操作系统(上)
参考自:公众号小林coding的图解系统
链接:https://pan.baidu.com/s/15zW9NaAIL5FJBeEF2aFdxQ
提取码:fkwx
硬件部分

首先我们要明确一个概念,读写速度越快(花费的CPU时钟周期越少)的硬件就越靠近CPU,且越昂贵。
CPU(中央处理器)
等于人体的大脑,是计算机得以运行的根本。32位CPU一次可装入4字节数据(32bits),64位CPU一次可装入8字节数据(64bits)。
64位CPU的优势在于能够计算的数值更大,比如(2^40)这个数,64位CPU可一次性装入并运算,放到32位CPU上只能把数拆分为高位与低位,分两次装入。
事实上,如果不计算2^32以上的大数,32位与64位CPU之间没有区别。只不过在32位CPU上运行的程序并不能直接移植到64位系统上。
在CPU内部,还有多种寄存器,包括但不限于通用寄存器(存放运算的数据)、程序计数器(也就是PC,PC指针指向了下一条指令在内存的地址)、指令寄存器(存放指令本身,指令被执行前,会被装载在这里)。
总线
分为以下三种:
1、地址总线:用于指定CPU要操作的内存地址,32位CPU采用的地址总线是并行的,也就是说有32根地址总线,可操作的地址空间是4GB(2^32 bytes)
2、数据总线:用于读写内存数据,32位CPU最好也配备32跟数据总线
3、控制总线:用于发送和接收信号,比如中断等信号,CPU收到信号就会进行响应
存储器
存储器分为很多种,内存、cache、寄存器以及硬盘。他们的特性、性能、应用场景各不相同,总的来说,就是读写速度越快的越贵,容量越少。除了硬盘之外,其他存储器在关机后,内部存储的数据都会丢失。
寄存器
寄存器的数量可达数十甚至数百个,32位CPU中大多数寄存器都能存储4字节数据,64位CPU则是8字节。寄存器的读写一般只需要花费半个时钟周期。
CPU cache
即高速缓冲存储器,使用SRAM芯片,读写速度次于寄存器。cache共分为三级。

L1级读写需要2-4个时钟周期,大小在几十到几百KB,每个CPU核心都有自己的L1高速缓存。在L1里指令与数据时分开存放的,所以通常分成指令缓存与数据缓存。
L2级读写需要10-20个时钟周期,大小在几百到几千KB,其位置比L1更远离CPU。同样地,每个CPU核心都有自己的L2高速缓存。
L3级读写需要20-60个时钟周期,大小在几MB到几十MB,多个CPU核心共享L3高速缓存。
内存
使用DRAM芯片,比SRAM便宜(意味着读取速度更慢,容量更大)。其访问数据需要200-300个时钟周期。
硬盘
分为SSD(固态硬盘)以及HDD(机械硬盘),断电后也能保存数据,固态的速度比内存慢10-1000倍。机械比内存慢十万倍,因为内部是靠磁盘旋转,然后靠磁头读取数据的。
存储器层次关系
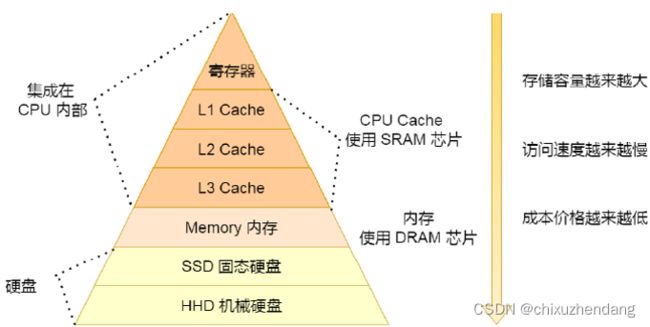 CPU并不会跟每一种存储器进行数据交换,而是通过寄存器,寄存器再通过cache…,因此每一种存储器只会与相邻的存储器进行数据交换。
CPU并不会跟每一种存储器进行数据交换,而是通过寄存器,寄存器再通过cache…,因此每一种存储器只会与相邻的存储器进行数据交换。
细聊cache
在linux系统中,我们可以根据一下命令查看三级高速缓存的大小。

