走好每一步,基于C实现机器人运动学建模与标定、运动规划、轨迹规划算法
走好每一步,基于C实现机器人运动学建模与标定、运动规划、轨迹规划算法
- 废话
- 综述
- 一:C部分
-
- 初始C语言
- Chapter2-4:基本数据类型
- Chapter5-7:运算符、表达式、循环、分支与跳转
- Chapter9/10/14:函数、数组、结构体、指针
-
- 函数
- 数组
- 指针
- 结构体
- 综合
- 文件I/O
- C预处理、C库
- 内存管理
- 函数指针实现类封装、继承、多态
- 二:C++部分
-
- 基础
-
- HelloWorld
- 流算子
- 数据类型
- 限定符
- 存储类
- 随机数
- 字符串
- 结构体
- 类(class)&对象(object)
-
- 概念
- 类的定义和创建
- 类的成员变量和成员函数
- 类成员的访问权限(封装)
- 构造函数(Constructor)
- 构造函数的参数初始化表
- 析构函数(Destructor)
- this指针详解
- static静态成员变量
- static静态成员函数
- 类与const关键字
- class和struct的区别
- 动态内存
- 模板 template
-
- 函数模板
- 类模板
- STL模板类:string,vector、array
-
- STL(标准模板库)
-
- 容器 Containers
- 算法 Algorithms
- 迭代器 iterators
- 几个重要类: string array vector
-
- string
- array
- vector
- 三:编程实践
-
- 应用案例
-
- 矩阵运算与线性代数
- SCARA运动学建模、DH参数标定
- 相机手眼标定
- 运动规划
- 路径规划/轨迹规划:直线与圆弧规划
- 轨迹规划:圆弧/多项式/抛物线过渡
- 轨迹规划:局部贝塞尔曲线与全局B样条曲线
- 速度规划-指定时间七段加减速算法
- 循环顺序线性队列
- OpenGL实时(双缓冲技术)绘制散点图
- 多线程与线程锁
- 数值计算方法
- 优化算法
- Debug日志杂记
废话
之前所有工都是基于Matlab/Simulink完成,现在考虑将之前关于运动学建模/标定/轨迹规划的工作转换为C,不得已需要重新捡起来。然水平有限,故本文仅用于个人学习总结以及日后温习强化之用(所以总结写的比较随心随性哈)!
综述
功能模块:机器人学运动学与轨迹规划部分;工业相机手眼标定;数据结构之循环顺序线性队列
详细功能模块:矩阵基本运算;线性方程组求解(最小二乘法);基于DH法的封闭正逆解;DH参数标定与工具标定;循环顺序队列;C/结构体与全局变量/指针与动态内存/函数指针/多线程与锁;轨迹规划:插值与拟合;速度规划:7段S加减速算法;
C/数据结构涉及到到的知识点:二维数组与指针、结构体数组与指针、动态内存分配、函数指针、全局变量、多线程与线程锁、结构体与指针函数实现类、顺序循环队列读写操作、VS下使用OpenGL实时(双缓冲技术)绘制散点图等,以及编译编辑平台的使用:VM虚拟机下Linux gcc/g++、Win10下VisualStudio2010调试、SourceInsight4.0编辑;
PS:C++部分仅用于记录本人简单的入门学习笔记;
一:C部分
初始C语言
1.C与C++:C++几乎是C的超集。C++在C的基础上嫁接了面向对象编程工具。
2.面向对象编程是一门哲学,它通过对语言建模来适应问题,而不是对问题建模来适应语言。
3.缺点:C语言使用指针,编程错误难以发觉。有句话说得好:想拥有自由就必须时刻保持警惕。
4.CPU工作原理:CPU从存储器或高速缓冲存储器中取出指令,放入指令寄存器,并对指令译码。它把指令分解成一系列的微操作,然后发出各种控制命令,执行微操作系列,从而完成一条指令的执行。指令是计算机规定执行操作的类型和操作数的基本命令。指令是由一个字节或者多个字节组成。
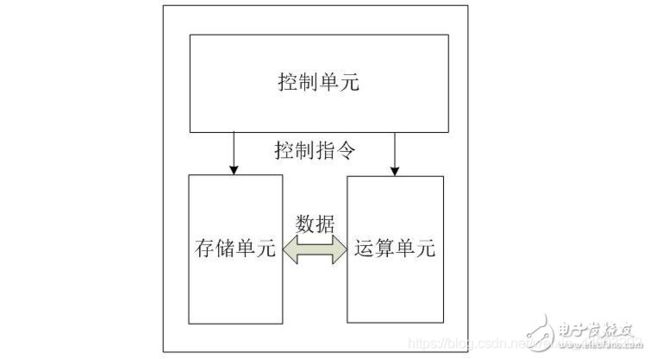
5.语言标准:C99
6.使用C语言的7个步骤:
1)定义程序的目标(术语描述,问题分析:信息/控制量/目标);
2)设计程序(术语,伪代码,非具体代码);
3)编写代码;
4)编译(编译器把源代码变成可执行代码的程序,可执行文件);
编译的分为4个步骤:预处理, 编译, 汇编和链接。
5)运行程序(可执行文件是可运行的程序);
6)测试和调试(Debug);
7)维护和修改(合理注释,良好的编程习惯);
7.编程环境:VS2010。
Chapter2-4:基本数据类型
C程序实例:first.cpp
