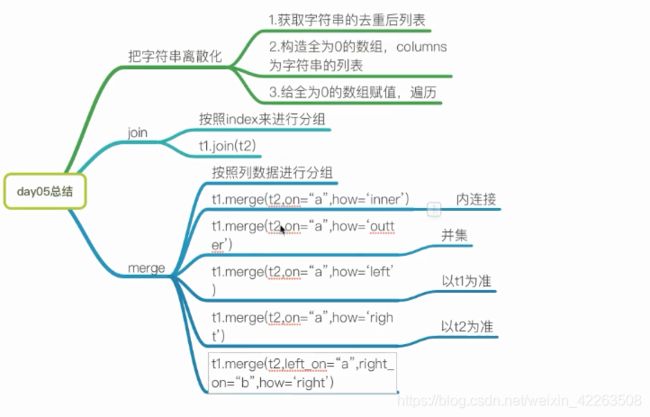
数据分析10章-数据的合并和分组聚合
1.对非数值型且多类别数据的处理方式
2.groupby
01字符串离散化的案例–对非数值型且多类别数据的处理方式
视频中的数据没有,所以自己制作数据,自己采用的是中电比赛的一个数据:采用了Alarm_equip列中的数据:你们可以自己制作数据来实现
1.导入数据,并删去无数据的行列
import pandas as pd
import numpy as np
file_path = './trainData-V1.csv'
df = pd.read_csv(file_path)
df = df.dropna()

2.对特征中的非数值型多列别的数据进行处理
选择10行的数据进行处理:
#------------对特征有多个类别的时候处理方式------------------
#在series里面,tolist是没有下划线的,在dataFrame里面to_list是有下划线的
#Alarm_list:[[],[],[]]
Alarm_list = df['Alarm_equipment'][:10].str.split(",|,").tolist()
Alarm=[]
for i in Alarm_list:
Alarm.extend(i)
Alarm = list(set(Alarm))
#-----------------构造为0的数组----------------
zero_df = pd.DataFrame(np.zeros((10,len(Alarm))),columns=Alarm)
#--------------给每个出现的标签赋值1--------------
for i in range(len(zero_df)):
# zero_df.loc[0,['_r1wt','_r2wt','_r3wt']] = 1
zero_df.loc[i,Alarm_list[i]] = 1
print(zero_df)


完整代码:
import pandas as pd
import numpy as np
file_path = './trainData-V1.csv'
df = pd.read_csv(file_path)
# print(df.info())
#
# print(df.head(1))
# print(list(df["Alarm_equipment"][:100].str.split(',|,')))
df = df.dropna()
# print(df['Alarm_equipment'][:10].str.split(",|,").tolist())
#------------对特征有多个类别的时候处理方式------------------
Alarm_list = df['Alarm_equipment'][:10].str.split(",|,").tolist()#在series里面,tolist是没有下划线的,在dataFrame里面to_list是有下划线的
#Alarm_list:[[],[],[]]
Alarm=[]
for i in Alarm_list:#或者Alarm = list(set([j for i in Alarm_list for j in i]))
Alarm.extend(i)
# print(len(Alarm))
# print(len(set(Alarm)))
Alarm = list(set(Alarm))
#-----------------构造为0的数组----------------
# zero_list = np.zeros(len(Alarm))
# zero_df =pd.DataFrame(np.zeros((df.shape[0],len(Alarm))), columns=Alarm)
zero_df = pd.DataFrame(np.zeros((10,len(Alarm))),columns=Alarm)
# print(zero_df)
#--------------给每个出现的标签赋值1--------------
# num = 0
# for j in Alarm_list:
# for i in j:
# if i in zero_df.columns:
# zero_df.loc[num,i]=1
# num +=1
# 或者
for i in range(len(zero_df)):
# zero_df.loc[0,['_r1wt','_r2wt','_r3wt']] = 1
zero_df.loc[i,Alarm_list[i]] = 1
# print(zero_df[zero_df>0])
print(zero_df)
#--------------统计每个分类的数量和----------------
Alarm_count = zero_df.sum(axis=0)
print('每个分类的数量和:',Alarm_count)
#--------------------排序------------------------
# 对数量和进行排序
Alarm_sum = Alarm_count.sort_values()
print(Alarm_sum)
#------------------画图-----------------------
from matplotlib import pyplot as plt
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
_x = Alarm_sum.index
y = Alarm_sum.values
plt.figure(figsize=(20,8),dpi=80)
plt.bar(range(len(_x)),y)
plt.xticks(range(len(_x)),_x,rotation=90)
plt.yticks(range(3))
#显示X,Y的标签
plt.xlabel("数量")
plt.ylabel("类别")
plt.show()