CPU读取数据时会先访问cache,如果cache中恰好有所需的数据就直接读取而不必再访问内存,这就是缓存命中。
cache从内存中一块一块地读取数据,这些小块称为cache line(缓存块)。
CPU访问内存数据时同样是一块块读取的,这些块称为Block(内存块)。
要把内存块放到cache里面的话,就需要把一块内存块的地址映射到缓存块的地址上。通过地址取模可以分配缓存块行号,但还需要其他信息才能唯一指定缓存块中的数据块。
具体数据结构如下:
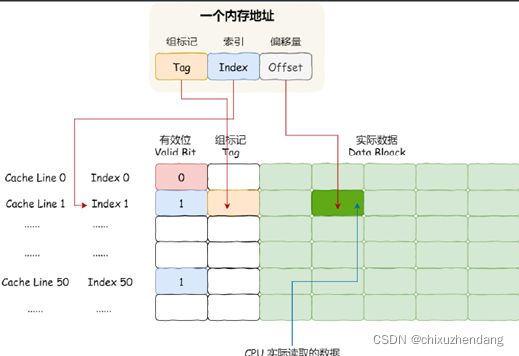
CPU访问一个内存地址的时候,需要4个步骤:
1、找到数据对应的cache line地址
2、判断有效位,如果无效就直接访问内存并重新加载数据
3、对比内存地址和cache line的组标记,如果不一致就直接访问内存并重新加载数据
4、根据内存地址的偏移量信息从cache line中读取对应的字
缓存一致性
即保持缓存中的数据与内存中的一致。对于单核CPU来说,只需要在缓存未命中的时候把对应的cache block标记为脏,然后再把数据写回内存就可以了。但是对于多核CPU(只共享L3 cache),还需要考虑多个CPU间的缓存一致性问题。多核CPU的缓存一致性需要有以下两种机制:
1、写传播:某个CPU核心的缓存更新需要同步到其他CPU
2、事务串行化:某个核心对数据的操作顺序,在其他核心看来也是一致的,打个比方,一个核心的缓存里的数据i先更改为100,再更改为200,那么这个过程放在别的核心里面也是一样的流程。
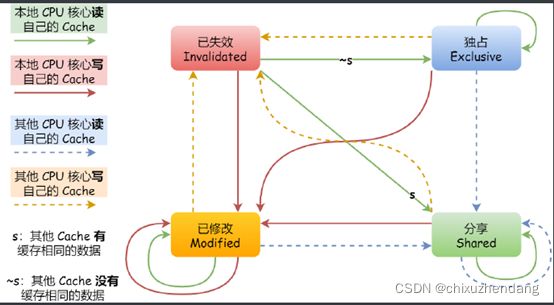
MESI协议
为了实现CPU缓存一致性而生的协议,主要定义了cache line的四种状态:modified(已修改)、exclusive(独占)、shared(共享)、invalidated(已失效)。
1、modified:表示当前缓存块的数据已被更改,并且还没有与内存同步。
2、exclusive:表示数据还没有更改,且没有与其他CPU缓存分享。
3、shared:多个CPU缓存都保存着这份数据。
4、invalidated:数据失效,不能再读取这份数据了。
举黎姿(黎姿永远的女神!):
1、1号CPU从内存读取变量i,此时其他CPU并没有缓存i,因此在1号CPU里对应的缓存块应标记为exclusive。
2、2号CPU也从内存读取了i,此时会发送信息给其他CPU,由于1号CPU缓存了i,因此缓存块应该从exclusive变为shared。
3、1号CPU更改了i的值,由于此时是shared柱状态,需要向其他所有CPU发送广播,请求他们把i对应的缓存块标记为invalidated。1号CPU修改完i值后,缓存块标记为modified。
4、如果1号继续修改modified数据,就无须再进行广播了。
5、1号CPU的i值对应的缓存块将被替换,由于此时是modified状态,就会在被替换时把i写回内存。
在exclusive和modified状态下修改数据都是不需要发送广播的,如果采用总线嗅探技术,每次修改都需要广播,无疑会增大总线压力。
状态转移图:
伪共享
所谓的伪共享,是指特定情况下,两个CPU读取同一块数据时,本该都是shared状态,然而在一系列特定的操作后,却变成一个已修改,另一个无效,且无法跳出这个状态循环。
故事伊始,我们假设有a、b两个变量,它们都不在cache,我们也有两个线程,它们分别绑定了1号CPU和2号CPU。假设线程1只读写a,线程2只读写b。
1、1号CPU读取a,但a、b恰好分在同一个cache line,此时应该是exclusive状态。
2、2号CPU读取b,此时应该是shared状态。
3、1号CPU要修改a,那么就先进行广播,请求2号把cache line修改为invalidated,然后1号标记为modified并修改。
4、2号CPU要修改b,由于是目前的cache line是invalidated,为了同步,应该先把1号CPU的modified数据协会到内存。2号CPU再从内存读取包含b的一块cache line,把状态更改为modified并修改。
5、如果1号与2号CPU交替修改a和b,就会重复步骤3和4,那么cache的作用就体现不出来了(每次修改数据都要从内存读进来)。
综上所述,对于多线程共享的热点数据,也就是经常会修改的数据,应当避免分在同一个cache line。
线程调度
linux系统中的任务有优先级,优先级越高则越快相应。分为实时任务(优先级0-99),普通任务(优先级100-139)。
对于不同的任务,有以下三种调度类:
1、deadline和realtime:用于实时任务,有以下特点:一、按照deadline(ddl)最近的优先调度。二、相同优先级排在前面的先调度。三、每个任务都有时间片,用完之后就放回队列尾部。支持抢占式任务调度。
2、fair:由CFS调度器管理,应用于普通任务。
每个CPU都有自己的运行队列,三种调度类各占一个,分别为dl_rq、rt_rq、csf_rq。其中csf_rq根据vruntime(任务的虚拟运行时间)大小来排序。
中断
搞单片机的应该听过,中断是操作系统响应硬件设备请求的机制,一旦发生中断,当前进程立刻挂起,并保护现场,然后去执行中断处理程序,处理完毕再回来恢复现场。(然而单片机学的并不好,有些术语好像并没有用对)。
如果整个中断流程用时太长,就会降低运行效率。因此linux系统把中断分为两部分。上半部分处理与硬件相关的事,下半部分用于后续处理。
比如,网卡接收网络包的时候,先是把这些包读到内存中,完成上半部分,然后内核触发软中断,进行网络数据包解析,下半部分用时一般较长。