UI自动化教程
Selenium教程
一、安装SeleniumWebdrive
1、下载selenium webdrive
2、下载地址:chromedrive
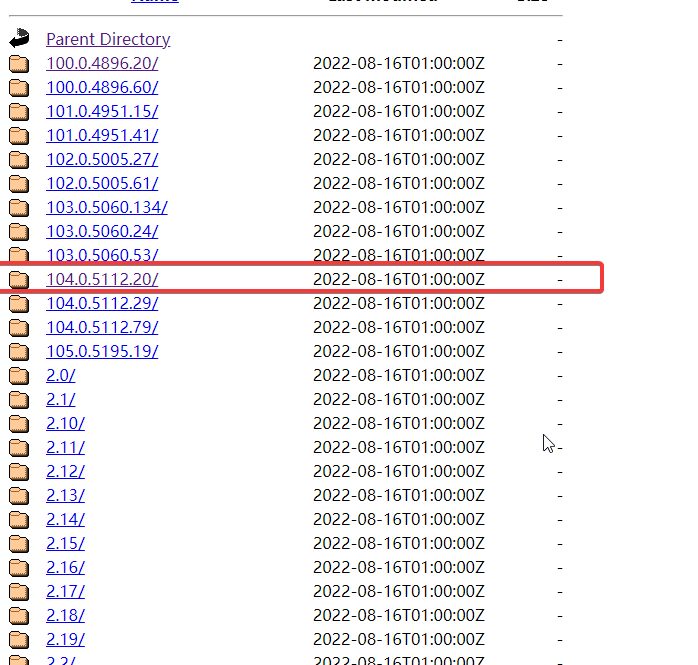
3、找到与谷歌浏览器版本号一致的包,下载chromedriver_win32.zip
可以通过浏览器右上角,点击设置,找到关于谷歌,即可查看本地谷歌浏览器的版本号
随后在淘宝镜像网中,找到与浏览器版本号开头一致的数字包即可.
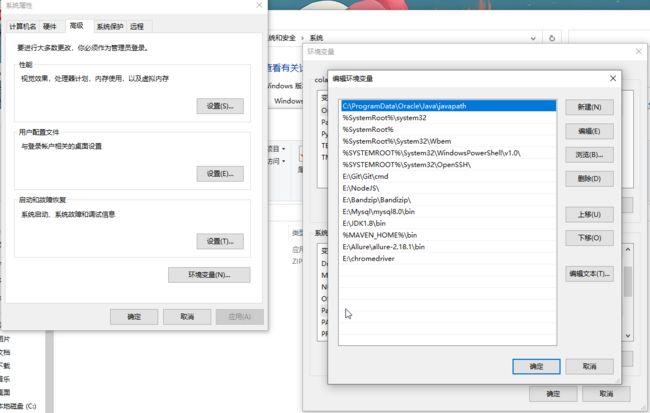
4、配置环境变量,将chromedriver_win32.zip文件解压地址添加到Path变量
Selenium驱动程序需要环境变量配置
二、Pycharm安装selenium
- 控制台Terminal输入安装命令
pip install selenium
三、测试Demo
from selenium import webdriver
driver = webdriver.Chrome(port=8800)
url = "https://www.colablog.top"
driver.get(url)
配置port端口可以用于多浏览器运行自动化,例如A电脑谷歌浏览器端口为8800
B电脑谷歌浏览器端口为9900
四、浏览器操作
-
driver.back() 上一个页面
-
driver.forward() 前进下一个页面
-
driver.refresh() 刷新
-
driver.minimize_window() 窗口最小化
-
driver.maximize_window() 窗口最大化
-
driver.fullscreen_window() 全屏
-
在新窗口打开链接
new_win = "window.open('https://taobao.com')"
driver.execute_script(new_win)
-
driver.get_screenshot_as_file() 截屏
-
driver.quit() 退出
from selenium import webdriver
from time import sleep
# 获得浏览器对象
driver = webdriver.Chrome(port=8800)
# 访问的URL
url = "https://www.colablog.top"
# 浏览器对象进行访问
driver.get(url)
sleep(2)
# 跳转操作
driver.get("https://www.bilibili.com")
sleep(2)
# 上一个页面
driver.back()
# 刷新
driver.refresh()
# 前进下一个页面
driver.forward()
# 窗口最小化
driver.minimize_window()
# 窗口最大化
driver.maximize_window()
# 在新窗口打开链接
new_win = "window.open('https://taobao.com')"
driver.execute_script(new_win)
# 截屏
driver.get_screenshot_as_file("E://PythonWorkSpace//SeleniumProject//screen.png")
# 退出
driver.quit()
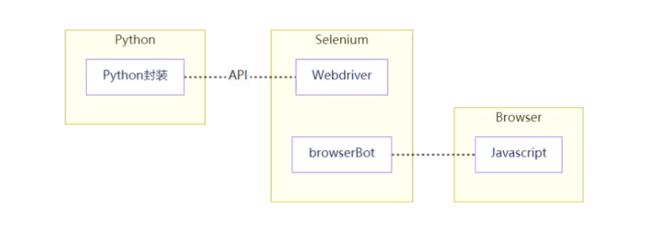
五、Python、Selenium、Chrome之间的关系
Python通过Selenium实例对象调用API去访问Webdriver接口,再通过Webdriver使用js代码去控制浏览器
六、8种元素定位方式
提醒:
通过webdriver对象的
find_element_by_xx(" ")(在selenium的4.0版本中此种用法已经抛弃,不推荐使用)
4.0版本语法解析
def find_element(self, by=By.ID, value=None)
或
def find_elements(self, by=By.ID, value=None)
find_element 和 find_elements的区别如下:
1、find_element查找元素返回的是一个对象,而find_elements返回的是一个列表
2、当find_element找到多个元素时,返回第一个,find_elements返回一个列表
3、当find_element找不到元素时,报错,find_elements返回空列表