02数据合并
- join的使用----按行索引进行合并,以第一个字典为主


t1 = pd.DataFrame(np.zeros((2,3)),index=['A','B'],columns=list('xyz'))
print(t1)

t2 = pd.DataFrame(np.ones((3,3)))
print(t2)

print(t1.join(t2))

为什么会这样?—需要行索引相同才能正确拼接
所以将t2进行修改:
t2 = pd.DataFrame(np.ones((3,3)),index=['A','B','C'],columns=list('abc'))
print(t2)
print(t1.join(t2))
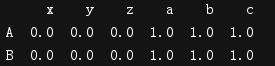
print(t2.join(t1))
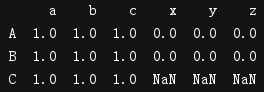
列合并:

t1 = pd.DataFrame(np.ones((2,4)),index=['A','B'],columns=list('abcd'))
print(t1)

t2 = pd.DataFrame(np.zeros((3,3)),index=['A','B','C'],columns=list('xyz'))
print(t2)
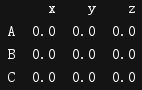
t3 = pd.DataFrame(np.zeros((3,3)),columns=list('fax'))
print(t3)
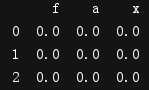
print(t1.merge(t3,on="a"))#按照a列,若t1 t3的a列有相同的数值,则取交集,没有则不合并
因为若t1 t3的a列没有相同的数值,所以不合并。

t3.loc[1,‘a’]=1
print(t3)

print(t1.merge(t3,on="a"))

因为t1中a列有两行都等于1,所以这两列与t3中的进行合并
t3 = pd.DataFrame(np.arange(9).reshape((3,3)),columns=list('fax'))
print(t3)
print(t1.merge(t3,on="a"))#按照a列,若t1 t3的a列有相同的数值,则合并,没有则不合并

t1.loc['A','a']=100
print(t1)
print(t1.merge(t3,on="a"))
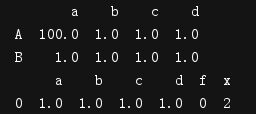
修改t1后,可以看到只合并了一行,因为a列中只有一个数(或者说一行)是相等的。
介绍:inner/outer方式
how=‘inner’—取交集
how=‘outer’—取并集
print(t1.merge(t3,on="a",how='inner'))#默认的是how='inner'---取交集
![]()
t1 = pd.DataFrame(np.ones((2,4)),index=['A','B'],columns=list('abcd'))
print(t1)
t3 = pd.DataFrame(np.arange(9).reshape((3,3)),columns=list('fax'))
print(t3)
t1.loc['A','a']=100
print(t1)
print(t1.merge(t3,on="a",how='outer'))#默认的是how='outer'---取并集

