基于驾驶训练优化算法的函数寻优算法
文章目录
- 一、理论基础
-
- 1、驾驶训练优化算法
-
- (1)第一阶段:驾驶教练培训(探索)
- (2)第二阶段:学员驾驶技能的模式化(探索)
- (3)第三阶段:个人实践(开发)
- 2、DTBO算法伪代码
- 二、仿真实验与结果分析
- 三、参考文献
一、理论基础
1、驾驶训练优化算法
文献[1]提出了一种新的随机优化算法,即基于驾驶训练的随机优化算法(Driving Training‑Based Optimization, DTBO),该算法模拟了驾驶员的驾驶训练行为。DTBO设计背后的基本灵感来自于驾校学习驾驶的过程和驾校教练的培训。DTBO的数学模型分为三个阶段:(1)驾驶教练的训练;(2)教练技能对学生的模式化;(3)实践。
DTBO是一种基于种群的元启发式方法,其成员包括驾驶学习者和教员。DTBO成员是使用式(1)中称为种群矩阵的矩阵建模的给定问题的候选解决方案。使用式(2)随机初始化这些成员在实施开始时的初始位置。 X = [ X 1 ⋮ X i ⋮ X N ] N × m = [ x 11 ⋯ x 1 j ⋯ x 1 m ⋮ ⋱ ⋮ ⋱ ⋮ x i 1 ⋯ x i j ⋯ x i m ⋮ ⋱ ⋮ ⋱ ⋮ x N 1 ⋯ x N j ⋯ x N m ] N × m (1) X=\begin{bmatrix}X_1\\\vdots\\X_i\\\vdots\\X_N\end{bmatrix}_{N\times m}=\begin{bmatrix}x_{11} & \cdots & x_{1j} & \cdots & x_{1m}\\\vdots & \ddots &\vdots & \ddots & \vdots\\x_{i1} & \cdots & x_{ij} & \cdots & x_{im}\\\vdots & \ddots &\vdots & \ddots & \vdots\\x_{N1} & \cdots & x_{Nj} & \cdots & x_{Nm}\end{bmatrix}_{N\times m}\tag{1} X=⎣ ⎡X1⋮Xi⋮XN⎦ ⎤N×m=⎣ ⎡x11⋮xi1⋮xN1⋯⋱⋯⋱⋯x1j⋮xij⋮xNj⋯⋱⋯⋱⋯x1m⋮xim⋮xNm⎦ ⎤N×m(1) x i , j = l b j + r ⋅ ( u b j − l b j ) , i = 1 , 2 , … , N , j = 1 , 2 , … , m (2) x_{i,j}=lb_j+r\cdot(ub_j-lb_j),\quad i=1,2,\ldots,N,\,\,j=1,2,\ldots,m\tag{2} xi,j=lbj+r⋅(ubj−lbj),i=1,2,…,N,j=1,2,…,m(2)其中, X X X是DTBO算法的种群矩阵, X i X_i Xi是第 i i i个候选解, x i , j x_{i,j} xi,j是由第 i i i个候选解确定的第 j j j个变量的值, N N N是DTBO算法的种群数量, m m m是问题变量的个数, r r r是 [ 0 , 1 ] [0,1] [0,1]间的随机数, l b j lb_j lbj和 u b j ub_j ubj分别是第 j j j维变量的下界和上界。