其中By.ID在源码中存在映射关系,关系如下,一共有八种定位方式。
class By:
"""
Set of supported locator strategies.
"""
ID = "id"
XPATH = "xpath"
LINK_TEXT = "link text"
PARTIAL_LINK_TEXT = "partial link text"
NAME = "name"
TAG_NAME = "tag name"
CLASS_NAME = "class name"
CSS_SELECTOR = "css selector"
value传需要定位的元素,如xpath语句,最终调用find_element方法
也可直接传参str类型的数据,代表元素查找方式
input_element = browser.find_element('xpath', '表达式')
当使用By.ID或者其他时,需要导入from selenium.webdriver.common.by import By
最终返回一个WebElement对象,对象包含以下属性和方法:
-
tag_name 获取对象标签名
-
size 获得标签的宽高
-
text 获取标签文本
-
location 获得标签x,y轴坐标
-
rect 获得标签宽高和坐标
-
id 获取标签的标识
-
text 获取标签文本内容
-
click() 点击方法
-
submit() 提交方法
-
clear() 清空输入的内容
-
is_selected() 是否被选中
-
is_enabled() 是否可用
-
send_keys() 输入内容
-
is_displayed() 是否显示
-
get_attribute() 该元素指定属性的值
(一)、xpath
input_element = browser.find_element('xpath', '//*[@id="nav-searchform"]/div[1]/input')
Xpath常用方法详解:
- 基础语法:
| 表达式 | 描述 | 举例 |
|---|---|---|
| node_name | 选取此节点的所有子节点。 | 无 |
| / | 绝对路径匹配,从根节点选取。 | 无 |
| // | 相对路径匹配,从所有节点中查找当前选择的节点,包括子节点和后代节点,其第一个 / 表示根节点。 | //li |
| . | 选取当前节点。 | 无 |
| … | 选取当前节点的父节点。 | 无 |
| @ | 选取属性值,通过属性值选取数据。常用元素属性有 @id 、@name、@type、@class、@tittle、@href。 | //a[@class=“参数”] |
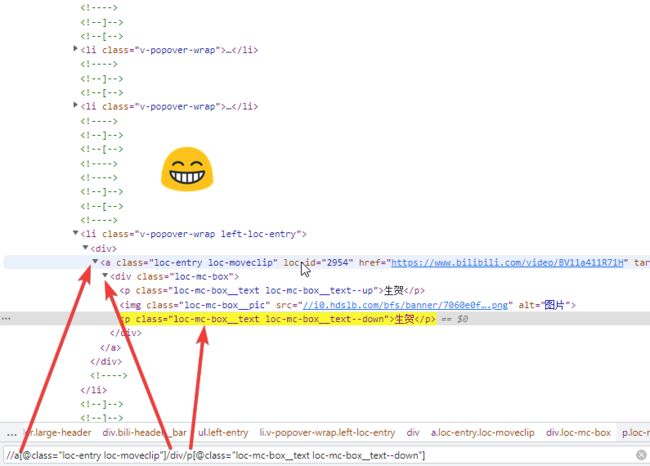
- xpath通配符:
| 通配符 | 描述说明 | 举例 |
|---|---|---|
| * | 匹配任意元素节点 | //li/* |
| @* | 匹配任意属性节点 | //li/@* |
| node() | 匹配任意类型的节点 | //li/node() |
- 多路径匹配
xpath表达式1 | xpath表达式2 | xpath表达式3
//ul/li[@class=“book2”]/p[@class=“price”]|//ul/li/@href
- 进阶用法
1、contains(包含某内容)
contains通常配合text一起使用,//a[contains(text(), ‘关闭’)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BBbFEdL6-1661627512771)(http://colablog.top/imagechrome_M8vYQQuoaB.png)]
2、starts-with(以某内容开头)

3、or(或)
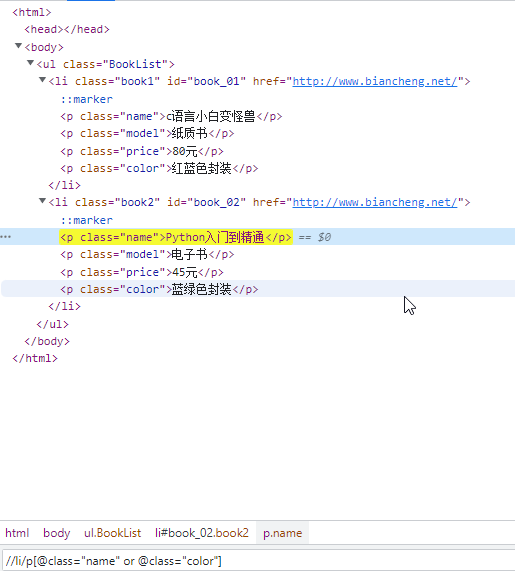
4、and(与)

5、text(包含某文本)
contains通常配合text一起使用,//a[contains(text(), ‘关闭’)]

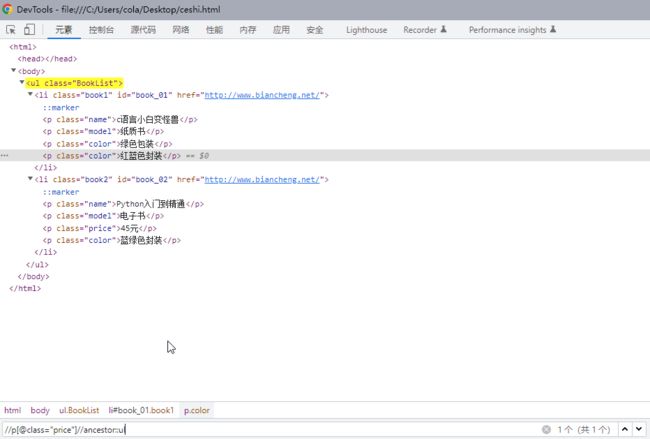
6、ancestor(查找节点前)
首先查找到在ancestor声明之前的那个元素,然后将这个元素设为顶端节点,最后查找这个节点内所有符合规则的元素
7、following(查找节点后)
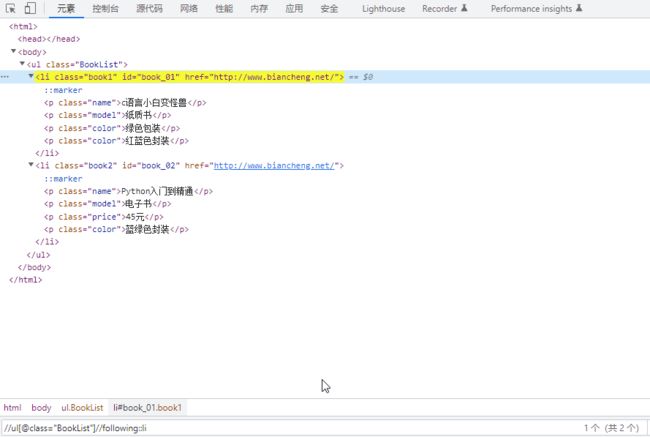
8、following-sibling(当前节点之后的所有同级节点)

9、preceding-sibling(当前节点之前的所有同级节点)

(二)、css
# 通过css选择器
lis = driver.browser.find_element('By.CSS_SELECTOR', 'body > div > ul > li:nth-child(2)')
print(lis.text)
| 选择器 | 示例 | 示例说明 |
|---|---|---|
| .class | .intro | 选择所有class="intro"的元素 |
| *id | #firstname | 选择所有id="firstname"的元素 |
| * | * | 选择所有元素 |
| element | p | 选择所有 元素 |
| element,element | div,p | 选择所有
元素和
元素 |
| element element | div p | 选择
元素内的所有
元素 |
| element>element | div>p | 选择所有父级是
元素的
元素 |
| element+element | div+p | 选择所有紧跟在
元素之后的第一个
元素 |
| [attribute] | [target] | 选择所有带有target属性元素 |
(三)、id
# 找到id = username的元素
username = driver.find_element('By.ID',"username")
# 输入值 张三
username.send_keys("张三")
# 找到od = password的元素
password = driver.find_element('By.ID',"password")
# 输入值 123
password.send_keys("123")
(四)、class
# =====通过 元素Class查找(仅返回匹配到的第一个)
login_btn = driver.find_element('By.CLASS_NAME',"login")
# 点击
login_btn.click()
element在找到多个class为login时,只返回第一个,若有多个标签使用同一个class属性值,建议使用elements
(五)、name
# =====通过 元素name查找元素(仅返回匹配到的第一个)
password = drive.find_element('By.NAME',"password")
# =====输入值 123
password.send_keys("123")
(六)、tag_name(标签名)
# 通过元素标签(仅返回匹配到的第一个)
p = driver.find_element('By.TAG_NAME',"p")
# 打印元素的文本值
print(p.text)
(七)、link_text(超链接文本—全量匹配)
# 通过超链接的文本查找元素
news_text = driver.find_element('By.LINK_TEXT ',"新闻")
print(news_text.text)
(八)、partial_link_text(超链接文本—模糊匹配)
# =====通过 超链接的文本查找元素(支持模糊匹配)
news_text = driver.find_element('By.PARTIAL_LINK_TEXT',"新")
print(news_text.text)
七、三种等待方式
- 强制等待
time.sleep(10)
停止代码运行,直到指定时间才继续运行代码,全局无限次数使用。
- 隐性等待
browser.implicitly_wait(10)
隐性等待只能等待目标元素加载完毕,不能等待页面内容加载,即每一个driver.find_element或driver.find_elements寻找的元素,全局只能使用一次此方法。
- 显性等待
wait = WebDriverWait(browser, 10)
基于强制等待和隐性等待的综合体,全局无限使用,在某个需要等待的元素后面添加即可,分三个步骤
第一个步骤是获得显性等待器,传入两个参数,第一个是浏览器驱动对象,第二个是超时时长,在固定时间内如果超时,则不再等待。第三个为可选参数,每隔多长时长查看是否得到等待结果,poll_frequency=时长
第二个步骤是设置等待器的等待条件,wait.until(),导入expected_conditions包,里面有等待条件的各种方法。如查询是否包含在标题中,wait.until(expected_conditions.title_contains()

显性等待不仅可以等待页面内容的出现,也可以等待页面元素的加载,如下代码实现
locator可传元组或者列表。
locator = ['id', 'kw']
baidu_element = wait.until(expected_conditions.presence_of_element_located(locator))
窗口等待案例:
窗口等待方法为:expected_conditions.new_window_is_opened(current_handles)
在窗口切换之前获得当前handlers,在源码中,判断当前与新开窗口的handles列表长度,如果长度大于打开之前的handles,则说明新窗口打开成功。
def test_setting(self):
# 实例化浏览器对象
browser = webdriver.Chrome()
# 隐性等待
browser.implicitly_wait(10)
# 自定义URL
url = "https://www.baidu.com"
# 访问url
browser.get(url)
time.sleep(2)
# 获取当前窗口句柄
current_handles = browser.window_handles
# 鼠标操作
action = ActionChains(browser)
setting = browser.find_element(By.ID, 's-usersetting-top')
action.move_to_element(setting).perform()
time.sleep(2)
weather = browser.find_element('xpath', '//a[contains(text(), "隐私")]')
action.click(weather).perform()
# 新窗口显性等待
wait = WebDriverWait(driver=browser, timeout=5)
wait.until(expected_conditions.new_window_is_opened(current_handles))
browser.switch_to.window(browser.window_handles[-1])
qr_code = browser.find_element('xpath', "//p[contains(text(),'用户名密码') and @class='pass-form-logo']")
time.sleep(2)
print(qr_code.tag_name)
总结:使用等待优先级—隐形等待 > 强制等待 > 显性等待
八、三种切换
(一)、窗口切换
browser.switch_to.window()
窗口的切换根据窗口句柄进行切换,窗口句柄就是窗口的标识码,多个窗口通过browser.window_handles获得窗口列表,通过下标获取指定窗口。
(二)、iframe切换
browser.switch_to.frame()
参数可传index(下标0开始),name(name属性值),以及iframe_element(通过find_element获得),表示具体切换的iframe
# iframe切换
# 通过name
browser.switch_to.frame('iframeResult')
# 通过index
browser.switch_to.frame(0)
# 通过element
iframe_element = browser.find_element('id', 'iframeResult')
browser.switch_to.frame(iframe_element)
(三)、alert切换
alert = browser.switch_to.alert
- accetp()
1.先用switch_to_alert方法切换到alert弹出框上
2.可以用text方法获取弹出的文本信息
3.accept()点击确认按钮
- dismiss()
1.先用switch_to_alert方法切换到alert弹出框上
2.可以用text方法获取弹出的文本信息
3.dismiss()相当于点右上角x,取消弹出框
- send_keys()— 仅限于prompt
1.先用switch_to_alert方法切换到alert弹出框上
2.可以用text方法获取弹出的文本信息
3.send_keys()这里多个输入框,可以用send_keys()方法输入文本内容
4.accept()点击确认按钮
九、鼠标操作
- 导包
from selenium.webdriver import ActionChains
初始化动作链条
action = ActionChains(browser)
ActionChains支持连续操作(链式调用),但是perfrom结尾将不能再进行连续操作,如:
action.click(weather).click().move_to_element().send_keys().perform()
- 单击操作()
方式一:action.click(driver).perform()
方拾二:browser.find_element(By.ID, ‘s-usersetting-top’).click()
区别:第一种方式可操作性更高,第二种方式简洁明了
- 移动操作
action.move_to_element(element_name).perform()
- 双击操作
action.double_click(element_name)
- 右击操作
action.context_click(element_name)
- 拖拽操作
action.drag_and_drop(element_name1, element_name2)
十、键盘操作
- 指定元素键盘操作—Keys
from selenium.webdriver import Keys
baidu_element.send_keys(Keys.ENTER)
- 全局键盘操作—ActionChains
from selenium.webdriver import ActionChains
baidu_element.send_keys(Keys.ESC).perform()
十一、下拉元素选择操作
- 第一种方式:直接选择元素
def test_choice(self):
# 实例化浏览器对象
browser = webdriver.Chrome()
# 隐性等待
browser.implicitly_wait(10)
# 自定义URL
url = "E:/PythonWorkSpace/SeleniumProject/test.html"
# 访问url
browser.get(url)
time.sleep(2)
select_ele = browser.find_element('xpath', '//option[@value="women"]')
select_ele.click()

- 方式二:通过Select
导包:
from selenium.webdriver.support.select import Select
先找到下拉框元素ID,传入Select,再根据返回的对象去根据方法找对应的下拉元素
select_ele = browser.find_element('id', 'choice')
select_ele2 = Select(select_ele)
select_ele2.select_by_visible_text("女")
time.sleep(2)
select_ele2.select_by_value("man")
time.sleep(2)
十二、JS操作
当下拉框元素不是select时,直接选择元素或通过Select将无法选择,可以通过JS操作
- browser.execute_script(dom_script)
def test_dmo(self):
# 实例化浏览器对象
browser = webdriver.Chrome()
# 隐性等待
browser.implicitly_wait(10)
# 自定义URL
url = "https://www.12306.cn/index/"
# 访问url
browser.get(url)
time.sleep(2)
# 当下拉框为Select时,此方法生效
# elem = browser.find_element('id', 'train_date')
# elem_select = Select(elem)
# elem_select.select_by_visible_text('31')
# time.sleep(2)
# 当下拉框为其他元素,如div时,可用dom操作
dom_script = "let date = document.getElementById('train_date');date.readOnly = false;date.value = '2022-05-01'"
browser.execute_script(dom_script)
time.sleep(2)
- Python 与 JS 混用
# python 与 JS 混用
elem = browser.find_element('id', 'train_date')
time.sleep(2)
js_script = "arguments[0].readOnly = false; arguments[0].value = '2022-05-01'"
browser.execute_script(js_script, elem)
time.sleep(5)
- JS操作滚动条
window.scrollTo(0, document.body.scrollHeight)
十三、文件上传
- 上传元素为input时
def test_file(self):
# 实例化浏览器对象
browser = webdriver.Chrome()
# 隐性等待
browser.implicitly_wait(10)
# 自定义URL
url = "http://www.zuohaotu.com/image-converter.aspx"
# 访问url
browser.get(url)
time.sleep(2)
file_elem = browser.find_element('id', 'newFile')
file_elem.send_keys(r'D:\壁纸.jpg')
time.sleep(2)
- 元素为非input时,使用第三付库—win32gui
# 打开上传网站
driver.get("https://tinypng.com/")
paths = Path.cwd().parent
# 触发文件上传的操作
driver.find_element_by_css_selector("section.target").click()
time.sleep(2)
# 一级顶层窗口
dialog = win32gui.FindWindow("#32770", "打开")
# 二级窗口
comboBoxEx32 = win32gui.FindWindowEx(dialog, 0, "ComboBoxEx32", None)
# 三级窗口
comboBox = win32gui.FindWindowEx(comboBoxEx32, 0, "ComboBox", None)
# 四级窗口 -- 文件路径输入区域
edit = win32gui.FindWindowEx(comboBox, 0, "Edit", None)
# 二级窗口 -- 打开按钮
button = win32gui.FindWindowEx(dialog, 0, "Button", None)
# 1、输入文件路径
filepath = f"{paths}\\resources\\11.png"
win32gui.SendMessage(edit, win32con.WM_SETTEXT, None, filepath)
# 2、点击打开按钮
win32gui.SendMessage(dialog, win32con.WM_COMMAND, 1, button)
注意:当涉及文件路径时,有三种办法防止路径转义报错
(一):使用正斜杠/
(二):使用双反斜杠\\
(三):前面加r参数
多文件上传只需要写多几个send_keys方法即可
十四、PO(POM)模式
简介:PO模式是page object model的缩写,Page Object模式是Selenium中的一种测试设计模式,主要是将每一个页面设计为一个Class(封装在一个class类中),其中包含页面中需要测试的所有元素(按钮,输入框,标题等)的属性和操作,这样在Selenium测试页面中可以通过调用页面类来获取页面元素,这样巧妙的避免了当页面元素id或者位置变化时,需要改测试页面代码的情况。当页面元素id变化时,只需要更改测试页Class中页面的属性即可。
(一)、为何使用PO模式?
少数的自动化测试用例维护起来看起来是很容易的。但随着时间的迁移,测试套件将持续地增长脚本也将变得越来越臃肿庞大。如果变成我们需要维护10个页面,100个页面,甚至1000个呢?且页面元素很多是公用的,所以页面元素的任何改变都会让我们的脚本维护变得繁琐复杂,且变得耗时易出错。
也就是说页面中有一个按钮 元素A"。该元素A在十个测试用例中都被用到了,如果元素A被前端更新了,我就要去修改这十个自动化用例所用道元素A的地方。如果有100个、1000个用例用到了元素A,那我可就疯了。
而POM设计模式,会把公共的元素抽取出来,该元素被前端修改,只需要更新该元素的定位方式即可,用例不需要改动。换句话说,不管我多少测试用例,用到了该元素,我只重新修改元素的定位方式,重新能够获得该元素即可。
(二)、PO模式的优势?
-
代码冗余明显降低:二次封装Selenium方法和提取公共方法,提高代码复用性
-
代码的阅读性明显提升:因为三层分级,将不同内容进行不同的封装,整体代码阅读性提升
-
代码维护性明显提升:UI测试中,页面若经常变动,代码的维护量随之增多;因为三层分级,我们只需要修改页面对象的代码,如元素对象或者操作对象的方法,不用修改测试用例的代码,也不影响测试用例的正常执行
-
降低代码耦合性
(三)、PO模式三层详解
- 基础层 : 二次封装Selenium的方法
包括一些点击操作、find_element/find_elements操作,send_keys操作等
此层主要是针对Selenium的方法进行二次封装,方便调用
目前市面上的包括Helium、playwright等框架都是基于Selenium进行二次封装
- 页面对象层: 用于放页面的元素和页面的动作
一个页面即为一个Object对象,这个是PO模型的特征,一个页面对象里面包含有属性和方法,属性就是页面上的所有HTML标签,一个标签即理解为一个元素,一个find_element,HTML标签的点击事件则为一个方法
- 测试用例层: 多个页面操作完成一个业务测试
通过调用基础层(BasePage)对Selenium二次封装的方法,操作页面对象层中的动作,将多个动作连成一个业务测试流程,完成UI自动化测试。
(四)、实战案例
前言:以黑马的博学谷网站为例,使用PO模型,设计一个对于登录流程的UI自动化用例。
(1)、项目整体架构
-
Common:公共层,存放通用方法,如Selenium二次封装,即基础层,BasePages
-
Config: 项目配置层,存放项目配置文件,如conf.yaml,db.ini
-
Data: 数据层,存放测试数据,或者数据驱动文件,关键字驱动等等
-
Logs: 日志层,存放项目运行日志,按照日期区分
-
Reports: 测试报告层,存放测试用例执行的HTML报告文件
-
Pages: 页面层,一个网页即为一个页面.py文件,封装页面的元素及方法
-
TestCases: 测试用例层,存放测试用例,按照pytest命名规则,以test_开头
-
Utils: 工具层,封装工具类方法,如读取yaml,获取绝对路径,日志类封装等
-
conftest.py: 夹具层,存放测试类或者测试方法的全局测试前置步骤和后置步骤
-
run.py: 执行测试用例,生成测试报告
(2)、编写BasePage
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver import Chrome
from Utils.GetPath import GetPath
class BasePage:
"""selenium操作二次封装"""
def __init__(self, driver: Chrome):
self.driver = driver
# 访问链接
def get_url(self, url, path=None):
"""
:param url: 后缀地址
:param path: 需要拼接的yaml文件地址
:return:
"""
url = GetPath.get_url(url, path)
self.driver.get(url)
return self
# 点击操作封装
def click(self, locator: tuple):
elem = self.driver.find_element(*locator)
self.wait_elem(locator)
# 此操作为强制点击
self.driver.execute_script("arguments[0].click({force:true})", elem)
return self
# 输入操作封装
def send_keys(self, locator: tuple, text):
self.driver.find_element(*locator).send_keys(text)
return self
# 显性等待封装
def wait_elem(self, locator, timeout=10, poll=0.5):
wait = WebDriverWait(self.driver, timeout=timeout, poll_frequency=poll)
wait.until(expected_conditions.presence_of_element_located(locator))
return self
(3)、编写Utils
封装绝对路径:
import os.path
import yaml
class GetPath:
@classmethod
def get_abs_path(cls, path):
system_path = os.path.dirname(os.path.dirname(__file__))
data_path = os.path.oin(system_path, 'Config', path)
return data_path
@classmethod
def get_url(cls, url, path):
if path:
path = cls.get_abs_path(path)
with open(file=path, mode="r", encoding="utf-8") as file:
url_data = yaml.load(stream=file, Loader=yaml.FullLoader)
front_url = url_data[0]["host"]
behind_url = url
fill_url = front_url + behind_url
return fill_url
else:
return url
@classmethod
def get_log_path(cls):
system_path = os.path.dirname(os.path.dirname(__file__))
log_path = os.path.join(system_path, "Logs", "")
return log_path
日志类封装:
import logging
import datetime
import os
from Utils.GetPath import GetPath
log_level_dict = {
"debug": logging.DEBUG,
"info": logging.INFO,
"warning": logging.WARNING,
"error": logging.ERROR,
"critical": logging.CRITICAL
}
class LogUtil:
def __init__(self, log_name, file_name, log_level, **kwargs):
self.log_name = log_name
self.file_name = file_name
self.log_level = log_level
def log(self):
# 1、创建日志对象
my_log = logging.getLogger(self.log_name)
# 2、设置日志级别
my_log.setLevel(log_level_dict[self.log_level])
# 3、创建控制台输出Handler,不存在才创建,存在直接用
if not my_log.handlers:
handler = logging.StreamHandler()
# 4.设置控制台Handler输出日志级别
handler.setLevel(log_level_dict[self.log_level])
# 5.设置日志输出格式
formatter = logging.Formatter('%(asctime)s %(levelname)s [%(filename)s(%(funcName)s:%(lineno)d)] - %(message)s')
# 6.绑定handler输出格式
handler.setFormatter(formatter)
# 7.添加到logger对象中
my_log.addHandler(handler)
# 8.级别排序:CRITICAL >ERROR >WARNING >INFO >DEBUG
# 9.写入文件
file_handler = logging.FileHandler(self.file_name, encoding='utf-8')
# 10.设置日志文件级别
file_handler.setLevel(log_level_dict[self.log_level])
# 11.设置日志文件输出格式
file_handler.setFormatter(formatter)
# 12.添加到logger对象中
my_log.addHandler(file_handler)
return my_log
def log_util():
log_path = GetPath.get_log_path()
current_time = datetime.datetime.now().strftime("%Y-%m-%d")
log_file = os.path.join(log_path + "AutoUI" + current_time + ".log")
print(log_file)
util = LogUtil("log", log_file, "debug").log()
return util
读取Yaml封装:
import yaml
from Utils.GetPath import GetPath
class ReadYamlUtils:
@classmethod
def read_data(cls, path, key):
path = GetPath.get_abs_path(path)
with open(file=path, mode="r", encoding="utf-8") as file:
data = yaml.load(stream=file, Loader=yaml.FullLoader)
return data[0][key]
(4)、编写Pages
以页面为对象把元素和方法进行封装
from selenium.webdriver.common.by import By
from Common.BasePage import BasePage
from Utils.Logger import log_util
class OnlineClass(BasePage):
# 定义类属性
url = "/user/login?refer=https%3A%2F%2Fwww.boxuegu.com%2F"
button_locator = (By.XPATH, "//span[text()='登录']")
submit_locator = (By.XPATH, "//button[text()='登录']")
username_locator = (By.XPATH, '//*[@placeholder="请输入手机号或邮箱" and @class="el-input__inner"]')
password_locator = (By.XPATH, '//*[@placeholder="请输入密码" and @class="el-input__inner"]')
# 登录操作封装
def login(self, username, password):
"""
:param username: 账号
:param password: 密码
:return: 对象本身
"""
self.click(self.button_locator)
locator = ['xpath', "//button[text()='登录']"]
self.wait_elem(locator).send_keys(self.username_locator, username)\
.send_keys(self.password_locator, password)\
.click(self.submit_locator)
log_util().debug("登录操作")
return self
# 加载
def load(self):
self.get_url(self.url, path="conf.yaml")
log_util().debug("加载操作")
return self
# 获取操作提示
def get_errmsg(self):
tips = self.driver.find_elements(By.XPATH, '//div[@class="el-form-item__error"]')
log_util().debug("提示符文字获取操作")
return [index.text for index in tips]
# 清除内容
def clear(self):
log_util().debug("清楚输入框内容操作")
self.driver.find_element(By.XPATH, '//*[@placeholder="请输入手机号或邮箱" and @class="el-input__inner"]').clear()
self.driver.find_element(By.XPATH, '//*[@placeholder="请输入密码" and @class="el-input__inner"]').clear()
(5)、编写Data
为了方便获取参数,没有使用yaml文件,使用了py文件
login_data = [
('', '', ['请输入手机号或邮箱!', '请输入密码!']),
('13536237223', '', ['请输入密码!']),
('13536237223', '123456', ['请输入正确密码,连续输入错误密码,账号将被锁定'])
]
(6)、编写Config
此文件主要是控制项目的切换,可自行添加参数,包括项目环境,地址等等
-
host: "https://passport.boxuegu.com"
enviorment: "TEST"
(7)、编写TestCases
由于Pages封装的方法返回值为Page类对象本身,所以在测试用例设计中,可以使用链式调用
import pytest
from Data import Login
from Pages.OnlineClass import OnlineClass
class TestClass:
@pytest.mark.parametrize("login_data", Login.login_data)
def test_login(self, get_driver, login_data):
# 解包
username, password, result = login_data
# 全局夹具对象
browser = get_driver
# po模型对象
login_page = OnlineClass(driver=browser)
# 链式调用
value = login_page.load().login(username, password).get_errmsg()
assert value == result
(8)、编写conftest.py
当有多个不同身份登录时,可以写不同身份的夹具方法,如学生和老师,在登录测试用例中,对于老师和学生不同的登录,就可以按照不同的夹具实现,因为夹具里面可能会定义一些登录账号和密码,需要注意的是scope参数,如果是class,则一个类里面所有测试用例必须是在同一个页面进行操作,否则找不到元素,这是因为driver对应着一个页面,如果上一个页面跳转到其他页面,而其他用例的dirver还是原来的,那么肯定是找不到元素的
import pytest
from selenium import webdriver
@pytest.fixture(scope="class")
# 必须是测同一个页面才能用class,否则不要设置作用域,会找不到元素哦
def get_driver():
# 实例化浏览器对象
browser = webdriver.Chrome()
# 隐性等待
browser.implicitly_wait(10)
browser.maximize_window()
yield browser
browser.quit()