print(t1.merge(t3,on="a",how='left'))#以左边的t1为主

print(t1.merge(t3,on="a",how='right'))#以右边的t3为主

03数据分组聚合


无数据,自己造的数据:
import pandas as pd
import numpy as np
file_path = './trainData-V1.csv'
df = pd.read_csv(file_path)
df = df.dropna()
#print(df.info())
fault_title_group = df[:20].groupby(by='fault_title')#只选择20行进行操作----对df,通过fault_title列建立groupby,后面可以遍历,调用
print(fault_title_group)
for i ,j in fault_title_group:
print(i)
print("*"*100)
print(j)
print(type(j))
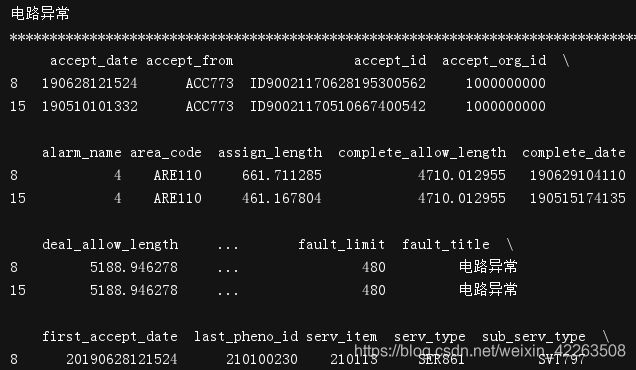
#调用聚合方法:统计该列下fault_title的类别和个数
#fault_title_group是'fault_title'组成的group,但他实际是一个DataFrame格式,所以fault_title_group['serv_type']可以获取DataFrame(fault_title_group)中的列,
print(fault_title_group['serv_type'].count())

fault_count = fault_title_group['serv_type'].count()
print(fault_count['设备发生故障'])#显示该列别('设备发生故障')的个数,fault_title_group是'fault_title'组成的group,但他实际是一个DataFrame格式,fault_title_group['serv_type'].count可以对其计数,但是还是一个DataFrame格式,fault_title_group['serv_type'].count()['设备发生故障']可以获取DataFrame(fault_title_group['serv_type'].count())中的列['设备发生故障']相关数据。
6
04数据分组聚合02
import pandas as pd
import numpy as np
file_path = './trainData-V1.csv'
df = pd.read_csv(file_path)
df = df.dropna()
#print(df.info())
fault_data = df[df['fault_title']=='设备发生故障'] #选定‘设备发生故障’的数据
# print(fault_data[:10])
grouped = fault_data[:10].groupby(by="CODE").count()#依据fault_data数据对'CODE'列进行计数
print(grouped)#对DataFrame计数还是一个DataFrame格式
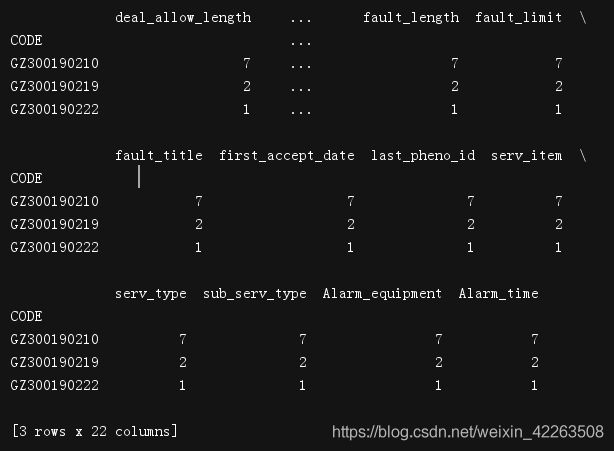
grouped = fault_data[:10].groupby(by="CODE").count()['Alarm_equipment']#对DataFrame提取['Alarm_equipment’]列的数据
print(grouped)

注意上图:CODE是group的依据项,Alarm_equipment是调用计算count后的DataFrame中的列项值


这里两个索引是叫复合索引,后面对复合索引进行举例。
import pandas as pd
file_path = './trainData-V1.csv'
df = pd.read_csv(file_path)
df = df.dropna()
print(df.info())
#数据按照多个条件进行分组
# grouped = df['fault_title'].groupby(by=['Alarm_equipment',"CODE"]).count() #---不可用,是因为df['fault_title']是series类型,里面根本没有'Alarm_equipment',"CODE"项
grouped = df['fault_title'].groupby(by=[df['Alarm_equipment'],df['CODE']]).count()
print(grouped)
print(type(grouped))#Series类型,主要是看df是使用的啥类型,这里使用的是df['fault_title'],就是Series类型