包含:main函数体;函数printf();函数getchar();注释;
如下所示:
/* first.cpp 测试main函数 printf()函数 getchar()函数 代码注释 */
#include C程序实例:DataTypeConversion.cpp
包含:基本数据类型输出
如下所示:
/* DataTypeConversion.cpp 测试常用数据类型转换 */
#include程序实例:charcode.cpp
包含:字符常量格式化输出
如下所示:
/* charcode.cpp 测试手动输入字符常量并格式化显示 */
#include程序实例:StringArray.cpp
包含:字符串、二维数组存储与地址、指针访问二维数组元素、函数定义/声明/调用
如下所示:
/* StringArray.cpp 测试指针访问二维数组地址*/
#include Chapter5-7:运算符、表达式、循环、分支与跳转
程序实例:operate.cpp
包含:自增自减运算符、while循环、for循环
具体如下:
/* operate.cpp 测试自增自减运算符 while循环 for循环*/
#include 程序实例:judge.cpp
包含:分支/跳转、条件判断、逻辑运算符
具体如下:
/* judge.cpp 测试分支跳转语句以及关系运算符(用作条件判断) */
#include Chapter9/10/14:函数、数组、结构体、指针
这里,我们按照参考书目扫描知识点,对相关重点内容进行整理总结。具体实践将由下一节给出。由于工作原因,仅仅给出了部分源代码,仅供参考!如研究方向一致,欢迎交流!
函数
1-main()函数是主函数,它可以调用其它函数,而不允许被其它函数调用。因此,C程序的执行总是从 main()函数开始,完成对其它函数的调用后再返回到 main() 函数,最后由 main() 函数结束整个程序;
2-C语言允许在代码块内部定义变量,这样的变量具有块级作用域;换句话说,在代码块内部定义的变量只能在代码块内部使用,出了代码块就无效了。例如:for(int i=m; i<=n; i++){ /* i是块级变量 */ sum += i;}
3-在所有函数外部定义的变量称为全局变量(Global Variable),它的作用域默认是整个程序,也就是所有的源文件,包括 .c 和 .h 文件;
4-不允许函数嵌套定义;没有返回值的函数为空类型,用void表示,return 后面不能带任何数据,直接写分号即可;
5-return 语句是提前结束函数的唯一办法。return 后面可以跟一份数据,表示将这份数据返回到函数外面;return 后面也可以不跟任何数据,表示什么也不返回,仅仅用来结束函数;
6-函数原型给出了使用该函数的所有细节,当我们不知道如何使用某个函数时,需要查找的是它的原型,而不是它的定义,我们往往不关心它的实现。www.cplusplus.com 是一个非常给力的网站,它提供了所有C语言标准函数的原型,并给出了详细的介绍和使用示例,可以作为一部权威的参考手册。
数组
0-在C语言中,数组属于构造数据类型。一个数组可以分解为多个数组元素,这些数组元素可以是基本数据类型或是构造类型。因此按数组元素的类型不同,数组又可分为数值数组、字符数组、指针数组、结构数组等各种类别;
1-数组是一个整体,它的内存是连续的;
2-当赋值的元素少于数组总体元素的时候,剩余的元素自动初始化为 0;我们可以通过下面的形式将数组的所有元素初始化为 0:int nums[10] = {0};char str[10] = {0};float scores[10] = {0.0};
3-就目前学到的知识而言,int、char、float 等类型的变量用于 scanf()时都要在前面添加&,而数组或者字符串用于 scanf() 时不用添加&,它们本身就会转换为地址。读者一定要谨记这一点;
4-string.h是一个专门用来处理字符串的头文件,它包含了很多字符串处理函数,可以对字符串进行输入、输出、合并、修改、比较、转换、复制、搜索等操作等,链接:http://www.cplusplus.com/reference/cstring/
5-冒泡排序,按从小到大输出。代码如下:
#include 6-学完了数组,有两项内容大家可以深入研究了,分别是查找(Search)和排序(Sort),它们在实际开发中都经常使用。
指针
1-一切都是地址:CPU 访问内存时需要的是地址,而不是变量名和函数名!变量名和函数名只是地址的一种助记符,当源文件被编译和链接成可执行程序后,它们都会被替换成地址。编译和链接过程的一项重要任务就是找到这些名称所对应的地址;
