通用链表的设计与实现
前言
- 本文用到一个很重要的思想--泛型编程思想;不熟悉泛型的话,请自行搜索相关资料学习(void *,如memcpy,memmove,qsort,memset等库函数均使用到了泛型思想) 。
- 本文最后会提供一个demo程序附件,该demo程序以c99标准进行编写的,在Linux-gcc下调试通过,vc6下可能会有错误。
- 本文图示中,红色实线表示要添加的地方,黑色虚线表示要断开的地方,黑色实线保持原样。
- 本文链表设计为最简单的非循环单链表。
数组与链表比较
|
数组
|
链表
|
|
|
优点
|
存取速度快
操作方便
|
不限制大小
插入删除易于实现
空间无需连续
|
|
缺点
|
插入删除等操作不易实现
需要连续空间存储
数组元素需要类型相同
|
存取速度慢
操作复杂
|
通过比较可以发现,数组的优点正好就是链表的缺点,而链表的缺点正好是数组的优点。
链表的分类
单链表
每个节点有1个指针域,指向后继(next)
双链表
每个节点都有2个指针域,一个指向前驱(previous),一个指向后继(next)
循环链表
首尾相接,tail->next = head; 能通过任意一个节点找到其他所有的节点
非循环链表
首尾不相接,tail->next = NULL;通过head可以找到所有节点。
链表数据结构
typedef struct node{ //节点结构
void *data;
struct node *next;
} node;
typedef struct { //链表结构
struct node *head;
struct node *tail;
long len;
} List;
void *data;
struct node *next;
} node;
typedef struct { //链表结构
struct node *head;
struct node *tail;
long len;
} List;
常见链表算法
初始化
void list_init(List *list);
销毁
void list_destroy(List *list, void (*destroy)(void *));
插入
void list_insert(List *list, void *data);
头插法 void list_insert_at_head(List *list, void *data);
随插法 void list_insert_at_index(List *list, void *data);
尾插法 void list_insert_at_tail(List *list, void *data, long idx);
删除
void *list_delete(List *list, void *key, int (*compare)(const void *, const void *));
搜索
void *list_search(List *list, void *key, int (*compare)(const void *, const void *));
排序
void *list_sort(List *list, void *key, int (*compare)(const void *, const void *));
遍历
void list_traverse(List *list, void (*handle)(void *));
逆序 void list_reverse(List *list);
求长度
long get_lenth(List *list);
获取链表节点
void *list_get_element(List *list, long index);
判断空链表
bool is_empty(List *list);
各算法的详解与实现
已知链表结构如下所示
typedef
struct{
//链表结构
struct node *head;
struct node *tail;
long len;
} List;
struct node *head;
struct node *tail;
long len;
} List;
该链表有具有3个属性,头指针head,尾指针tail以及链表长度len;
首先,定义一个链表,
List list;
此时链表结构如下所示:

链表的初始化
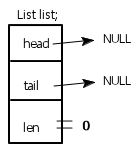
链表刚建立的时候,是不含任何有效数据的,也就是说不含有效节点。因此头指针head和尾指针tail无指向,即指向NULL,此时链表长度为0。
即此时链表结构如下所示
程序实现
void list_init(List *list)
{
list->head = NULL;
list->tail = NULL;
list->len = 0;
}
{
list->head = NULL;
list->tail = NULL;
list->len = 0;
}
刚初始化完的链表是一个空链表,空链表的头指针必定为NULL,该特征可以作为判定空链表的依据,由此实现
判断空链表的程序
#include <stdbool.h>
bool is_empty(List *list)
{
return (list->head == NULL);
}
bool is_empty(List *list)
{
return (list->head == NULL);
}
链表节点的插入
链表初始化完成之后,就可以进行各种操作(如插入删除节点,求长度,销毁链表等)了,下面来解释一下链表插入的操作方法;
插入节点需要分2种情况讨论:
-
链表为空时,插入的第一个节点(首节点);
-
在非空链表上插入一个节点。
