互联网大厂的分布式ID解决方案(上)
“ 该系列是对美团Leaf、滴滴TinyId、百度UidGenerator的源码分析和思考”
大家好,我是面条哥。
01
—
什么是分布式ID
在分布式系统中,ID的生成分布在不同的服务器并保证全局唯一,我们把这种ID叫做分布式ID。
02
—
为什么需要分布式ID
摘抄美团技术团队对分布式ID的要求。
-
全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求。举个例子:MySQL在分库分表的时候,很多时候都会使用自增长id作为主键,由于是不同的表组成了一个大而全的表数据,所以生成的id时候,如果不做控制,不同的表就会出现相同的主键,对于全局而言就会产生冲突。
-
趋势递增:在MySQL InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。
-
单调递增:保证下一个ID一定大于上一个ID,例如事务版本号、IM增量消息、排序等特殊需求。
-
信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,可以直接知道我们一天的单量。所以在一些应用场景下,会需要ID无规则、不规则。
03
—
分布式ID的解决方案
1、一个实际营销项目的ID生成案例
需求:给一个租户或者渠道生成一个全局唯一的AppKey,并发小,有规律,易记,实现功能要求快。

【技术设计方案】
方案解释:(当年-2000) + (当前日,凑3位不够补0) + (当前小时,凑2位不够补0) + (从1开始五位数不够补0)。左侧是自定义的规则(方案设计上有bug,但是不影响举例说明),右侧是利用redis的原子操作incr保证并发下唯一并自增长,可以看出来210201400001是2021年某月的20号14点生成的第一个key,这种方式比较简单,只需要利用redis的机制即可,如果项目属于传统行业、使用率低、并发量小,这个功能就可以满足需求了。
2、百度UidGenerator
在了解百度的分布式id生成器之前,需要先了解一下雪花算法。
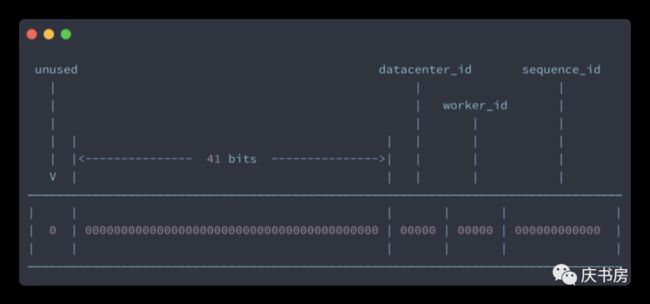
【雪花算法原理图】
-
41-bit的时间可以表示(1L<<41)/(1000L*3600*24*365)=69年的时间。
-
10-bit机器可以分别表示1024台机器。如果我们对IDC划分有需求,还可以将10-bit分5-bit给IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,可以根据自身需求定义。
-
12个自增序列号可以表示2^12个ID
-
理论上snowflake方案的QPS约为419.4w/ms,这种分配方式可以保证在任何一个IDC的任何一台机器在任意毫秒内生成的ID都是不同的。
总结一下:雪花算法是依赖64位的整型数据,第一位不用,代表正数,后41位代表当前生成id的时间戳,后面10位和12位组合生成一个ID。百度的UidGenerator也是基于雪花算法,如下图所示

【百度雪花算法原理图】
百度的ID生成策略只是将64位的分配做了调整,这样组合的改变会带来以下几点变化:
-
并发的粒度由毫秒变成秒,缩短了id全局唯一的年限,由之前的69年变成了现在的8.7年。
-
支持的机器数量由1024增加到420w。
-
并发序列由每毫秒4096变成了每秒8192。
-
理论上的并发量由之前的每毫秒419.4w/ms变成现在的3440万/ms,也就是缩短了年限,提高了并发量。
接下来将会对源码进行分析,源码主要是粘贴图片,在图片上面说明,这样有利于边看源码边看解释,百度的UidGenerator提供了两种生成Id的策略,一种是默认的DefaultUidGenerator,一种是基于RingBuffer的CachedUidGenerator,第二种继承了DefaultUidGenerator,也就是说在第一种的基础上进行了扩展。
一、DefaultUidGenerator

可以看到它实现了UidGenerator接口和InitializingBean的接口,UidGenerator接口主要是定义getUID()和parseUID(),InitializingBean接口的作用是在初始化bean的时候调用afterPropertiesSet()方法,所以服务在启动的时候就会执行这个方法,看下里面做了什么操作。
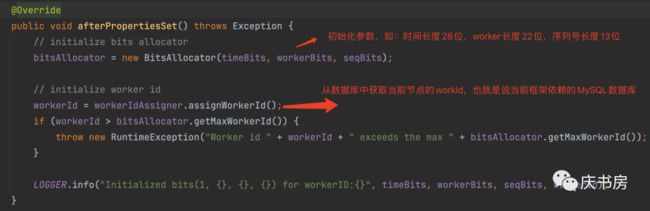

可以看出服务在启动的时候会将一条数据插入MySQL中,然后返回这条记录的主键ID,之后就没有对数据库的操作了,如果重启服务也是插入一条记录,这个workerId貌似只是起到了一个临时的作用,那为什么要这样做?主要的原因就是依赖MySQL的主键,保证主键唯一,如果不想使用MySQL可以使用Redis的分布式锁。如果要支持重复使用workerId,那么workerId就需要持久化,这个时候存储在MySQL就比较适合了,重启之后就会从数据库中读取对应的workerId继续使用。

所以在百度的雪花算法中,workerId满足了第三段worker node id的22bits的,时间戳-(2016-05-20)、workerId、sequence三者就可以进行组合生成id了,来看下生成id的方法。

-
nextId只需要在JVM级别保证并发安全即可,所以使用了synchronized关键字保证线程安全。
-
由于雪花算法是基于时间的,如果时间出现回拨,就有可能出现id重复的问题,这里做的只是简单的判断,如果在极端的情况下如果时钟回拨在几十分钟,这个时候当前服务将会一直返回错误给到调用者。
-
currentSecond==lastSecod代表是当前时间的并发操作,也就是一秒钟的并发,如果超过1秒钟并发的最大值也就是8192,则会等待下一秒,然后从下一秒第一个序列号开始,第一个序列号是sequence=0。
二、CachedUidGenerator
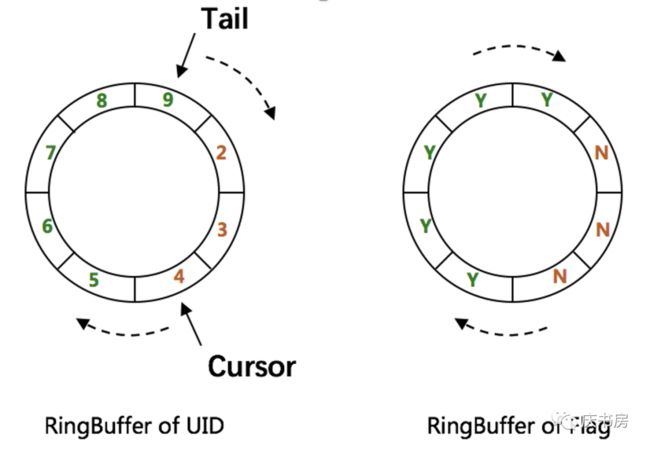
先了解一下什么是环形数组,请看图

循环数组本质上是一个数组,它对这个循环数组进行重复利用,生产者先插入数据,然后消费端从头开始消费数据,一边生产一边消费,生产到尾部之后,再从头开始生产,重复利用当前数组,要做到重复利用则需要将数组中值是否可以读取,是否可以生产做标记,看下一个例子。一个数组中有5个值0、1、2、3、4,下标也是一样0、1、2、3、4,生产者已经将数据写满了。

消费者从0开始读取数据读取了0、1、2,3条数据,此时标记一下前3条数据已经被读取了,读取的数据就没有用了,可以被生产者覆盖,如果生产者此时开始从头生产,则是可以插入新的值。

生产者开始生产新值5的数据,判断当前位置是否可以被覆盖,可以的话,就将值为0的数据覆盖,然后标记下标为0值为5的状态为可以被消费但不能被覆盖,如下图所示绿色代表没有被消费。

标记数组值的状态是否可以被消费,是否可以被覆盖就需要另外一个长度一样的数组,用来标记状态,那这样就是双环形数组。
看下启动的时候怎么初始化CacheUidGenerator
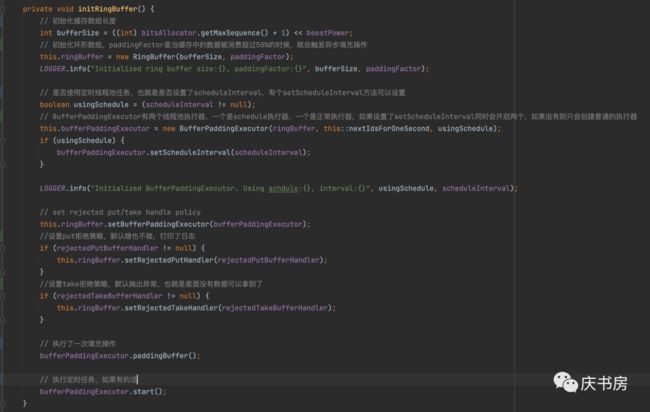

总结:
1、启动服务初始化workerId和默认生成器一样,用完即弃。
2、初始化RingBuffer,设定一些参数,然后创建线程池,如果设置定时的间隔,就会创建一个定时任务线程池,也就是定时去填充RingBuffer,如果没有则不会。
3、启动的时候都会填充一次RingBuffer数据组。
接下来再看下核心的方法take()注释在截图上面

总结:
1、主要是根据tail和curse指针做数据的位移,并可以根据他们来计算出对应数据和状态的的下标。
2、当触发阈值的之后就会异步初始化填充数据,直到填满为止。
3、设置对应的状态,是否可以设置。
思考1:
消费指针和生产指针采用了原子包装类,take主要是查询数据,但是有全局修改的动作,消费指针需要移动,flags的状态需要设置,为什么take动作没有加锁呢?为什么是线程安全的呢?
可以看到操作的代码如下所示
// 获取下一个消费指针cursor.updateAndGet(old -> old == tail.get() ? old : old + 1)...//设置指针状态为putflags[nextCursorIndex].set(CAN_PUT_FLAG);
首先cursor是原子的通过cas去增加,可以做到多线程可见性,当一个线程执行的时候将数据cursor增加了1,其它线程就会立马看到设置的值,那这个时候针对于flags而言虽然是全局的,但是针对于flags的每个槽的位置只会有一个线程去操作,不会有多个线程并发去操作flags的同一个槽位,因为前置的原子操作就已经让不同的线程执行了flags的不同槽位,这样就不会有线程安全的问题。
思考2:
tail、cursor、flags都使用了PadderAtomicLong,为什么不直接使用AtomicLong?
我们来看下官网给出的解释,这个涉及到计算机操作系统的知识,伪共享。

我们再来看下著名的Disrupt相关的源码,是不是有点相似?嘿嘿

看下put()方法的源码

总结:put方法加锁了,而且是synchronized方法级别的锁,为什么要加锁?
发现共享变量有slots、flags。假设不加锁的话,现在有两个线程A和B同时执行put方法,A和B线程都获取了currentTail的值为5,线程A执行完了这段代码,结果是值为5的uid可以被take(),此时线程B由于没有拿到cpu时间片挂起了一段时间,在这段时间里,线程C来了将值为5的数据读取了,并设置成了可以put状态,然后此时线程B恢复了继续执行之后的代码又将数据5的状态设置了可以take。这样就会出现数据紊乱,数据5已经被读取了。
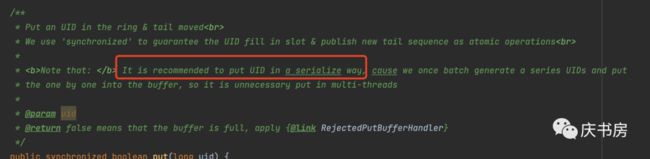
官网推荐使用单线程的方式生成uid,因为是预加载的方式,速度很快,超过50%就会触发异步加载。
百度UidGenerator总结:
优点:
-
id的生成依赖于jvm内存,生成速度非常快,效率高。
-
双循环数组加快id的生成效率。
缺点:
-
采用雪花算法生成id,可能会出现时钟回拨的问题,没有根本解决问题。
-
workerId的生成是基于MySQL用完即弃的方式,启动之后就不再依赖数据库,弱依赖于MySQL,workerId会造成浪费。
-
id的长度很长,如果想缩短id的长度可以对雪花算法进行改造。
-
满足趋势递增,不满足单调递增,下篇文章主要说下滴滴的TinyId,满足了单调递增。
时钟回拨的可能性未知,可以基于美团技术团队在使用的过程中遇到过一次判断,但是美团的Leaf解决了时钟回拨的问题,但是开源的Leaf并没有开源相关的代码,需要自己去实现。遇到时钟回拨的整体概率应该是偏小的,如果可以容忍小概率的事件,雪花算法是比较合适作为生成id的一种方式。