python网络爬虫-数据存储之MySQL
MySQL是目前最受欢迎的开源关系型数据库管理系统。一个开源项目具有如此之竞争力是在是令人意外,它的流行程度正在不断接近另外两个闭源的商业数据库系统:微软的SQL Server和甲骨文的Oracle数据库。因为MySQL受众广泛、免费、开箱即用,所以它也是网络数据采集项目中常用的数据库。
上篇文章介绍了Linux环境下MySQL软件的安装和权限及密码设置,本篇文章开始使用Python整合MySQL。
Python没有内置的MySQL支持工具。不过,有很多开源的库可以用来与MySQL做交互。最著名的一个就是PyMySQL。直接使用pip包管理工作安装PyMySQL。

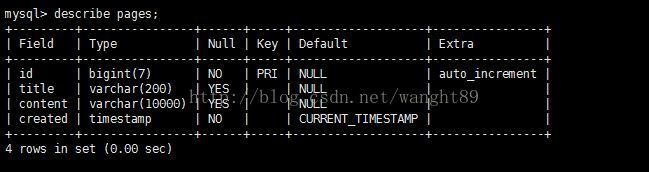
首先在MySQL数据库中新建数据库和表,并插入数据:
create database scrapying;
use scrapying;
create table pages(
id BIGINT(7) NOT NULL AUTO_INCREMENT,
title VARCHAR(200),
content VARCHAR(10000),
created TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
primary key(id)
);
执行插入语句操作:
insert into pages(title,content) values("Test Page Title","This is some test page content.It can be up to 10000 chareaters long.");成功安装了PyMySQL包,使用如下程序去测试安装是否成功:
import pymysql
conn=pymysql.connect(host='127.0.0.1',unix_socket='/tmp/mysql.sock',user='root',passwd='123456',db='mysql')
cur=conn.cursor()
cur.execute("USE scrapying")
cur.execute("SELECT * FROM pages WHERE id=1")
print(cur.fetchone())
cur.close()
conn.close()通过执行结果分析,发现数据库成功连接并且成功执行了查询语句,查询结果如上所示。这段程序中有两个对象:连接对象(conn)和光标对象(cur)。连接/光标模式时数据库编程中常用的模式。连接模式除了要连接数据库之外,还要发送数据库信息,处理回滚操作,创建新的光标对象等等。而一个连接可以有很多光标。一个光标跟踪一种状态信息,比如跟踪数据库的使用状态。如果你有多个数据库,且需要向所有数据库写内容,就需要多个光标来处理。光标还会包含最后一次查询执行的结果。通过调用光标函数,比如cur.fetchone(),可以获取查询结果。
使用完光标和连接之后,千万记得把他们关闭。如果不关闭就会导致连接泄漏(connection leak),造成一种未关闭的现象,即连接不再使用,但是数据库却不能关闭,因为数据库不能确定你还要不要继续使用它。这种现象会一直耗费数据库的资源,所以用完数据库之后记得关闭连接。
在进行网络数据采集时,处理Unicode字符串是很痛苦的事情。默认情况下,MySQL也不支持Unicode字符处理。不过你可以设置这个功能(但是这样做会增加数据库的占用空间),具体切换方法请参考http://blog.csdn.net/wanght89/article/details/78051022.
现在数据库已经准备好接受维基百科的各种信息了,你可以使用下面的程序来存储信息了:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import datetime
import random
import pymysql
conn=pymysql.connect(host='127.0.0.1',user='root',passwd='123456',db='mysql',charset='utf8')
cur=conn.cursor()
cur.execute("USE scrapying")
random.seed(datetime.datetime.now())
def store(title,content):
cur.execute("INSERT INTO pages(title,content) VALUES(\"%s\",\"%s\")",(title,content))
cur.connection.commit()
def getLinks(articleUrl):
html=urlopen("http://en.wikipedia.org"+articleUrl)
bsObj=BeautifulSoup(html,"html.parser")
title=bsObj.find("h1").get_text()
content=bsObj.find("div",{"id":"mw-content-text"}).find("p").get_text()
store(title,content)
return bsObj.find("div",{"id":"bodyContent"}).findAll("a",href=re.compile("^(/wiki/)((?!:).)*$"))
links=getLinks("/wiki/Kevin_Bacon")
try:
while len(links)>0:
newArticle=links[random.randint(0,len(links)-1)].attrs["href"]
print(newArticle)
links=getLinks(newArticle)
finally:
cur.close()
conn.close()执行上述代码后,爬虫开始运行,数据开始存入MySQL数据库,执行过程和结果如下:

上述程序中,有几点需要注意,首先是charset='utf8'要增加到连接字符串里。这里让连接conn把所有发送到数据库的信息都当成UTF-8编码格式。然后是store函数,它有两个参数,title和content,并把这两个参数加到了一个INSERT语句中并用光标执行,然后用光标进行连接确认。这是一个让光标与连接操作分离的好例子。当光标里存储了一些数据与数据库上下文context的信息时,需要通过链接的确认操作现将信息传进数据库,在将信息插入数据库。
最后要注意的是,finally语句是在程序主循环的外面,代码的最下面。这样做可以保证,无论程序执行过程中如何发生中断或抛出异常。光标和连接都会在程序结束前立即关闭。无论你是在采集网络,还是处理一个打开连接的数据库,try.....finally都会一个好主意。