MobileNet V1&V2 学习笔记
MobileNet V1&V2
引言
随着深度学习的发展,卷积神经网络变得越来越普遍。当前发展的总体趋势是,通过更深和更复杂的网络来得到更高的精度,但是这种网络往往在模型大小和运行速度上没多大优势。一些嵌入式平台上的应用比如机器人和自动驾驶,它们的硬件资源有限,就十分需要一种轻量级、低延迟(同时精度尚可接受)的网络模型,这就是本文的主要工作。
毕竟消费类产品很多是嵌入式的终端产品,而且嵌入式芯片的计算性能并不很强。即使我们考虑云计算,也需要消耗大量的带宽资源和计算资源。因此,CNN的优化已成为深度学习产品能否在消费市场落脚生根的一个重要课题之一。所以,有不少学者着手研究CNN的网络优化,如韩松的SqueezeNet,Deep Compression,LeCun的SVD,Google的MobileNet以及孙剑的ShuffleNet等。
网络压缩优化的方法有两个发展方向,一个是迁移学习,另一个是网络稀疏。迁移学习是指一种学习对另一种学习的影响,好比我们常说的举一反三行为,以减少模型对数据量的依赖。不过,它也可以通过knowledge distillation(知识蒸馏)实现大模型到小模型的迁移,这方面的工作有港中文汤晓鸥组的MobileID。他们运用模型压缩技术和domain knowledge,用小的网络去拟合大量的数据,并以大型teacher network的知识作为监督,训练了一个小而紧凑的student network打算将DeepID迁移到移动终端与嵌入式设备中。而另一方面,网络稀疏是现在比较主流的压缩优化方向,这方面的工作主要是以网络结构的剪枝和调整卷积方式为主。比如深度压缩,它先通过dropout,L1/L2-regularization等能产生权重稀疏性的方法训练体积和密度都很大的网络,然后把网络中贡献小(也就是被稀疏过的)的权重裁剪掉,相当于去除了一些冗余连接,最后对模型做一下fine-tune就得到他所说的30%压缩率的效果。但它在效率上的提高并不适合大多数的通用CPU,因为它的存储不连续,索引权重时容易发生Cache Miss,反而得不偿失。下面介绍的MobileNet在这方面更有优势,MobileNets主要关注优化延迟,同时兼顾模型大小,不像有些模型虽然参数少。
MobileNetV1
1. 摘要
深度卷积神经网络将多个计算机视觉任务性能提升到了一个新高度,总体的趋势是为了达到更高的准确性构建了更深更复杂的网络,但是这些网络在尺度和速度上不一定满足移动设备要求。MobileNetV1描述了一个高效的网络架构,允许通过两个超参数直接构建非常小、低延迟、易满足嵌入式设备要求的模型。
我们提供一类称为MobileNets的高效模型,用于移动和嵌入式视觉应用。 MobileNets是基于一个流线型的架构,它使用深度可分离的卷积来构建轻量级的深层神经网络。我们引入两个简单的全局超参数,在延迟度和准确度之间有效地进行平衡。这两个超参数允许模型构建者根据问题的约束条件,为其应用选择合适大小的模型。我们进行了资源和精度权衡的广泛实验,与ImageNet分类上的其他流行的网络模型相比,MobileNets表现出很强的性能。最后,我们展示了MobileNets在广泛的应用场景中的有效性,包括物体检测,细粒度分类,人脸属性和大规模地理定位。
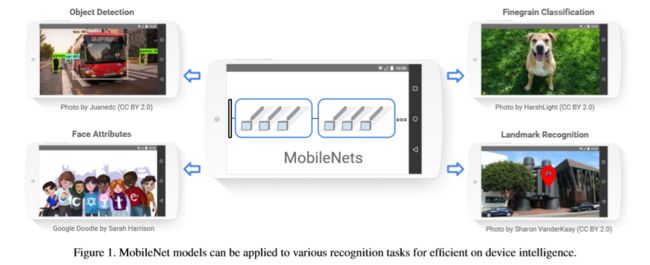
2. 创新点
1)深度可分离卷积