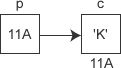
2-指针变量:数据在内存中的地址也称为指针,如果一个变量存储了一份数据的指针,我们就称它为指针变量。在C语言中,允许用一个变量来存放指针,这种变量称为指针变量。指针变量的值就是某份数据的地址,这样的一份数据可以是数组、字符串、函数,也可以是另外的一个普通变量或指针变量。如下图所示,p 是指向变量 c 的指针变量,它的值为 0X11A,正好等于变量 c 的地址。
3-定义-修改指针变量。需要强调的是,p1、p2 的类型分别是float和char,而不是float和char,它们是完全不同的数据类型,要引起注意。
//定义普通变量
float a = 99.5, b = 10.6;
char c = '@', d = '#';
//定义指针变量
float *p1 = &a;
char *p2 = &c;
//修改指针变量的值
p1 = &b;
p2 = &d;
4-指针除了可以获取内存上的数据,也可以修改内存上的数据,例如:
#include *p代表的是a中的数据,它等价于a,可以将另外的一份数据赋值给它,也可以将它赋值给另外的一个变量。
5- *在不同的场景下有不同的作用:*可以用在指针变量的定义中,表明这是一个指针变量,以和普通变量区分开;使用指针变量*时在前面加表示获取指针指向的数据,或者说表示的是指针指向的数据本身。也就是说,定义指针变量*时的和使用指针变量*时的意义完全不同。如:
int *p = &a;
*p = 100;
需要注意的是,给指针变量本身赋值时不能加`*,如:
int *p;
p = &a;
*p = 100;
指针变量也可以出现在普通变量能出现的任何表达式中,例如:
int x, y, *px = &x, *py = &y;
y = *px + 5; //表示把x的内容加5并赋给y,*px+5相当于(*px)+5
y = ++*px; //px的内容加上1之后赋给y,++*px相当于++(*px)
y = *px++; //相当于y=(*px)++
py = px; //把一个指针的值赋给另一个指针
对星号*的总结,主要有三种用途:
表示乘法,例如:int a = 3, b = 5, c; c = a * b;,这是最容易理解的。
表示定义一个指针变量,以和普通变量区分开,例如:int a = 100; int *p = &a;。
表示获取指针指向的数据,是一种间接操作,例如:int a, b, *p = &a; *p = 100; b = *p;。
6-指针变量保存的是地址,本质上是一个整数,可以进行部分运算,例如加法、减法、比较等,请看下面的代码:
#include 从运算结果可以看出:pa、pb、pc 每次加 1,它们的地址分别增加 4、8、1,正好是int、double、char 类型的长度;减 2 时,地址分别减少 8、16、2,正好是 int、double、char类型长度的 2 倍。指针变量加减运算的结果跟数据类型的长度有关,而不是简单地加 1 或减 1。
另外需要说明的是,不能对指针变量进行乘法、除法、取余等其他运算,除了会发生语法错误,也没有实际的含义。
7-数组指针(指向数组的指针)
引入数组指针后,我们就有两种方案来访问数组元素了,一种是使用下标,另外一种是使用指针。
- 使用下标
也就是采用arr[i]的形式访问数组元素。如果p是指向数组arr的指针,那么也可以使用p[i]来访问数组元素,它等价于arr[i]。 - 使用指针
也就是使用*(p+i)的形式访问数组元素。另外数组名本身也是指针,也可以使用*(arr+i)来访问数组元素,它等价于*(p+i)。例如:
#include 说明:*p++等价于 *(p++),表示先取得第 n 个元素的值,再将 p 指向下一个元素,上面已经进行了详细讲解。
*++p 等价于 *(++p),会先进行 ++p 运算,使得 p 的值增加,指向下一个元素,整体上相当于*(p+1),所以会获得第n+1 个数组元素的值。
(*p)++就非常简单了,会先取得第 n 个元素的值,再对该元素的值加 1。
8-字符串指针(指向字符串的指针)
字符数组归根结底还是一个数组,上节讲到的关于指针和数组的规则同样也适用于字符数组。代码如下:
#include 除了字符数组,C语言还支持另外一种表示字符串的方法,就是直接使用一个指针指向字符串,例如:
char *str;
str = "http://c.biancheng.net";
这一切看起来和字符数组是多么地相似,它们都可以使用%s输出整个字符串,都可以使用*或[ ]获取单个字符,这两种表示字符串的方式是不是就没有区别了呢?