1、第一种情况
该种情况可用下图表示
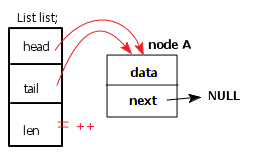
此时,只有一个节点A,此时节点A既是首节点(因此head指向节点A),又是尾节点(因此tail也指向节点A,并且A->next = NULL);同时,链表长度要相应的+1(插入程序中,len始终呈++的状态,下文不再赘述)。
程序实现(假设n为待插入的节点)
struct node *new;
list->head = new;
list->tail = new;
new->next = NULL;
list->len++;
list->head = new;
list->tail = new;
new->next = NULL;
list->len++;
2、第二种情况
第二种情况又分为3种情况,根据新节点的插入位置,分为
1.在头部插,头插法:list_insert_at_head(...);
2.在尾部插,尾插法:list_insert_at_tail(...);
3.在第index个节点处插,随插法:list_insert_at_index(...)。
2.1、头插法
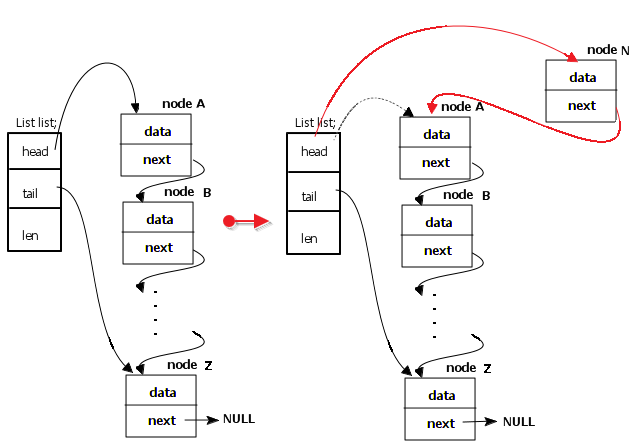
分析图例可知,已有链表(左侧),list->head = A;现在要在head处插入一个节点N,需要断开head与A的连接,使N->next = A;然后list->head = N(这两步不可调换顺序,可以想想为什么?)。
程序实现如下:
struct node *new;
new->next = list->head->next;
list->head = new;
list->len++;
new->next = list->head->next;
list->head = new;
list->len++;
2.2、尾插法
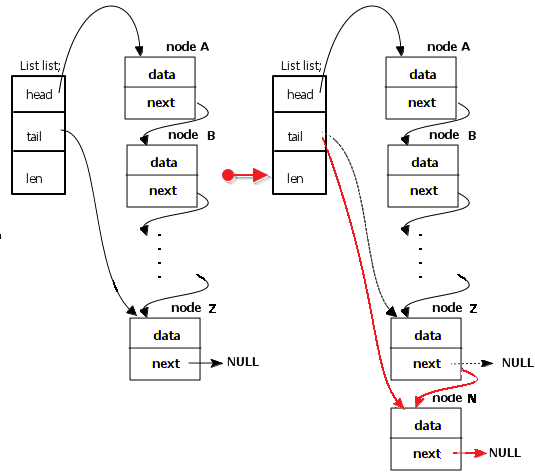
分析图例可知,已有链表(左侧),list->tail = Z;现在要在tail处插入一个节点N,需要断开tail与Z的连接,使Z->next = N;(即list->tail->next = N;)然后list->tail = N(这两步可以调换顺序吗?想想为什么?),然后再使N->next = NULL。
程序实现如下:
struct node *new;
list->tail->next = new;
list->tail = new;
new->next = NULL;
list->len++;
list->tail->next = new;
list->tail = new;
new->next = NULL;
list->len++;
2.3、随插法
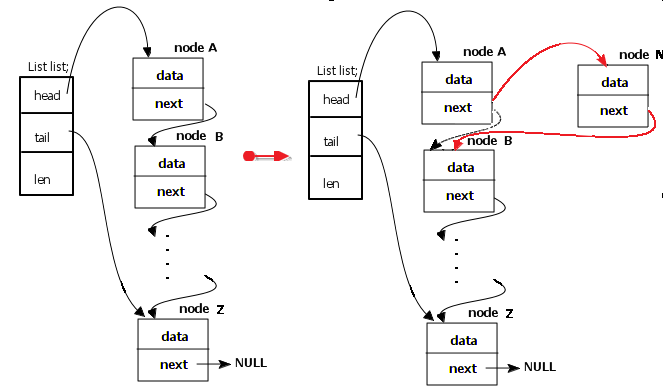
分析图例可知,已有链表(左侧),A->next= B;现在要在A处插入一个节点N,需要断开A与B的连接,使N->next = B;(即N->next = A->next;)然后使A->next = N(这两步可以调换顺序吗?想想为什么?)。
随插法由于插入位置不确定,所以不一定在图中的A节点处插入,有可能是B、C、D甚至Z。所以此处需要通过用户给定的index值配合list->head来找到插入位置。
代码实现如下:
static struct node *make_node(void *data) //把用户传递过来的数据打包为一个链表节点
{
struct node *n;
n = malloc(sizeof(struct node));
assert(n != NULL);
n->next = NULL;
n->data = data;
return n;
}
void list_insert_at_head(List *list, void *data) //头插法
{
struct node *n;
n = make_node(data);
if(list->head == NULL){ //如果是空链表
list->head = n;
list->tail = n;
}
else{ //如果不是非空链表
n->next = list->head;
list->head = n;
}
list->len++;
}
void list_insert_at_tail(List *list, void *data) //尾插法
{
struct node *n;
n = make_node(data);
if(list->head == NULL){ //如果是空链表
list->head = n;
list->tail = n;
n->next = NULL;
}
else{ //如果不是非空链表
list->tail->next = n;
list->tail = n;
n->next = NULL;
}
list->len++;
}
void list_insert_at_index(List *list, void *data, long index)
{
long i = 1; //从1开始算
struct node *p, *n;
p = list->head;
while(p && i < index){
p = p->next;
i++;
}
if(p){ //如果链表遍历完了,计数i还没到index,说明第index个节点不存在。
n = make_node(data);
n->next = p->next;
p->next = n;
list->len++;
}
}
void list_insert(List *list, void *data) //默认采用尾插法
{