grouped = df.groupby(by=[df['Alarm_equipment'],df['CODE']]).count()
print(type(grouped))#DataFrame类型,主要是看df是使用的啥类型
注意:两者的区别,最后的类型依赖于所取的df是DataFrame还是Series(df[‘fault_title’])
如果对所取的是df[‘fault_title’]但是仍然需要返回时DataFrame类型,则需要进行如下修改:df[‘fault_title’]—》df[ [‘fault_title’] ]
#如何将返回的Series改为DataFrame类型
grouped1 = df[['fault_title']].groupby(by=[df['Alarm_equipment'],df['CODE']]).count()
grouped2 = df.groupby(by=[df['Alarm_equipment'],df['CODE']])[['fault_title']].count()
grouped3 = df.groupby(by=[df['Alarm_equipment'],df['CODE']]).count()[['fault_title']]
print(type(grouped1))
print(type(grouped2))
print(type(grouped3))
注意:1.注意他们之间的区别,以及series怎么变成DataFrame的
2.df.groupby(by=[df[‘Alarm_equipment’],df[‘CODE’]])[[‘fault_title’]].count()也可以写成:
df.groupby(by=[‘Alarm_equipment’,‘CODE’])[[‘fault_title’]].count()
3.以上三个表示的意思是,以[‘Alarm_equipment’],[‘CODE’]建立group,然后提取出建立group后的[‘fault_title’]列,并统计
4.对单个的df从series转成DataFrame也是一样操作


05数据的索引学习

grouped1 = df[['Alarm_equipment']].groupby(by=[df['fault_title'],df['CODE']]).count()
print(grouped1[:20].index)
print(grouped1[:20])
MultiIndex(levels=[[‘A级’, ‘BBU中断’, ‘BTS掉站’, ‘B级’, ‘C级’, ‘Down’, ‘D级’, ‘E1’, ‘FAULT’, ‘FDD’, ‘IP’, ‘LTE’, ‘Num’, ‘OBD’, ‘OLT’, ‘ONU’, ‘ONU离线(FTTB类)’, ‘PON’, ‘RRU’, ‘RTR’, ‘msgno’, ‘unknown’, ‘不可用’, ‘不可达’, ‘不合格’, ‘交流电异常’, ‘停电’, ‘失败’, ‘巡检异常’, ‘总电压’, ‘断站告警’, ‘本地网’, ‘温度告警’, ‘状态Down’, ‘状态异常’, ‘用户异常’, ‘电池告警’, ‘电路异常’, ‘直流电异常’, ‘网元告警’, ‘网元异常’, ‘设备发生故障’, ‘设备告警’, ‘设备掉电’, ‘设备无效’, ‘设备脱管’, ‘超低告警’, ‘过低告警’, ‘通信中断’, ‘通信链路中断’, ‘通讯异常’, ‘通讯状态’, ‘采集失败’], [‘GZ300190210’, ‘GZ300190211’, ‘GZ300190212’, ‘GZ300190213’, ‘GZ300190214’, ‘GZ300190215’, ‘GZ300190216’, ‘GZ300190217’, ‘GZ300190218’, ‘GZ300190219’, ‘GZ300190220’, ‘GZ300190221’, ‘GZ300190222’]],
labels=[[0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2], [0, 1, 5, 9, 11, 12, 0, 1, 2, 4, 5, 9, 10, 11, 12, 0, 1, 2, 4, 5]],
names=[‘fault_title’, ‘CODE’])

df1= pd.DataFrame(np.ones((2,4)),index=['A','B'],columns=list('abcd'))
print(df1)
print(df1.index)

df1.index=['a','b']
print(df1)
print(df1.index)

print(df1.reindex(['h','a']))#因为a索引存在,所以有值,h索引不存在,所以为Nan
print(df1) #df1没有变,上面只是提取了两行而已
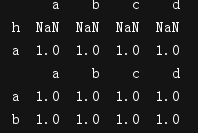
#将某一列作为索引
df1.loc['a','a'] =100
print(df1)
print(df1.set_index('a'))