有!它们最根本的区别是在内存中的存储区域不一样,字符数组存储在全局数据区或栈区,第二种形式的字符串存储在常量区。全局数据区和栈区的字符串(也包括其他数据)有读取和写入的权限,而常量区的字符串(也包括其他数据)只有读取权限,没有写入权限。
内存权限的不同导致的一个明显结果就是,字符数组在定义后可以读取和修改每个字符,而对于第二种形式的字符串,一旦被定义后就只能读取不能修改,任何对它的赋值都是错误的。
我们将第二种形式的字符串称为字符串常量,意思很明显,常量只能读取不能写入。
在编程过程中如果只涉及到对字符串的读取,那么字符数组和字符串常量都能够满足要求;如果有写入(修改)操作,那么只能使用字符数组,不能使用字符串常量。
最后我们来总结一下,C语言有两种表示字符串的方法,一种是字符数组,另一种是字符串常量,它们在内存中的存储位置不同,使得字符数组可以读取和修改,而字符串常量只能读取不能修改。
9-指针变量作为函数参数(用数组作函数参数)
用指针变量作函数参数可以将函数外部的地址传递到函数内部,使得在函数内部可以操作函数外部的数据,并且这些数据不会随着函数的结束而被销毁。像数组、字符串、动态分配的内存等都是一系列数据的集合,没有办法通过一个参数全部传入函数内部,只能传递它们的指针,在函数内部通过指针来影响这些数据集合。
数组是一系列数据的集合,无法通过参数将它们一次性传递到函数内部,如果希望在函数内部操作数组,必须传递数组指针。下面的例子定义了一个函数 max(),用来查找数组中值最大的元素,如下:
#include 用数组做函数参数时,参数也能够以“真正”的数组形式给出。例如对于上面的 max() 函数,它的参数可以写成下面的形式:
int max(int intArr[6], int len){
int i, maxValue = intArr[0]; //假设第0个元素是最大值
for(i=1; i<len; i++){
if(maxValue < intArr[i]){
maxValue = intArr[i];
}
}
return maxValue;
}
或者更加简洁:
int max(int intArr[], int len){
int i, maxValue = intArr[0]; //假设第0个元素是最大值
for(i=1; i<len; i++){
if(maxValue < intArr[i]){
maxValue = intArr[i];
}
}
return maxValue;
}
int intArr[6]好像定义了一个拥有 6 个元素的数组,调用 max()时可以将数组的所有元素“一股脑”传递进来。
int intArr[]虽然定义了一个数组,但没有指定数组长度,好像可以接受任意长度的数组。
实际上这两种形式的数组定义都是假象,不管是int intArr[6]还是int intArr[]都不会创建一个数组出来,编译器也不会为它们分配内存,实际的数组是不存在的,它们最终还是会转换为int *intArr这样的指针。这就意味着,两种形式都不能将数组的所有元素“一股脑”传递进来,大家还得规规矩矩使用数组指针。
int intArr[6]这种形式只能说明函数期望用户传递的数组有 6 个元素,并不意味着数组只能有 6 个元素,真正传递的数组可以有少于或多于 6 个的元素。
需要强调的是,不管使用哪种方式传递数组,都不能在函数内部求得数组长度,因为 intArr仅仅是一个指针,而不是真正的数组,所以必须要额外增加一个参数来传递数组长度。
问题来了,C语言为什么不允许直接传递数组的所有元素,而必须传递数组指针呢?
参数的传递本质上是一次赋值的过程,赋值就是对内存进行拷贝。所谓内存拷贝,是指将一块内存上的数据复制到另一块内存上。
对于像 int、float、char等基本类型的数据,它们占用的内存往往只有几个字节,对它们进行内存拷贝非常快速。而数组是一系列数据的集合,数据的数量没有限制,可能很少,也可能成千上万,对它们进行内存拷贝有可能是一个漫长的过程,会严重拖慢程序的效率,为了防止技艺不佳的程序员写出低效的代码,C语言没有从语法上支持数据集合的直接赋值。除了C语言,C++、Java、Python 等其它语言也禁止对大块内存进行拷贝,在底层都使用类似指针的方式来实现。
10-指针作为函数返回值
C语言允许函数的返回值是一个指针(地址),我们将这样的函数称为指针函数。下面的例子定义了一个函数 strlong(),用来返回两个字符串中较长的一个:
#include 用指针作为函数返回值时需要注意的一点是,函数运行结束后会销毁在它内部定义的所有局部数据,包括局部变量、局部数组和形式参数,函数返回的指针请尽量不要指向这些数据,C语言没有任何机制来保证这些数据会一直有效,它们在后续使用过程中可能会引发运行时错误。请看下面的例子:
#include 输出:
value = -2
这里所谓的销毁并不是将局部数据所占用的内存全部抹掉,而是程序放弃对它的使用权限,弃之不理,后面的代码可以随意使用这块内存。对于上面的两个例子,func() 运行结束后 n 的内存依然保持原样,值还是 100,如果使用及时也能够得到正确的数据,如果有其它函数被调用就会覆盖这块内存,得到的数据就失去了意义。而覆盖它的究竟是一份什么样的数据我们无从推断(一般是一个没有意义甚至有些怪异的值)。
11-二级指针(指向指针的指针)
不展开,用到时再学习。
PS:其实,二维数组就是二级指针,再好好反思一下二维数组指针与数组名之间的关系!
