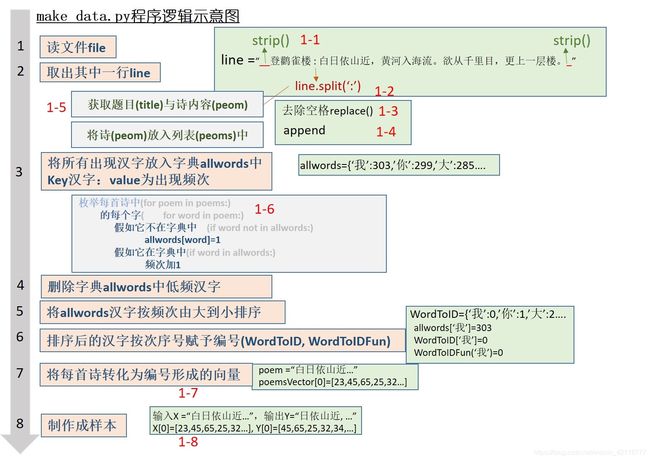
1-1、1-2将line字符串的前后空格删除,将它以’:'为分割标志,分成title和poem。
poems = []
file = open(filename, "r", encoding="gbk")
for line in file: # 每行储存一首诗
# 将line开头及结尾处的空格删除,然后分成题目title与诗体peom
title,poem=line.strip().split(':')
## strip()将line开头及结尾处的空格等其它非文字符号删除
## split是分割函数,将字符串分割成“字符”,保存在一个列表中
1-3、1-4、1-5去除空格、其他字符,获取题目与诗的内容
poem = poem.replace(' ','') #去除诗中的空格
## replace替换函数。
if '_' in poem or '《' in poem or '[' in poem or '(' in poem or '(' in poem:
continue
## 去除poem的其它字符
if len(poem) < 10 or len(poem) > 128:
continue
## 确保poem长度适当
poem = '[' + poem + ']' #add start and end signs
poems.append(poem)
# 将poem加到列表 poems当中
1-6 动作:将诗集中出现的汉字根据出现频次制作一个字典,储存于变量allWords之中。
allWords = {}
# 定义一个空的字典(dictionary)
# key:为汉字
# 字典的值value:为该汉字出现的频次
# 代码仿照写处2
for poem in poems: # 枚举诗歌列表中所有诗
for word in poem: # 枚举每首诗中所有的字
if word not in allWords:
allWords[word] = 1 # 假如该汉字还没出现过
else:
allWords[word] += 1
# 删除低频字
erase = []
for key in allWords: # 枚举字典allwords中的所有字key
if allWords[key] < 2: #假如其频次小于2,加入待删列表
erase.append(key)
for key in erase:
del allWords[key]
1-7 将每首诗转换成一个向量
wordPairs = sorted(allWords.items(), key = lambda x: -x[1])
# 所有出现的汉字按出现频次,由多到少排序。
# 函数items,用于取出字典的key和值。
# key = lamda表示按key的值进行排序,按x的第1维进行排序
words, a= zip(*wordPairs) # *wordpairs 将wordpairs解压(unzip)
# zip()将输入变量变成turple
words += (" ", ) # 将空格加在最后。
wordToID = dict(zip(words, range(len(words)))) #word to ID
# 把每个汉字赋予一个数。
wordTOIDFun = lambda A: wordToID.get(A, len(words)) # 转化成函数,
# 输入汉字,输出它对应的数。
poemsVector = [([wordTOIDFun(word) for word in poem]) for poem in poems] # poem to vector
## 将所有的诗转化成向量,其中一首诗中,数字用turple储存,在外面用列表储存。
## 类似这样。[(1 3 2 4), (2 3 4 1), (1 5 6 2)]
1-8制作训练样本
batchNum = (len(poemsVector) - 1) // batchSize # // 除法将余数去掉,如10//3 = 3
X = []
Y = []
#create batch
for i in range(batchNum):
batch = poemsVector[i * batchSize: (i + 1) * batchSize]
# batch 储存了 batchsize诗的向量
maxLength = max([len(vector) for vector in batch])
# 得到一个batch其中一首最长的诗的长度
temp = np.full((batchSize, maxLength), wordTOIDFun(" "), np.int32)
#将temp初始化成batchsize * maxlength的矩阵,其中矩阵元素初始值皆为空格对应的ID。
for j in range(batchSize):
temp[j, :len(batch[j])] = batch[j]
#将temp 储存了一批诗对应的矩阵
# 代码粘贴处4
X.append(temp) # 把这个矩阵放入列表X中,
temp2 = np.copy(temp)
temp2[:, :-1] = temp[:, 1:]#将诗向前挪一个字的位置对应的向量放入Y中。
Y.append(temp2)
#提示:比如:输入X =“白日依山近…”,输出Y=“日依山近, …”。
# 将字往向前移一个字。比如
# temp = [(白日依山进),()]->temp2 [(日依山进进), ()]
# X -> Y相当于只挪动一个字。
return X, Y, len(words) + 1, wordToID, words
step2 搭建训练模型 model.py
下图为buildmodel函数的示意图。它的基本思路:先将一批样本gtX[16X122]矩阵(相当于整数表征)通过embedding_lookup,将其转成向量表征inputbatch;然后,搭建动态RNN,这个RNN基本单元basicCell是一个LSTM,由它堆两层形成stackCell,然后再动态形成RNN(其中 t = 1到122)
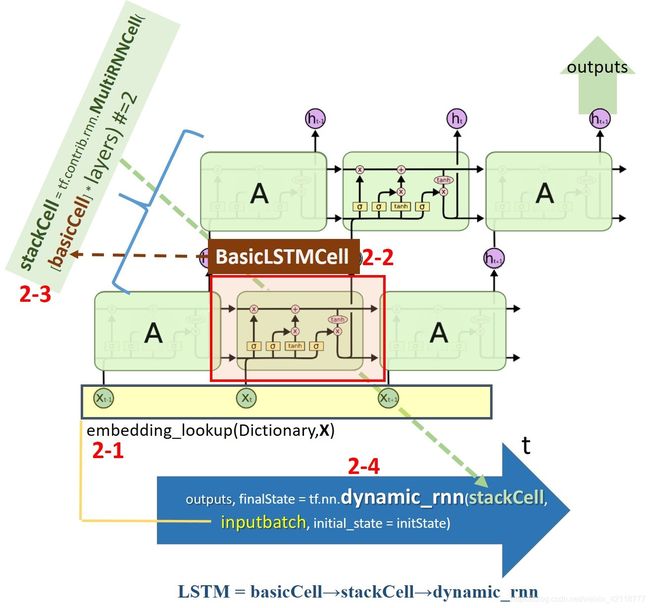
2-1将输入buildmodel的变量gtX(整数表征),通过内嵌表embedding,转变成向量表征变量inputbatch。
with tf.variable_scope("embedding"): #embedding
embedding = tf.get_variable("embedding", [wordNum, hidden_units], dtype = tf.float32)
# embedding 为 n * m维的矩阵,其中n为涉及的汉字的数目,m为隐藏LSTM单元的数目
# 将汉字用hidden_units维向量重新表征,训练RNN的其中一个目的就是为了找到embedding这个矩阵
## 代码仿写处 1
#将输入buildmodel的变量gtX(整数表征),通过内嵌表embedding,转变成向量表征变量inputbatch。
inputbatch = tf.nn.embedding_lookup(embedding, gtX)
# 将16首诗转化为向量表达。
# embedding_lookup(params, ids)其实就是按照ids顺序返回params中的第ids行。比如说,
#ids=[1,3,2],就是返回params中第1,3,2行。返回结果为由params的1,3,2行组成的tensor。