list_insert_at_tail(list, data);
}
{
struct node *n;
n = malloc(sizeof(struct node));
assert(n != NULL);
n->next = NULL;
n->data = data;
return n;
}
void list_insert_at_head(List *list, void *data) //头插法
{
struct node *n;
n = make_node(data);
if(list->head == NULL){ //如果是空链表
list->head = n;
list->tail = n;
}
else{ //如果不是非空链表
n->next = list->head;
list->head = n;
}
list->len++;
}
void list_insert_at_tail(List *list, void *data) //尾插法
{
struct node *n;
n = make_node(data);
if(list->head == NULL){ //如果是空链表
list->head = n;
list->tail = n;
n->next = NULL;
}
else{ //如果不是非空链表
list->tail->next = n;
list->tail = n;
n->next = NULL;
}
list->len++;
}
void list_insert_at_index(List *list, void *data, long index)
{
long i = 1; //从1开始算
struct node *p, *n;
p = list->head;
while(p && i < index){
p = p->next;
i++;
}
if(p){ //如果链表遍历完了,计数i还没到index,说明第index个节点不存在。
n = make_node(data);
n->next = p->next;
p->next = n;
list->len++;
}
}
void list_insert(List *list, void *data) //默认采用尾插法
{
list_insert_at_tail(list, data);
}
链表节点的删除
删除链表中的一个已有节点,如下图所示:
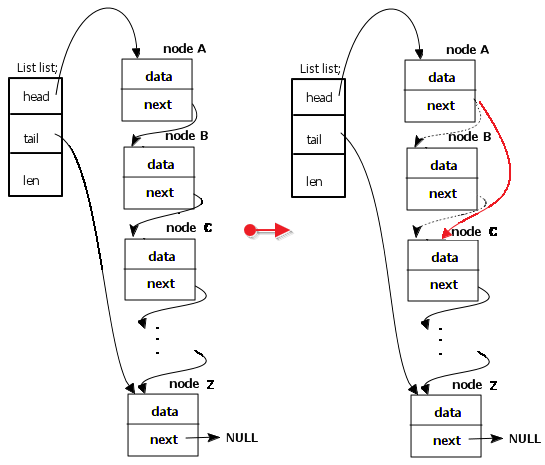
分析图例可知,已有链表(左侧),A->next= B;B->next = C;现在要删除节点B,那么需要断开节点AB和BC之间的关系,然后把AC连接起来。即A->next = A->next->next;然后根据需要f释放节点B即可。
程序实现:
void * list_delete(List *list, void *key,
int (*compare)(const void *, const void *)) //以key为删除关键词,compare为节点数据比较机制,由用户自己编写
{
void *data;
struct node *n, *t;
n = list->head;
if(!compare(n->data, key)){ //如果要删除的节点为首节点
printf("list_delete\n");
t = n;
data = n->data;
list->head = n->next;
free(t);
list->len--;
return data;
}
while(n->next != NULL){ //遍历查找符合条件的节点,删除之
if(compare(n->next->data, key) == 0){ //只删除第一个符合条件的节点。
t = n->next;
if(n->next == list->tail){
list->tail = n;
}
n->next = n->next->next;
data = t->data;
free(t);
list->len--;
return data; //把删除的数据返回给用户,供用户后续的处理使用。
}
n = n->next;
}
return NULL; //没找到匹配的节点,返回NULL
}
int (*compare)(const void *, const void *)) //以key为删除关键词,compare为节点数据比较机制,由用户自己编写
{
void *data;
struct node *n, *t;
n = list->head;
if(!compare(n->data, key)){ //如果要删除的节点为首节点
printf("list_delete\n");
t = n;
data = n->data;
list->head = n->next;
free(t);
list->len--;
return data;
}
while(n->next != NULL){ //遍历查找符合条件的节点,删除之
if(compare(n->next->data, key) == 0){ //只删除第一个符合条件的节点。
t = n->next;
if(n->next == list->tail){
list->tail = n;
}
n->next = n->next->next;
data = t->data;
free(t);
list->len--;
return data; //把删除的数据返回给用户,供用户后续的处理使用。
}
n = n->next;
}
return NULL; //没找到匹配的节点,返回NULL
}
链表的遍历
使用node = node->next的方式,依次得到各个节点,对各个节点使用handle方法,即实现了链表的遍历。