12-指针与二维数组
参考:http://c.biancheng.net/cpp/html/2930.html 以及程序实例:StringArray.cpp
打印/显示任意维度二维数组;任意维度二维数组作为函数参数(二重指针)
13-函数指针(指向函数的指针)
不展开,用到再学习。
函数返回二维数组指针;函数返回结构体指针;函数返回结构体一维数组指针!!!
结构体
1-概念
数组(Array),它是一组具有相同类型的数据的集合;。结构体(Struct)是一种集合,它里面包含了多个变量或数组,它们的类型可以相同,也可以不同,每个这样的变量或数组都称为结构体的成员(Member)。请看下面的一个例子:
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在学习小组
float score; //成绩
};
既然结构体是一种数据类型,那么就可以用它来定义变量。例如:
struct stu stu1, stu2;
在编译器的具体实现中,各个成员之间可能会存在缝隙。结构体使用点号.获取单个成员。获取结构体成员的一般格式为:
结构体变量名.成员名;
通过这种方式可以获取成员的值,也可以给成员赋值:
#include 需要注意的是,结构体是一种自定义的数据类型,是创建变量的模板,不占用内存空间;结构体变量才包含了实实在在的数据,需要内存空间来存储。
2-结构体数组
所谓结构体数组,是指数组中的每个元素都是一个结构体。在实际应用中,结构体数组常被用来表示一个拥有相同数据结构的群体,比如一个班的学生、一个车间的职工等。
结构体数组在定义的同时也可以初始化,例如:
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
}class[5] = {
{"Li ping", 5, 18, 'C', 145.0},
{"Zhang ping", 4, 19, 'A', 130.5},
{"He fang", 1, 18, 'A', 148.5},
{"Cheng ling", 2, 17, 'F', 139.0},
{"Wang ming", 3, 17, 'B', 144.5}
};
结构体数组的使用也很简单,例如,获取 Wang ming 的成绩:
class[4].score;
修改 Li ping 的学习小组:
class[0].group = 'B';
【示例】计算全班学生的总成绩、平均成绩和以及 140 分以下的人数。
#include 3-结构体和指针
指针也可以指向一个结构体,定义的形式一般为:
struct 结构体名 *变量名;
下面是一个定义结构体指针的实例:
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
} stu1 = { "Tom", 12, 18, 'A', 136.5 };
//结构体指针
struct stu *pstu = &stu1;
也可以在定义结构体的同时定义结构体指针:
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
} stu1 = { "Tom", 12, 18, 'A', 136.5 }, *pstu = &stu1;
注意,结构体变量名和数组名不同,数组名在表达式中会被转换为数组指针,而结构体变量名不会,无论在任何表达式中它表示的都是整个集合本身,要想取得结构体变量的地址,必须在前面加&,所以给 pstu 赋值只能写作:
struct stu *pstu = &stu1;
而不能写作:
struct stu *pstu = stu1;
还应该注意,结构体和结构体变量是两个不同的概念:结构体是一种数据类型,是一种创建变量的模板,编译器不会为它分配内存空间,就像 int、float、char 这些关键字本身不占用内存一样;结构体变量才包含实实在在的数据,才需要内存来存储。下面的写法是错误的,不可能去取一个结构体名的地址,也不能将它赋值给其他变量:
struct stu *pstu = &stu;
struct stu *pstu = stu;
通过结构体指针可以获取结构体成员,一般形式为:
(*pointer).memberName
或者:
pointer->memberName
第一种写法中,.的优先级高于*,(*pointer)两边的括号不能少。如果去掉括号写作*pointer.memberName,那么就等效于*(pointer.memberName),这样意义就完全不对了。
第二种写法中,->是一个新的运算符,习惯称它为“箭头”,有了它,可以通过结构体指针直接取得结构体成员;这也是->在C语言中的唯一用途。
上面的两种写法是等效的,我们通常采用后面的写法,这样更加直观。
【示例】结构体指针的使用。
#include 运行结果:
Tom的学号是12,年龄是18,在A组,今年的成绩是136.5!
Tom的学号是12,年龄是18,在A组,今年的成绩是136.5!