每个候选解决方案都为问题变量赋值,通过将其放入目标函数中,对目标函数进行评估。因此,计算与每个候选解对应的目标函数的值。式(3)中的向量对目标函数的值进行建模。 F = [ F 1 ⋮ F i ⋮ F N ] N × 1 = [ F ( X 1 ) ⋮ F ( X i ) ⋮ F ( X N ) ] N × 1 (3) F=\begin{bmatrix}F_1\\\vdots\\F_i\\\vdots\\F_N\end{bmatrix}_{N\times1}=\begin{bmatrix}F(X_1)\\\vdots\\F(X_i)\\\vdots\\F(X_N)\end{bmatrix}_{N\times1}\tag{3} F=⎣ ⎡F1⋮Fi⋮FN⎦ ⎤N×1=⎣ ⎡F(X1)⋮F(Xi)⋮F(XN)⎦ ⎤N×1(3)其中, F F F为目标函数的向量, F i F_i Fi为第 i i i个候选解的目标函数值。
目标函数获得的值是确定候选解的好坏的标准。基于对目标函数值的比较,对目标函数具有最佳值的成员称为种群中的最佳成员( X b e s t X_{best} Xbest)。由于候选解在每次迭代中都会得到改进和更新,因此必须更新最佳成员。
元启发式算法之间的主要区别在于更新候选解的过程中采用的策略。在DTBO中,候选解决方案在以下三个不同阶段进行更新:(i)由驾驶教师培训学习型驾驶员,(ii)根据教师技能对学员进行模式化,(iii)练习学员。
(1)第一阶段:驾驶教练培训(探索)
DTBO更新的第一阶段是基于学员对驾驶教练的选择,然后由所选的驾驶教练对学员进行驾驶培训。在DTBO人群中,挑选出一些最优秀的成员被认为是驾驶教练,其余的被认为是学员。选择驾驶教练并学习该教练的技能将导致成员移动到搜索空间的不同区域。这将增加DTBO在全局搜索和发现最优区域方面的探索能力。因此,DTBO更新的这一阶段展示了该算法的探索能力。在每次迭代中,根据目标函数值的比较,选择DTBO的 N N N个成员作为驾驶教练,如式(4)所示。 D I = [ D I 1 ⋮ D I i ⋮ D I N D I ] N D I × m = [ D I 11 ⋯ D I 1 j ⋯ D I 1 m ⋮ ⋱ ⋮ ⋱ ⋮ D I i 1 ⋯ D I i j ⋯ D I i m ⋮ ⋱ ⋮ ⋱ ⋮ D I N D I 1 ⋯ D I N D I j ⋯ D I N D I m ] N D I × m (4) DI=\begin{bmatrix}DI_1\\\vdots\\DI_i\\\vdots\\DI_{N_{DI}}\end{bmatrix}_{N_{DI}\times m}=\begin{bmatrix}DI_{11} & \cdots & DI_{1j} & \cdots & DI_{1m}\\\vdots & \ddots &\vdots & \ddots & \vdots\\DI_{i1} & \cdots & DI_{ij} & \cdots & DI_{im}\\\vdots & \ddots &\vdots & \ddots & \vdots\\DI_{N_{DI}1} & \cdots & DI_{N_{DI}j} & \cdots & DI_{N_{DI}m}\end{bmatrix}_{N_{DI}\times m}\tag{4} DI=⎣ ⎡DI1⋮DIi⋮DINDI⎦ ⎤NDI×m=⎣ ⎡DI11⋮DIi1⋮DINDI1⋯⋱⋯⋱⋯DI1j⋮DIij⋮DINDIj⋯⋱⋯⋱⋯DI1m⋮DIim⋮DINDIm⎦ ⎤NDI×m(4)其中, D I DI DI为驾驶教练矩阵, D I i DI_i DIi为第 i i i个驾驶教练, D I i , j DI_{i,j} DIi,j为其第 j j j维; N D I = ⌊ 0.1 ⋅ N ⋅ ( 1 − t / T ) ⌋ N_{DI}=\lfloor0.1\cdot N\cdot(1-t/T)\rfloor NDI=⌊0.1⋅N⋅(1−t/T)⌋为驾驶教练人数,其中 t t t为当前迭代次数, T T T为最大迭代次数。
首先,使用式(5)计算每个成员的新位置。然后,根据式(6),如果这个新位置改善了目标函数的值,那么这个新位置将取代之前的位置。 x i , j P 1 = { x i , j + r ⋅ ( D I k i , j − I ⋅ x i , j ) , F D I k i < F i x i , j + r ⋅ ( x i , j − D I k i , j ) , otherwise (5) x_{i,j}^{P1}=\begin{dcases}x_{i,j}+r\cdot(DI_{k_i,j}-I\cdot x_{i,j}),\quad F_{DI_{k_i}}
(2)第二阶段:学员驾驶技能的模式化(探索)
DTBO更新的第二阶段是基于新手驾驶员对教练的模仿,即学员尝试模仿教练的所有动作和技能。这个过程将DTBO成员移动到搜索空间中的不同位置,从而增加了DTBO的探索能力。为了在数学上模拟这个概念,根据式(7)的每个成员与教员的线性组合生成一个新的位置,如果这个新位置改善了目标函数的值,则根据式(8)替换之前的位置。 x i , j P 2 = P ⋅ x i , j + ( 1 − P ) ⋅ D I k i , j (7) x_{i,j}^{P2}=P\cdot x_{i,j}+(1-P)\cdot DI_{k_i,j}\tag{7} xi,jP2=P⋅xi,j+(1−P)⋅DIki,j(7) X i = { X i P 2 , F i P 2 < F i X i , otherwise (8) X_i=\begin{dcases}X_i^{P2},\quad\, F_i^{P2}
(3)第三阶段:个人实践(开发)
第三阶段的DTBO更新是基于每个学员的个人实践,以提高驾驶技能。在这个阶段,每个初学者都试图接近自己的最佳技能。这一阶段允许每个成员在其当前位置周围进行局部搜索的基础上发现更好的位置。这个阶段演示了DTBO在开发局部搜索方面的强大能力。对这个DTBO阶段进行数学建模,首先根据式(10)在每个种群成员附近生成一个随机位置。然后,根据式(11),如果该位置改进了目标函数的值,则该位置将取代前一位置。 x i , j P 3 = x i , j + ( 1 − 2 r ) ⋅ R ⋅ ( 1 − t T ) ⋅ x i , j (10) x_{i,j}^{P3}=x_{i,j}+(1-2r)\cdot R\cdot\left(1-\frac tT\right)\cdot x_{i,j}\tag{10} xi,jP3=xi,j+(1−2r)⋅R⋅(1−Tt)⋅xi,j(10) X i = { X i P 3 , F i P 3 < F i X i , otherwise (11) X_i=\begin{dcases}X_i^{P3},\quad\, F_i^{P3}
2、DTBO算法伪代码
DTBO算法的伪代码如图1所示。

二、仿真实验与结果分析
将DTBO与PSO、GSA、TLBO、GWO、WOA、MPA、TSA、MVO和RSA进行对比,以常用23个测试函数中的F1、F4(单峰函数/30维)、F8、F9(多峰函数/30维)、F22、F23(固定维度多峰函数/4维、4维)为例,实验设置种群规模为30,最大迭代次数为1000,每种算法独立运算20次,结果显示如下:
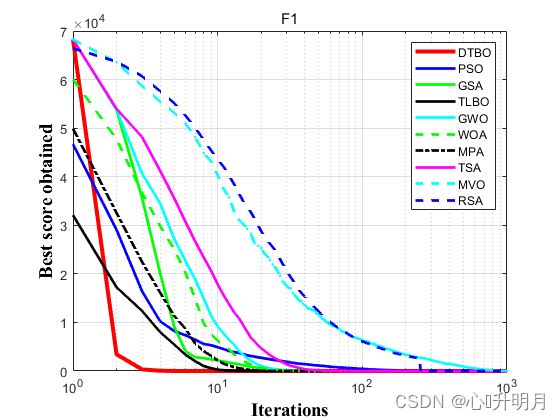
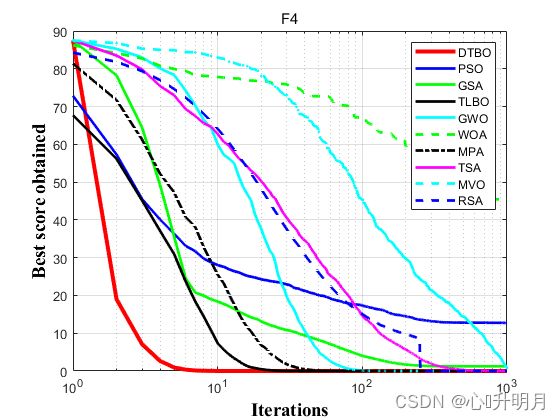
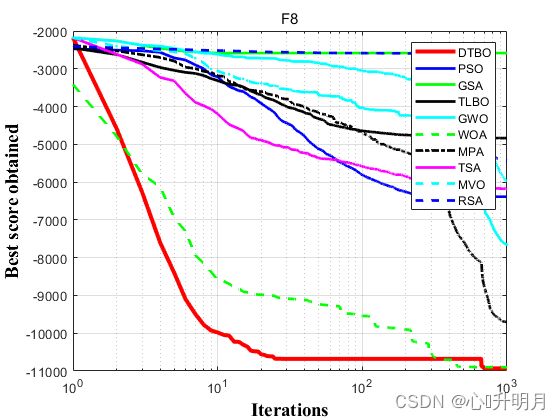

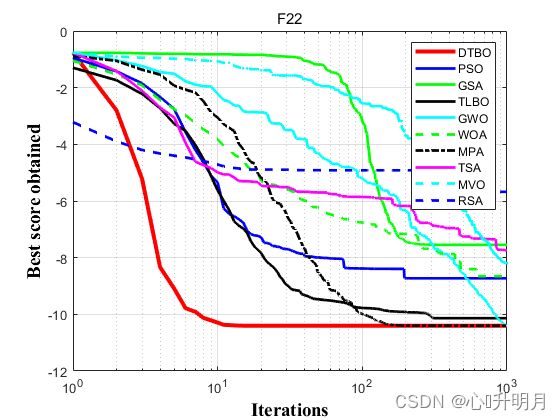
函数:F1
DTBO:最差值: 0, 最优值: 0, 平均值: 0, 标准差: 0, 秩和检验: NaN