void list_traverse(List *list, void (*handle)(void *)) //handle为节点遍历策略,由用户自己编写
{
struct node *p;
p = list->head;
while(p){
handle(p->data);
p = p->next;
}
}
{
struct node *p;
p = list->head;
while(p){
handle(p->data);
p = p->next;
}
}
链表的搜索
根据用户给点的数据遍历匹配节点,如果找到了,则将该节点的数据域返回给用户;找不到返回NULL。
void *list_search(List *list, void *key, int (*compare)(const void *, const void *)) //以key为搜索关键词,compare为节点数据比较机制,由用户自己编写
{
struct node *n;
n = list->head;
while(n){
if(!compare(n->data, key)){ //找到了,返回找到的数据
return n->data;
}
n = n->next;
}
return NULL; //找不到,返回NULL
}
{
struct node *n;
n = list->head;
while(n){
if(!compare(n->data, key)){ //找到了,返回找到的数据
return n->data;
}
n = n->next;
}
return NULL; //找不到,返回NULL
}
链表的排序
排序思想:新建一个链表tmp,然后依次取出原链表list中的最小节点,以头插法或者尾插法的机制插入到tmp链表中,直到原链表list为空。然后再把list指向tmp,此时list即为排序好的链表。当然也可以采用选择排序、冒泡排序等其它方式实现。
static struct node * find_min_node(List *list,
int (*compare)(const void *, const void *)) //找最小节点,链表排序用;以compare为比较机制,由用户自己编写
{
struct node *min, *n;
n = list->head;
min = list->head;
while(n) {
if(compare(min->data, n->data) > 0) {
min = n;
}
n = n->next;
}
return min;
}
static void delete_node(List *list, struct node *key) //以节点数据key为关键词,删除匹配的节点,链表排序用;
{
struct node *n;
n = list->head;
if(n == key){
list->head = n->next;
return;
}
while(n->next){
if(n->next == key){
if(key == list->tail){
list->tail = n;
}
n->next = n->next->next;
return;
}
n = n->next;
}
}
static void insert_node(List *list, struct node *key)//以节点数据key为关键词,插入匹配的节点,链表排序用;
{
if(list->head == NULL){
list->head = key;
list->tail = key;
}else{
list->tail->next = key;
list->tail = key;
}
}
void list_sort(List *list,
int (*compare)(void *, void *))
{
List tmp;
struct node *n;
list_init(&tmp);
while(! is_empty(list)) {
n = find_min_node(list, compare);
delete_node(list, n);
n->next = NULL;
insert_node(&tmp, n);
}
list->head = tmp.head;
list->tail = tmp.tail;
}
int (*compare)(const void *, const void *)) //找最小节点,链表排序用;以compare为比较机制,由用户自己编写
{
struct node *min, *n;
n = list->head;
min = list->head;
while(n) {
if(compare(min->data, n->data) > 0) {
min = n;
}
n = n->next;
}
return min;
}
static void delete_node(List *list, struct node *key) //以节点数据key为关键词,删除匹配的节点,链表排序用;
{
struct node *n;
n = list->head;
if(n == key){
list->head = n->next;
return;
}
while(n->next){
if(n->next == key){
if(key == list->tail){
list->tail = n;
}
n->next = n->next->next;
return;
}
n = n->next;
}
}