【示例】结构体数组指针的使用。
#include 运行结果:
Name Num Age Group Score
Zhou ping 5 18 C 145.0
Zhang ping 4 19 A 130.5
Liu fang 1 18 A 148.5
Cheng ling 2 17 F 139.0
Wang ming 3 17 B 144.5
结构体指针作为函数参数
结构体变量名代表的是整个集合本身,作为函数参数时传递的整个集合,也就是所有成员,而不是像数组一样被编译器转换成一个指针。如果结构体成员较多,尤其是成员为数组时,传送的时间和空间开销会很大,影响程序的运行效率。所以最好的办法就是使用结构体指针,这时由实参传向形参的只是一个地址,非常快速。
【示例】计算全班学生的总成绩、平均成绩和以及 140 分以下的人数。
#include 运行结果:
sum=707.50
average=141.50
num_140=2
综合
实际应用:函数指针,函数返回结构体数组指针、二维数组指针(动态内存分配)。
请转到文末!
文件I/O
目标:使用fopen fread fwrite fclose读写txt二进制文本,块数据导入导出。
fread()函数用来从指定文件中读取块数据。所谓块数据,也就是若干个字节的数据,可以是一个字符,可以是一个字符串,可以是多行数据,并没有什么限制。fread() 的原型为:
size_t fread ( void *ptr, size_t size, size_t count, FILE *fp );
fwrite()函数用来向文件中写入块数据,它的原型为:
size_t fwrite ( void * ptr, size_t size, size_t count, FILE *fp );
对参数的说明:
ptr 为内存区块的指针,它可以是数组、变量、结构体等。fread() 中的 ptr 用来存放读取到的数据,fwrite()中的 ptr 用来存放要写入的数据。
size:表示每个数据块的字节数。
count:表示要读写的数据块的块数。
fp:表示文件指针。
理论上,每次读写 size*count个字节的数据。
C预处理、C库
1-typedef:给类型起一个别名
链接:http://c.biancheng.net/cpp/html/2930.html
使用关键字 typedef 可以为类型起一个新的别名,语法格式为:
typedef oldName newName;
oldName 是类型原来的名字,newName 是类型新的名字。例如:
typedef int INTEGER;
INTEGER a, b;
a = 1;
b = 2;
INTEGER a, b;等效于int a, b;。
typedef还可以给数组、指针、结构体等类型定义别名。先来看一个给数组类型定义别名的例子:
typedef char ARRAY20[20];
表示 ARRAY20 是类型char [20]的别名。它是一个长度为 20 的数组类型。接着可以用 ARRAY20 定义数组:
ARRAY20 a1, a2, s1, s2;
它等价于:
char a1[20], a2[20], s1[20], s2[20];
注意,数组也是有类型的。例如char a1[20];定义了一个数组 a1,它的类型就是 char [20]
又如,为结构体类型定义别名:
typedef struct stu{
char name[20];
int age;
char sex;
} STU;
STU 是 struct stu 的别名,可以用 STU 定义结构体变量:
STU body1,body2;
它等价于:
struct stu body1, body2;
再如,为指针类型定义别名:
typedef int (*PTR_TO_ARR)[4];
表示 PTR_TO_ARR 是类型int * [4]的别名,它是一个二维数组指针类型。接着可以使用 PTR_TO_ARR 定义二维数组指针:
PTR_TO_ARR p1, p2;
按照类似的写法,还可以为函数指针类型定义别名:
typedef int (*PTR_TO_FUNC)(int, int);
PTR_TO_FUNC pfunc;
【示例】为指针定义别名。
#include 运行结果:
max: 20
str[0]: http://c.biancheng.net
str[1]: C语言中文网
str[2]: C-Language
需要强调的是,typedef 是赋予现有类型一个新的名字,而不是创建新的类型。为了“见名知意”,请尽量使用含义明确的标识符,并且尽量大写。
typedef 和#define 的区别
typedef 在表现上有时候类似于 #define,但它和宏替换之间存在一个关键性的区别。正确思考这个问题的方法就是把 typedef看成一种彻底的“封装”类型,声明之后不能再往里面增加别的东西。
- 可以使用其他类型说明符对宏类型名进行扩展,但对
typedef所定义的类型名却不能这样做。如下所示:
#define INTERGE int
unsigned INTERGE n; //没问题
typedef int INTERGE;
unsigned INTERGE n; //错误,不能在 INTERGE 前面添加 unsigned
