图像处理黑科技——弯曲矫正、去摩尔纹、切边增强、PS检测
目录
- 0 前言
- 1 弯曲矫正
- 2 去摩尔纹
- 3 图像切边增强
- 4 PS检测
- 5 总结
0 前言
合合信息是行业领先的人工智能及大数据科技企业,专注文字识别领域16年,在智能文字识别及商业大数据等核心领域处于国内领先地位,全球企业和个人用户提供创新的数字化、智能化服务。合合信息提供的文字与图像处理黑科技已经不知不觉地影响了我们生活的方方面面,让我们来深入介绍一下那些你不曾注意到,但却实实在在给我们带来极大便捷的技术力量。

1 弯曲矫正
现代神经科学表明,哺乳动物大脑的初级视觉皮层的主要工作就是进行图像的字典表示,因为视觉是人类最重要的感觉——据不完全统计,至少80%以上的外界信息由视觉获得。然而,计算机获取图像的过程相当于用二维平面对三维客观世界进行降维表示,其中降低的维度称为深度,就像我们无法理解四维、五维等高维空间意义,二维平面图像因为维度丢失,导致图像处理的困难。
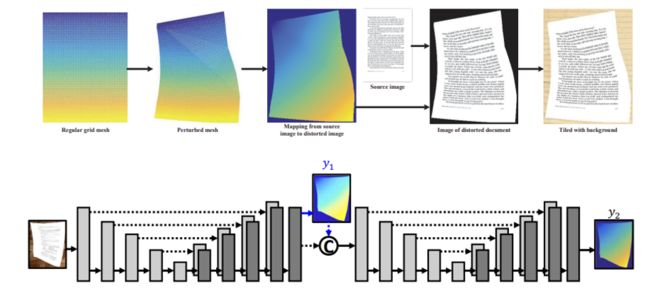
因为相机硬件不符合理论上透视相机模型针孔无限小的假设,所以真实图像会产生明显的径向失真——场景中的线条在图像中显示为曲线。径向畸变(Radial Distortion)有两种类型:筒体畸变(Barrel Distortion)与枕形失真(Pincushion Distortion)。此外由于相机组装过程中,透镜不能和成像面严格平行,会引入切向畸变(Tangential Distortion),再加上视觉文档图像的拍摄视角一般不垂直于文档平面,产生文档图像的变形和扭曲。例如比较厚重的书籍在展开后其书脊两侧文字区会出现向内弯曲的情况。由此可见,扭曲文档的形变情况要比平面文档要复杂,对其分析和矫正的难度也比平面文档图像要高。业界针对扭曲文档图像的矫正方法主要有:
- 基于柱面模型的方法。其核心思想是将文档视为柱面,先定位出所有的文本基线,再根据这些基线计算柱面模型弯曲函数,最后利用该模型对原文档图像进行矫正;
- 基于硬件的方法。该类方法通常使用特制的硬件设备扫描纸张的三维形状信息。比如采用结构光源来对文档进行扫描从而获取文档确实的深度信息,然后根据深度信息对文档图像进行矫正;
- 基于图像切分的方法。其核心思想是将扭曲文档图像切分成多个近似平面区域,分别对它们进行独立矫正,最后把所有矫正后的区域拼接起来恢复正视图。
然而这些方法都有各自的不足之处:基于柱面模型的方法在定位文本基线时会出现基线断开的情况,在扭曲比较严重的文本区域还可能会定位错误,另外,在复杂的版面或包含有图像的文档中,有效的文本基线较少,柱面模型的精度也因此而下降;基于硬件的方法虽然精度高,但因为受限于硬件成本,对于合合信息主营的民用商业化应用而言,不具有普适性——不能奢望用户有这种昂贵的设备; 基于图像切分的方法只适用于纯文本校正,对于有公式或图像的信息无法处理。
合合信息采用基于偏移场的学习方法大大改善了上述缺陷。偏移场是一种具有中间监督的堆叠U-Net网络,用于直接预测从扭曲图像到校正图像的正向映射。通过扭曲未失真的图像创建高质量的图像合成数据集,而数据驱动和学习的方法可以极大地涵盖各种真实世界条件,提高了模型泛化能力,达到商用级别。偏移场学习对网络进行端到端训练,因此没有使用手工制作的低级特征,所以在提供大规模训练数据的前提下,它可以处理各种文档类型——克服了前述不能处理公式和图像的问题;且可以作为一种有效的方法部署在现实世界中应用。
2 去摩尔纹
因为相机拍摄电子屏幕时,显示设备的发光点阵与相机传感器阵列发生混叠,产生了摩尔纹现象。屏幕图像摩尔纹表现为叠加在图像上的条纹,颜色和形态多变。图像中的摩尔纹在大范围的空域和频域内与原始图像信号混合,通常覆盖整张图像。摩尔纹图案不仅随着图像的不同而变化,而且在同一图像中随着空间位置的变化而呈现不同的色彩和形态。如果拍摄距离或拍摄角度略有变化,摩尔纹图案可能会有很大差异。另外,摩尔纹图案也与相机种类、屏幕种类和图像内容有关。摩尔纹的出现严重影响了成像的视觉质量,因此采用后处理技术去除图像摩尔纹有其必要性。如图所示为图像摩尔纹的实例,可以看出,摩尔纹可以呈条纹状、网格状或波纹状,纹理的走向和弧度都有差别,颜色也各异,因此去摩尔纹技术研究富有挑战性。
目前抑制摩尔纹的常见方法是在成像前进行预处理,例如,在相机镜头前放置抗混叠滤波器,对彩色滤波阵列(CFA)的输出应用精确插值算法。另外,在专业摄影领域,目前最有效的去摩尔纹方法是借助专业图像处理软件的后处理方法——Adobe Photoshop是最常用的软件之一。Photoshop简称“PS”,是由Adobe Systems公司开发及发行的图像处理软件,主要用于处理由像素构成的数字图像,有众多的编修和绘图工具,可以高效地进行图像的编辑工作。然而这些预处理方法对已获取摩尔纹图像,特别是屏幕图像的去摩尔纹算法的后矫正没有普适性的帮助——甚至需要用户掌握专业软件。

近年来,深度学习正在引领一场计算机视觉和图像处理领域的革命。例如:
- 解码器网络。该网络由多个卷积层和反卷积层构成,学习从降质的噪声图像到原始图像的端到端映射。卷积层作为特征提取器,提取图像的高层级特征同时去除噪声。反卷积层用来恢复图像细节。跳过连接对称的卷积层和反卷积层,可以加快训练的收敛速度,使模型收敛到更佳的局部最优值。跳过连接允许信号从高层直接反向传播到低层,解决了梯度消失的问题,使得训练深度网络更容易,让模型具有更优异的性能。此外,跳过连接将图像细节从卷积层直接传递到反卷积层,有助于恢复原始图像。该算法可用于图像复原任务如图像去噪和超分辨率等;
- 前馈卷积神经网络。该算法端到端的学习从噪声观测到干净图像的映射,利用残差学习和批归一化方法加速训练过程并提高去噪性能,可以实现未知噪声水平的高斯去噪;
- 超分辨率重建。采用卷积神经网络将低分辨率图像插值后的结果作为网络输入,学习由插值后的图像到高分辨率图像之间的映射关系,该映射在概念上由三个操作组成,首先提取相应的图像块并将其表示为高维向量,然后将此输入高维向量非线性地映射到高分辨率的高维向量上,最后根据学习到的映射关系生成高分辨率图像。
如图所示,合合信息的去摩尔纹技术已经相当成熟。

3 图像切边增强
图像切边增强是图像分割的子课题,也是图像处理和计算机视觉中的重要工作,近年来也是计算机视觉领域的研究热点之一,在目标检测、识别、分类等领域中得到广泛的应用。图像分割实质把人们关注的部分从图像中提取出来,进一步对图像有用信息进行分析和处理。目前根据分割原理分为:
-
基于边缘的分割算法,此类方法假设不同的区域之间的边缘上像素灰度值的变化往往比较剧烈,进而利用图像一阶导数的极大值或二阶导数的过零点信息来提供判断边缘点的基本依据,进一步还可以采用各种曲线拟合技术获得划分不同区域边界的连续曲线;
-
基于阈值的分割算法,阈值分割是常见的直接对图像进行分割的算法,根据图像像素的灰度值的不同而定。其基本原理是通过设定不同的特征阀值,把图像像素点分为具有不同灰度级的目标区域和背景区域的若干类对应单一目标图像;
-
基于区域的分割方法。以直接寻找区域为基础的分割技术,具体算法有区域生长和区域分离与合并算法%。区域生长是从某个或者某些像素点出发,最后得到整个区域,进而实现目标的提取。而分裂合并可以说是区域生长的逆过程。它是从整个图像出发,不断分裂得到各个子区域,然后再把前景区域合并,得到前景目标,继而实现目标的提取。基于区域的分割算法对于较均匀的连通目标有较好的分割效果。但需要人为的选取种子,且对噪声较敏感,可能会导致区域内有空洞;
-
基于聚类的分割算法。把像素点样本集划分为独立的区域,同一区域内的像素相似度高,不同区域之间相似度小。早期的K-means算法通过初始化一定数量聚类中心后,通过计算各个像素点到聚类中心距离来度量相似度,相似度高的像素点完成迭代聚类;模糊聚类算法则通过在计算距离时应用隶属度函数,能更加准确的实现聚类,但是计算复杂度也高。

4 PS检测
随着 Photoshop 的不断发展,技术水平的不断提高,应用 PS 可以对图像进行各种操作,例如美化、分割、抠图等,并且操作后的图像不会显得很突兀。然而,在高速发展的数字信息时代,信息安全是我们不容忽视的问题,若利用 PS 对图片进行恶意的复制、修改、删除或添加等,会导致非常严重的后果。高质量的 PS 图像很难用肉眼识别出来,采用一种合适的方法对更改图像进行识别是非常必要的。基于图像特征检测与匹配的方法是PS检测领域的常用技术。
最传统和经典的特征点检测方法是尺度不变特征转换(Scale-Invariant Feature Transform, SIFT),SIFT的核心原理是:基于拉普拉斯金字塔,在不同尺度空间中查找和定位鲁棒性关键点;基于HOG实现旋转不变性并生成特征描述子。主要的步骤如下:
- 尺度空间关键点检测与定位
为使特征描述具有尺度不变性,SIFT在尺度空间上寻找关键特征点。考虑到图像特征往往具有高频特性,使用拉普拉斯金字塔构造图像尺度空间。拉普拉斯金字塔已由各尺度图像局部极值点构成,SIFT更进一步检测金字塔局部极值点作为粗关键点。考虑到上述粗关键点的求取在拉普拉斯尺度空间内进行,该空间在突出特征响应的同时也具有很强的边缘响应,而一旦特征点落在图像边缘上就会带来不稳定性。这是因为:① 图像边缘上很难定位到某个具体像素点,具有歧义性;② 边缘点容易受噪声干扰。因此还需要消除上述修正点的边缘响应。SIFT中借鉴了Harris角点检测的思路消除边缘响应。设每个检测点的Hessian矩阵为
H = [ f x x f x y f y x f y y ] H=\left[ \begin{matrix} f_{xx}& f_{xy}\\ f_{yx}& f_{yy}\\\end{matrix} \right] H=[fxxfyxfxyfyy]
二阶偏导项通过有限差分法取得。要排除边缘点,只需使式的响应值尽可能大——趋近角点而非边缘,在SIFT中即为
t r ( H ) 2 det ( H ) < ( γ + 1 ) 2 γ \frac{\mathrm{tr}\left( \boldsymbol{H} \right) ^2}{\det \left( \boldsymbol{H} \right)}<\frac{\left( \gamma +1 \right) ^2}{\gamma} det(H)tr(H)2<γ(γ+1)2
至此,就得到了图像全部的尺度不变性特征点。
- 特征点特征方向分配
SIFT为各特征点分配特征方向 θ \theta θ,这样在不同的图片中,同一个特征会被扭转到相同的基准角进行比较,实现特征描述的旋转不变性,如图所示。下面阐述具体步骤。首先以特征点 X = ( x , y , σ ) T X=\left( x,y,\sigma \right) ^T X=(x,y,σ)T为中心,选取半径 的区域,计算各像素梯度。以特征点为中心,用 的高斯核对区域进行加权,以综合各像素对特征点梯度的贡献(越远的像素点贡献越小)。

加权完毕后,构造一个0~360°范围,每10°一个直方柱的HOG,统计上述区域的梯度信息。具体而言,区域内梯度方向为0~9°的像素,其梯度幅值的加权值相加构成HOG第一直方柱的高,其余同理。HOG统计完毕后,其主峰代表的梯度角度范围包含了特征点的特征主方向 θ m a i n \theta _{main} θmain,通过二次曲线插值拟合公式,从第 i i i个直方柱的角度范围估计精确的 θ m a i n \theta _{main} θmain。每个特征点除了必须分配一个主方向外,还可能有一个或多个特征辅方向 θ e l s e \theta _{else} θelse,其定义为:当存在另一直方柱高度大于主峰高度80%时,该旁峰所代表的的方向角即为辅方向。增加辅方向的目的是为了增强图像匹配的鲁棒性,将主方向、辅方向合成为特征点的特征方向 θ = [ θ m a i n , θ e l s e ] T \theta =\left[ \theta _{main},\theta _{else} \right] ^T θ=[θmain,θelse]T。至此,特征点的表述形式增强为 X = [ x y σ θ ] T \boldsymbol{X}=\left[ \begin{matrix} x& y& \sigma& \boldsymbol{\theta }\\\end{matrix} \right] ^T X=[xyσθ]T,同时具有尺度不变性和旋转不变性
- 生成SIFT特征描述子
对特征点 X = [ x y σ θ ] T \boldsymbol{X}=\left[ \begin{matrix} x& y& \sigma& \boldsymbol{\theta }\\\end{matrix} \right] ^T X=[xyσθ]T,以 ( x , y ) \left( x,y \right) (x,y)为中心,将其邻域划分 d × d d\times d d×d个Cell。每个Cell边长为 3 σ 3\sigma 3σ。为保证特征点的旋转不变性,需要将上面的邻域旋转 进行特征方向对齐,旋转半径为邻域对角线长度的一半,旋转后特征点邻域的实际大小为 ( 2 r + 1 ) × ( 2 r + 1 ) \left( 2r+1 \right) \times \left( 2r+1 \right) (2r+1)×(2r+1),旋转完毕后,将该邻域重采样为6×16像素的数字窗口。计算数字窗口内各像素梯度。为防止窗口边界或某个像素梯度方向因噪声干扰产生突变,SIFT以特征点为中心,对梯度幅值进行高斯滤波。必须指出,HOG算法中并没有数字窗口,所以无需滤波操作。
虽然SIFT、SURF等特征描述算法的性能优越,但其特征描述占用的内存和特征匹配所耗费的时间不能忽视。 举例而言,一个128维(Float类型)SIFT描述子需要512B内存,而对于同样一个128维二进制描述子,仅需16B内存,且两个二进制串通过汉明距离可以快速进行特征匹配。因此二进制特征检测匹配算法具有重要意义,简单介绍其中的BREIF算法。
主要算法步骤如下:
- 通过FAST、SIFT等方式检测和定位图像特征点;
- 以某个特征点 为中心,取一个 大小的Patch并对其高斯滤波(9×9高斯核)降噪;
- 在Patch内以高斯分布随机选取 N N N个像素点对,即离特征点越近的像素点,对特征描述的贡献越大;
- 采用如下特征描述映射对 N N N个像素点对进行二进制编码,生成描述子
T ( M ; X , Y ) = { 1 , f ( X ) < f ( Y ) 0 , e l s e T\left( M;X,Y \right) =\begin{cases} 1, f\left( X \right)
其中 f ( ⋅ ) f\left( \cdot \right) f(⋅)是像素强度。
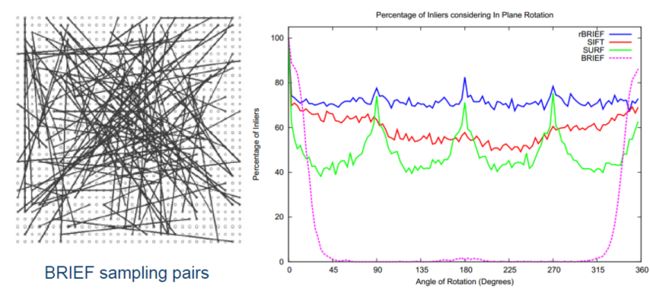
BRIEF算法形成的描述对旋转操作非常敏感,当目标图像旋转角度增大时,BRIEF描述子的匹配结果极大降低,如图所示(纵轴为匹配性能,横轴为旋转角度)。
5 总结
介绍了这么多黑科技之后,想必大家对智能文字处理领域有了一定了解。合合信息的智能文字识别应用开发宗旨就是为了让世界更高效!合合信息深耕人工智能16年,全球累计用户下载量23亿,享有国内外发明专利113项,在顶级AI竞赛获得15项世界冠军,提供行业智能解决方案30个。合合信息提供了深受全球用户喜爱的效率工具,例如C端的名片全能王、扫描全能王、启信宝等。相信合合信息在模式识别、深度学习、图像处理、自然语言处理等领域的深耕厚积薄发,用技术方案惠及更多的人。