static void insert_node(List *list, struct node *key)//以节点数据key为关键词,插入匹配的节点,链表排序用;
{
if(list->head == NULL){
list->head = key;
list->tail = key;
}else{
list->tail->next = key;
list->tail = key;
}
}
void list_sort(List *list,
int (*compare)(void *, void *))
{
List tmp;
struct node *n;
list_init(&tmp);
while(! is_empty(list)) {
n = find_min_node(list, compare);
delete_node(list, n);
n->next = NULL;
insert_node(&tmp, n);
}
list->head = tmp.head;
list->tail = tmp.tail;
}
链表逆序
如下图所示:
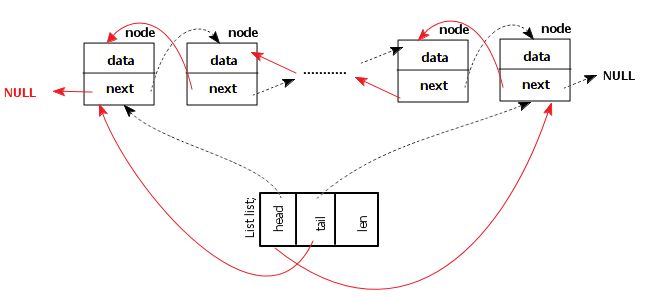
基本思想:遍历一遍链表,依次处理每个节点的next指针指向;遍历完一遍链表,链表的顺序就倒置过来了。见下列程序实现:
void list_reverse(List *list)
{
struct node *pre = NULL, *next, *p = list->head;
list->tail = list->head; //tail指向head;第一次head到tail的倒置。
while(p){
next = p->next;
if(!next){ //当p->next为最后一个节点时,让head指向p->next;最后一次tail到head的倒置。
list->head = p;
}
//备份当前节点为pre,作为其下一个节点的next(第一个节点为NULL,初始化时已定义);中间部分节点的倒置。
p->next = pre;
pre = p;
p = next;
}
}
{
struct node *pre = NULL, *next, *p = list->head;
list->tail = list->head; //tail指向head;第一次head到tail的倒置。
while(p){
next = p->next;
if(!next){ //当p->next为最后一个节点时,让head指向p->next;最后一次tail到head的倒置。
list->head = p;
}
//备份当前节点为pre,作为其下一个节点的next(第一个节点为NULL,初始化时已定义);中间部分节点的倒置。
p->next = pre;
pre = p;
p = next;
}
}
求链表长度
由于链表结构中添加了len属性,因此获取链表长度,直接读取len即可。如果链表结构中不实用len属性,则需要遍历一遍链表,统计循环次数。
程序实现:
long get_lenth(List *list)
{
return (list->len);
}
{
return (list->len);
}
获取链表某节点的数据
遍历链表到第idx个节点,将该节点处的数据返回给用户即可。
程序实现:
void *list_get_element(List *list, int idx)
{
int i = 0;
struct node *n;
n = list->head;
while(n && i < idx){
i ++;
n = n->next;
}
if(n){
return n->data;
}
return NULL;
}
{
int i = 0;
struct node *n;
n = list->head;
while(n && i < idx){
i ++;
n = n->next;
}
if(n){
return n->data;
}
return NULL;
}
链表的注销
使用完链表之后,需要销毁链表来释放资源;秉着谁的数据谁负责的原则,需要传递一个函数指针到list_destroy中,用于销毁节点的数据;
void list_destroy(List *list, void (*destroy)(void *)) //destroy为销毁链表时对节点数据的处理函数,由用户自己编写。传递NULL时表示不做处理
{
list->len = 0;
struct node *n, *tmp;
n = list->head;
while(n){
tmp = n->next; //tmp只起一个记录n->next的功能,否则后面把n free掉之后,就找不到n->next了。
if(destroy){ //传递用户自定义的数据处理函数,为0时不执行
destroy(n->data); //使用用户提供的destroy函数来释放用户的数据。
}
free(n);
n = tmp; //把n free掉之后,再把tmp给n,相当于把n->next给n,如此循环遍历链表,挨个删除。
}
}
{
list->len = 0;
struct node *n, *tmp;
n = list->head;
while(n){
tmp = n->next; //tmp只起一个记录n->next的功能,否则后面把n free掉之后,就找不到n->next了。
if(destroy){ //传递用户自定义的数据处理函数,为0时不执行
destroy(n->data); //使用用户提供的destroy函数来释放用户的数据。
}
free(n);
n = tmp; //把n free掉之后,再把tmp给n,相当于把n->next给n,如此循环遍历链表,挨个删除。
}
}
Sample1