print(df1.set_index('a',drop=False))#drop=False是指继续保存列

print(df1.set_index("b").index.unique())
print(list(df1.set_index("a").index))
[ 1.]
[100.0, 1.0]
print(df1.set_index(["a","b"]))
print(df1.set_index(["a","b"]).index)
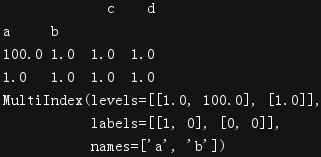
print(df1.set_index(["a","b","c"],drop=False))
print(df1.set_index(["a","b","c"],drop=False).index)

a = pd.DataFrame({'a':range(7),'b':range(7,0,-1),'c':['one','one','one','two','two','two','two'],'d':list('hjklmno')})
print(a)
print(a.set_index(['c','d']))

06数据分组聚合练习和总结
a = pd.DataFrame({'a':range(7),'b':range(7,0,-1),'c':['one','one','one','two','two','two','two'],'d':list('hjklmno')})
print(a)
b = a.set_index(['c','d'])
print(b)

c=b['a']
print(c)
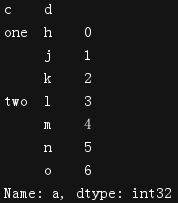
print(type(c))
print(c['one']['j'])
print('-'*100)
print(c['one'])

d = a.set_index(["d","c"])["a"]#这个和c是一样的,都是取a列,只是所使用的行c,d交换了位置
print(d)

print(d.index)
print(d.swaplevel())#交换levels,交换之后就是和前面的c一样啦

print(d.swaplevel()['one'])#与上面的c['one']相同

print(b)#这个type(b)是DataFrame
print("---------------------")
print(b['a']['one']['j'])#只能取到a列上的数
print('***********************')
print(b.loc['one'].loc['j'])#能取到a和b列上的数


print(b.swaplevel().loc[‘h’])


 动手实例1:—无数据,所以自己造了数据:
动手实例1:—无数据,所以自己造了数据:
df = pd.DataFrame({'a':range(7),'Brand':range(7,0,-1),'Country':['one','one','one','two','two','two','two'],'d':list('hjklmno')})
df =df.set_index(['a'])
print(df)
grouped = df.groupby(by=['Country']).count()['Brand'].sort_values(ascending=False)
print(grouped)
print(type(grouped))

注意:grouped类型是series
#取索引和values
_x = grouped.index
_y = grouped.values
#画图
from matplotlib import pyplot as plt
plt.figure(figsize=(20,8),dpi=80)
plt.bar(range(len(_x)),_y)
plt.xticks(range(len(_x)),_x)
plt.show()

动手实例2:
生成数据:
df = pd.DataFrame({'a':range(7),'Brand':range(7,0,-1),'Country':['one','one','one','two','two','two','two'],'City':list('hjkllno')})
df =df.set_index(['a'])
print(df)

df = df[df['Country']=='two']
print(df)
grouped = df.groupby(by=['City']).count()['Brand'].sort_values(ascending=True)
print(grouped)
print(type(grouped))

#获取数据
_x = grouped.index
_y = grouped.values
#画图
from matplotlib import pyplot as plt
plt.figure(figsize=(20,8),dpi=80)
plt.barh(range(len(_x)),_y)
# plt.bar(range(len(_x)),_y)
plt.yticks(range(len(_x)),_x)
plt.show()
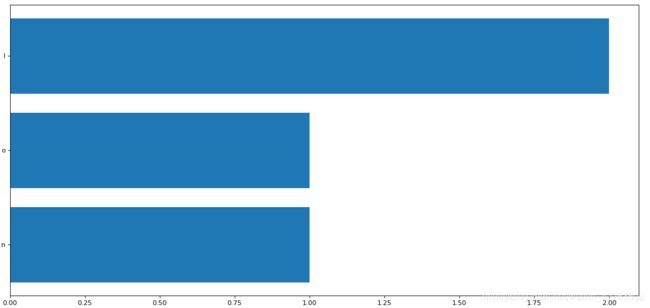
完整程序:
df = pd.DataFrame({'a':range(7),'Brand':range(7,0,-1),'Country':['one','one','one','two','two','two','two'],'City':list('hjkllno')})
df =df.set_index(['a'])
print(df)
df = df[df['Country']=='two']
print(df)
grouped = df.groupby(by=['City']).count()['Brand'].sort_values(ascending=True)
print(grouped)
print(type(grouped))
_x = grouped.index
_y = grouped.values
from matplotlib import pyplot as plt
plt.figure(figsize=(20,8),dpi=80)
plt.barh(range(len(_x)),_y)
# plt.bar(range(len(_x)),_y)
plt.yticks(range(len(_x)),_x)
plt.show()