# gtx: batchsize * hidden_units, embedding (wordnum*hidden)
# inputbatch: batchsize * maxLength * hidden
1-2构建LSTM单元
basicCell = tf.contrib.rnn.BasicLSTMCell(hidden_units, state_is_tuple = True)
2-3 动作:将LSTM单元垒起来。
#将LSTM单元垒起来
stackCell = tf.contrib.rnn.MultiRNNCell([basicCell] * layers)
2-4 动作:构建动态RNN
#构建动态RNN。
initState = stackCell.zero_state(np.shape(gtX)[0], tf.float32)
outputs, finalState = tf.nn.dynamic_rnn(stackCell, inputbatch, initial_state = initState)
outputs = tf.reshape(outputs, [-1, hidden_units])
step3 定义训练过程
计算成本函数。将一个样本gtX,gtY代入buildmodel函数计算出logits, probs之后,就可以计算其成本函数了
loss = tf.contrib.legacy_seq2seq.sequence_loss_by_example([logits], [targets],
[tf.ones_like(targets, dtype=tf.float32)], wordNum)
cost = tf.reduce_mean(loss) # 定义损耗函数
计算梯度
相关资料如下,有多种计算梯度的方法
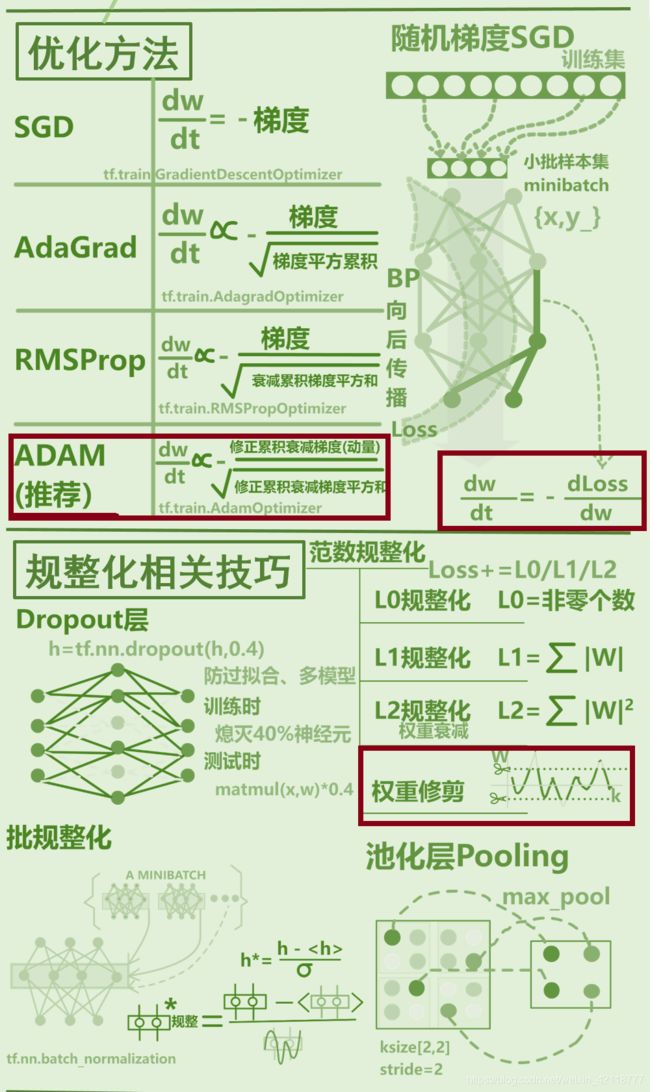
选择优化方法
optimizer = tf.train.AdamOptimizer(learningRate)
构建训练器
trainOP = optimizer.apply_gradients(zip(grads, tvars))
step4、编写写诗过程
(只实训head这个过程。)比如输入"白黄",它返回"白日依山近,黄河入海流。"
理解probtoword函数。训练好的Model最终输入下一个字出现的概率(它依赖于前面几个字的输入)。它储存在一个5667维的数组,即这5667汉字的出现的概率分别是多少。当然可取概率最大的那个,但这将导致每次都出现同一个词。因此,需要将概率较大的几个当中随机选择一个,但同时使得概率原来越大的被选中的概率也越大。
完成probtoword函数。输入一个概率分布weights(5667个小于1的数字),在概率较大的几个中随机选择一个输出汉字。为了达到这个目的,先用cumsum(累加)函数将分布变成累积分布函数,这样只要取0到1的一个随机数,那么可以证明它落入初始概率大的那个格子的概率正比于原来分布中的概率,如下图所示。
完成testhead函数。请仔细阅读testhead函数。它先导入训练好的网络参数,然后构建初始状态。一个个字往后预测出后面的字出现的概率,并概率转变成汉字
打开文件main.py,修改第33行(也可不改),尝试输入不同的四个或多个汉字(每句诗的诗头),然后 在命令行输入。(比如"白黄欲更")看看AI能创造出什么诗来
具体代码见https://github.com/Arfer-ustc/AI_Poem_BiLstm_CRF.git