PSO:最差值: 94.1204, 最优值: 21.4207, 平均值: 51.1621, 标准差: 19.7125, 秩和检验: 8.0065e-09
GSA:最差值: 1.7555e-16, 最优值: 6.2282e-17, 平均值: 1.1925e-16, 标准差: 2.9414e-17, 秩和检验: 8.0065e-09
TLBO:最差值: 1.9915e-252, 最优值: 2.5728e-260, 平均值: 1.5527e-253, 标准差: 0, 秩和检验: 8.0065e-09
GWO:最差值: 2.4764e-58, 最优值: 6.4648e-62, 平均值: 3.1734e-59, 标准差: 5.7572e-59, 秩和检验: 8.0065e-09
WOA:最差值: 6.1671e-151, 最优值: 2.986e-169, 平均值: 3.0836e-152, 标准差: 1.379e-151, 秩和检验: 8.0065e-09
MPA:最差值: 8.8367e-49, 最优值: 2.8684e-52, 平均值: 7.9028e-50, 标准差: 1.9723e-49, 秩和检验: 8.0065e-09
TSA:最差值: 2.9577e-46, 最优值: 1.3148e-50, 平均值: 4.1517e-47, 标准差: 7.2105e-47, 秩和检验: 8.0065e-09
MVO:最差值: 0.55072, 最优值: 0.16063, 平均值: 0.34444, 标准差: 0.10975, 秩和检验: 8.0065e-09
RSA:最差值: 0, 最优值: 0, 平均值: 0, 标准差: 0, 秩和检验: NaN
函数:F4
DTBO:最差值: 4.9407e-324, 最优值: 0, 平均值: 0, 标准差: 0, 秩和检验: 1
PSO:最差值: 15.8846, 最优值: 9.6113, 平均值: 12.7292, 标准差: 1.9798, 秩和检验: 2.8636e-08
GSA:最差值: 4.0953, 最优值: 1.3017e-08, 平均值: 1.236, 标准差: 1.3, 秩和检验: 2.8636e-08
TLBO:最差值: 9.9574e-122, 最优值: 1.8543e-125, 平均值: 7.1601e-123, 标准差: 2.2632e-122, 秩和检验: 2.8636e-08
GWO:最差值: 6.1308e-14, 最优值: 7.5078e-16, 平均值: 1.4563e-14, 标准差: 1.6816e-14, 秩和检验: 2.8636e-08
WOA:最差值: 83.2429, 最优值: 0.046988, 平均值: 45.4546, 标准差: 29.1516, 秩和检验: 2.8636e-08
MPA:最差值: 1.5892e-18, 最优值: 2.5828e-20, 平均值: 3.4682e-19, 标准差: 3.478e-19, 秩和检验: 2.8636e-08
TSA:最差值: 0.047332, 最优值: 5.983e-05, 平均值: 0.0060028, 标准差: 0.011607, 秩和检验: 2.8636e-08
MVO:最差值: 1.5395, 最优值: 0.36337, 平均值: 0.80149, 标准差: 0.26239, 秩和检验: 2.8636e-08
RSA:最差值: 0, 最优值: 0, 平均值: 0, 标准差: 0, 秩和检验: 0.01945
函数:F8
DTBO:最差值: -6055.2965, 最优值: -12569.4866, 平均值: -10932.3441, 标准差: 2039.6663, 秩和检验: 1