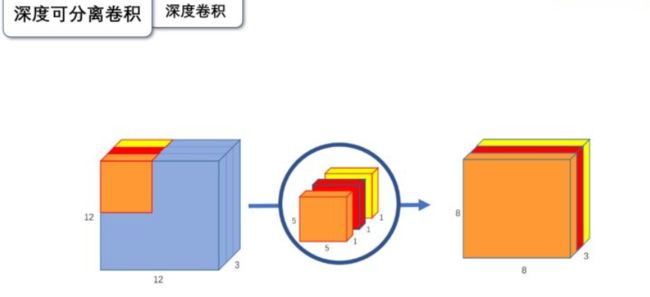
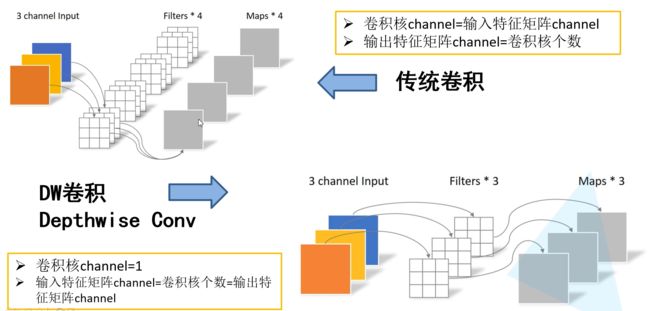
深度卷积(DW)
与标准卷积网络不一样的是,我们将卷积核拆分成为单通道形式,在不改变输入特征图像的深度的情况下,对每一通道进行卷积操作,这样就得到了和输入特征图通道数一致的输出特征图。如上图:输入12×12×3的特征图,经过5×5×1×3的深度卷积之后,得到了8×8×3的输出特征图。输入个输出的维度是不变的3。这样就会有一个问题,通道数太少,特征图的维度太少,或许不能获取到足够的有效信息。
逐点卷积(PW)
逐点卷积就是1×1卷积。主要作用就是对特征图进行升维和降维,如下图:

深度卷积将每个卷积核应用到每一个通道,而1 × 1卷积用来组合通道卷积的输出。
一图以蔽之:
计算量对比
标准卷积
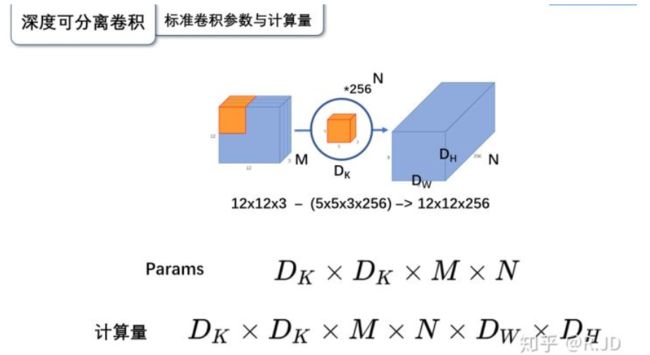
深度可分离卷积

参数量对比
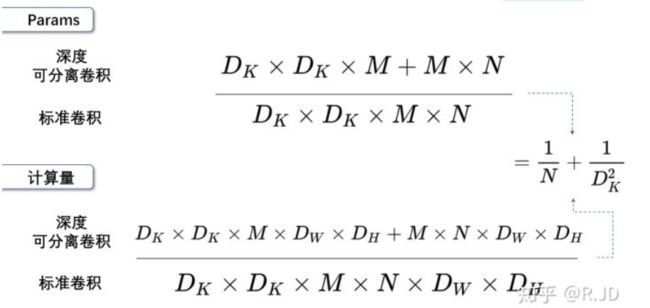
一般情况下,如果采用3x3卷积核的话,depthwise separable convolution相较标准卷积可以降低大约9倍的计算量。
2)引入两个超参数α、ρ
前面说的MobileNet的基准模型,但是有时候你需要更小的模型,那么就要对MobileNet瘦身了。这里引入了两个超参数:width multiplier和resolution multiplier。第一个参数width multiplier主要是 按比例减少通道数 ,该参数记为α,其取值范围为(0,1],对于depthwise separable convolution,其计算量变为:

因为主要计算量在后一项,所以width multiplier可以按照比例降低计算量,其是参数量也会下降。第二个参数resolution multiplier主要是按比例降低特征图的大小,记为 ρ ,比如原来输入特征图是224x224,可以减少为192x192。在width multiplier的基础上加上resolution multiplier,depthwise separable convolution的计算量为:
要说明的是,resolution multiplier仅仅影响计算量,但是不改变参数量。引入两个参数会给肯定会降低MobileNet的性能,具体实验分析可以见paper,总结来看是在accuracy和computation,以及accuracy和model size之间做折中。
3. 网络结构
基本结构(块)
前面讲述了depthwise separable convolution,这是MobileNet的基本组件,但是在真正应用中会加入batchnorm,并使用ReLU激活函数,所以depthwise separable convolution的基本结构如下图所示:

Tips:BN(Batch Normalization )层 ——数据标准化(归一化)处理
大致有以下优点:
• 可以使学习快速进行(可以增大学习率)
• 不那么依赖初始值(对于初始值不用那么神经质)
• 抑制过拟合(降低Dropout等的必要性)
具体结构

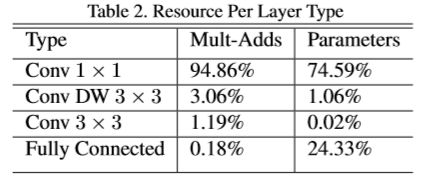
计算量与参数分布
4. 模型表现

5. 小结
-
采用深度可分离卷积操作,较标准卷积操作在小幅降低准确率的同时大幅减少计算量
-
引入两个简单的全局超参数,在延迟度和准确度之间有效地进行平衡。这两个超参数允许模型构建者根据问题的约束条件,为其应用选择合适大小的模型。
MobileNetV2
1. 引言
V1核心思想是采用 深度可分离卷积 操作。在相同的权值参数数量的情况下,相较标准卷积操作,可以减少数倍的计算量,从而达到提升网络运算速度的目的。
首先利用3×3的深度可分离卷积提取特征,然后利用1×1的卷积来扩张通道。用这样的block堆叠起来的MobileNetV1既能较少不小的参数量、计算量,提高网络运算速度,又能的得到一个接近于标准卷积的还不错的结果,看起来是很美好的(但是)。
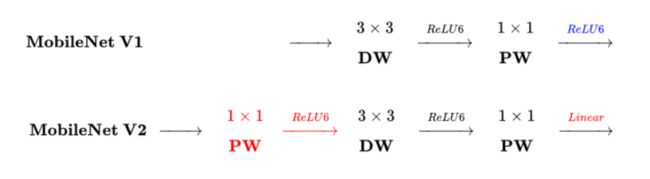