简单的功能测试函数,程序无实际意义。
#include <stdio.h>
#include "list.h"
typedef struct test{
int val1;
float val2;
}test_t;
void handle(void *data)
{
test_t *test = (test_t *)data;
printf("val1:%d, val2:%f\n", test->val1, test->val2);
}
int compare_int(const void *s1, const void *s2)
{
test_t *data1 = (test_t *)s1;
int *data2 =(int *)s2;
return (data1->val1 - *data2);
}
int compare_int_sort(const void *s1, const void *s2)
{
test_t *data1 = (test_t *)s1;
test_t *data2 = (test_t *)s2;
return (data1->val1 - data2->val1);
}
void print(List *list)
{
printf("list len = %ld\n", list_get_lenth(list));
if(!is_empty(list)){
//test list_reverse
list_traverse(list, handle);
}
else{
printf("\tthe list is empty\n");
}
}
int main(void)
{
List list;
list_init(&list);
test_t test1 = {10, 10.5};
test_t test2 = {20, 20.5};
test_t test3 = {30, 30.5};
test_t test4 = {40, 40.5};
test_t test5 = {50, 50.5};
//test list_insert
printf("------insert(_at_tail)----\n");
list_insert(&list, &test1);
list_insert(&list, &test2);
list_insert(&list, &test3);
print(&list);
//test list_delete
printf("------delete----\n");
list_delete(&list, &test1.val1, compare_int);
print(&list);
//test list_insert_at_head
printf("------insert_at_head----\n");
list_insert_at_head(&list, &test4);
print(&list);
//test list_insert_at_index
printf("------insert_at_index(2)----\n");
list_insert_at_index(&list, &test5, 2);
print(&list);
//test list_reverse
printf("------reverse----\n");
list_reverse(&list);
print(&list);
//test list_search
int key = 20;
test_t *ret;
printf("------search----\n");
ret = list_search(&list, &key, compare_int);
printf("%d:%f\n", ret->val1, ret->val2);
key = 50;
ret = list_search(&list, &key, compare_int);
printf("%d:%f\n", ret->val1, ret->val2);
//test list_get_element
printf("------list_get_element----\n");
ret = list_get_element(&list, 2);
printf("%d:%f\n", ret->val1, ret->val2);
ret = list_get_element(&list, 3);
printf("%d:%f\n", ret->val1, ret->val2);
//test list_sort
printf("-----sort----\n");
list_sort(&list, compare_int_sort);
print(&list);
//test list_destroy
printf("-----destroy----\n");
list_destroy(&list, NULL);
return 0;
}
#include "list.h"
typedef struct test{
int val1;
float val2;
}test_t;
void handle(void *data)
{
test_t *test = (test_t *)data;
printf("val1:%d, val2:%f\n", test->val1, test->val2);
}
int compare_int(const void *s1, const void *s2)
{
test_t *data1 = (test_t *)s1;
int *data2 =(int *)s2;
return (data1->val1 - *data2);
}