- 在连续定义几个变量的时候,
typedef能够保证定义的所有变量均为同一类型,而#define则无法保证。例如:
#define PTR_INT int *
PTR_INT p1, p2;
经过宏替换以后,第二行变为:
int *p1, p2;
这使得 p1、p2 成为不同的类型:p1 是指向int 类型的指针,p2 是int 类型。
相反,在下面的代码中:
typedef int * PTR_INT
PTR_INT p1, p2;
p1、p2 类型相同,它们都是指向 int 类型的指针。
2-const:禁止修改变量的值
链接:http://c.biancheng.net/cpp/html/2930.html
3-预处理指令是以#号开头的代码行,# 号必须是该行除了任何空白字符外的第一个字符。# 后是指令关键字,在关键字和# 号之间允许存在任意个数的空白字符,整行语句构成了一条预处理指令,该指令将在编译器进行编译之前对源代码做某些转换。
3.1-宏定义:宏(Macro)是预处理命令的一种,它允许用一个标识符来表示一个字符串。
宏定义的一般形式为:
#define 宏名 字符串
带参宏调用的一般形式为:
宏名(实参列表);
例如:
#define M(y) y*y+3*y //宏定义
// Code
k=M(5); //宏调用
带参数的宏和函数很相似,但有本质上的区别:宏展开仅仅是字符串的替换,不会对表达式进行计算;宏在编译之前就被处理掉了,它没有机会参与编译,也不会占用内存。而函数是一段可以重复使用的代码,会被编译,会给它分配内存,每次调用函数,就是执行这块内存中的代码。
3.2部分预处理指令:
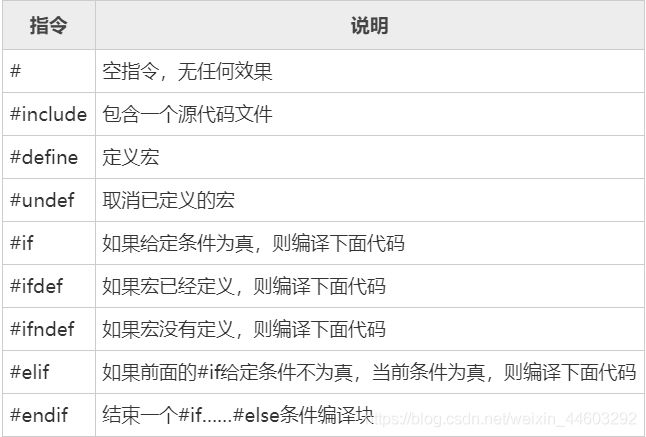
C库
标准C语言(ANSI C)共定义了15 个头文件,称为“C标准库”,所有的编译器都必须支持,如何正确并熟练的使用这些标准库,可以反映出一个程序员的水平。
合格程序员:
熟练程序员:
优秀程序员:
以上各类函数不仅数量众多,而且有的还需要硬件知识才能使用,初学者要想全部掌握得需要一个较长的学习过程。我的建议是先掌握一些最基本、最常用的函数,在实践过程中再逐步深入。由于课时关系,本教程只介绍了很少一部分库函数,其余部分读者可根据需要查阅C语言函数手册,网址是 http://www.cplusplus.com。
还应该指出的是,C语言中所有的函数定义,包括主函数 main() 在内,都是平行的。也就是说,在一个函数的函数体内,不能再定义另一个函数,即不能嵌套定义。但是函数之间允许相互调用,也允许嵌套调用。习惯上把调用者称为主调函数,被调用者称为被调函数。函数还可以自己调用自己,称为递归调用。
main() 函数是主函数,它可以调用其它函数,而不允许被其它函数调用。因此,C程序的执行总是从 main() 函数开始,完成对其它函数的调用后再返回到 main()函数,最后由main() 函数结束整个程序。
内存管理
参考:菜鸟教程:https://www.runoob.com/cprogramming/c-memory-management.html
C 语言为内存的分配和管理提供了几个函数。这些函数可以在
序号 函数和描述
1 void *calloc(int num, int size);
在内存中动态地分配 num 个长度为 size 的连续空间,并将每一个字节都初始化为 0。所以它的结果是分配了 num*size 个字节长度的内存空间,并且每个字节的值都是0。
2 void free(void *address);
该函数释放 address 所指向的内存块,释放的是动态分配的内存空间。
3 void *malloc(int num);
在堆区分配一块指定大小的内存空间,用来存放数据。这块内存空间在函数执行完成后不会被初始化,它们的值是未知的。
4 void *realloc(void *address, int newsize);
该函数重新分配内存,把内存扩展到 newsize。
注意:void * 类型表示未确定类型的指针。C、C++ 规定 void * 类型可以通过类型转换强制转换为任何其它类型的指针。
动态分配内存
编程时,如果您预先知道数组的大小,那么定义数组时就比较容易。例如,一个存储人名的数组,它最多容纳 100 个字符,所以您可以定义数组,如下所示:
char name[100];
但是,如果您预先不知道需要存储的文本长度,例如您想存储有关一个主题的详细描述。在这里,我们需要定义一个指针,该指针指向未定义所需内存大小的字符,后续再根据需求来分配内存,如下所示:
实例
#include 当上面的代码被编译和执行时,它会产生下列结果:
Name = Zara Ali
Description: Zara ali a DPS student in class 10th
上面的程序也可以使用calloc() 来编写,只需要把 malloc 替换为calloc 即可,如下所示:
calloc(200, sizeof(char));
当动态分配内存时,您有完全控制权,可以传递任何大小的值。而那些预先定义了大小的数组,一旦定义则无法改变大小。
重新调整内存的大小和释放内存
当程序退出时,操作系统会自动释放所有分配给程序的内存,但是,建议您在不需要内存时,都应该调用函数 free() 来释放内存。
