Leetcode刷题笔记——剑指offer II (五)【二分、排序、回溯】
这里写目录标题
- 二分查找
-
- 剑指 Offer II 069. 山峰数组的顶部
- 剑指 Offer II 070. 排序数组中只出现一次的数字
- 剑指 Offer II 071. 按权重生成随机数
- 剑指 Offer II 072. 求平方根
- 剑指 Offer II 073. 狒狒吃香蕉
- 4. 寻找两个正序数组的中位数
- 33. 搜索旋转排序数组
- 排序
-
- 剑指 Offer II 074. 合并区间
- 剑指 Offer II 075. 数组相对排序
- 归并排序 (比较占用内存,但效率高且稳定)
- 剑指 Offer II 077. 链表排序
- 剑指 Offer II 078. 合并排序链表
- 剑指 Offer 51. 数组中的逆序对
- 769. 最多能完成排序的块
- 回溯(二叉树、多叉树)
-
- 剑指 Offer II 079. 所有子集
- 剑指 Offer II 080. 含有 k 个元素的组合
- 剑指 Offer II 081. 允许重复选择元素的组合
- 剑指 Offer II 082. 含有重复元素集合的组合
- 剑指 Offer II 083. 没有重复元素集合的==全排列==
- 剑指 Offer II 084. 含有重复元素集合的全排列
- 剑指 Offer II 085. 生成匹配的括号
- 剑指 Offer II 086. 分割回文子字符串
- 剑指 Offer II 087. 复原 IP
- (归并) 856. 括号的分数
二分查找
剑指 Offer II 069. 山峰数组的顶部
符合下列属性的数组 arr 称为 山峰数组(山脉数组) :
arr.length >= 3- 存在
i(0 < i < arr.length - 1)使得:arr[0] < arr[1] < ... arr[i-1] < arr[i]arr[i] > arr[i+1] > ... > arr[arr.length - 1]
给定由整数组成的山峰数组arr,返回任何满足arr[0] < arr[1] < ... arr[i - 1] < arr[i] > arr[i + 1] > ... > arr[arr.length - 1]的下标i,即山峰顶部。
示例 1:
输入:arr = [0,1,0]
输出:1
示例 2:
输入:arr = [1,3,5,4,2]
输出:2
示例 3:
输入:arr = [0,10,5,2]
输出:1
示例 4:
输入:arr = [3,4,5,1]
输出:2
示例 5:
输入:arr = [24,69,100,99,79,78,67,36,26,19]
输出:2
提示:
3 <= arr.length <= 104
0 <= arr[i] <= 106
题目数据保证 arr 是一个山脉数组
进阶:很容易想到时间复杂度 O(n) 的解决方案,你可以设计一个 O(log(n)) 的解决方案吗?
我的方法:遍历
int peakIndexInMountainArray(vector<int>& arr) {
for (int i = 1; i < arr.size(); i++) {
if (arr[i] < arr[i - 1]) return i - 1;
}
return arr.size() - 1;
}
复杂度分析
-
时间复杂度:O(n),其中 n 是数组 arr \textit{arr} arr 的长度。我们最多需要对数组 arr \textit{arr} arr 进行一次遍历。
-
空间复杂度:O(1)。
方法二:二分查找
思路与算法
记满足题目要求的下标 i 为 i ans i_\textit{ans} ians。我们可以发现:
-
当 i < i ans i < i_\textit{ans} i<ians时, arr i < arr i + 1 \textit{arr}_i < \textit{arr}_{i+1} arri<arri+1恒成立;
-
当 i ≥ i ans i \geq i_\textit{ans} i≥ians时, arr i > arr i + 1 \textit{arr}_i > \textit{arr}_{i+1} arri>arri+1 恒成立。
这与方法一的遍历过程也是一致的,因此 i ans i_\textit{ans} ians即为「最小的满足 arr i > arr i + 1 \textit{arr}_i > \textit{arr}_{i+1} arri>arri+1的下标 i i i」,我们可以用二分查找的方法来找出 i ans i_\textit{ans} ians。
int peakIndexInMountainArray(vector<int>& arr) {
int n = arr.size();
int left = 1, right = n - 2, ans = 0;
while (left <= right) {
int mid = (left + right) / 2;
if (arr[mid] > arr[mid + 1]) {
ans = mid;
right = mid - 1;
}
else {
left = mid + 1;
}
}
return ans;
}
复杂度分析
- 时间复杂度: O ( log n ) O(\log n) O(logn),其中 nn 是数组 arr \textit{arr} arr 的长度。我们需要进行二分查找的次数为 O ( log n ) O(\log n) O(logn)。
- 空间复杂度:O(1)。
剑指 Offer II 070. 排序数组中只出现一次的数字
给定一个只包含整数的有序数组 nums ,每个元素都会出现两次,唯有一个数只会出现一次,请找出这个唯一的数字。
示例 1:
输入: nums = [1,1,2,3,3,4,4,8,8]
输出: 2
示例 2:
输入: nums = [3,3,7,7,10,11,11]
输出: 10
提示:
1 <= nums.length <= 105
0 <= nums[i] <= 105
进阶: 采用的方案可以在 O(log n) 时间复杂度和 O(1) 空间复杂度中运行吗?
我的方法:遍历异或
int singleNonDuplicate(vector<int>& nums) {
int ans = nums[0];
for (int i = 1; i < nums.size(); i++) {
ans ^= nums[i];
}
return ans;
}
复杂度:O(n), O(1)
方法二:全数组的二分查找
假设只出现一次的元素位于下标 x,由于其余每个元素都出现两次,因此下标 x 的左边和右边都有偶数个元素,数组的长度是奇数。
由于数组是有序的,因此数组中相同的元素一定相邻。对于下标 x 左边的下标 y,如果 nums [ y ] = nums [ y + 1 ] \textit{nums}[y] = \textit{nums}[y + 1] nums[y]=nums[y+1],则 y y y 一定是偶数;对于下标 x x x 右边的下标 z z z,如果 nums [ z ] = nums [ z + 1 ] \textit{nums}[z] = \textit{nums}[z + 1] nums[z]=nums[z+1],则 z z z 一定是奇数。由于下标 x x x 是相同元素的开始下标的奇偶性的分界,因此可以使用二分查找的方法寻找下标 x x x。
初始时,二分查找的左边界是 0 0 0,右边界是数组的最大下标。每次取左右边界的平均值 mid \textit{mid} mid 作为待判断的下标,根据 mid \textit{mid} mid 的奇偶性决定和左边或右边的相邻元素比较:
- 如果 mid \textit{mid} mid 是偶数,则比较 nums [ mid ] \textit{nums}[\textit{mid}] nums[mid] 和 nums [ mid + 1 ] \textit{nums}[\textit{mid} + 1] nums[mid+1] 是否相等;
- 如果 mid \textit{mid} mid是奇数,则比较 nums [ mid − 1 ] \textit{nums}[\textit{mid} - 1] nums[mid−1] 和 nums [ mid ] \textit{nums}[\textit{mid}] nums[mid] 是否相等。
如果上述比较相邻元素的结果是相等,则 mid < x \textit{mid} < x mid<x,调整左边界,否则 mid ≥ x \textit{mid} \ge x mid≥x,调整右边界。调整边界之后继续二分查找,直到确定下标 x x x 的值。
得到下标 x x x 的值之后, nums [ x ] \textit{nums}[x] nums[x] 即为只出现一次的元素。
细节
利用按位异或的性质,可以得到 mid \textit{mid} mid 和相邻的数之间的如下关系,其中 ⊕ \oplus ⊕ 是按位异或运算符:
- 当 mid \textit{mid} mid是偶数时, mid + 1 = mid ⊕ 1 \textit{mid} + 1 = \textit{mid} \oplus 1 mid+1=mid⊕1;
- 当 mid \textit{mid} mid是奇数时, mid − 1 = mid ⊕ 1 \textit{mid} - 1 = \textit{mid} \oplus 1 mid−1=mid⊕1。
因此在二分查找的过程中,不需要判断 mid \textit{mid} mid的奇偶性, mid \textit{mid} mid和 mid ⊕ 1 \textit{mid} \oplus 1 mid⊕1 即为每次需要比较元素的两个下标。
int singleNonDuplicate(vector<int>& nums) {
int low = 0, high = nums.size() - 1;
while (low < high) {
int mid = (high - low) / 2 + low;
if (nums[mid] == nums[mid ^ 1]) {
low = mid + 1;
} else {
high = mid;
}
}
return nums[low];
}
复杂度分析
- 时间复杂度: O ( log n ) O(\log n) O(logn),其中 n 是数组 nums \textit{nums} nums 的长度。需要在全数组范围内二分查找,二分查找的时间复杂度是 O ( log n ) O(\log n) O(logn)。
- 空间复杂度: O ( 1 ) O(1) O(1)。
剑指 Offer II 071. 按权重生成随机数
给定一个正整数数组 w ,其中 w[i] 代表下标 i 的权重(下标从 0 开始),请写一个函数 pickIndex ,它可以随机地获取下标 i,选取下标 i 的概率与 w[i] 成正比。
例如,对于 w = [1, 3],挑选下标 0 的概率为 1 / (1 + 3) = 0.25 (即,25%),而选取下标 1 的概率为 3 / (1 + 3) = 0.75(即,75%)。
也就是说,选取下标i的概率为 w [ i ] / s u m ( w ) w[i] / sum(w) w[i]/sum(w) 。
示例 1:
输入:
inputs = ["Solution","pickIndex"]
inputs = [[[1]],[]]
输出:
[null,0]
解释:
Solution solution = new Solution([1]);
solution.pickIndex(); // 返回 0,因为数组中只有一个元素,所以唯一的选择是返回下标 0。
示例 2:
输入:
inputs = ["Solution","pickIndex","pickIndex","pickIndex","pickIndex","pickIndex"]
inputs = [[[1,3]],[],[],[],[],[]]
输出:
[null,1,1,1,1,0]
解释:
Solution solution = new Solution([1, 3]);
solution.pickIndex(); // 返回 1,返回下标 1,返回该下标概率为 3/4 。
solution.pickIndex(); // 返回 1
solution.pickIndex(); // 返回 1
solution.pickIndex(); // 返回 1
solution.pickIndex(); // 返回 0,返回下标 0,返回该下标概率为 1/4 。
由于这是一个随机问题,允许多个答案,因此下列输出都可以被认为是正确的:
[null,1,1,1,1,0]
[null,1,1,1,1,1]
[null,1,1,1,0,0]
[null,1,1,1,0,1]
[null,1,0,1,0,0]
......
诸若此类。
提示:
1 <= w.length <= 10000
1 <= w[i] <= 10^5
pickIndex 将被调用不超过 10000 次
我的方法:前缀和+二分
注意:
- 使用rand函数时,要先设定随机数
srand((unsigned)time(0));才能起作用 - rand()如果想要返回double型o-1的小数,则
double ans = rand() % double(RAND_MAX);
vector<int> m;
Solution(vector<int>& w) {
m = vector<int>(w.size() + 1);
for (int i = 1; i <= w.size(); i++)
m[i] = m[i - 1] + w[i - 1];
srand((unsigned)time(0));
}
int pickIndex() {
int n = rand() % m.back() + 1;
auto it = lower_bound(m.begin(), m.end(), n);
return it-m.begin()-1;
}
剑指 Offer II 072. 求平方根
给定一个非负整数 x ,计算并返回 x 的平方根,即实现 int sqrt(int x) 函数。
正数的平方根有两个,只输出其中的正数平方根。
如果平方根不是整数,输出只保留整数的部分,小数部分将被舍去。
示例 1:
输入: x = 4
输出: 2
示例 2:
输入: x = 8
输出: 2
解释: 8 的平方根是 2.82842...,由于小数部分将被舍去,所以返回 2
提示:
0 <= x <= 231 - 1
我的方法:二分:
注意事项,此处不能用m*m作为判断条件,因为可能会整数越界
如果用m*m,则必须用long long数据类型
int mySqrt(int x) {
if (x<2) return x;
int l=1, r=x, m;
while (l < r) {
m = l + (r - l) / 2;
if (m == x / m) return m;
else if (m > x / m) r = m;
else l = m + 1;
}
return l - 1;
}
复杂度分析
-
时间复杂度: O ( log x ) O(\log x) O(logx),即为二分查找需要的次数。
-
空间复杂度:O(1) 。
进阶:牛顿法
剑指 Offer II 073. 狒狒吃香蕉
狒狒喜欢吃香蕉。这里有 n 堆香蕉,第 i 堆中有 piles[i] 根香蕉。警卫已经离开了,将在 h 小时后回来。
狒狒可以决定她吃香蕉的速度 k (单位:根/小时)。每个小时,她将会选择一堆香蕉,从中吃掉 k 根。如果这堆香蕉少于 k 根,她将吃掉这堆的所有香蕉,然后这一小时内不会再吃更多的香蕉,下一个小时才会开始吃另一堆的香蕉。
狒狒喜欢慢慢吃,但仍然想在警卫回来前吃掉所有的香蕉。
返回她可以在 h 小时内吃掉所有香蕉的最小速度 k(k 为整数)。
示例 1:
输入:piles = [3,6,7,11], h = 8
输出:4
示例 2:
输入:piles = [30,11,23,4,20], h = 5
输出:30
示例 3:
输入:piles = [30,11,23,4,20], h = 6
输出:23
提示:
1 <= piles.length <= 104
piles.length <= h <= 109
1 <= piles[i] <= 109
我的方法:二分
多联想!
对于本题,m的取值范围实际上可以确定下来,即1<=m<=max_element(piles)
因此,我们可以通过遍历m来得到最终答案,这个过程可以用二分搜索来加速运算
int helperMinEatingSpeed(vector<int> piles, int m, int h) {
for (auto& i : piles) {
int tmp = i/m;
h = (i % m!=0)? h - tmp - 1 : h-tmp;
}
return h;
}
int minEatingSpeed(vector<int>& piles, int h) {
int l = 1, r = *(max_element(piles.begin(), piles.end())) + 1, m;
while (l < r) {
m = l + (r - l) / 2;
int tmp = helperMinEatingSpeed(piles, m, h);
if (tmp == 0) r = m;
else if (tmp < 0) {
l = m + 1;
}
else r = m;
}
return l;
}
复杂度分析
时间复杂度: O ( N log W ) O(N \log W) O(NlogW),其中 N 是香蕉堆的数量, W 最大的香蕉堆的大小。
空间复杂度: O ( 1 ) O(1) O(1)。
4. 寻找两个正序数组的中位数
给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。
算法的时间复杂度应该为 O(log (m+n)) 。
示例 1:
输入:nums1 = [1,3], nums2 = [2]
输出:2.00000
解释:合并数组 = [1,2,3] ,中位数 2
示例 2:
输入:nums1 = [1,2], nums2 = [3,4]
输出:2.50000
解释:合并数组 = [1,2,3,4] ,中位数 (2 + 3) / 2 = 2.5
提示:
nums1.length == m
nums2.length == n
0 <= m <= 1000
0 <= n <= 1000
1 <= m + n <= 2000
-106 <= nums1[i], nums2[i] <= 106
思路:二分,舍弃折半区间
要在两个有序数组中,找中位数。
假设两个数组长度大小分别为 m, n,则原问题等价为:
- 如果m+n为奇数,则在两个有序数组中,寻找第 ( m + n ) / / 2 (m+n)//2 (m+n)//2 的数
- 如果m+n为偶数,则在两个有序数组中,寻找第 ( m + n ) / / 2 (m+n)//2 (m+n)//2 与 ( m + n ) / / 2 + 1 (m+n)//2+1 (m+n)//2+1 的数
我们定义一个函数 int getKthElement(int k) 以实现上述功能:
每次划定两个数组中,前 k//2 个值 [idx, idx+k//2-1],比较两个区间终点 idx+k//2-1 的值的大小,每次都能够舍弃小的数组的划定的区间。
class Solution:
def findMedianSortedArrays(self, nums1: List[int], nums2: List[int]) -> float:
def getKthElement(k: int)-> int:
idx1, idx2 = 0, 0
while True:
if idx1==m:
return nums2[idx2+k-1] # 返回区间终点
if idx2==n:
return nums1[idx1+k-1]
if k==1:
return min(nums1[idx1], nums2[idx2])
newIdx1 = min(idx1+k//2-1, m-1)
newIdx2 = min(idx2+k//2-1, n-1)
pivot1, pivot2 = nums1[newIdx1], nums2[newIdx2]
if pivot1<=pivot2:
k -= newIdx1-idx1+1
idx1 = newIdx1+1 # 更新,idx = 区间终点+1
else:
k -= newIdx2-idx2+1
idx2 = newIdx2+1
m, n = len(nums1), len(nums2)
totalLen = m+n
if totalLen%2 == 1:
return getKthElement((totalLen+1)//2)
else:
return (getKthElement(totalLen//2) + getKthElement(totalLen//2+1))/2
复杂度分析
- 时间复杂度: O ( log ( m + n ) ) O(\log(m+n)) O(log(m+n)),其中 m m m 和 n n n 分别是数组 nums 1 \textit{nums}_1 nums1 和 nums 2 \textit{nums}_2 nums2 的长度。初始时有 k = ( m + n ) / 2 k=(m+n)/2 k=(m+n)/2 或 k = ( m + n ) / 2 + 1 k=(m+n)/2+1 k=(m+n)/2+1,每一轮循环可以将查找范围减少一半,因此时间复杂度是 O ( log ( m + n ) ) O(\log(m+n)) O(log(m+n))。
- 空间复杂度: O ( 1 ) O(1) O(1)。
33. 搜索旋转排序数组
整数数组 nums 按升序排列,数组中的值 互不相同 。
在传递给函数之前,nums 在预先未知的某个下标 k(0 <= k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k+1], …, nums[n-1], nums[0], nums[1], …, nums[k-1]](下标 从 0 开始 计数)。例如, [0,1,2,4,5,6,7] 在下标 3 处经旋转后可能变为 [4,5,6,7,0,1,2] 。
给你 旋转后 的数组 nums 和一个整数 target ,如果 nums 中存在这个目标值 target ,则返回它的下标,否则返回 -1 。
你必须设计一个时间复杂度为 O(log n) 的算法解决此问题。
示例 1:
输入:nums = [4,5,6,7,0,1,2], target = 0
输出:4
示例 2:
输入:nums = [4,5,6,7,0,1,2], target = 3
输出:-1
示例 3:
输入:nums = [1], target = 0
输出:-1
思路:二分,只搜索有序的部分
class Solution:
def search(self, nums: List[int], target: int) -> int:
l, r = 0, len(nums)-1
while l<=r:
m = l + (r-l)//2
if nums[m]==target:
return m
elif nums[m]>=nums[0]: # m 在前半部分
if nums[m]>target>=nums[0]: # target在前半部分有序数组中
r = m-1
else:
l = m+1
elif nums[m]<=nums[-1]: # m 在后半部分
if nums[m]<target<=nums[-1]: # target在后半部分有序数组中
l = m+1
else:
r = m-1
return -1
时间复杂度为 O(log n)
排序
剑指 Offer II 074. 合并区间
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间。
示例 1:
输入:intervals = [[1,3],[2,6],[8,10],[15,18]]
输出:[[1,6],[8,10],[15,18]]
解释:区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
示例 2:
输入:intervals = [[1,4],[4,5]]
输出:[[1,5]]
解释:区间 [1,4] 和 [4,5] 可被视为重叠区间。
提示:
1 <= intervals.length <= 104
intervals[i].length == 2
0 <= starti <= endi <= 104
我的方法:排序
注意,sort方法可以对二维数组arr排序,默认取arr[][0]进行比较
[a, b], [c, d]区间合并的二种情况;
- a
aa[a, max(b, d)]
vector<vector<int>> merge(vector<vector<int>>& intervals) {
if (intervals.size()==0) return {};
// auto f = [](vector a, vector b) ->bool { return a[0] < b[0]; };
sort(intervals.begin(), intervals.end());
vector<vector<int>> ans;
ans.push_back(intervals[0]);
int a, b, c, d;
for (int i = 1; i < intervals.size(); i++) {
c = intervals[i][0]; d = intervals[i][1];
a = ans.back()[0], b = ans.back()[1];
if (c <= b) {
ans.back()[1] = max(b, d);
}
else {
ans.push_back(vector<int> {c, d});
}
}
return ans;
}
剑指 Offer II 075. 数组相对排序
给定两个数组,arr1 和 arr2,
arr2 中的元素各不相同
arr2 中的每个元素都出现在 arr1 中
对 arr1 中的元素进行排序,使 arr1 中项的相对顺序和 arr2 中的相对顺序相同。未在 arr2 中出现过的元素需要按照升序放在 arr1 的末尾。
示例:
输入:arr1 = [2,3,1,3,2,4,6,7,9,2,19], arr2 = [2,1,4,3,9,6]
输出:[2,2,2,1,4,3,3,9,6,7,19]
提示:
1 <= arr1.length, arr2.length <= 1000
0 <= arr1[i], arr2[i] <= 1000
arr2 中的元素 arr2[i] 各不相同
arr2 中的每个元素 arr2[i] 都出现在 arr1 中
我的方法:自定义排序,哈希数组映射
vector<int> relativeSortArray(vector<int>& arr1, vector<int>& arr2) {
vector<int> mem(1001);
for (int i = 0; i < arr2.size(); ++i) {
mem[arr2[i]] = i+1;
}
auto f = [&mem](int a, int b)->bool {
if (mem[a] != 0 && mem[b] != 0) return mem[a] < mem[b];
else if (mem[a] != 0 && mem[b] == 0) return true;
else if (mem[a] == 0 && mem[b] != 0) return false;
else return a < b;
};
sort(arr1.begin(), arr1.end(), f);
return arr1;
}
时间复杂度: O ( m log m + n ) O(m \log m + n) O(mlogm+n),其中 m m m 和 n n n 分别是数组 arr 1 \textit{arr}_1 arr1 和 arr 2 \textit{arr}_2 arr2的长度。构造哈希表 rank \textit{rank} rank 的时间复杂度为 O ( n ) O(n) O(n),排序的时间复杂度为 O ( m log m ) O(m \log m) O(mlogm)。
归并排序 (比较占用内存,但效率高且稳定)
**思路:**先将数组通过dfs分成最小单位,回溯的时候,再将二者合并。合并的时候会开辟一个新的数组,用于存放比较排序后的两个对象。如图,8 与 4进行比较,小的放在新数组(绿色的)的第一个。
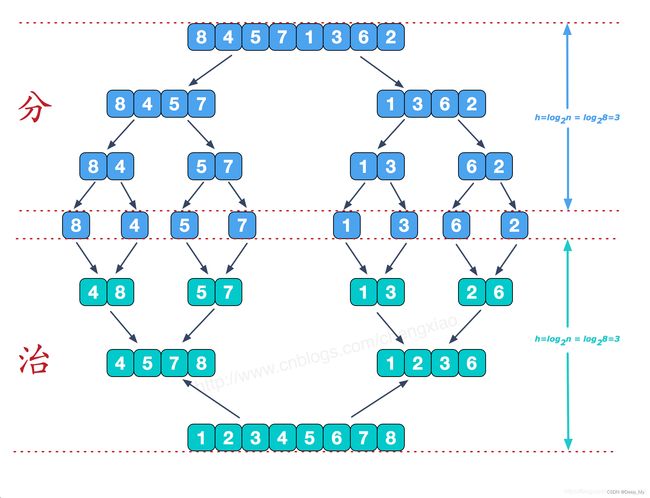
递归实现:
py实现
def mergeSort(nums: list):
def merge(nums1: List[int], nums2: List[int]):
numsTmp = []
m, n = len(nums1), len(nums2)
i, j = 0, 0
while i<m and j<n:
if nums1[i]<nums2[j]:
numsTmp.append(nums1[i])
i += 1
else:
numsTmp.append(nums2[j])
j += 1
if i==m:
numsTmp.extend(nums2[j:])
else:
numsTmp.extend(nums1[i:])
return numsTmp
def dfs(nums: List[int], start: int, end: int):
if start==end:
return [nums[start]]
mid = start+(end-start)//2
fir = dfs(nums, start, mid)
sec = dfs(nums, mid+1, end)
return merge(fir, sec)
return dfs(nums, 0, len(nums)-1)
cpp实现
new(nothrow) 顾名思义,即不抛出异常,当new一个对象失败时,默认设置该对象为NULL,这样可以方便的通过if (p == NULL) 来判断new操作是否成功
void myMerge(int nums[], int l, int m, int r) {
int i = l, j = m + 1, k = 0; // 两个数组起点,以及temp数组的起点
int* temp = new(nothrow) int[r - l + 1];
if (!temp) {
cout << "error! 内存分配失败";
return;
}
while (i <= m && j <= r) {
if (nums[i] > nums[j]) temp[k++] = nums[j++];
else temp[k++] = nums[i++];
}
while (i <= m) temp[k++] = nums[i++];
while (j <= r) temp[k++] = nums[j++];
// 将排序好的临时数组,存回nums中
for (i = l, k = 0; i <= r; i++, k++) nums[i] = temp[k];
delete[]temp;
}
void dfsMergeSort(int nums[], int l, int r) {
if (l < r) {
int m = l + (r - l) / 2;
dfsMergeSort(nums, l, m);
dfsMergeSort(nums, m + 1, r);
myMerge(nums, l, m, r);
}
}
- 时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn),
- 空间复杂度为 O ( n ) O(n) O(n)。
为什么不是 O ( n l o g n ) O(nlogn) O(nlogn)?栈不是需要开辟 O ( l o g n ) O(log n) O(logn)的内存吗,归代码的空间复杂度并不能像时间复杂度那样累加。尽管每次合并操作都需要申请额外的内存空间,但在合并完成之后,临时开辟的内存空间就被释放掉了。在任意时刻,CPU 只会有一个函数在执行,也就只会有一个临时的内存空间在使用。临时内存空间最大也不会超过 n 个数据的大小,所以空间复杂度是 O(n)
非递归
非递归就是先从最底层开始先把数组分割成每个子数组包含两个元素,利用merge方法,对这个子数组进行排序,等这些子数组都排序完成,然后下一轮就是将数组分割成每个子数组包含4个元素,再排序···按照1、2、4、8···顺序来分割,直到最后只剩下一个数组就排序完了
void myMergeSort(int arr[], int n) {// n是数组长度
int idx = 1, l, m, r;
while (idx <= n - 1) { // idx是子数组包含的元素个数
l = 0;
while (l + idx <= n - 1) {
m = l + idx - 1;
r = m + idx;
if (r > n - 1)//第二个序列个数不足size
r = n - 1;
myMerge(arr, l, m, r);//调用归并子函数
l = r + 1;//下一次归并时第一个序列的下界
}
idx <<= 1;//范围扩大一倍
}
}
剑指 Offer II 077. 链表排序
给定链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
示例 1:
输入:head = [4,2,1,3]
输出:[1,2,3,4]
示例 2:
输入:head = [-1,5,3,4,0]
输出:[-1,0,3,4,5]
示例 3:
输入:head = []
输出:[]
提示:
链表中节点的数目在范围 [0, 5 * 104] 内
-105 <= Node.val <= 105
进阶:你可以在 O(n log n) 时间复杂度和常数级空间复杂度下,对链表进行排序吗?
我的方法:冒泡,超时
void swapList(ListNode* a, ListNode* b) {
int tmpNxt = a->val;
a->val = b->val;
b->val = tmpNxt;
}
ListNode* sortList(ListNode* head) {
ListNode* dmyHead = new ListNode(0), *cur1, *cur2, *pre;
cur1 = head;
stack<ListNode*> stk;
while (cur1) {
stk.push(cur1); cur1 = cur1->next;
}
while (!stk.empty()) {
cur1 = head; cur2 = head->next;
while (cur1 != stk.top()) {
if (cur2 && cur1->val > cur2->val) swapList(cur1, cur2);
cur1 = cur1->next;
cur2 = cur2->next;
}
stk.pop();
}
return head;
}
时间复杂度:O(n^2)
时间复杂度是 O ( n log n ) O(n \log n) O(nlogn) 的排序算法包括归并排序、堆排序和快速排序(快速排序的最差时间复杂度是 O ( n 2 ) O(n^2) O(n2),其中最适合链表的排序算法是归并排序。
改进时间:堆排序
注意事项:入堆时,需要将结点间的连接都给打断。(或者使用dummy头结点,将尾结点手动断掉)
- 定义类型为ListNode的最小堆
- 建堆:链表所有node入堆
- 依次弹出堆顶node,即是从小到大的顺序
此法和数组的堆排序几乎没有区别,实现起来最简单,不易出错
ListNode* sortList(ListNode* head) {
if (!head) return head;
auto f = [](ListNode* a, ListNode* b)->bool { return a->val > b->val; };
priority_queue<ListNode*, vector<ListNode*>, decltype(f)> q(f);
ListNode* cur = head, *tmp;
while (cur) {
q.push(cur); tmp = cur->next;
cur->next = nullptr; cur = tmp;
}
head = q.top(); q.pop(); cur = head;
while (!q.empty()) {
cur->next = q.top();
cur = cur->next;
q.pop();
}
return head;
}
- 时间复杂度 O ( n l o g n ) O(nlogn) O(nlogn),
- 空间复杂度 O ( n ) O(n) O(n)
改进空间:自顶向下归并排序
对链表自顶向下归并排序的过程如下。
- 数组的归并排序需要引入辅助数组用于归并,因此空间复杂度是O(n)
- 有序链表的归并不需要额外空间辅助
- 自顶向下,对链表进行排序:
- 若链表结点个数为1或0:
- 已经有序,返回头结点
- 否则
- 用快慢指针法将链表分为两部分,其长度差不超过1
- 对这两部分链表排序(递归)
- 合并排序后的两个链表
- 其实merge函数创建了一条新的链表,通过比较两个需要归并的链表。
- 若链表结点个数为1或0:
ListNode* findMidL(ListNode* head, ListNode* tail) {
ListNode* slow = head;
while (head != tail && head->next != tail) {
head = head->next->next;
slow = slow->next;
}
return slow;
}
ListNode* helpListMerge(ListNode* l, ListNode* r) {
ListNode* dummy, *head;
dummy = new ListNode(0);
head = dummy;
while (l && r) {
if (l->val > r->val) {
dummy->next = r;
r = r->next;
}
else {
dummy->next = l;
l = l->next;
}
dummy = dummy->next;
}
if (l) dummy->next = l;
else dummy->next = r;
return head->next;
}
ListNode* listMergesort(ListNode* l, ListNode* r) {
if (!l) return l;
ListNode* m = findMidL(l, r), * mNxt = m->next;
if (l != r) {
ListNode* tmpl = listMergesort(l, m);
ListNode* tmpr = listMergesort(mNxt, r);
return helpListMerge(tmpl, tmpr);
}
l->next = nullptr;
return l;
}
ListNode* sortList(ListNode* head) {
return listMergesort(head, nullptr);
}
- 时间复杂度 O ( n l o g n ) O(nlogn) O(nlogn),
- 空间复杂度 O ( l o g n ) O(logn) O(logn),即递归调用的深度
进一步优化空间复杂度-自底向上的归并
- 熟悉归并排序的同学应该知道,若采用自底向上归并,可以把递归调用改为迭代,不使用额外空间
- 对于链表,可以把只有1个节点的链表看作有序,即归并的底
- 两个长度为1的链表合并为长度为2的有序链表,两个长度为2的链表合并为长度为4的有序链表,以此类推
- 设归并长度为len,一开始len=1,每进行一轮归并,len*=2,当len>=原始链表长度时,链表排序完成
- 由于链表始终不能断开,因此merge方法中不能用null来判断是否合并完一条链表
- merge方法设计为void Merge(ListNode beforeHead, ListNode mid, ListNode afterTail)
- beforehead用于确定head1和合并的指针位置
- mid是链表2的开始head2,同时也是链表1的结尾哨兵
- afterTail是链表2的结尾哨兵
- 如何确定每次合并的3个参数?
- 对每个len的首次合并,beforeHead为链表头部之前的哨兵节点
- mid为beforeHead后面的第len+1个节点
- afterTail为mid后面的第len个节点
- 使用上述参数完成一个区间的合并
- 下一个区间的beforeHead为beforeHead后面的第len*2个节点
- 以上移动均需注意是否达到链表尾部的null
- 若beforeHead为null,本轮合并完成
ListNode* sortList(ListNode* head) {
if (head == nullptr) {
return head;
}
int length = 0;
ListNode* node = head;
while (node != nullptr) {
length++;
node = node->next;
}
ListNode* dummyHead = new ListNode(0, head);
for (int subLength = 1; subLength < length; subLength <<= 1) {
ListNode* prev = dummyHead, *curr = dummyHead->next;
while (curr != nullptr) {
ListNode* head1 = curr;
for (int i = 1; i < subLength && curr->next != nullptr; i++) {
curr = curr->next;
}
ListNode* head2 = curr->next;
curr->next = nullptr;
curr = head2;
for (int i = 1; i < subLength && curr != nullptr && curr->next != nullptr; i++) {
curr = curr->next;
}
ListNode* next = nullptr;
if (curr != nullptr) {
next = curr->next;
curr->next = nullptr;
}
ListNode* merged = helpListMerge(head1, head2);
prev->next = merged;
while (prev->next != nullptr) {
prev = prev->next;
}
curr = next;
}
}
return dummyHead->next;
}
- 时间复杂度O(nlogn),
- 空间复杂度O(1),只使用了几个变量和1层函数调用
剑指 Offer II 078. 合并排序链表
给定一个链表数组,每个链表都已经按升序排列。
请将所有链表合并到一个升序链表中,返回合并后的链表。
示例 1:
输入:lists = [[1,4,5],[1,3,4],[2,6]]
输出:[1,1,2,3,4,4,5,6]
解释:链表数组如下:
[
1->4->5,
1->3->4,
2->6
]
将它们合并到一个有序链表中得到。
1->1->2->3->4->4->5->6
示例 2:
输入:lists = []
输出:[]
示例 3:
输入:lists = [[]]
输出:[]
提示:
k == lists.length
0 <= k <= 10^4
0 <= lists[i].length <= 500
-10^4 <= lists[i][j] <= 10^4
lists[i] 按 升序 排列
lists[i].length 的总和不超过 10^4
我的方法:自底向上的归并排序,同上题第3种解法
如图,每次将相邻的两个合并,并把多余的vector空间pop掉即可,最后vector只剩1个元素时返回最终答案
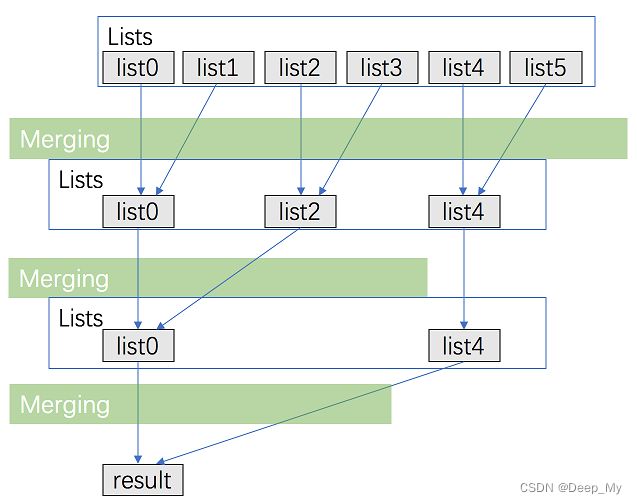
ListNode* helpMergeKlist(ListNode* l, ListNode* r) {
ListNode* dummyNode = new ListNode(0), * head = dummyNode;
while (l && r) {
if (l->val <= r->val) {
dummyNode->next = l;
l = l->next;
}
else {
dummyNode->next = r;
r = r->next;
}
dummyNode = dummyNode->next;
}
if (l) dummyNode->next = l;
else dummyNode->next = r;
return head->next;
}
ListNode* mergeKLists(vector<ListNode*>& lists) {
int n, k, i;
if (lists.size() == 0) return nullptr;
while (lists.size() > 1) {
n = lists.size();
for (i = 0, k=0; i < n; i = i + 2, k++) {
if (i == n - 1) lists[k] = lists[i];
else lists[k] = helpMergeKlist(lists[i], lists[i + 1]);
}
/*lists.assign(lists.begin(), lists.begin() + k - 1);*/
for (k; k < n; k++) lists.pop_back();
}
return lists.back();
}
复杂度分析
- 时间复杂度:考虑递归「向上回升」的过程——第一轮合并 k 2 \frac{k}{2} 2k 组链表,每一组的时间代价是 O ( 2 n ) O(2n) O(2n);第二轮合并 k 4 \frac{k}{4} 4k组链表,每一组的时间代价是 O ( 4 n ) O(4n) O(4n)…所以总的时间代价是 O ( ∑ i = 1 ∞ k 2 i × 2 i n ) = O ( k n × log k ) O(\sum_{i = 1}^{\infty} \frac{k}{2^i} \times 2^i n) = O(kn \times \log k) O(∑i=1∞2ik×2in)=O(kn×logk),故渐进时间复杂度为 O ( k n × log k ) O(kn \times \log k) O(kn×logk)。
- 空间复杂度: O ( 1 ) O(1) O(1) 空间代价。
当然还有其他方法,例如优先队列、递归归并等等
剑指 Offer 51. 数组中的逆序对
在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数。
示例 1:
输入: [7,5,6,4]
输出: 5
限制:
0 <= 数组长度 <= 50000
思路:归并排序
求逆序对和归并排序又有什么关系呢?关键就在于 M e r g e Merge Merge 的过程。
只在 l P t r l_{Ptr} lPtr 右移的时候计算,是基于这样的事实:当前 l P t r l_{Ptr} lPtr 指向的数字比 r P t r r_{Ptr} rPtr 小,但是比 R R R 中 [ 0... r P t r − 1 ] [0 ... rPtr - 1] [0...rPtr−1] 的其他数字大, [ 0... r P t r − 1 ] [0 ... r_{Ptr} - 1] [0...rPtr−1] 的其他数字本应当排在 l P t r l_{Ptr} lPtr 对应数字的左边,但是它排在了右边,所以这里就贡献了 r P t r r_{Ptr} rPtr 个逆序对。
class Solution:
def reversePairs(self, nums: List[int]) -> int:
n = len(nums)
if n<2:
return 0
ans = [0]
def merge(left: list, right: list):
tmp = []
l, r = 0, 0
while l<len(left) and r<len(right):
if left[l]<=right[r]:
tmp.append(left[l])
l += 1
ans[0] += r #
else:
tmp.append(right[r])
r += 1
while l<len(left):
tmp.append(left[l])
l += 1
ans[0] += r #
while r<len(right):
tmp.append(right[r])
r += 1
return tmp
def dfs(l: int, r: int):
if l==r:
return [nums[l]]
m = l + (r-l)//2
left = dfs(l, m)
right = dfs(m+1, r)
return merge(left, right)
dfs(0, len(nums)-1)
return ans[0]
- 时间复杂度:同归并排序 O ( n log n ) O(n \log n) O(nlogn)
- 空间复杂度:同归并排序 O ( n ) O(n) O(n),因为归并排序需要用到一个临时数组。
769. 最多能完成排序的块
给定一个长度为 n 的整数数组 arr ,它表示在 [0, n - 1] 范围内的整数的排列。
我们将 arr 分割成若干 块 (即分区),并对每个块单独排序。将它们连接起来后,使得连接的结果和按升序排序后的原数组相同。
返回数组能分成的最多块数量。
示例 1:
输入: arr = [4,3,2,1,0]
输出: 1
解释:
将数组分成2块或者更多块,都无法得到所需的结果。
例如,分成 [4, 3], [2, 1, 0] 的结果是 [3, 4, 0, 1, 2],这不是有序的数组。
示例 2:
输入: arr = [1,0,2,3,4]
输出: 4
解释:
我们可以把它分成两块,例如 [1, 0], [2, 3, 4]。
然而,分成 [1, 0], [2], [3], [4] 可以得到最多的块数。
提示:
n == arr.length
1 <= n <= 10
0 <= arr[i] < n
arr 中每个元素都 不同
我的思路一:TreeSet + 双指针
双指针 l,r 维护一个区间,每次判断区间内,treeset的值,是否与排序后的值相等
如果不相等,则扩大区间
class Solution:
def maxChunksToSorted(self, arr: List[int]) -> int:
from sortedcontainers import SortedSet
ans = sorted(arr)
numSet = SortedSet()
l, r = 0, 1
cnt = 0
while l<len(arr):
numSet.add(arr[l])
while r<len(arr) and list(numSet)[l:r]!=ans[l:r]:
numSet.add(arr[r])
r += 1
cnt += 1
l = r
r = l+1
return cnt
时间复杂度: O ( n 2 log ( n ) ) O(n^2 \log(n)) O(n2log(n))
优化时间
由于 arr 的长度最大为10,因此我们可以用一个二维数组保存 Tree Set 每次存入arr一个元素后的排序数组。
双指针直接查询数组即可
class Solution:
def maxChunksToSorted(self, arr: List[int]) -> int:
from sortedcontainers import SortedSet
ans = sorted(arr)
numSet = SortedSet()
l, r = 0, 1
cnt = 0
vis = []
for i in range(len(arr)):
numSet.add(arr[i])
vis.append(list(numSet))
while l<len(arr):
while r<len(arr) and vis[r-1][l:r]!=ans[l:r]:
r += 1
cnt += 1
l = r
r = l+1
return cnt
时间复杂度: O ( n log ( n ) ) O(n \log(n)) O(nlog(n))
回溯(二叉树、多叉树)
【二叉树&多叉树回溯】
这类回溯问题根据当前元素选取逻辑,搜索树通常可以构建为二叉树和多叉树。二叉树就是选与不选,多叉树就是依次选取。

【二叉树回溯】
当前数字选与不选,构建出回溯用的二叉树。套用二叉树回溯模板就好,一般会在dfs方法里传一个索引idx参数(数组下标),这样比较清晰易读。
【多叉树回溯】
回溯方法的主体是一个for循环,考察从当前(可通过函数传递索引)数字到最后一个数字
剑指 Offer II 079. 所有子集
给定一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例 1:
输入:nums = [1,2,3]
输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
示例 2:
输入:nums = [0]
输出:[[],[0]]
提示:
1 <= nums.length <= 10
-10 <= nums[i] <= 10
nums 中的所有元素 互不相同
方法一:迭代法 + 状态压缩 + bit运算
记原序列中元素的总数为 n n n。原序列中的每个数字 a i a_i ai 的状态可能有两种,即「在子集中」和「不在子集中」。我们用 1 1 1 表示「在子集中」, 0 0 0 表示不在子集中,那么每一个子集可以对应一个长度为 n n n 的 0 / 1 0/1 0/1 序列,第 i i i 位表示 a i a_i ai是否在子集中。例如, n = 3 n = 3 n=3 , a = { 5 , 2 , 9 } a = \{ 5, 2, 9 \} a={5,2,9} 时:
| 0 / 1 0/1 0/1序列 | 子集 | 0 / 1 0/1 0/1 序列对应的二进制数 |
|---|---|---|
| 000 000 000 | { } \{ \} {} | 0 0 0 |
| 001 001 001 | { 9 } \{ 9 \} {9} | 1 1 1 |
| 010 010 010 | { 2 } \{ 2 \} {2} | 2 2 2 |
| 011 011 011 | { 2 , 9 } \{ 2, 9 \} {2,9} | 3 3 3 |
| 100 100 100 | { 5 } \{ 5 \} {5} | 4 4 4 |
| 101 101 101 | { 5 , 9 } \{ 5, 9 \} {5,9} | 5 5 5 |
| 110 110 110 | { 5 , 2 } \{ 5, 2 \} {5,2} | 6 6 6 |
| 111 111 111 | { 5 , 2 , 9 } \{ 5, 2, 9 \} {5,2,9} | 7 7 7 |
可以发现 0 / 1 0/1 0/1 序列对应的二进制数正好从 0 0 0 到 2 n − 1 2^n - 1 2n−1。我们可以枚举 mask ∈ [ 0 , 2 n − 1 ] \textit{mask} \in [0, 2^n - 1] mask∈[0,2n−1], mask \textit{mask} mask 的二进制表示是一个 0 / 1 0/1 0/1 序列,我们可以按照这个 0 / 1 0/1 0/1 序列在原集合当中取数。当我们枚举完所有 2 n 2^n 2n个 mask \textit{mask} mask ,我们也就能构造出所有的子集。
vector<vector<int>> subsets(vector<int>& nums) {
vector<vector<int>> ans;
int n = nums.size();
int nu = 1 << n;
vector<int> tmp;
for (int mask = 0; mask < nu; mask++) {
tmp.clear();
for (int i = 0; i < n; ++i) { // 遍历每一位
if (mask & (1 << i)) tmp.push_back(nums[i]);
}
ans.push_back(tmp);
}
return ans;
}
复杂度分析
- 时间复杂度: O ( n × 2 n ) O(n \times 2^n) O(n×2n)。一共 2 n 2^n 2n个状态,每种状态需要 O ( n ) O(n) O(n) 的时间来构造子集。
- 空间复杂度: O ( n ) O(n) O(n)。即构造子集使用的临时数组 t t t 的空间代价。
方法二:DFS递归
我们也可以用递归来实现子集枚举。
假设我们需要找到一个长度为 n n n 的序列 a a a 的所有子序列,代码框架是这样的:
vector<int> t;
void dfs(int cur, int n) {
if (cur == n) {
// 记录答案
// ...
return;
}
// 考虑选择当前位置
t.push_back(cur);
dfs(cur + 1, n, k);
t.pop_back();
// 考虑不选择当前位置
dfs(cur + 1, n, k);
}
上面的代码中, dfs ( cur , n ) \text{dfs}(\textit{cur}, n) dfs(cur,n) 参数表示当前位置是 cur \textit{cur} cur,原序列总长度为 n n n。原序列的每个位置在答案序列中的状态有被选中和不被选中两种,我们用 t t t 数组存放已经被选出的数字。
在进入 dfs ( cur , n ) \text{dfs}(\textit{cur}, n) dfs(cur,n) 之前 [ 0 , cur − 1 ] [0, \textit{cur} - 1] [0,cur−1] 位置的状态是确定的,而 [ cur , n − 1 ] [\textit{cur}, n - 1] [cur,n−1] 内位置的状态是不确定的, dfs ( cur , n ) \text{dfs}(\textit{cur}, n) dfs(cur,n) 需要确定 cur \textit{cur} cur 位置的状态,然后求解子问题 dfs ( c u r + 1 , n ) {\text{dfs}(cur + 1}, n) dfs(cur+1,n)。
对于 cur \textit{cur} cur 位置,我们需要考虑 a [ cur ] a[\textit{cur}] a[cur] 取或者不取,如果取,我们需要把 a [ cur ] a[\textit{cur}] a[cur] 放入一个临时的答案数组中(即上面代码中的 t t t),再执行 dfs ( c u r + 1 , n ) {\text{dfs}(cur + 1}, n) dfs(cur+1,n),执行结束后需要对 t t t 进行回溯;如果不取,则直接执行 dfs ( c u r + 1 , n ) {\text{dfs}(cur + 1}, n) dfs(cur+1,n)。在整个递归调用的过程中, cur \textit{cur} cur 是从小到大递增的,当 cur \textit{cur} cur 增加到 n n n 的时候,记录答案并终止递归。可以看出二进制枚举的时间复杂度是 O ( 2 n ) O(2 ^ n) O(2n)。
vector<int> t;
vector<vector<int>> ans;
void dfs(int cur, vector<int>& nums) {
if (cur == nums.size()) {
ans.push_back(t);
return;
}
t.push_back(nums[cur]);
dfs(cur + 1, nums);
t.pop_back();
dfs(cur + 1, nums);
}
vector<vector<int>> subsets(vector<int>& nums) {
dfs(0, nums);
return ans;
}
复杂度分析
- 时间复杂度: O ( n × 2 n ) O(n \times 2 ^ n) O(n×2n)。一共 2 n 2^n 2n个状态,每种状态需要 O ( n ) O(n) O(n) 的时间来构造子集。
- 空间复杂度: O ( n ) O(n) O(n)。临时数组 t t t 的空间代价是 O ( n ) O(n) O(n),递归时栈空间的代价为 O ( n ) O(n) O(n)。
剑指 Offer II 080. 含有 k 个元素的组合
给定两个整数 n 和 k,返回 1 … n 中所有可能的 k 个数的组合。
示例 1:
输入: n = 4, k = 2
输出:
[
[2,4],
[3,4],
[2,3],
[1,2],
[1,3],
[1,4],
]
示例 2:
输入: n = 1, k = 1
输出: [[1]]
提示:
1 <= n <= 20
1 <= k <= n
我的方法:DFS,同上题
void dfsCombine(vector<vector<int>>& ans, vector<int>& tmp, int& k, int& n, int cur) {
// 剪枝:tmp 长度加上区间 [cur, n] 的长度小于 k,不可能构造出长度为 k 的 temp
if (tmp.size() + (n - cur + 1) < k) {
return;
}
if (tmp.size() == k) {
ans.push_back(tmp);
return;
}
if (cur > n) return; // 无用,包含在剪枝条件中了
tmp.push_back(cur);
dfsCombine(ans, tmp, k, n, cur + 1);
tmp.pop_back();
dfsCombine(ans, tmp, k, n, cur + 1);
}
vector<vector<int>> combine(int n, int k) {
vector<vector<int>> ans;
vector<int> tmp;
dfsCombine(ans, tmp, k, n, 1);
return ans;
}
复杂度分析
- 时间复杂度: O ( ( n k ) × k ) O({n \choose k} \times k) O((kn)×k)。
- 空间复杂度: O ( n + k ) = O ( n ) O(n + k) = O(n) O(n+k)=O(n),即递归使用栈空间的空间代价和临时数组 temp \textit{temp} temp 的空间代价。
方法二:非递归(字典序法)实现组合型枚举
思路与算法
小贴士:这个方法理解起来比「方法一」复杂,建议读者遇到不理解的地方可以在草稿纸上举例模拟这个过程。
这里的非递归版不是简单的用栈模拟递归转化为非递归:我们希望通过合适的手段,消除递归栈带来的额外空间代价。
假设我们把原序列中被选中的位置记为 11,不被选中的位置记为 00,对于每个方案都可以构造出一个二进制数。我们让原序列从大到小排列(即 { n , n − 1 , ⋯ 1 , 0 } \{ n, n - 1, \cdots 1, 0 \} {n,n−1,⋯1,0})。我们先看一看 n = 4 n = 4 n=4, k = 2 k = 2 k=2 的例子:
| 原序列中被选中的数 | 对应的二进制数 | 方案 |
|---|---|---|
| 43 [ 2 ] [ 1 ] 43[2][1] 43[2][1] | 0011 0011 0011 | 2 , 1 2,1 2,1 |
| 4 [ 3 ] 2 [ 1 ] 4[3]2[1] 4[3]2[1] | 0101 0101 0101 | 3 , 1 3, 1 3,1 |
| 4 [ 3 ] [ 2 ] 1 4[3][2]1 4[3][2]1 | 0110 0110 0110 | 3 , 2 3, 2 3,2 |
| [ 4 ] 32 [ 1 ] [4]32[1] [4]32[1] | 1001 1001 1001 | 4 , 1 4, 1 4,1 |
| [ 4 ] 3 [ 2 ] 1 [4]3[2]1 [4]3[2]1 | 1010 1010 1010 | 4 , 2 4, 2 4,2 |
| [ 4 ] [ 3 ] 21 [4][3]21 [4][3]21 | 1100 1100 1100 | 4 , 3 4, 3 4,3 |
我们可以看出「对应的二进制数」一列包含了由 k k k 个 1 1 1 和 n − k n - k n−k 个 0 0 0 组成的所有二进制数,并且按照字典序排列。这给了我们一些启发,我们可以通过某种方法枚举,使得生成的序列是根据字典序递增的。我们可以考虑我们一个二进制数数字 x x x,它由 k k k 个 1 1 1 和 n − k n - k n−k 个 0 0 0 组成,如何找到它的字典序中的下一个数字 n e x t ( x ) {next}(x) next(x),这里分两种情况:
规则一: x x x 的最低位为 1 1 1,这种情况下,如果末尾由 t t t 个连续的 1 1 1,我们直接将倒数第 t t t 位的 1 1 1 和倒数第 t + 1 t + 1 t+1 位的 0 0 0 替换,就可以得到 n e x t ( x ) {next}(x) next(x)。如 0011 → 0101 0011 \rightarrow 0101 0011→0101, 0101 → 0110 0101 \rightarrow 0110 0101→0110, 1001 → 1010 1001 \rightarrow 1010 1001→1010, 1001111 → 1010111 1001111 \rightarrow 1010111 1001111→1010111。
规则二: x x x 的最低位为 0 0 0,这种情况下,末尾有 t t t 个连续的 0 0 0,而这 t t t 个连续的 0 0 0 之前有 m m m 个连续的 1 1 1,我们可以将倒数第 t + m t + m t+m 位置的 1 1 1 和倒数第 t + m + 1 t + m + 1 t+m+1 位的 0 0 0 对换,然后把倒数第 t + 1 t + 1 t+1 位到倒数第 t + m − 1 t + m - 1 t+m−1 位的 1 1 1 移动到最低位。如 0110 → 1001 0110 \rightarrow 1001 0110→1001, 1010 → 1100 1010 \rightarrow 1100 1010→1100, 1011100 → 1100011 1011100 \rightarrow 1100011 1011100→1100011。
至此,我们可以写出一个朴素的程序,用一个长度为 n n n 的 0 / 1 0/1 0/1 数组来表示选择方案对应的二进制数,初始状态下最低的 k k k 位全部为 1 1 1,其余位置全部为 0 0 0,然后不断通过上述方案求 n e x t next next,就可以构造出所有的方案。
我们可以进一步优化实现,我们来看 n = 5 n = 5 n=5, k = 3 k = 3 k=3 的例子,根据上面的策略我们可以得到这张表:
| 二进制数 | 方案 |
|---|---|
| 00111 00111 00111 | 3 , 2 , 1 3, 2, 1 3,2,1 |
| 01011 01011 01011 | 4 , 2 , 1 4, 2, 1 4,2,1 |
| 01101 01101 01101 | 4 , 3 , 1 4, 3, 1 4,3,1 |
| 01110 01110 01110 | 4 , 3 , 2 4, 3, 2 4,3,2 |
| 10011 10011 10011 | 5 , 2 , 1 5, 2, 1 5,2,1 |
| 10101 10101 10101 | 5 , 3 , 1 5, 3, 1 5,3,1 |
| 10110 10110 10110 | 5 , 3 , 2 5, 3, 2 5,3,2 |
| 11001 11001 11001 | 5 , 4 , 1 5, 4, 1 5,4,1 |
| 11010 11010 11010 | 5 , 4 , 2 5, 4, 2 5,4,2 |
| 11100 11100 11100 | 5 , 4 , 3 5, 4, 3 5,4,3 |
在朴素的方法中我们通过二进制数来构造方案,而二进制数是需要通过迭代的方法来获取 n e x t next next 的。考虑不通过二进制数,直接在方案上变换来得到下一个方案。假设一个方案从低到高的 k k k 个数分别是 { a 0 , a 1 , ⋯ , a k − 1 } \{ a_0, a_1, \cdots, a_{k - 1} \} {a0,a1,⋯,ak−1},我们可以从低位向高位找到第一个 j j j 使得 a j + 1 ≠ a j + 1 a_{j} + 1 \neq a_{j + 1} aj+1=aj+1,我们知道出现在 a a a 序列中的数字在二进制数中对应的位置一定是 1 1 1,即表示被选中,那么 a j + 1 ≠ a j + 1 a_{j} + 1 \neq a_{j + 1} aj+1=aj+1 意味着 a j a_j aj 和 a j + 1 a_{j + 1} aj+1 对应的二进制位中间有 0 0 0,即这两个 1 1 1 不连续。我们把 a j a_j aj 对应的 1 1 1 向高位推送,也就对应着 a j ← a j + 1 a_j \leftarrow a_j + 1 aj←aj+1,而对于 i ∈ [ 0 , j − 1 ] i \in [0, j - 1] i∈[0,j−1] 内所有的 a i a_i ai 把值恢复成 i + 1 i + 1 i+1,即对应这 j j j 个 1 1 1 被移动到了二进制数的最低 j j j 位。这似乎只考虑了上面的「规则二」。但是实际上**「规则一」是「规则二」在 t = 0 t = 0 t=0 时的特殊情况**,因此这么做和按照两条规则模拟是等价的。
在实现的时候,我们可以用一个数组 temp \textit{temp} temp 来存放 a a a 序列,一开始我们先把 1 1 1 到 k k k 按顺序存入这个数组,他们对应的下标是 0 0 0 到 k − 1 k - 1 k−1。为了计算的方便,我们需要在下标 k k k 的位置放置一个哨兵 n + 1 n + 1 n+1(思考题:为什么是 n + 1 n + 1 n+1 呢?)。然后对这个 temp \textit{temp} temp 序列按照这个规则进行变换,每次把前 k k k 位(即除了最后一位哨兵)的元素形成的子数组加入答案。每次变换的时候,我们把第一个 a j + 1 ≠ a j + 1 a_{j} + 1 \neq a_{j + 1} aj+1=aj+1 的 j j j 找出,使 a j a_j aj 自增 1 1 1,同时对 i ∈ [ 0 , j − 1 ] i \in [0, j - 1] i∈[0,j−1] 的 a i a_i ai 重新置数。如此循环,直到 temp \textit{temp} temp 中的所有元素为 n n n 内最大的 k k k 个元素。
回过头看这个思考题,它是为了我们判断退出条件服务的。我们如何判断枚举到了终止条件呢?其实不是直接通过 temp \textit{temp} temp 来判断的,我们会看每次找到的 j j j 的位置,如果 j = k j = k j=k 了,就说明 [ 0 , k − 1 ] [0, k - 1] [0,k−1] 内的所有的数字是比第 k k k 位小的最后 k k k 个数字,这个时候我们找不到任何方案的字典序比当前方案大了,结束枚举。
vector<int> temp;
vector<vector<int>> ans;
vector<vector<int>> combine(int n, int k) {
// 初始化
// 将 temp 中 [0, k - 1] 每个位置 i 设置为 i + 1,即 [0, k - 1] 存 [1, k]
// 末尾加一位 n + 1 作为哨兵
for (int i = 1; i <= k; ++i) {
temp.push_back(i);
}
temp.push_back(n + 1);
int j = 0;
while (j < k) {
ans.emplace_back(temp.begin(), temp.begin() + k);
j = 0;
// 寻找第一个 temp[j] + 1 != temp[j + 1] 的位置 t
// 我们需要把 [0, t - 1] 区间内的每个位置重置成 [1, t]
while (j < k && temp[j] + 1 == temp[j + 1]) {
temp[j] = j + 1;
++j;
}
// j 是第一个 temp[j] + 1 != temp[j + 1] 的位置
++temp[j];
}
return ans;
}
复杂度分析
- 时间复杂度: O ( ( n k ) × k ) O({n \choose k} \times k) O((kn)×k)。外层循环的执行次数是 ( n k ) n \choose k (kn) 次,每次需要做一个 O ( k ) O(k) O(k) 的添加答案和 O ( k ) O(k) O(k) 的内层循环,故时间复杂度 O ( ( n k ) × k ) O({n \choose k} \times k) O((kn)×k)。
- 空间复杂度: O ( k ) O(k) O(k)。即 temp \textit{temp} temp 的空间代价。
剑指 Offer II 081. 允许重复选择元素的组合
给定一个无重复元素的正整数数组 candidates 和一个正整数 target ,找出 candidates 中所有可以使数字和为目标数 target 的唯一组合。
candidates 中的数字可以无限制重复被选取。如果至少一个所选数字数量不同,则两种组合是不同的。
对于给定的输入,保证和为 target 的唯一组合数少于 150 个。
示例 1:
输入: candidates = [2,3,6,7], target = 7
输出: [[7],[2,2,3]]
示例 2:
输入: candidates = [2,3,5], target = 8
输出: [[2,2,2,2],[2,3,3],[3,5]]
示例 3:
输入: candidates = [2], target = 1
输出: []
示例 4:
输入: candidates = [1], target = 1
输出: [[1]]
示例 5:
输入: candidates = [1], target = 2
输出: [[1,1]]
提示:
1 <= candidates.length <= 30
1 <= candidates[i] <= 200
candidate 中的每个元素都是独一无二的。
1 <= target <= 500
我的方法,多叉树回溯 + 剪枝, 70ms
dfsCombinationSum 返回的是,当前组合是否满足条件
vector 用于记录组合元素出现的频次
set 防止添加重复组合
bool dfsCombinationSum(set<vector<int>>& vis, vector<int>& vt, vector<int>& candidates, vector<int>& tmp, vector<vector<int>>& ans, int target, int i) {
if (target < 0) {
return false;
}
if (target == 0) {
if (!vis.count(vt)) {
ans.push_back(tmp);
vis.insert(vt);
}
return true;
}
for (int i = 0; i < candidates.size(); i++) {
tmp.push_back(candidates[i]);
vt[candidates[i]]++;
if (!dfsCombinationSum(vis, vt, candidates, tmp, ans, target - candidates[i], i)) {
tmp.pop_back();
vt[candidates[i]]--;
break; // 如果当前满足,则后面的元素不用比较了,因为candidates排序了
}
tmp.pop_back();
vt[candidates[i]]--;
}
return true;
}
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
vector<vector<int>> ans;
sort(candidates.begin(), candidates.end());
vector<int> tmp; int n = candidates.size();
set<vector<int>> vis;
vector<int> vt(201);
dfsCombinationSum(vis, vt, candidates, tmp, ans, target, 0);
return ans;
}
多叉树优化, 0ms
vector set 这两个东西,是造成时间复杂度高的主要因素(set的操作log n)
因此考虑如何才能避免使用备忘录。
回顾使用备忘录的原因:防止ans出现[[2,2,3], [2,3,2], [3,2,2]] 这种情况
产生该情况的主要原因是 for (int i = 0; i < candidates.size(); i++) dfs递归的时候,每次都是从头开始遍历,因此会重复选择2, 3很多次。
我们可不可以使得dfs遍历只能按某种顺序进行呢?比如说2走完了,我开始走3,但是我的3不能往小的走,只能往大的走,这样就能够避免重复情况的出现
因此,我们将数组索引作为dfs参数,只有回溯时,才能往大了走;
其他情况dfsCombinationSum(candidates, tmp, ans, target - candidates[i], i) 我们只递归当前位置索引。
bool dfsCombinationSum(vector<int>& candidates, vector<int>& tmp, vector<vector<int>>& ans, int target, int i) {
if (target < 0) {
return false;
}
if (target == 0) {
ans.push_back(tmp);
return true;
}
for (; i < candidates.size(); i++) {
tmp.push_back(candidates[i]);
if (!dfsCombinationSum(candidates, tmp, ans, target - candidates[i], i)) {
tmp.pop_back();
break;
}
tmp.pop_back();
}
return true;
}
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
vector<vector<int>> ans;
sort(candidates.begin(), candidates.end());
vector<int> tmp; int n = candidates.size();
dfsCombinationSum(candidates, tmp, ans, target, 0);
return ans;
}
二叉树回溯
未使用排序剪枝
class Solution {
private:
vector<vector<int>> res;
vector<int> tmp;
public:
void dfs(vector<int>& candidates, int i, int target)
{
if (target == 0)
{
res.push_back(tmp);
}
else if (target > 0 && i < candidates.size())
{
tmp.push_back(candidates[i]);
dfs(candidates, i, target - candidates[i]); //重复选当前元素
tmp.pop_back();
dfs(candidates, i + 1, target); //不选当前元素
}
}
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
dfs(candidates, 0, target);
return res;
}
};
剑指 Offer II 082. 含有重复元素集合的组合
给定一个可能有重复数字的整数数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的每个数字在每个组合中只能使用一次,解集不能包含重复的组合。
示例 1:
输入: candidates = [10,1,2,7,6,1,5], target = 8,
输出:
[
[1,1,6],
[1,2,5],
[1,7],
[2,6]
]
示例 2:
输入: candidates = [2,5,2,1,2], target = 5,
输出:
[
[1,2,2],
[5]
]
提示:
1 <= candidates.length <= 100
1 <= candidates[i] <= 50
1 <= target <= 30
我的方法:二叉树回溯,排序,set备忘录, 500ms
将vector排序,则重复的数字一定相邻,
void dfscombinationSum2(set<vector<int>>& s, vector<int>& nums, vector<int>& t, vector<vector<int>>& ans, int target, int idx) {
if (target < 0) return;
if (target == 0 && !s.count(t)) {
ans.push_back(t);
s.insert(t);
return;
}
if (idx == nums.size()) return;
t.push_back(nums[idx]);
dfscombinationSum2(s, nums, t, ans, target - nums[idx], idx + 1);
t.pop_back();
dfscombinationSum2(s, nums, t, ans, target, idx + 1);
return;
}
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
vector<vector<int>> ans;
sort(candidates.begin(), candidates.end());
vector<int> tmp;
set<vector<int>> s;
dfscombinationSum2(s, candidates, tmp, ans, target, 0);
return ans;
}
多叉树回溯,4ms
:if (i > idx && nums[i] == nums[i - 1]) continue; 保证了与父节点相同时,不跳;只在相同层级的节点中比较。
bool dfscombinationSum2(vector<int>& nums, vector<int>& t, vector<vector<int>>& ans, int target, int idx) {
if (target < 0) return false;
if (target == 0) {
ans.push_back(t);
return true;
}
for (int i = idx; i < nums.size(); i++) {
if (i > idx && nums[i] == nums[i - 1]) continue; //
t.push_back(nums[i]);
if (dfscombinationSum2(nums, t, ans, target - nums[i], i + 1)) {
t.pop_back();
break;
}
t.pop_back();
}
return false;
}
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
vector<vector<int>> ans;
sort(candidates.begin(), candidates.end());
vector<int> tmp;
dfscombinationSum2(candidates, tmp, ans, target, 0);
return ans;
}
剑指 Offer II 083. 没有重复元素集合的全排列
给定一个不含重复数字的整数数组 nums ,返回其 所有可能的全排列 。可以 按任意顺序 返回答案。
示例 1:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
示例 2:
输入:nums = [0,1]
输出:[[0,1],[1,0]]
示例 3:
输入:nums = [1]
输出:[[1]]
提示:
1 <= nums.length <= 6
-10 <= nums[i] <= 10
nums 中的所有整数 互不相同
我的方法:多叉树回溯
对于全排列,与顺序有关,多叉树回溯+备忘录即可
void dfsPermute(vector<int>& nums, vector<vector<int>> & ans, vector<int>& t, int (&vis)[21], int size) {
if (size == nums.size()) {
ans.push_back(t);
return;
}
for (auto& i : nums) {
if (vis[i+10] != 0) continue;
vis[i + 10]++;
t.push_back(i);
dfsPermute(nums, ans, t, vis, size+1);
t.pop_back();
vis[i + 10]--;
}
}
vector<vector<int>> permute(vector<int>& nums) {
int vis[21] = {};
vector<vector<int>> ans; vector<int> t;
dfsPermute(nums, ans, t, vis, 0);
return ans;
}
剑指 Offer II 084. 含有重复元素集合的全排列
给定一个可包含重复数字的整数集合 nums ,按任意顺序 返回它所有不重复的全排列。
示例 1:
输入:nums = [1,1,2]
输出:
[[1,1,2],
[1,2,1],
[2,1,1]]
示例 2:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
提示:
1 <= nums.length <= 8
-10 <= nums[i] <= 10
同上,属于升级版:多叉树+vis+排序去重
void dfsPermuteUnique(vector<int>& nums, vector<vector<int>>& ans, vector<int>& t, int(&vis2)[21], int size) {
if (size == nums.size()) {
ans.push_back(t);
return;
}
for (int i = 0; i < nums.size(); i++) {
if (vis2[i]!=0 || (i > 0 && nums[i] == nums[i - 1] && vis[i - 1] != 0)) {
continue; // 排序后,当相邻数字重复时,判断跳过
}
vis2[i]++;
t.push_back(nums[i]);
dfsPermuteUnique(nums, ans, t, vis2, size + 1);
t.pop_back();
vis2[i]--;
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
int vis2[21] = {};
int a = 0;
sort(nums.begin(), nums.end());
vector<vector<int>> ans; vector<int> t;
dfsPermuteUnique(nums, ans, t, vis2, 0);
return ans;
}
方法二:多叉树回溯 + set 去重
vis 用于剪枝相同的 set
vis2 用于防止重复选择同一位置元素
def permuteUnique(self, nums: List[int]) -> List[List[int]]:
ans = set()
vis2 = set()
vis = set()
def dfs(depth: int, tmp: tuple):
if depth==len(nums):
ans.add(tmp)
return
if tmp in vis:
return
for i, it in enumerate(nums):
if i in vis2:
continue
lst = list(tmp)
lst.append(it)
vis2.add(i)
dfs(depth+1, tuple(lst))
vis2.remove(i)
vis.add(tmp)
dfs(0, tuple())
return [list(it) for it in ans]
另一种写法
class Solution:
def permuteUnique(self, nums: List[int]) -> List[List[int]]:
ans = []
vis2 = set()
vis = set()
def dfs(depth: int, tmp: list):
if depth==len(nums):
ans.append(tmp[:])
return
if tuple(tmp) in vis:
return
for i, it in enumerate(nums):
if i in vis2:
continue
tmp.append(it)
vis2.add(i)
dfs(depth+1, tmp)
tmp.pop()
vis2.remove(i)
vis.add(tuple(tmp))
dfs(0, [])
return ans
剑指 Offer II 085. 生成匹配的括号
正整数 n 代表生成括号的对数,请设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
示例 1:
输入:n = 3
输出:["((()))","(()())","(())()","()(())","()()()"]
示例 2:
输入:n = 1
输出:["()"]
提示:
1 <= n <= 8
暴力,全排列
class Solution:
def generateParenthesis(self, n: int) -> List[str]:
from itertools import permutations
ans = []
vis = set()
for item in permutations("()"*n):
if item in vis: continue
vis.add(item)
cnt = 0
for it in item:
if it=="(":
cnt+=1
else:
cnt-=1
if cnt<0:
break
else:
ans.append("".join(item))
return ans
回溯、python
先生成左括号,只有左括号数量 > 右括号数量时,才添加右括号,否则直接返回
class Solution:
def generateParenthesis(self, n: int) -> List[str]:
ans = []
def dfs(s: str, cntP: int, cntN: int):
if cntP<cntN:
return
if cntP<n: # 左括号
dfs(s+'(', cntP+1, cntN)
if len(s)==n*2:
ans.append(s)
return
dfs(s+')', cntP, cntN+1) # 右括号
dfs("", 0, 0)
return ans
官解: 回溯 cpp
void dfsgenerateParenthesis(vector<string>& ans, string& t, int l, int r, int& n) {
if (t.size() == n << 1) {
ans.push_back(t); return;
}
if (l < n) {
t.push_back('(');
dfsgenerateParenthesis(ans, t, l + 1, r, n);
t.pop_back();
}
if (r < l) { // 只有 r < l时,才添加右括号
t.push_back(')');
dfsgenerateParenthesis(ans, t, l, r + 1, n);
t.pop_back();
}
}
vector<string> generateParenthesis(int n) {
vector<string> ans;
string t;
dfsgenerateParenthesis(ans, t, 0, 0, n);
return ans;
}
复杂度分析
我们的复杂度分析依赖于理解 generateParenthesis ( n ) \textit{generateParenthesis}(n) generateParenthesis(n) 中有多少个元素。这个分析超出了本文的范畴,但事实证明这是第 n n n 个卡特兰数 1 n + 1 ( 2 n n ) \dfrac{1}{n+1}\dbinom{2n}{n} n+11(n2n),这是由 4 n n n \dfrac{4^n}{n\sqrt{n}} nn4n渐近界定的。
-
时间复杂度: O ( 4 n n ) O(\dfrac{4^n}{\sqrt{n}}) O(n4n),在回溯过程中,每个答案需要 O ( n ) O(n) O(n) 的时间复制到答案数组中。
-
空间复杂度: O ( n ) O(n) O(n),除了答案数组之外,我们所需要的空间取决于递归栈的深度,每一层递归函数需要 O ( 1 ) O(1) O(1) 的空间,最多递归 2 n 2n 2n 层,因此空间复杂度为 O ( n ) O(n) O(n)。
剑指 Offer II 086. 分割回文子字符串
给定一个字符串 s ,请将 s 分割成一些子串,使每个子串都是 回文串 ,返回 s 所有可能的分割方案。
回文串 是正着读和反着读都一样的字符串。
示例 1:
输入:s = "google"
输出:[["g","o","o","g","l","e"],["g","oo","g","l","e"],["goog","l","e"]]
示例 2:
输入:s = "aab"
输出:[["a","a","b"],["aa","b"]]
示例 3:
输入:s = "a"
输出:[["a"]]
提示:
1 <= s.length <= 16
s 仅由小写英文字母组成
方法一:回溯 + 动态规划预处理
由于需要求出字符串 s s s 的所有分割方案,因此我们考虑使用搜索 + 回溯的方法枚举所有可能的分割方法并进行判断。
假设我们当前搜索到字符串的第 i i i 个字符,且 s [ 0.. i − 1 ] s[0..i-1] s[0..i−1] 位置的所有字符已经被分割成若干个回文串,并且分割结果被放入了答案数组 ans \textit{ans} ans 中,那么我们就需要枚举下一个回文串的右边界 j j j,使得 s [ i . . j ] s[i..j] s[i..j] 是一个回文串。
DFS过程:因此,我们可以从 i i i 开始,从小到大依次枚举 j j j。对于当前枚举的 j j j 值,我们使用双指针的方法判断 s [ i . . j ] s[i..j] s[i..j] 是否为回文串:如果 s [ i . . j ] s[i..j] s[i..j] 是回文串,那么就将其加入答案数组 ans \textit{ans} ans 中,并以 j + 1 j+1 j+1 作为新的 i i i 进行下一层搜索,并在未来的回溯时将 s [ i . . j ] s[i..j] s[i..j] 从 ans \textit{ans} ans 中移除。
如果我们已经搜索完了字符串的最后一个字符,那么就找到了一种满足要求的分割方法。
细节
当我们在判断 s [ i . . j ] s[i..j] s[i..j] 是否为回文串时,常规的方法是使用双指针分别指向 i i i 和 j j j,每次判断两个指针指向的字符是否相同,直到两个指针相遇。然而这种方法会产生重复计算,例如下面这个例子:
当 s = aaba s = \texttt{aaba} s=aaba 时,对于前 2 2 2 个字符 aa \texttt{aa} aa,我们有 2 2 2 种分割方法 [ aa ] [\texttt{aa}] [aa] 和 [ a , a ] [\texttt{a}, \texttt{a}] [a,a],当我们每一次搜索到字符串的第 i = 2 i=2 i=2 个字符 b \texttt{b} b 时,都需要对于每个 s [ i . . j ] s[i..j] s[i..j] 使用双指针判断其是否为回文串,这就产生了重复计算。
因此,我们可以将字符串 s s s 的每个子串 s [ i . . j ] s[i..j] s[i..j] 是否为回文串预处理出来,使用动态规划即可。
设 f ( i , j ) f(i, j) f(i,j) 表示 s [ i . . j ] s[i..j] s[i..j] 是否为回文串,那么有状态转移方程:
f ( i , j ) = { True , i ≥ j f ( i + 1 , j − 1 ) ∧ ( s [ i ] = s [ j ] ) , otherwise f(i, j) = \begin{cases} \texttt{True}, & \quad i \geq j \\ f(i+1,j-1) \wedge (s[i]=s[j]), & \quad \text{otherwise} \end{cases} f(i,j)={True,f(i+1,j−1)∧(s[i]=s[j]),i≥jotherwise
其中 ∧ \wedge ∧ 表示逻辑与运算,即 s [ i . . j ] s[i..j] s[i..j] 为回文串,当且仅当其为空串( i > j i>j i>j),其长度为 1 1 1( i = j i=j i=j),或者首尾字符相同且 s [ i + 1.. j − 1 ] s[i+1..j-1] s[i+1..j−1] 为回文串。
预处理完成之后,我们只需要 O ( 1 ) O(1) O(1) 的时间就可以判断任意 s [ i . . j ] s[i..j] s[i..j] 是否为回文串了。
void dfspartition(const string& s, int idx, vector< vector<int>>& f, vector<vector<string>>& ans, vector<string> &tmp) {
if (idx == s.size()) {
ans.push_back(tmp);
return;
}
for (int i = idx; i < s.size(); i++) {
if (f[idx][i]) {
tmp.push_back(s.substr(idx, i - idx + 1));
dfspartition(s, i + 1, f, ans, tmp);
tmp.pop_back();
}
}
}
vector<vector<string>> partition(string s) {
int n = s.size();
vector< vector<int>> f;
vector<vector<string>> ans;
f.assign(n, vector<int>(n, 1));
for (int i = n-1; i >= 0; i--) { //
for (int j = i + 1; j < n; j++) {
f[i][j] = f[i + 1][j - 1] && (s[i] == s[j]);
}
}
vector<string > tmp;
dfspartition(s, 0, f, ans, tmp);
return ans;
}
此处的dp可以改成双指针方法,二者复杂度一样
void dfspartition(const string& s, int idx, int (&f)[16][16], vector<vector<string>>& ans, vector<string>& tmp) {
if (idx == s.size()) {
ans.push_back(tmp);
return;
}
for (int i = idx; i < s.size(); i++) {
if (f[idx][i]) {
tmp.push_back(s.substr(idx, i - idx + 1));
dfspartition(s, i + 1, f, ans, tmp);
tmp.pop_back();
}
}
}
void helperpartition(string s, int l, int r, int (&vis)[16][16]) { //
while (l >= 0 && r < s.size() && s[l] == s[r]) {
vis[l][r] = 1;
l--; r++;
}
return;
}
vector<vector<string>> partition(string s) {
int n = s.size();
int f[16][16] = {};
vector<vector<string>> ans;
for (int i = 0; i < s.size(); i++) {
helperpartition(s, i, i, f);
helperpartition(s, i, i + 1, f);
}
vector<string > tmp;
dfspartition(s, 0, f, ans, tmp);
return ans;
}
时间复杂度O( n ⋅ 2 n n· 2^n n⋅2n),
空间O( n 2 n^2 n2)
剑指 Offer II 087. 复原 IP
给定一个只包含数字的字符串 s ,用以表示一个 IP 地址,返回所有可能从 s 获得的 有效 IP 地址 。你可以按任何顺序返回答案。
有效 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 ‘.’ 分隔。
例如:“0.1.2.201” 和 “192.168.1.1” 是 有效 IP 地址,但是 “0.011.255.245”、“192.168.1.312” 和 “[email protected]” 是 无效 IP 地址。
示例 1:
输入:s = "25525511135"
输出:["255.255.11.135","255.255.111.35"]
示例 2:
输入:s = "0000"
输出:["0.0.0.0"]
示例 3:
输入:s = "1111"
输出:["1.1.1.1"]
示例 4:
输入:s = "010010"
输出:["0.10.0.10","0.100.1.0"]
示例 5:
输入:s = "10203040"
输出:["10.20.30.40","102.0.30.40","10.203.0.40"]
提示:
0 <= s.length <= 3000
s 仅由数字组成
我的方法:带索引的多叉树回溯
本题与上一题解法类似
bool helperResAddr(const string& s, int start, int end) { // 判断 数字 是否合法
string t = s.substr(start, end - start + 1);
if (t.size() > 1 && t[0] == '0') return false;
int c = stoi(t);
return c < 256;
}
void dfsrestoreAddr(const string& s, int cur, int size, string& tmp, vector<string>& ans) {
if (size == 4 && cur==s.size()) {
tmp.erase(tmp.size() - 1);
ans.push_back(tmp);
return;
}
for (int i = cur; i < s.size(); ++i) { // i 是当前终点索引
if (i - cur > 3 || size > 4) continue;
if (helperResAddr(s, cur, i)) {
int tmpEnd = tmp.size(); // 用于回溯时,还原字符串
tmp += s.substr(cur, i - cur + 1);
tmp += ".";
dfsrestoreAddr(s, i + 1, size + 1, tmp, ans); // 使用当前终点索引的下一个索引作为起始值dfs
tmp.erase(tmp.size() - 1);
tmp.erase(tmpEnd, tmp.size());
}
}
}
vector<string> restoreIpAddresses(string s) {
vector<string> ans;
string tmp;
dfsrestoreAddr(s, 0, 0, tmp, ans);
return ans;
}
(归并) 856. 括号的分数
给定一个平衡括号字符串 S,按下述规则计算该字符串的分数:
() 得 1 分。
AB 得 A + B 分,其中 A 和 B 是平衡括号字符串。
(A) 得 2 * A 分,其中 A 是平衡括号字符串。
示例 1:
输入: "()"
输出: 1
示例 2:
输入: "(())"
输出: 2
示例 3:
输入: "()()"
输出: 2
示例 4:
输入: "(()(()))"
输出: 6
提示:
S 是平衡括号字符串,且只含有 ( 和 ) 。
2 <= S.length <= 50
方法一:归并
根据题意,一个平衡括号字符串 s s s 可以被分解为 A + B A+B A+B 或 ( A ) (A) (A) 的形式,因此我们可以对 s s s 进行分解,分而治之。
class Solution:
def scoreOfParentheses(self, s: str) -> int:
def dfs(s: str)-> int:
n = len(s)
if n==2:
return 1
need = 0
for i, c in enumerate(s):
need += 1 if c=="(" else -1
if need==0:
if i==n-1:
return dfs(s[1:-1])<<1
return dfs(s[:i + 1]) + dfs(s[i + 1:]) # merge
return dfs(s)
复杂度分析
- 时间复杂度: O ( n 2 ) O(n^2) O(n2),其中 n n n 是字符串的长度。递归深度为 O ( n ) O(n) O(n),每一层的所有函数调用的总时间复杂度都是 O ( n ) O(n) O(n),因此总时间复杂度为 O ( n 2 ) O(n^2) O(n2)。
- 空间复杂度: O ( n 2 ) O(n^2) O(n2)。每一层都需要将字符串复制一遍,因此总空间复杂度为 O ( n 2 ) O(n^2) O(n2)。对于字符串支持切片的语言,空间复杂度为递归栈所需的空间 O ( n ) O(n) O(n)。
方法二:栈
class Solution:
def scoreOfParentheses(self, s: str) -> int:
st = [0]
for c in s:
if c == '(':
st.append(0) # 初始化左括号的值
else:
v = st.pop()
st[-1] += max(2 * v, 1) # 累加左括号的值
return st[-1]
复杂度分析
- 时间复杂度: O ( n ) O(n) O(n),其中 n n n 是字符串的长度。
- 空间复杂度: O ( n ) O(n) O(n)。栈需要 O ( n ) O(n) O(n) 的空间。