int compare_int_sort(const void *s1, const void *s2)
{
test_t *data1 = (test_t *)s1;
test_t *data2 = (test_t *)s2;
return (data1->val1 - data2->val1);
}
void print(List *list)
{
printf("list len = %ld\n", list_get_lenth(list));
if(!is_empty(list)){
//test list_reverse
list_traverse(list, handle);
}
else{
printf("\tthe list is empty\n");
}
}
int main(void)
{
List list;
list_init(&list);
test_t test1 = {10, 10.5};
test_t test2 = {20, 20.5};
test_t test3 = {30, 30.5};
test_t test4 = {40, 40.5};
test_t test5 = {50, 50.5};
//test list_insert
printf("------insert(_at_tail)----\n");
list_insert(&list, &test1);
list_insert(&list, &test2);
list_insert(&list, &test3);
print(&list);
//test list_delete
printf("------delete----\n");
list_delete(&list, &test1.val1, compare_int);
print(&list);
//test list_insert_at_head
printf("------insert_at_head----\n");
list_insert_at_head(&list, &test4);
print(&list);
//test list_insert_at_index
printf("------insert_at_index(2)----\n");
list_insert_at_index(&list, &test5, 2);
print(&list);
//test list_reverse
printf("------reverse----\n");
list_reverse(&list);
print(&list);
//test list_search
int key = 20;
test_t *ret;
printf("------search----\n");
ret = list_search(&list, &key, compare_int);
printf("%d:%f\n", ret->val1, ret->val2);
key = 50;
ret = list_search(&list, &key, compare_int);
printf("%d:%f\n", ret->val1, ret->val2);
//test list_get_element
printf("------list_get_element----\n");
ret = list_get_element(&list, 2);
printf("%d:%f\n", ret->val1, ret->val2);
ret = list_get_element(&list, 3);
printf("%d:%f\n", ret->val1, ret->val2);
//test list_sort
printf("-----sort----\n");
list_sort(&list, compare_int_sort);
print(&list);
//test list_destroy
printf("-----destroy----\n");
list_destroy(&list, NULL);
return 0;
}
输出结果如下所示:
--
--
--insert(_at_tail)
--
--
list len = 3
val1 : 10, val2 : 10. 500000
val1 : 20, val2 : 20. 500000
val1 : 30, val2 : 30. 500000
-- -- --delete -- --
list len = 2
val1 : 20, val2 : 20. 500000
val1 : 30, val2 : 30. 500000
-- -- --insert_at_head -- --
list len = 3
val1 : 40, val2 : 40. 500000
val1 : 20, val2 : 20. 500000
val1 : 30, val2 : 30. 500000
-- -- --insert_at_index( 2) -- --
list len = 4
val1 : 40, val2 : 40. 500000
val1 : 20, val2 : 20. 500000
val1 : 50, val2 : 50. 500000
val1 : 30, val2 : 30. 500000
-- -- --reverse -- --
list len = 4
val1 : 30, val2 : 30. 500000
val1 : 50, val2 : 50. 500000
val1 : 20, val2 : 20. 500000
val1 : 40, val2 : 40. 500000
-- -- --search -- --
