Pytorch+Python实现人体关键点检测
用Python+Pytorch工程代码对人体进行关键点检测和骨架提取,并实现可视化。
使用背景:
物体检测为许多视觉任务提供动力,如实例分割、姿态估计、跟踪和动作识别。它在监控、自动驾驶和视觉答疑中有下游应用。当前的对象检测器通过紧密包围对象的轴向包围框来表示每个对象。然后,他们将目标检测减少到大量潜在目标边界框的图像分类。对于每个边界框,分类器确定图像内容是特定的对象还是背景。
人体关键点检测属于目标检测的一个小分支,在很多虚拟应用场景中需要使用,比如说姿态识别、虚拟穿衣等应用领域。今天给大家推荐一个好用的人体关键点检测项目代码,并基于该代码进行一定的升级,使得提取的人体关键点可以独立显示在可视化界面当中。
使用环境:
本项目通过Python实现,运行环境为:
Python 3.7
Pytorch 1.8.1
Opencv 4.5.4.60
使用代码:
本项目实现基于rwightman的代码进行改进实现,
参考代码地址:https://github.com/rwightman/posenet-python
源代码效果(左图为原图,右图为检测结果图):
修改后的效果:
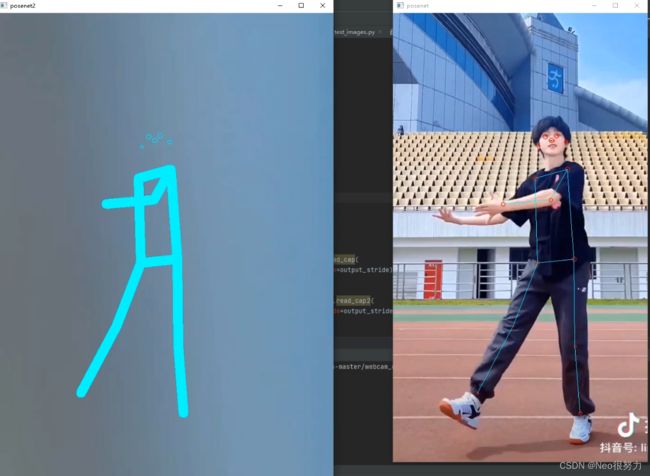
代码使用步骤:
如下的代码都基于参考github链接源码进行直接修改,找到上下行代码参考修改的具体位置。
本代码以源代码视频应用文件举例(webcam_demo.py)
第一步:
在原项目工程代码中找到webcam_demo.py
修改视频获取路径(基于源代码修改):
def main():
model = posenet.load_model(args.model)
model = model.cuda()
output_stride = model.output_stride
# cap = cv2.VideoCapture(args.cam_id)
cap = cv2.VideoCapture('3.mp4')
cap.set(3, args.cam_width)
cap.set(4, args.cam_height)
#背景视频读取
cap2 = cv2.VideoCapture('2.mp4')
cap2.set(3, args.cam_width)
cap2.set(4, args.cam_height)
然后在视频显示代码部分添加提取关键点显示界面:
min_pose_score=0.15, min_part_score=0.1)
cv2.imshow('posenet', overlay_image)
# cv2.imshow('net', overlay_image)
# cv2.resizeWindow('posenet', 500, 900)
overlay_image2 = posenet.draw_skel_and_kp2(
display_image2,display_image2, pose_scores, keypoint_scores, keypoint_coords,
min_pose_score=0.15, min_part_score=0.1)
cv2.imshow('posenet2', overlay_image2)
#提取skeleton
# cv2.namedWindow("dance", 0)
# cv2.resizeWindow("dance", 600, 900) # 设置窗口大小
#
# cv2.imshow("dance", img)
frame_count += 1
if cv2.waitKey(1) & 0xFF == ord('q'):
break
print('Average FPS: ', frame_count / (time.time() - start))
第二步:
修改posenet/utils.py代码部分:
添加提取的骨架的视频背景函数:
#背景视频
def read_cap2(cap, scale_factor=1.0, output_stride=16):
res2, img2 = cap.read()
if not res2:
raise IOError("webcam failure")
return _process_input2(img2, scale_factor, output_stride)
添加定义骨架关键点绘制函数:
def draw_skel_and_kp2(
img, img2, instance_scores, keypoint_scores, keypoint_coords,
min_pose_score=0.1, min_part_score=0.1): #将置信度由0.5改为0.3
bk=img2
out_img = img
adjacent_keypoints = []
cv_keypoints = []
for ii, score in enumerate(instance_scores):
if score < min_pose_score:
continue
new_keypoints = get_adjacent_keypoints(
keypoint_scores[ii, :], keypoint_coords[ii, :, :], min_part_score)
adjacent_keypoints.extend(new_keypoints)
for ks, kc in zip(keypoint_scores[ii, :], keypoint_coords[ii, :, :]):
if ks < min_part_score:
continue
cv_keypoints.append(cv2.KeyPoint(kc[1], kc[0], 10. * ks))
if cv_keypoints:
bk = cv2.drawKeypoints(
bk, cv_keypoints, outImage=np.array([]), color=(255, 255, 0),
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
out_img = cv2.polylines(bk, adjacent_keypoints, isClosed=False, color=(255, 255, 0),thickness=20)
return out_img
然后就能以一个纯粹的骨架关键点样式显示在另一个UI界面啦:
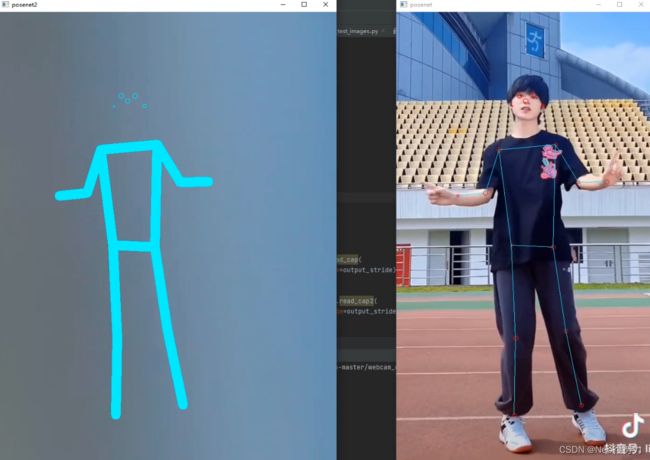
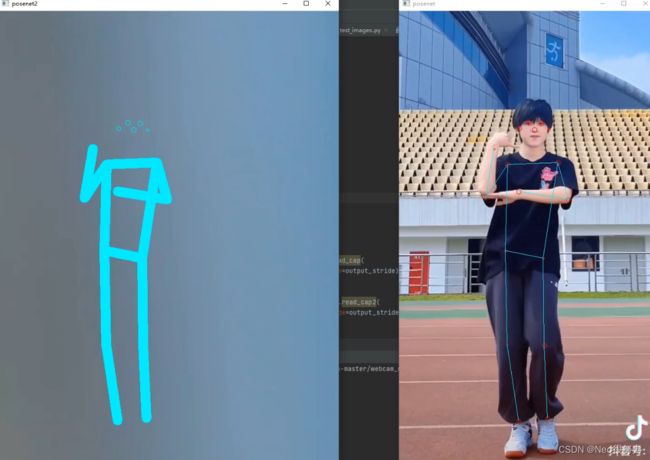

上面用的是段dy的舞蹈视频做demo~
Reference:
1、https://github.com/rwightman/posenet-python
2、Zhou, Xingyi, Dequan Wang, and Philipp Krähenbühl. “Objects as points.” arXiv preprint arXiv:1904.07850 (2019).