在MobileNet v1的网络结构表中能够发现,网络的结构就像VGG一样是个直筒型的,不像ResNet网络有shorcut之类的连接方式。而且有人反映说MobileNet v1网络中的DW卷积核很容易训练废掉:训完之后发现深度卷积训出来的卷积核参数大部分为0(可能是由于ReLU函数导致的),效果并没有那么理想。
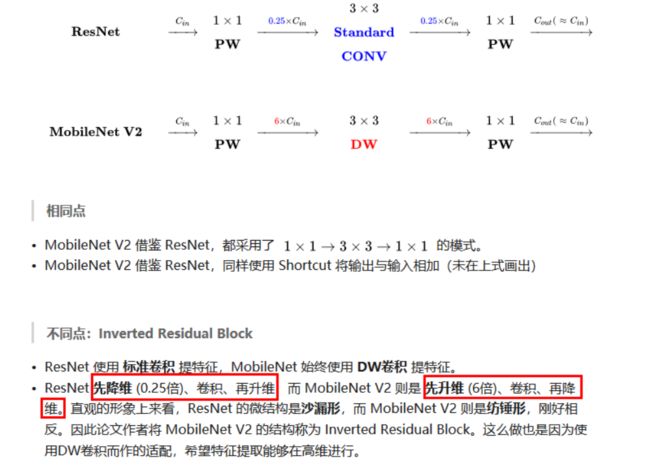
MobileNet v2网络是由google团队在2018年提出的,相比MobileNet V1网络,准确率更高,模型更小。刚刚说了MobileNet v1网络中的亮点是DW卷积,那么在MobileNet v2中的亮点就是Inverted residual block(倒残差结构),如下图所示,左侧是ResNet网络中的残差结构,右侧就是MobileNet v2中的倒残差结构。在残差结构中是1x1卷积降维->3x3卷积->1x1卷积升维,在倒残差结构中正好相反,是1x1卷积升维->3x3DW卷积->1x1卷积降维。为什么要这样做,原文的解释是高维信息通过ReLU激活函数后丢失的信息更少(注意倒残差结构中基本使用的都是ReLU6激活函数,但是最后一个1x1的卷积层使用的是线性激活函数)。
2. 创新点
1)倒残差结构(Inverted residuals)
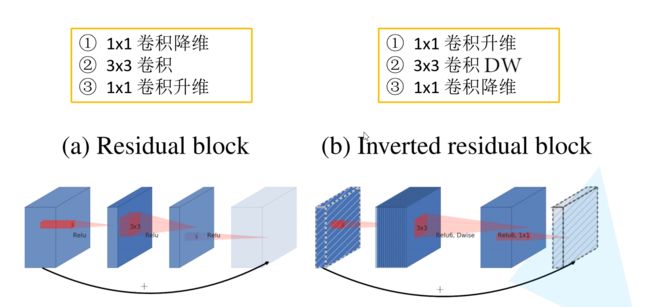
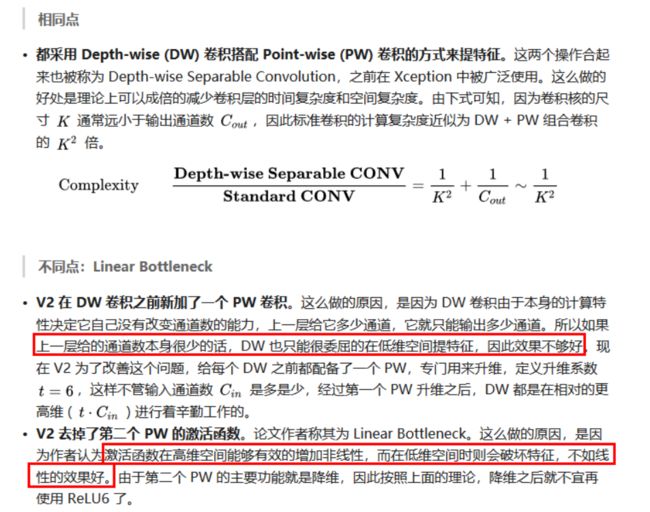
深度卷积本身没有改变通道的能力,来的是多少通道输出就是多少通道。如果来的通道很少的话,DW深度卷积只能在低维度上工作,这样效果并不会很好,所以我们要“扩张”通道。既然我们已经知道PW逐点卷积也就是1×1卷积可以用来升维和降维,那就可以在DW深度卷积之前使用PW卷积进行升维(论文建议升维倍数为t,t=6),再在一个更高维的空间中进行卷积操作来提取更多的特征信息。
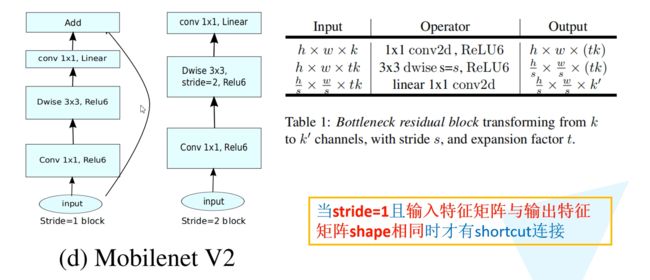
注意:在使用倒残差结构时,并不是所有的倒残差结构都有shortcut连接,只有当stride=1且输入特征矩阵与输出特征矩阵shape相同时才有shortcut连接(只有当shape相同时,两个矩阵才能做加法运算,当stride=1时并不能保证输入特征矩阵的channel与输出特征矩阵的channel相同)。
2)将ReLU替换成线性激活函数(ReLU -> Linear)

