MobileNetv1、MobileNetv2、MobileNetv3网络讲解
目录
- 前言
- 一.MobileNetv1
-
- 1.1.传统卷积
- 1.2.DW卷积
- 1.3.深度可分离卷积(Depthwise Separable Conv)
- 1.4.网络架构
- 1.5.超参数 α , ρ \alpha,\rho α,ρ
- 二.MobileNetv2
-
- 2.1.倒残差结构
- 2.2.倒残差结构图
- 三.MobileNetv3
-
- 3.1.更新Block
- 3.2.重新设计耗时层结构
- 3.3.重新设计激活函数
- 3.4.网络结构
前言
上篇博文我们介绍了Mobile-ViT网络模型,Mobile-ViT是一个基于MobileNet和ViT的轻量化网络模型,又不了解的小伙伴可以回到前面看看,Mobile-ViT (MobileViT)网络讲解,所以还是很有必要来研究下MobileNet这个网络的,下面附上MobileNet系列的官方论文链接。
- MobileNetv1:https://arxiv.org/abs/1704.04861v1
- MobileNetv2:https://arxiv.org/abs/1801.04381v4
- MobileNetv3:https://arxiv.org/abs/1905.02244v5
一.MobileNetv1
我们平常遇到的网络像VGG,Resnet,ViT等网络模型参数都很多,运算量也很大,模型推理时间慢等特点,无法在移动设备上运行。于是就诞生了MobileNet网络,MobileNet的出现就是为了让网络能够在移动端运行并且保证网络的性能不会下降太多,大大降低模型参数,提升模型的推理速度。如MobileNetv1的准确率相比于VGG16而言只降低了约0.9%,但是模型参数只有VGG的 1 32 \frac{1}{32} 321。MobileNet主要有以下两个亮点。
- 引入了
DW(Depthwise Convolution)卷积,大大降低了模型的参数和运算量- 增加了超参数 α , ρ \alpha,\rho α,ρ
1.1.传统卷积
我们先来看下传统卷积的计算方式及其计算量。

从上面的卷积过程可以发现,对于普通卷积而言,输入的特征图的通道个数是多少,那么卷积核的通道个数也需要是多少,这样的话假设我输入的是一个三通道的图像,输出也要保证三通道,那我我就需要两组卷积核,每组卷积核均为三通道的卷积来进行操作。
1.2.DW卷积
下面我们再来看下DW卷积的计算过程。我们仍以输入图像为三通道,输出为三通道为例进行计算。

从DW卷积过程可以看到,与普通卷积相比较,DW卷积在卷积的时候针对输入的图像的每个深度只使用一个卷积核,并且卷积核的深度只有1,也就是在DW卷积中是相当于输入的每个图像只有单通道,因此在卷积的时候卷积核的深度也就只需要一层就行了。由此可见,当输入的图像的深度比较大的时候,DW卷积能够极大的减少计算量。
我们总结一下普通卷积和DW卷积的各自特点。
普通卷积:
- 卷积核的通道数目等于输入特征矩阵的通道数目
- 输出特征矩阵的通道数目等于卷积核的个数
DW卷积:
- 卷积核的通道个数等于1
- 输入特征矩阵的通道个数等于卷积核个数=输出特征矩阵的通道个数
1.3.深度可分离卷积(Depthwise Separable Conv)
上面我们介绍了普通卷积和DW卷积,接下来我们再介绍另一种卷积:深度可分离卷积,他是由DW卷积+普通卷积(卷积核大小为1,也就是我们常说的点卷积)构成的。我们来看下深度可分离卷积的卷积过程。
深度可分离卷积:

普通卷积:
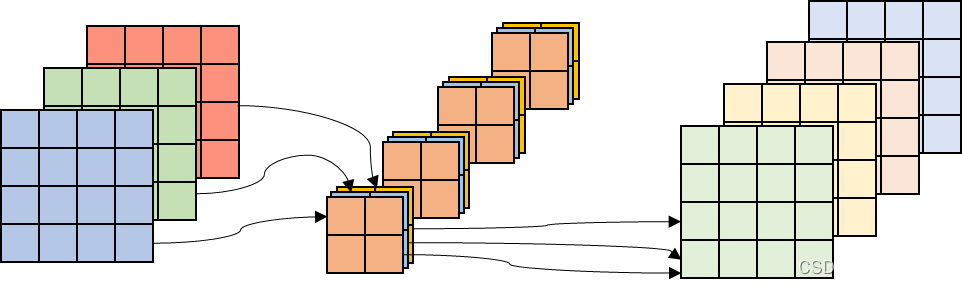
下面我们来对比下这两种卷积的计算量。在此我们先假设输入的特征矩阵的宽,高和通道个数分别为 W , H , C W,H,C W,H,C。卷积核的宽,高和卷积核个数个数大小为 K w , K h , K n K_{w},K_{h},K_{n} Kw,Kh,Kn,步距假设为1,输出深度为 K h K_{h} Kh。
普通卷积的参数计算量:
P 1 = W × H × C × K w × K h × K n P_{1}=W\times H\times C \times K_{w} \times K_{h} \times K_{n} P1=W×H×C×Kw×Kh×Kn
深度可分离卷积参数计算量:
P 2 = W × H × C × K w × K h × 1 + W × H × C × K n × 1 × 1 P_{2}=W\times H\times C \times K_{w} \times K_{h} \times 1 + W\times H\times C \times K_{n} \times 1\times 1 P2=W×H×C×Kw×Kh×1+W×H×C×Kn×1×1
我们来计算下 P 2 P 1 \frac{P{2}}{P_{1}} P1P2
P 2 P 1 = 1 K n + 1 K w × K h \frac{P_{2}}{P_{1}}=\frac{1}{K_{n}}+\frac{1}{K_{w}\times K_{h}} P1P2=Kn1+Kw×Kh1
可见,当我们的输出深度越大,卷积核个数越大的情况下,深度可分离卷积的参数越少。
1.4.网络架构
上面介绍了三种卷积的实现方式及参数计算,下面我们再来看下MobileNetv1的网络结构。