PSO:最差值: -5297.0288, 最优值: -7981.5834, 平均值: -6386.2856, 标准差: 841.0953, 秩和检验: 3.625e-07
GSA:最差值: -1804.7885, 最优值: -3435.5199, 平均值: -2584.8971, 标准差: 443.3003, 秩和检验: 6.1882e-08
TLBO:最差值: -4160.0995, 最优值: -5672.4358, 平均值: -4835.8365, 标准差: 434.7945, 秩和检验: 6.1882e-08
GWO:最差值: -4681.2686, 最优值: -6679.1921, 平均值: -5973.3057, 标准差: 583.4896, 秩和检验: 3.625e-07
WOA:最差值: -8361.6676, 最优值: -12567.3731, 平均值: -10900.4761, 标准差: 1596.7113, 秩和检验: 0.037915
MPA:最差值: -8730.8362, 最优值: -10927.9839, 平均值: -9698.5444, 标准差: 572.9746, 秩和检验: 0.10067
TSA:最差值: -5180.4239, 最优值: -7328.2681, 平均值: -6187.8641, 标准差: 515.3844, 秩和检验: 3.625e-07
MVO:最差值: -6802.1623, 最优值: -8419.6343, 平均值: -7652.7358, 标准差: 485.0641, 秩和检验: 1.1126e-06
RSA:最差值: -4867.4014, 最优值: -5783.8982, 平均值: -5428.5941, 标准差: 226.7074, 秩和检验: 6.1794e-08
函数:F9
DTBO:最差值: 0, 最优值: 0, 平均值: 0, 标准差: 0, 秩和检验: NaN
PSO:最差值: 80.5132, 最优值: 31.9342, 平均值: 55.9099, 标准差: 11.9032, 秩和检验: 8.0065e-09
GSA:最差值: 92.5304, 最优值: 14.9244, 平均值: 34.2265, 标准差: 16.7778, 秩和检验: 7.9919e-09
TLBO:最差值: 0, 最优值: 0, 平均值: 0, 标准差: 0, 秩和检验: NaN
GWO:最差值: 4.5901, 最优值: 0, 平均值: 0.39471, 标准差: 1.2327, 秩和检验: 0.040127
WOA:最差值: 0, 最优值: 0, 平均值: 0, 标准差: 0, 秩和检验: NaN
MPA:最差值: 0, 最优值: 0, 平均值: 0, 标准差: 0, 秩和检验: NaN
TSA:最差值: 235.4443, 最优值: 70.8933, 平均值: 157.6332, 标准差: 44.313, 秩和检验: 8.0065e-09
MVO:最差值: 167.3692, 最优值: 52.8361, 平均值: 115.9141, 标准差: 30.9301, 秩和检验: 8.0065e-09
RSA:最差值: 0, 最优值: 0, 平均值: 0, 标准差: 0, 秩和检验: NaN
函数:F22
DTBO:最差值: -10.4029, 最优值: -10.4029, 平均值: -10.4029, 标准差: 1.092e-06, 秩和检验: 1
PSO:最差值: -2.7519, 最优值: -10.4029, 平均值: -8.7293, 标准差: 3.0331, 秩和检验: 0.0066974
GSA:最差值: -1.0939, 最优值: -10.4029, 平均值: -7.5456, 标准差: 3.0577, 秩和检验: 1