换句话说,就是对一个n维空间中的一个“东西”做ReLU运算,然后(利用T的逆矩阵T-1恢复)对比ReLU之后的结果与Input的结果相差有多大。
当n = 2,3时,与Input相比有很大一部分的信息已经丢失了。而当n = 15到30,还是有相当多的地方被保留了下来。
也就是说,对低维度做ReLU运算,很容易造成信息的丢失。而在高维度进行ReLU运算的话,信息的丢失则会很少。
这就解释了为什么深度卷积的卷积核有不少是空。发现了问题,我们就能更好地解决问题。针对这个问题,可以这样解决:既然是ReLU导致的信息损耗,将ReLU替换成线性激活函数。
注意: 仅去掉 Narrow layer(low dimension or depth) 后的 ReLU,保留特征多样性
Tips:ReLU6

3. 网络结构
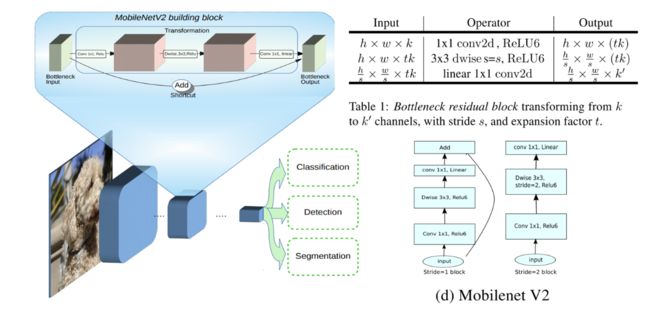
Bottleneck Residual Block

具体结构

4. 和一些相关网络的对比
MobileNetV1
ResNet
5. 模型表现

Tips:Top1与mAP
mAP,其中代表P(Precision)精确率,AP(Average precision)单类标签平均(各个召回率中最大精确率的平均数)的精确率,mAP(Mean Average Precision)所有类标签的平均精确率。
Top-1 Accuracy是指排名第一的类别与实际结果相符的准确率
6. 小结
- 引入残差结构,先升维再降维,增强梯度的传播,显著减少推理期间所需的内存占用(Inverted Residuals)
- 去掉 Narrow layer(low dimension or depth) 后的 ReLU,保留特征多样性,增强网络的表达能力(Linear Bottlenecks)
- 网络为全卷积的,使得模型可以适应不同尺寸的图像;使用 ==RELU6(最高输出为 6)==激活函数,使得模型在低精度计算下具有更强的鲁棒性
V1 VS V2

可以看到,虽然V2的层数比V1的要多很多,但是FLOPs,参数以及CPU耗时都是比V1要好的。
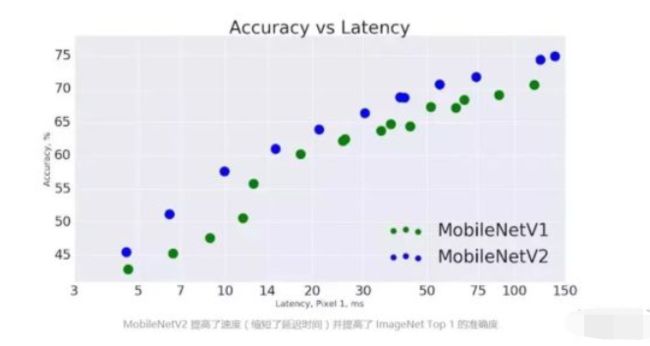
V1V2在google Pixel 1手机上在Image Classification任务的对比:MobileNetV2 模型在整体速度范围内可以更快实现相同的准确性。
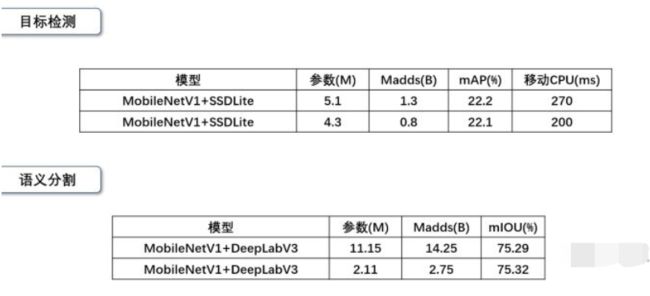
目标检测和语义分割的比较结果
综上,MobileNetV2 提供了一个非常高效的面向移动设备的模型,可以用作许多视觉识别任务的基础。
参考链接
Batch Normalization 学习笔记
轻量级神经网络——MobileNet
MobileNets网络详解
MobileNetV1 & MobileNetV2 简介
视频链接