表中的Conv表示普通卷积,Conv dw表示DW卷积。Filter Shape表示的是卷积核的个数和输出深度。整个网络就是串行下来的,有点像VGG网络。
下面我们在看下MobileNet和其他网络的参数和准确率对比,如下表,可以看到MobileNet的准确率相比于VGG16而言,只下降了约1%而参数量却减少了约32倍。

1.5.超参数 α , ρ \alpha,\rho α,ρ
我们刚开始讲MobileNet的时候讲过MobileNet有两个亮点,一个是DW卷积,还一个就是增加了超参数 α , ρ \alpha,\rho α,ρ。
先来看下 α \alpha α, α \alpha α表示卷积核个数的倍率,控制卷积过程中采用的卷积核的个数,

结合论文中的表6我们看下, α \alpha α取不同的值的效果一目了然。

接下来我们在看下 ρ \rho ρ,分辨率倍率的超参数。

结合论文中的表7,不同的输入图像尺寸对模型的性能影响也一目了然。

关于MobileNet的原理部分基本上已经介绍完了,但是他存在一个致命的缺陷,就是在实际使用的时候会发现他的DW卷积卷积核的大部分参数都是0,没有起到任何作用。因此,就有出了MobileNetv2网络,对其进行了改进。
二.MobileNetv2
MobileNetv2是google在2018年提出的,相比于MobileNetv1而言,准确度更高,模型更小。他的亮点主要有两个:
- 倒残差结构(Inverted Residual)
- Linear Bottlenecks
2.1.倒残差结构
我们先来看下什么对比下残差结构和倒残差结构:

上图左边是残差结构,右图是倒残差结构。残差结构是先通过 1 × 1 1\times 1 1×1的卷积层对特征图进行降维,最后在通过 1 × 1 1\times 1 1×1进行升维操作。而倒残差结构是对输入特征图进行先升维,再进行降维。两者的运算过程完全相反。
注意:残差结构中间是普通卷积,激活函数是Relu;倒残差结构中间是DW卷积,激活函数是Relu6。两者的激活函数如下图所示:

2.2.倒残差结构图
我们来看下倒残差结构的具体结构,下图是论文中给的stride=1和stride=2的结构。

注意:
- 上面的残差结构的最后一个激活函数是线性的,而不是
Relu6。- 上面的
shorcut连接只有当stride=1且输入特征矩阵和输出特征矩阵的shape相同的时候才有shortcut连接。stride=2没有shortcut连接。
上面的操作可以用如下表来展示:

MobileNetv2的网络模型参数如下表:

- 上表中的t表示扩展因子,即经过第一层的 1 × 1 1\times1 1×1的卷积之后的扩展倍率。
- c表示输出特征矩阵的
channel,即对应上表中的 k ′ k^{\prime} k′。- n表示
bottleneck的重复次数。- s表示步距大小,他只针对第一层的
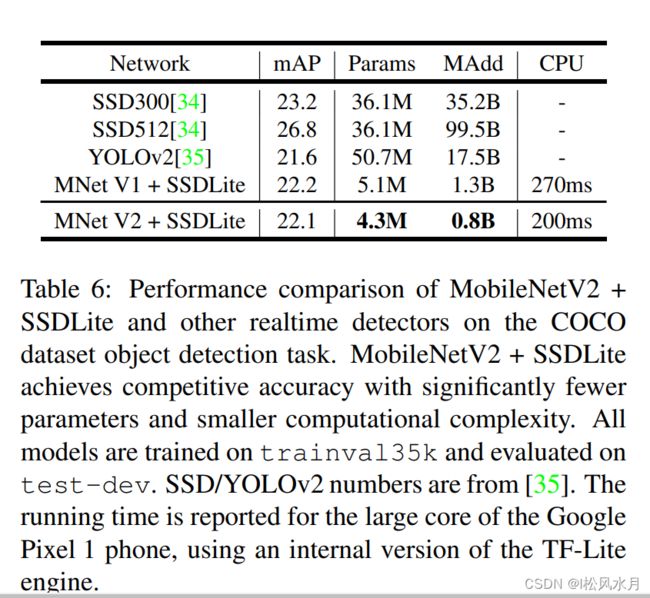
bottleneck的步距,其他的全为1。MobileNetv2的原理和架构基本上介绍完了,下面简单看下他的性能如何,直接放论文里面的几张表对比下。
分类:

检测:
三.MobileNetv3
接着我们来看下MobileNetv3网络,相比于MobileNetv2,MobileNetv3主要有以下三个亮点:
- 更新
Block- 使用
NAS搜索- 重新设计耗时层结构
- 重新设计激活函数
再来看下MobileNetv3的性能怎么样,从下面的表格可以看出,MobileNetv3的性能是要比MobileNetv2要高一点的,但是实际使用的时候用的比较多的还是MobileNet2网络。

3.1.更新Block
在介绍MobileNetv3的Block,我们在看下MobileNetv2的block模块:

那么MobileNetv3相比于MobileNetv2的改变是哪些呢,先上图:

整体上看着好像也没啥大的变化,仔细观察可以发现,MobileNetv3的block相比于MobileNetv2而言,好像就中间多了个SE注意力机制。这个注意力机制做了什么呢?他就是对得到的特征图的每个通道进行池化处理,channel等于多少,得到的一维向量就有多少个元素,后面再接两个全连接层得到输出向量。论文中说的是第一个全连接层的输出向量是输入的 1 4 \frac{1}{4} 41,第二个全连接层的输出向量是跟原始输入的保持一致。这样就给每个通道赋予了一个权重,根据重要程度赋予不大小的权重。这里还需要注意一点是MobileNetv3的每一层使用的激活函数不同。
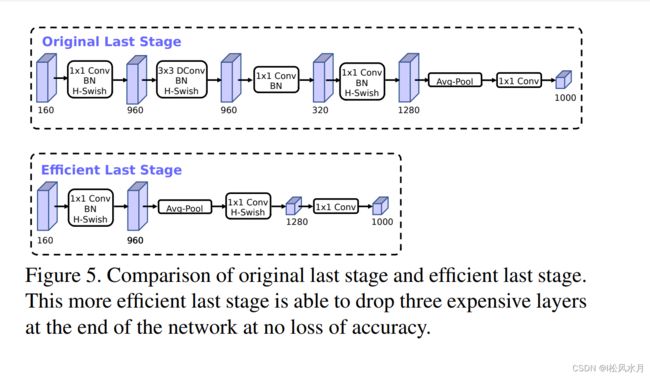
3.2.重新设计耗时层结构
关于这部分的内容,,论文中主要提到两个部分:
- 减少第一层卷积层的卷积核个数,由
32减少为16- 精简
Last Stage
针对第一个改进,作者提到把第一层的卷积核个数减少一般,模型的性能并没有变化。针对第二部分,作者使用NAS搜索出来的是下图中的Original Last Stage,这个结构比较耗时,于是做了一些精简得到下面的Efficient Last Stage结构,并且模型性能没有任何变化,还减少了模型的推理时间。
3.3.重新设计激活函数
作者改进了由Relu激活函数演变而来的swish激活函数,因为激活函数的计算和求导过程很复杂,并且对量化很不友好。因此作者提出了h-swish激活函数,改进了swish激活函数的上面提到的缺点。其实呢h-swish激活函数就是模仿swish激活函数由h-sigmoid激活函数演变而来的。我们来看下这几个函数的曲线长什么样。

3.4.网络结构

表中的Input表示的是输入当前层的shape、operator表示操作过程、exp_size表示bneck中的第一个 1 × 1 1 \times 1 1×1升维卷积,即经过 1 × 1 1 \times 1 1×1的卷积之后输出通道为多少、out表示输出的特征矩阵的通道数,即通过bneck的最后一个 1 × 1 1 \times 1 1×1卷积之后的输出通道数、SE表示是否使用注意力机制、NL表示激活函数是什么、s表示步距。bneck就是下图中的结构,bneck后面的 3 × 3 3 \times 3 3×3, 5 × 5 5 \times 5 5×5, 7 × 7 7 \times 7 7×7等表示DW卷积核的大小。上表中的最后两层有个NBN表示不使用BN层结构。个人感觉MobileNetv3网络真的就是炼丹练出来的,相比于MobileNetv2亮点不是很突出。

至此,MobileNetv1、MobileNetv2、MobileNetv3网络都介绍完了,欢迎各位大佬们批评指正。