动手实例3:不同年份书的数量
没有数据,首先构造数据:
df = pd.DataFrame({'a':range(10),'original_publication_year':range(1956,1966),'average_rating':[5.6,6.0,7.8,8.9,9.0,4.5,5.5,4.6,9.0,5.6],'title':list('abcdefghij')})
df =df.set_index(['a'])
df.loc[3,'original_publication_year'] = None
df.loc[4:6,'original_publication_year'] = 1956
df.loc[8,'original_publication_year'] = 1965
print(df)

去除nan项:
data1 = df[pd.notnull(df['original_publication_year'])]
print(data1)

建立以的groupe,并计算count,然后显示(DataFrame类型)title项
grouped = data1.groupby(by=['original_publication_year']).count()['title'].sort_values()
print(grouped)

画图:
_x = grouped.index
_y = grouped.values
from matplotlib import pyplot as plt
plt.figure(figsize=(20,8),dpi=80)
plt.barh(range(len(_x)),_y)
# plt.bar(range(len(_x)),_y)
plt.yticks(range(len(_x)),_x)
plt.show()

完整代码:
df = pd.DataFrame({'a':range(10),'original_publication_year':range(1956,1966),'average_rating':[5.6,6.0,7.8,8.9,9.0,4.5,5.5,4.6,9.0,5.6],'title':list('abcdefghij')})
df =df.set_index(['a'])
df.loc[3,'original_publication_year'] = None
df.loc[4:6,'original_publication_year'] = 1956
df.loc[8,'original_publication_year'] = 1965
print(df)
data1 = df[pd.notnull(df['original_publication_year'])]
print(data1)
grouped = data1.groupby(by=['original_publication_year']).count()['title'].sort_values()
print(grouped)
_x = grouped.index
_y = grouped.values
from matplotlib import pyplot as plt
plt.figure(figsize=(20,8),dpi=80)
plt.barh(range(len(_x)),_y)
# plt.bar(range(len(_x)),_y)
plt.yticks(range(len(_x)),_x)
plt.show()
动手实例3:不同年份书的平均评分
#构建数据
df = pd.DataFrame({'a':range(10),'original_publication_year':range(1956,1966),'average_rating':[5.6,6.0,7.8,8.9,9.0,4.5,5.5,4.6,9.0,5.6],'title':list('abcdefghij')})
df =df.set_index(['a'])
df.loc[3,'original_publication_year'] = None
df.loc[4:6,'original_publication_year'] = 1956
df.loc[8,'original_publication_year'] = 1965
# print(df)
#去除NAN项
data1 = df[pd.notnull(df['original_publication_year'])]
print(data1)
#计算不同年份书的平均评分
grouped = data1['average_rating'].groupby(by=data1['original_publication_year']).mean().sort_values()
# grouped = data1.groupby(by=['original_publication_year']).mean()['average_rating'].sort_values()#余上面效果一样
print(grouped)
#画图
_x = grouped.index
_y = grouped.values
from matplotlib import pyplot as plt
plt.figure(figsize=(20,8),dpi=80)
plt.barh(range(len(_x)),_y)
# plt.bar(range(len(_x)),_y)
plt.yticks(range(len(_x)),_x)
plt.show()


总结: