EM(Expectation Maximization Algorithm)算法详解(附代码)-----大道至简之机器学习系列---通俗理解EM算法。
☕️ 本文来自专栏:大道至简之机器学习系列专栏
本专栏往期文章:逻辑回归(Logistic Regression)详解(附代码)---大道至简之机器学习算法系列——非常通俗易懂!_尚拙谨言的博客-CSDN博客_逻辑回归代码
❤️各位小伙伴们关注我的大道至简之机器学习系列专栏,一起学习各大机器学习算法
❤️还有更多精彩文章(NLP、热词挖掘、经验分享、技术实战等),持续更新中……欢迎关注我,主页:https://blog.csdn.net/qq_36583400,记得点赞+收藏哦!
个人GitHub地址:fujingnan (fujingnan) · GitHub
目录
总结
一、基础的基础
1. 数学期望(以下简称“期望”)
2. 最大似然估计
3. Jensen不等式
二、EM算法推导
1. 从特殊到一般
2. EM算法的推导
3. EM算法总结
三、EM算法在高斯混合模型中的应用(重要)
四、Python代码实现
五、总结

看到上面的表情了吗?没错,我的心情……为啥呢?因为我今天要讲一讲这个曾经耗费我将近两个月的时间去理解的EM(Emoji Melancholy)算法。先说在前面,该算法确实有点晦涩难懂,小伙伴们如果一时半会儿理解不了没关系,千万不要EM起来,我看网上太多大佬对解释这个算法都显得似乎轻而易举,很是佩服,小弟并不知道他们是如何做到理解的如此轻松的,大佬的世界咱不懂哎~
我尝试着并非抛几个公式,照着书上解释一通来写这篇博客,尽量用自己的理解来写,如果存在有误之处,还请大佬们提出指正,不胜感激!
通俗讲,EM算法它是实现是一种基础数学方法,它叫期望最大化算法,目的是能够求解带有隐含变量的最大似然值的问题。就好比我们要解决连续凸函数的最大值问题,那么我们就要学会微积分。因此,与其说EM算法是一种机器学习算法,不如说它是一种能够应用在一些机器学习算法求解问题上的一种基础数学工具。对于EM算法,本章想重点介绍一下它在高斯混合模型学习中的应用。但在这之前,我想先和大家过一遍EM算法的基础。
总结
文档撰写习惯,先抛出总结:
- EM算法的具体步骤:
(1)给参数θ即第0步赋初值
;
(2)E步:如果是第一轮迭代,那么令θ=
也就是给定θ和已知的观测数据x的条件下,求一下隐变量z的条件概率。
(3)M步: 根据E步计算出来的Q,按如下公式计算θ:
也就是固定Q(z也固定)和已知的观测数据x,算一下θ。
(4)重复(3)和(4)直至收敛。
- 高斯混合模型的EM算法步骤:
假设随机变量X是由K个高斯分布混合而成,各个高斯分布的概率为
,第i个高斯分布的均值为
,方差为
。我们观测到随机变量X的一系列样本值为
,计算如下:
第一步:给φ,μ,σ赋初值,开启迭代,高斯混合模型的φ,μ,σ有多个,就分别赋初值;
第二步:E步。如果是首轮迭代,那么φ,μ,σ分别为我们给定的初值;否则φ,μ,σ取决于上一轮迭代的值。有了φ,μ,σ的值,我们按照如下公式计算Q函数:
其中,φ,σ,μ,x均已知,代入即可,i=1,2,...,N;k=1,2,...,K
第三步:M步。根据计算出来的Q,套进以下公式算出高斯混合模型的各个参数:
重复2~3步,直至收敛。
好了,正文开始……
一、基础的基础
既然说EM算法是基础,那么它必然也有基础,这一节先介绍几个学习EM算法需要知道的基础。我们先从算法的名字入手:期望最大值算法。
1. 数学期望(以下简称“期望”)
百度百科上说:“数学期望(mathematic expectation)(或均值,亦简称期望)是试验中每次可能结果的概率乘以其结果的总和。”
瞅瞅上面这句话,什么试验?其实就是我们日常生活中发生的一些同类事件,比如买彩票事件、抛硬币事件等;所以百科上这句鸟话啥意思?事情还得从盘古开天辟地时的一场赌局说起,事情是这样的:
甲乙两个人赌博,他们两人获胜的机率相等,比赛规则是先胜三局者为赢家,一共进行五局,赢家可以获得100法郎的奖励。当比赛进行到第四局的时候,甲胜了两局,乙胜了一局,这时由于某些原因中止了比赛,那么如何分配这100法郎才比较公平?
我们简单算一下:因为甲输掉后两局的可能性只有(1/2)×(1/2)=1/4,也就是说甲赢得后两局或后两局中任意赢一局的概率为1-(1/4)=3/4,甲有75%的期望获得100法郎;而乙期望赢得100法郎就得在后两局均击败甲,乙连续赢得后两局的概率为(1/2)*(1/2)=1/4,即乙有25%的期望获得100法郎奖金。
可见,虽然不能再进行比赛,但依据上述可能性推断,甲乙双方最终胜利的客观期望分别为75%和25%,因此甲应分得奖金的100*75%=75(法郎),乙应分得奖金的的100×25%=25(法郎)。这个故事里出现了“期望”这个词,数学期望由此而来。
从上面的例子可以十分通俗的这么理解:数学期望就是一个事件可能获得的所有结果被其获得相应结果的可能性(概率)“降价(加权)”后,求得的和,作为该事件的整体期望结果,也就是用一个数来表示一件事获得可能结果是啥。
这里需要注意的是,每件事获得的结果都必须赋予实际的意义,且需要数字化表示,否则期望是无法计算的。又因为每个人赋予的实际意义和数字化表示都不相同,所以如果没有规定统一,则每个人计算出来的期望都有可能不同,例如上述的100法郎的奖励,你也可以规定是200法郎,那么计算的结果就会不一样,但这并不影响数学期望所表示的数学意义。
假设一个随机事件X ,对于离散型数值的数学期望为:
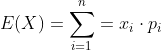
,p为概率值。
对于连续型数值的数学期望为:
![]()
,f(x)为概率密度函数。
关于数学期望还有呢太多细节,不是本文介绍重点,大家可自行查阅。这里只做一个宏观解释。
2. 最大似然估计
“期望最大值”的第二部分就是那个“最大”,“最大”蕴含着“最大似然估计”方法,只不过在EM算法里,最大似然估计是含有隐变量的最大似然估计,这个在后面说,这里先说说什么是最大似然估计。
通常的,当我们对某个事件做多次的一系列试验后,在大数定律下(对某事件做了无数多次试验发生的规律),我们统计出现各种试验结果的概率,那么会发现,这一事件的试验会大概率稳定在某种形式的结果。比如抛硬币,抛了无数多次后统计,会发现正面向上的概率和反面向上的概率基本都是0.5。而我们通常的试验,都会有一定的未知参数,那么最大似然参数估计就是要估计出能使这种出现最大概率结果的参数值,比如抛硬币的力度,试验者的年龄等。已知某个参数能使这个样本出现的概率最大,我们当然不会再去选择其他小概率的样本,所以干脆就把这个参数作为估计的真实值。那么这个需要估计的未知参数该如何理解呢?
举个例子:
已知一批往年下雨的数据样本,是杏下雨是由某些气象指标控制,如参数θ表示空气的湿度,L(x; θ) 就表示在湿度参数θ下下雨的可能性,参数θ可以取值
,每个参数
会得到对应的似然函数值, 如果某个
最大似然估计分为离散型随机变量和连续型随机变量两种。离散型随机变量是一系列独立同分布的随机事件在某个或某些未知参数θ的参与下,其得到最大概率值下,对参数θ的估计;连续型随机变量是指一系列具有连续特征的随机变量在某个或某些未知参数θ的参与下,其得到最大概率密度值下,对参数θ的估计。
通常,由于计算最大概率值时,需要用到概率连乘,这将在计算上带来很大的麻烦,因此,我们在求解最大似然值时,往往采用对数方法进行,即对连乘式取ln或者log,将连乘转换成连加形式,再求其偏导。举个例子:
我们要判断一句话出现的概率(即给定一些字词,判断这些字词能够组合成一句通顺的话的概率):例如“i am a chinese”,我们先对这句话分词[i,am,a,chinese],现在要判断“i am a chinese”这句话出现的概率,那么就得做如下计算:
![]()
我们知道,上式每个P都是一个0-1之间的数,连乘后将会趋近于0,但是如果我们取对数,那么上式的连乘将会变成连加的形式,不管是计算上还是结果,都更加亲民。
总结求解极大似然估计问题步骤:
- 写出似然函数;
- 对似然函数取对数,并整理;
- 求导数,令导数为0,得到似然方程;
- 解似然方程,得到的参数即为所求;
3. Jensen不等式
Jensen不等式是推导EM算法用到的一个强有力的工具,它很重要,但是我不打算深入讲解它(主要是这么短的篇幅我也说不明白,hhh…),因为它是纯数学问题,和我们的算法其实是“被应用”的关系,所以我们只需要记住相应结论就好。如果数学相关的小伙伴实在想弄懂它,可能需要查阅厚书。
Jensen不等式是这么说的:
如果f是凸函数,X是随机变量,那么:E[f(X)]>=f(E[X]),通俗的说法是函数的期望大于等于期望的函数。
特别地,如果f是严格凸函数,当且仅当P(X = EX) = 1,即X是常量时,上式取等号,即E[f(X)] = f(EX)
如图:
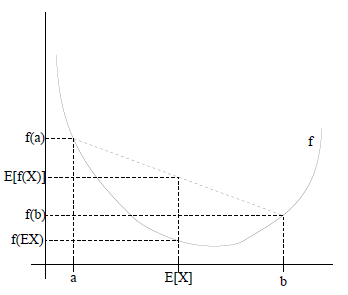
图中,实线f是凸函数(因为函数上方的区域是一个凸集),X是随机变量,有0.5的概率是a,有0.5的概率是b(就像抛硬币一样)。X的期望值就是a和b的中值了,可以很明显从看出, E[f(X)]>=f(E[X])。
当f是(严格)凹函数当且仅当-f是(严格)凸函数,不等号方向反向,也就是E[f(X)]<=f(E[X])
二、EM算法推导
1. 从特殊到一般
我们先举个简单情况的例子:已知某幼儿园有一群小朋友,男生和女生的身高都服从正态分布,男生正态分布参数为
,女生正态分布参数为
,我们随机从这些小朋友中抽取100位男生和100位女生进行身高测量。请求出男女生的正态分布式。
要解出男女生身高正态分布式,就是要求出 ,
, ,
,![]() ,
,![]() ,我们既已知男女生身高的分布,又已知这200名小朋友的身高,所以,根据极大似然值的求解方法,我们很容易能够求出它们的正态分布式。只需要将每位小朋友的身高带入对应的正态分布公式中,取对数,分别对,,
,我们既已知男女生身高的分布,又已知这200名小朋友的身高,所以,根据极大似然值的求解方法,我们很容易能够求出它们的正态分布式。只需要将每位小朋友的身高带入对应的正态分布公式中,取对数,分别对,,![]() ,
,![]() 求偏导,令偏导为0,即可求出4个参数,最后再把4个参数带回到正态分布公式中,就可以得出它们的正态分布式。这个正态分布式有啥用呢?当我们得到了男女生两个正态分布式后,我们再随机从幼儿园中盲抽一位小朋友,假设我们不知道ta的性别,我们可以通过测量其身高,并把身高值分别带进2个公式,算出谁的值大,那么这位小朋友大概率就是对应正态分布式的性别了。这就是最大似然估计。
求偏导,令偏导为0,即可求出4个参数,最后再把4个参数带回到正态分布公式中,就可以得出它们的正态分布式。这个正态分布式有啥用呢?当我们得到了男女生两个正态分布式后,我们再随机从幼儿园中盲抽一位小朋友,假设我们不知道ta的性别,我们可以通过测量其身高,并把身高值分别带进2个公式,算出谁的值大,那么这位小朋友大概率就是对应正态分布式的性别了。这就是最大似然估计。
现在将上面的情况反过来一下,我们打一开始就不知道这200位小朋友的性别,可是我又想求解它们的正态分布的参数值,而且也想再抽一位同学的身高,通过其正态分布式估计其性别,咋整?没招。没招我不管,这个需求很简单,能不能做我不管。好吧,那我告诉你能做!怎么做?woc,这就是EM算法的用武之地!
我们捋一捋,现在是有一个2个已知和3个未知:
已知:小朋友们的身高服从正态分布;200名小朋友的测量身高
未知:
,
以及性别z
我们将200名的测量身高称为观测值,性别z称为隐变量。 ,,![]() ,
,![]() 称为需要估计的未知参数。好了,接下来该怎么做呢?我们可以先给各个未知参数赋初值,再根据《统计学习方法 第二版》P165 的算法9.2来计算(算法怎么来的,下面会介绍),注意书里用的是高斯分布,咱们这儿只需要把P162式9.25中的φ替换成正态分布式即可。本质上,EM也是用到迭代法的思想。再通俗一点举例,假如给你两个没有刻度的试管,要从试剂瓶中给这两个试管平均分配药剂,正常人的做法就是先大概给每个试管倒入试剂,然后你会水平对比每个试管的液面差,多的再匀一匀给少的,来回倒腾,直到最后两根试管的试剂液面基本处于同一水平面。
称为需要估计的未知参数。好了,接下来该怎么做呢?我们可以先给各个未知参数赋初值,再根据《统计学习方法 第二版》P165 的算法9.2来计算(算法怎么来的,下面会介绍),注意书里用的是高斯分布,咱们这儿只需要把P162式9.25中的φ替换成正态分布式即可。本质上,EM也是用到迭代法的思想。再通俗一点举例,假如给你两个没有刻度的试管,要从试剂瓶中给这两个试管平均分配药剂,正常人的做法就是先大概给每个试管倒入试剂,然后你会水平对比每个试管的液面差,多的再匀一匀给少的,来回倒腾,直到最后两根试管的试剂液面基本处于同一水平面。
2. EM算法的推导
我们一步一步来,从第一章第二节的例子中我们可以知道,从分布为p(x|θ)的总体样本中抽取到N个样本的概率,也就是样本集X中各个样本的联合概率,例如 [am, i, chinese, a] 这几个单词要组合成“i am a chinese”的概率,我们就需要用如下公式:
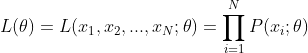
我们取个对数:
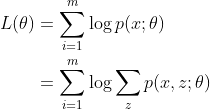
好家伙,出现了隐变量z,而且一个求和变成了两个求和,咋来的?注意看第二个求和符号的下标为z,也就是第二个求和符号是对z的边缘概率求和,得到的结果和没有z的一个求和符号的形式是一样的。你可以想象z是从一个整体分出来的一部分东西,我们再把分出来的东西求个和,就又变回一个整体。
上式是似然函数,我们的目的就是求得各个未知参数使该似然函数值达到最大。理论上,我们只需要针对上式的各个参数求偏导,再令偏导为0即可。可是上式中不仅存在隐变量,还存在对数的和的形式,这样求导起来就麻烦了。天才数学家,它们把上式做了个变换,变成如下形式(为了方便,下文统称下式为公式1):
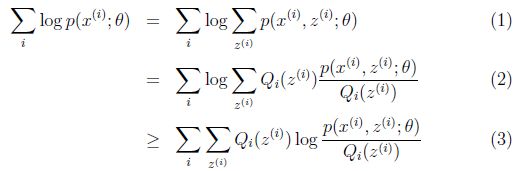
首先,天才们利用小学数学的技巧,分子分母同乘以一个数,原式保持不变,不一样的是,这里同乘的这个数不是瞎比乘的,它是关于隐变量z的概率分布函数,其条件是
![]() ,得到(2)式后,接着就可以去掉烦人的和的对数了。注意看(3)式,有个大于等于号,好嘛,这其实就用到了我们上面讲到的Jensen不等式的思想了。至于说人家咋想到的,我个人感觉这是数学天才特有的敏感度,或者经过好多人不断的尝试实验发现的,总之这种巨大跳跃的思维常人难以想象。
,得到(2)式后,接着就可以去掉烦人的和的对数了。注意看(3)式,有个大于等于号,好嘛,这其实就用到了我们上面讲到的Jensen不等式的思想了。至于说人家咋想到的,我个人感觉这是数学天才特有的敏感度,或者经过好多人不断的尝试实验发现的,总之这种巨大跳跃的思维常人难以想象。
抛开第一个求和符号,我们和Jensen不等式对比着用文字来解释一下:在满足Jensen不等式的条件下,函数的期望大于等于期望的函数,log的期望大于等于期望的log,解释的够俗了吧……
那么为啥式子里有期望存在呢?注意看(2)式中,倘若我们把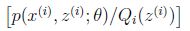
看成一个整体g(x),而Q又是关于z的分布律,那么由数学期望的定义就有
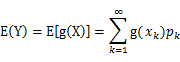
回顾一下简单形式的数学期望:E(X)=∑x·p(x),而g(x)又是X的函数,所以我们把简单形式的期望公式中的X替换成g(x),就得到了E(g(x))的数学期望了。事实上,上式属于复合函数型的数学期望。有了(2)式后,根据Jensen不等式,就有:
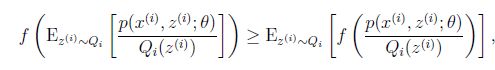
一边看着上式,一边跟我读一遍: 函数的期望大于等于期望的函数,log的期望大于等于期望的log。现在明白了吧。
现在让我们回到公式1,我们的初衷是求得(2)式的最大似然值,而我们最终把它变换成了(3)式,且等号变成大于等于号,就是说(2)的最大值并非一定是(3)的最大值了,咋办?我们把公式1简单写成L(θ)>=J(z, Q(z)),因此,不管J的值在z和Q的不同取值下如何变化,始终都会有L(θ)大于等于J,所以我们不用管这个不等号了,我们只需要让J不断增值就好,反正L这个帽子一直扣在J头上,J长高高,L肯定是跟着长呗,但始终是在J的头顶,而且肯定有个上限。所以我们根据这个歪道邪理,得到调整J,使得L最大化的思路了,需要注意的是,由于J包含着俩变量Q和θ,所以应该采用固定变量法来调整:
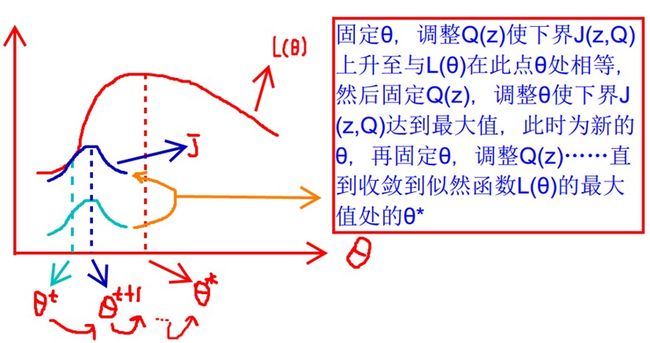
(1)先固定θ,调整Q,使上图中青绿色的那条线上升到深蓝色的线的位置,即J上升至与L的曲线相切处,此时,J和L在θ处相遇;
(2)再固定Q,调整θ,使青绿色虚线右移至深蓝色虚线处,即J到达最大值。此时,由于θ更新了,所以EM算法会在新的θ处重新计算Q函数,那么曲线就会有所变化;
(3)根据新的Q曲线,重复上述两个步骤,直到收敛至L(θ)的最大值处的θ*,也就是找到了使得似然函数值最大的那个参数θ。
其实至此,我们已经对EM算法有了比较通俗的理解了,但还不够全面,我们再来看下公式1,当我们固定θ调整Q的时候,总得有个标准来判断J和L是否在某个点相等吧,也就是公式1中等号成立的条件是啥?另外,像上面所说的那样调整来调整去的,真的一定能找到最大值哪怕仅仅是局部最大吗?凭什么说人家一定收敛?
来来来,我们先看下不等号成立的条件,在Jensen不等式中,我们说过了,当变量X是常数的时候,等式成立。也就是说,要让等号成立,则有:
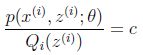
这么写没毛病吧?要注意前面我们说过的,上式为g(x),要使变量X为常量,即g(x)是常量,这里的![]() 就是随机变量X。好,我们继续。上述再变化一下:
就是随机变量X。好,我们继续。上述再变化一下:
![]()
而且我们知道,![]() ,所以对于上式就有:
,所以对于上式就有:
![]()
我们把上式代回到
得到:
咦?谁能告诉我公式里的编号为啥不在右边嘞? 不管了,从(1)到(2)是因为我们对z的边缘概率求和了,所以求和符号就没了,这个我们在上面讲过,就是整体与部分的关系,(1)式其实就是z取得各种情况的概率之和。从(2)到(3)是由条件概率计算公式来的,也就是P(A|B)=P(A, B)/P(B)。这里需要注意的是,一会儿分号一会儿“|”的啥意思?其实这是写法造成的,因为公式中存在多个参数,需要确定优先级,也就是上式(3)中,竖线代表一个条件概率,分号后的参数代表在这个条件概率中,θ参与其中了。
好了,我们现在不知不觉把EM算法中的E步给推导出来了,就是确定Q函数,上述公式中,表明了Q函数的计算方法,这给我们选择Q函数提供了依据。确定了Q函数,我们就可以建立L(θ)的下界,即可固定θ来调整Q,使J(θ)增大。
有了E步后,我么还需要计算M步。M步就很好理解了,当我们求出Q后,我们需要把Q代回到公式1中的(3),即得到关于θ的最大似然函数式:
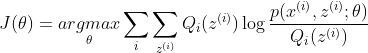
根据该似然函数,我们又可以求得使的似然函数值最大的新的θ,再用新的θ求新的Q,然后再用新的Q求新的θ……周而复始,循环重复,直到收敛为止。那么就有了上面提到的第二个问题:收敛性。
算法真的能收敛吗?如果能,啥时候算收敛?说实话,我是很不想证明这一块,一堆数学公式,让人头疼,但是这又是了解EM算法的一部分,所以如果大伙不愿意看,略过吧,记住结论就行,就是一定会收敛!这里先再把公式1抛出来:
公式1中我们提到,根据Jensen不等式,我们需要最大化(3),逼大L(θ)的下界,使L(θ)增大,现在我们用迭代法做这件事后,肯定就会出现![]() 和
和![]() 这一过程,前者是上一轮迭代算出来θ,后者是当前要算的θ,我们把这俩θ代入公式1中,可以得到:
这一过程,前者是上一轮迭代算出来θ,后者是当前要算的θ,我们把这俩θ代入公式1中,可以得到:
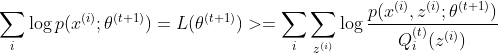
这里Q的上标是t的原因是这里我们是在调整θ,固定Q,所以Q仍然保持上一轮的状态。而我们知道, t+1轮的θ是t轮结果的最大化后生成的新的θ,即t轮是t+1轮的下界,所以上式又有:
总的,就有:
![]()
我们知道,如果对于任意第t次迭代后的值,都有f(t)>=f(t-1),那么经过无数次迭代后,一定能找到使f最大化的θ,对于上式,我们换句话说,就是当任意第t+1次用到的参数θ得到的似然函数L的值,都比其前一次迭代用到的θ所得到的L的值要大,因此,证明了EM算法的收敛性。我们判断收敛的方式可以是观察L的值随着继续迭代不再增加,或者也可以设置一个阈值,判断两次迭代后θ或L的值差是否小于该阈值,如果小于,那么说明θ或L基本稳定在一定区间,可以停止迭代,同理也可以判断Q函数。
上述证明与说法不够严谨,但是秉持着通俗理解的原则,以此足矣,望见谅。
3. EM算法总结
通过上面的分析,我们终于可以总结一下EM算法啦!总的来说,EM算法分为E步和M步:
(1)给参数θ即第0步赋初值![]() ;
;
(2)E步:如果是第一轮迭代,那么令θ=![]() 来计算Q函数;如果是>1轮迭代,则θ的值由上一次M步计算出的θ值决定。由于E步时θ已知,所以只需要计算Q,公式如下:
来计算Q函数;如果是>1轮迭代,则θ的值由上一次M步计算出的θ值决定。由于E步时θ已知,所以只需要计算Q,公式如下:
![]()
也就是给定θ和已知的观测数据x的条件下,求一下隐变量z的条件概率。
(3)M步: 根据E步计算出来的Q,按如下公式计算θ:
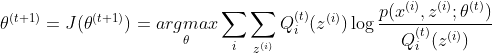
也就是固定Q(z也固定)和已知的观测数据x,算一下θ。
(4)重复(3)和(4)直至收敛。
公式看起来很复杂,但是面对具体问题时,该有的数据我们都有,所以只需要把具体的数套进对应的公式里就行,千万别晕,特别是接下来要介绍的EM算法在高斯混合模型中的应用,附上代码后,大家就知道有多简单了。其实最难的就是我们上面分析的关于EM算法的思想和推导。
三、EM算法在高斯混合模型中的应用(重要)
EM算法其实是一种数学工具,它的主要能力是求解隐含有未知隐变量的一系列似然估计问题。让我们回到第二章第一节的幼儿园小朋友身高的例子。我们再具体描述一下问题:假设从幼儿园中随机抽取200位小朋友测量其身高,现在已知每位小朋友的身高,以及男孩身高服从,女孩身高服从,但现在男女的身高数据混在一起了,我们不清楚每个数据究竟属于男孩身高还是女孩身高,在这种情况下,我们仍然需要估计 ,,![]() ,
,![]() ,很明显,性别是个隐变量。这种由若干个高斯分布混合而成的模型就是高斯混合模型,求解这类问题,就可以用到EM算法。
,很明显,性别是个隐变量。这种由若干个高斯分布混合而成的模型就是高斯混合模型,求解这类问题,就可以用到EM算法。
现在我们抽象一下上述问题,表述如下:
随机变量X是由K个高斯分布混合而成,且各个高斯分布的概率为
,第i个高斯分布的均值为
这里的![]() 就是200位小朋友的身高值。好了,我们参照上文推导的EM算法的思路来推导一下高斯混合模型。
就是200位小朋友的身高值。好了,我们参照上文推导的EM算法的思路来推导一下高斯混合模型。
这里为了区分变量名,我们将π用φ替换。
第一步:给φ,μ,σ赋初值,开启迭代;
第二步:E步。如果是首轮迭代,那么φ,μ,σ分别为我们给定的初值;否则φ,μ,σ取决于上一轮迭代的值。有了φ,μ,σ的值,我们计算Q函数:
i=1,2,...,N;k=1,2,...,K
千万别看复杂了,其实就是一个概率乘以一个高斯分布式,再除以一个k取各个分模型的概率之和。i表示第i个样本,k表示第k个分模型。
第三步:M步。根据似然函数公式:
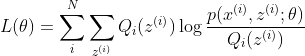
我们套用高斯分布的各个参数,得到:
别慌,我来解释一下,(1)很好理解,就是我们前面推导出的似然函数的表达式,只不过前面我们参数用θ表示,这里θ就是高斯分布式的参数;(2)式中,log后的分子其实就是(1)式中分子根据条件概率计算公式变换而来,这个我们在上文中也讲过,这里之所以把μ和σ分配给前一个p,是因为前一个概率p中我们计算的是在z=k条件下x的概率值,而x是服从高斯分布的,所以它仅和μ与σ有关,而后一个p的意义是,在参数φ的参与下,z取得第k个分模型的概率,实际上就是概率φk,对吧,因为φk的定义就是z取得第k个分模型的概率;(3)式中,唯一比较不同的是φk前面的那一串公式,它其实就是高斯分布式,不要想太多,只不过它是属于多元高斯分布式,我们平时写的都是一元的,这里是多元的,这个可以参考多元高斯分布(The Multivariate normal distribution) - bingjianing - 博客园。
好了,我们根据上面的式子,分别对φ,μ,σ求偏导,并令偏导为0,复杂的求导过程我这里就不啰嗦了,复杂而难用的公式编辑,冗长的篇幅,还容易写错,大家感兴趣自己下去照着书推导一遍就好,除了φ的求解需要用到拉格朗日算子,其它的就是常规求导。这样可以得出每个参数的求解形式:
注意Nk和N是不一样的,N是总体样本量,而Nk是每个样本属于各个分模型的概率之和,比如样本x1属于性别男(k=男)的概率是0.98,x2属于性别男的概率是0.84,x3属于性别男的概率是0.91,那么Nk就是0.98+0.84+0.91,同理,还要算一下x1,x2,x3属于性别女(k=女)的概率。
EM算法对初值的选取是敏感的,初值选的好,可能没几下就收敛了,所以初值的选择很重要哦,但是又没有普适的方法,只能靠经验和人品……
四、Python代码实现
待补充……
五、总结
OMG!终于写完了,写EM算法真的是折寿。所以希望大家如果得到帮助,多多支持我,有问题的及时指出,觉得好好的求点赞关注+收藏!真的很不容易,写了好久……
总结一下吧:
1. EM算法解决什么问题?
带有隐变量的极大似然参数估计问题。
2. EM算法的通俗解释是啥?
对带有隐变量的极大似然估计问题,拆解成E步和M步进行计算,E步是在最开始人为给个初值,后续迭代使用更新值,计算关于隐变量的期望值,称为Q函数,其余参数固定不变。M步是利用E步算出来的Q,代入似然函数求解使得似然函数取得最大值的其余参数。E步和M步循环迭代,直到收敛为止。
3. EM算法的具体步骤?
(1)给参数θ即第0步赋初值![]() ;
;
(2)E步:如果是第一轮迭代,那么令θ=![]() 来计算Q函数;如果是>1轮迭代,则θ的值由上一次M步计算出的θ值决定。由于E步时θ已知,所以只需要计算Q,公式如下:
来计算Q函数;如果是>1轮迭代,则θ的值由上一次M步计算出的θ值决定。由于E步时θ已知,所以只需要计算Q,公式如下:
![]()
也就是给定θ和已知的观测数据x的条件下,求一下隐变量z的条件概率。
(3)M步: 根据E步计算出来的Q,按如下公式计算θ:
也就是固定Q(z也固定)和已知的观测数据x,算一下θ。
(4)重复(3)和(4)直至收敛。
4. 高斯混合模型(GMM)是啥?
随机变量X(一堆样本)由若干个不同的高斯分布组合而成,也就是在某个样本集中,组成该样本集的每个样本服从不同的高斯分布,那么由这样一个随机变量X决定的分布模型,称为混合高斯分布模型。求解这样的模型参数估计,可以用EM算法,其中,样本属于哪个分模型的未知事件,为高斯混合模型的隐变量。
5. 高斯混合模型的EM算法步骤?
假设随机变量X是由K个高斯分布混合而成,各个高斯分布的概率为![]() ,第i个高斯分布的均值为
,第i个高斯分布的均值为![]() ,方差为
,方差为![]() 。我们观测到随机变量X的一系列样本值为
。我们观测到随机变量X的一系列样本值为![]() ,计算如下:
,计算如下:
第一步:给φ,μ,σ赋初值,开启迭代,高斯混合模型的φ,μ,σ有多个,就分别赋初值;
第二步:E步。如果是首轮迭代,那么φ,μ,σ分别为我们给定的初值;否则φ,μ,σ取决于上一轮迭代的值。有了φ,μ,σ的值,我们按照如下公式计算Q函数:
其中,φ,σ,μ,x均已知,代入即可,i=1,2,...,N;k=1,2,...,K
第三步:M步。根据计算出来的Q,套进以下公式算出高斯混合模型的各个参数:
重复2~3步,直至收敛。
6. 高斯混合模型干啥使?
图像的前景和背景的分离;人群特征的分析;经济数据的分析等;
终于写完了,望各位大佬批评指正,不胜感激!为了首尾呼应,再表示一下我此刻的心情:
参考文档:
[1]. 我们该怎么认识“数学期望”
[2]. 最大似然估计_jubary的博客-CSDN博客_最大似然估计
[3]. 多元高斯分布(The Multivariate normal distribution) - bingjianing - 博客园
[4]. EM算法_纸上得来终觉浅~的博客-CSDN博客_em算法
[5]. 《统计学习方法》李航