20 : 20. 500000
50 : 50. 500000
-- -- --list_get_element -- --
50 : 50. 500000
20 : 20. 500000
-- -- -sort -- --
list len = 4
val1 : 20, val2 : 20. 500000
val1 : 30, val2 : 30. 500000
val1 : 40, val2 : 40. 500000
val1 : 50, val2 : 50. 500000
-- -- -destroy -- --
list len = 3
val1 : 10, val2 : 10. 500000
val1 : 20, val2 : 20. 500000
val1 : 30, val2 : 30. 500000
-- -- --delete -- --
list len = 2
val1 : 20, val2 : 20. 500000
val1 : 30, val2 : 30. 500000
-- -- --insert_at_head -- --
list len = 3
val1 : 40, val2 : 40. 500000
val1 : 20, val2 : 20. 500000
val1 : 30, val2 : 30. 500000
-- -- --insert_at_index( 2) -- --
list len = 4
val1 : 40, val2 : 40. 500000
val1 : 20, val2 : 20. 500000
val1 : 50, val2 : 50. 500000
val1 : 30, val2 : 30. 500000
-- -- --reverse -- --
list len = 4
val1 : 30, val2 : 30. 500000
val1 : 50, val2 : 50. 500000
val1 : 20, val2 : 20. 500000
val1 : 40, val2 : 40. 500000
-- -- --search -- --
20 : 20. 500000
50 : 50. 500000
-- -- --list_get_element -- --
50 : 50. 500000
20 : 20. 500000
-- -- -sort -- --
list len = 4
val1 : 20, val2 : 20. 500000
val1 : 30, val2 : 30. 500000
val1 : 40, val2 : 40. 500000
val1 : 50, val2 : 50. 500000
-- -- -destroy -- --
获取Sample1
源码
Sample2
预计是一个学生信息管理系统,待续.......
后记
通过
valgrind这个工具可以检测内存泄漏,ubuntu下使用
sudo apt-get install valgrind即可安装;使用方法:
valgrind --tool=memcheck ./app
Sample1的检查结果如下所示:
$ valgrind
--tool
=memcheck .
/app
==4298== Memcheck, a memory error detector
==4298== Copyright (C) 2002-2009, and GNU GPL'd , by Julian Seward et al.
==4298== Using Valgrind-3.6.0.SVN-Debian and LibVEX; rerun with -h for copyright info
==4298== Command: ./app
==4298==
....
....
....
==4298==
==4298== HEAP SUMMARY:
==4298== in use at exit: 0 bytes in 0 blocks
==4298== total heap usage: 5 allocs, 5 frees, 40 bytes allocated
==4298==
==4298== All heap blocks were freed -- no leaks are possible
==4298==
==4298== Memcheck, a memory error detector
==4298== Copyright (C) 2002-2009, and GNU GPL'd , by Julian Seward et al.
==4298== Using Valgrind-3.6.0.SVN-Debian and LibVEX; rerun with -h for copyright info
==4298== Command: ./app
==4298==
....
....
....
==4298==
==4298== HEAP SUMMARY:
==4298== in use at exit: 0 bytes in 0 blocks
==4298== total heap usage: 5 allocs, 5 frees, 40 bytes allocated
==4298==
==4298== All heap blocks were freed -- no leaks are possible
==4298==
通过valgrind的检测,我们发现,程序退出时,仍有0个内存块上的0字节未释放,即程序所申请的内存已经全部释放;堆内存一共申请了5次,释放了5次,共申请了40个字节;所有堆内存都释放了,没有内存泄漏。推荐你也使用一下,与之功能相同的软件有很多,不再一一赘述。
附件列表