TLBO:最差值: -5.0877, 最优值: -10.4029, 平均值: -10.1372, 标准差: 1.1885, 秩和检验: 1.0154e-06
GWO:最差值: -10.4021, 最优值: -10.4028, 平均值: -10.4026, 标准差: 0.00016268, 秩和检验: 6.7956e-08
WOA:最差值: -3.7241, 最优值: -10.4027, 平均值: -8.6523, 标准差: 2.7247, 秩和检验: 6.7956e-08
MPA:最差值: -10.4029, 最优值: -10.4029, 平均值: -10.4029, 标准差: 3.645e-15, 秩和检验: 8.0065e-09
TSA:最差值: -1.8336, 最优值: -10.3649, 平均值: -7.741, 标准差: 3.5704, 秩和检验: 6.7956e-08
MVO:最差值: -2.7659, 最优值: -10.4029, 平均值: -8.1984, 标准差: 3.1615, 秩和检验: 6.7956e-08
RSA:最差值: -0.81598, 最优值: -10.4029, 平均值: -5.6746, 标准差: 3.5504, 秩和检验: 1.0646e-07
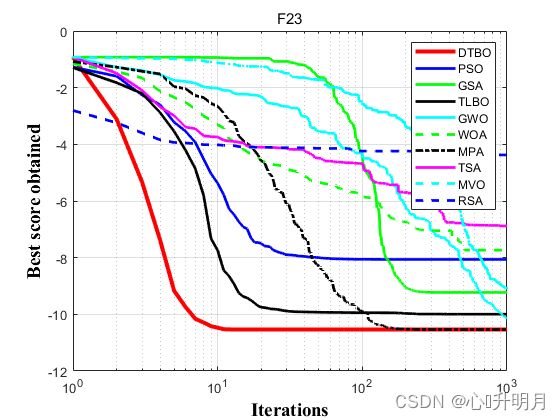
函数:F23
DTBO:最差值: -10.5364, 最优值: -10.5364, 平均值: -10.5364, 标准差: 8.0636e-07, 秩和检验: 1
PSO:最差值: -2.4217, 最优值: -10.5364, 平均值: -8.0615, 标准差: 3.5232, 秩和检验: 0.10272
GSA:最差值: -4.0368, 最优值: -10.5364, 平均值: -9.2269, 标准差: 2.3809, 秩和检验: 0.0067864
TLBO:最差值: -5.1285, 最优值: -10.5364, 平均值: -9.9956, 标准差: 1.6645, 秩和检验: 1.3439e-05
GWO:最差值: -2.4217, 最优值: -10.5363, 平均值: -10.1303, 标准差: 1.8144, 秩和检验: 6.7956e-08
WOA:最差值: -2.4216, 最优值: -10.5363, 平均值: -7.734, 标准差: 3.2621, 秩和检验: 6.7956e-08
MPA:最差值: -10.5364, 最优值: -10.5364, 平均值: -10.5364, 标准差: 2.4789e-15, 秩和检验: 3.789e-08
TSA:最差值: -1.6744, 最优值: -10.5029, 平均值: -6.8826, 标准差: 3.9962, 秩和检验: 6.7956e-08
MVO:最差值: -2.8711, 最优值: -10.5364, 平均值: -9.0762, 标准差: 2.6366, 秩和检验: 6.7956e-08
RSA:最差值: -1.0387, 最优值: -10.5346, 平均值: -4.3742, 标准差: 3.2908, 秩和检验: 6.7956e-08
实验结果表明:所提出的DTBO算法在优化和实现最优解方面更有效,比所比较的算法更具竞争力。
三、参考文献
[1] Mohammad D, Eva T, Pavel T. A new human-based metaheuristic algorithm for solving optimization problems on the base of simulation of driving training process[J]. Scientific Reports, 2022, 12: 9924.