或者,您可以通过调用函数realloc() 来增加或减少已分配的内存块的大小。让我们使用 realloc() 和 free()函数,再次查看上面的实例:
实例
#include 当上面的代码被编译和执行时,它会产生下列结果:
Name = Zara Ali
Description: Zara ali a DPS student.She is in class 10th
您可以尝试一下不重新分配额外的内存,strcat()函数会生成一个错误,因为存储 description 时可用的内存不足。
一般遇到数组溢出和指针溢出比较多,自己要当心;
内存泄漏 一般是分配的内存没有及时回收所致,本人可以预知的原因一般有:重复对同一个指针变量进行动态内存分配导致之前分配的无法释放;函数封装导致函数指针返回的内存跨域,从而导致内存无法回收。这种错误往往很难发现,在定义函数指针时需要格外注意。
二维数组动态内存分配(内存连续),参考链接:
https://www.cnblogs.com/huashiyiqike/articles/2887082.html
函数指针实现类封装、继承、多态
指针函数与函数指针:
https://www.jb51.net/article/82723.htm
函数指针实现类
参考链接:
https://www.cnblogs.com/liangxiaofeng/p/4312476.html
测试代码:https://www.cnblogs.com/luosongchao/p/3663882.html
参考源码:
本地文件:E:\...\MyWorkWontent\C_C++_learning\DataStructureC_Yutq\LinearList
对应的GitHub地址:忘记了,没找到
二:C++部分
先入个门,能看懂大概语法
参考:菜鸟教程:
https://www.runoob.com/cplusplus/cpp-intro.html
基础
主要用来记录基础部分C++与C的一些区别,不涉及到对象、类等C++高级玩法。
HelloWorld
先来个 HelloWorld.cpp
#include 流算子
再看,对流算子的操作:
#include 输出结果:
1)8d 141 215
2)1.2346e+006 12.346
3)1234567.89000 12.34567
4)1.23457e+006 1.23457e+001
5)***+12.10000
6)12.10000****
7)****12.10000
8)-***12.10000
9)12.10000
小结:输入输出:C++ VS C
输出:cout 可取代printf ,输入:cin取代scanf
示例如下:
#include 结果如下:
请依次输入一个字符、一个整数、一个浮点数:
r
6
7.5
字符是:r ;整数是:6 ;浮点数是:7.5 !
实例:输入输出流中的函数(模板)
#include 输出结果:
123.46
****123.46
999.123
1.235e+02
其中cout.setf 跟 setiosflags 一样,cout.precision 跟 setprecision 一样,cout.unsetf 跟 resetiosflags 一样。
setiosflags(ios::fixed) 固定的浮点显示
setiosflags(ios::scientific) 指数表示
setiosflags(ios::left) 左对齐
setiosflags(ios::right) 右对齐
setiosflags(ios::skipws 忽略前导空白
setiosflags(ios::uppercase) 16进制数大写输出
setiosflags(ios::lowercase) 16进制小写输出
setiosflags(ios::showpoint) 强制显示小数点
setiosflags(ios::showpos) 强制显示符号
iostream中定义的操作符:
操作符 描述 输入 输出
boolalpha 启用boolalpha标志 √ √
dec 启用dec标志 √ √
endl 输出换行标示,并清空缓冲区 √
ends 输出空字符 √
fixed 启用fixed标志 √
flush 清空流 √
hex 启用 hex 标志 √ √
internal 启用 internal 标志 √
left 启用 left 标志 √
noboolalpha 关闭boolalpha 标志 √ √
noshowbase 关闭showbase 标志 √
noshowpoint 关闭showpoint 标志 √
noshowpos 关闭showpos 标志 √
noskipws 关闭skipws 标志 √
nounitbuf 关闭unitbuf 标志 √
nouppercase 关闭uppercase 标志 √
oct 启用 oct 标志 √ √
right 启用 right 标志 √
scientific 启用 scientific 标志 √
showbase 启用 showbase 标志 √
showpoint 启用 showpoint 标志 √
showpos 启用 showpos 标志 √
skipws 启用 skipws 标志 √
unitbuf 启用 unitbuf 标志 √
uppercase 启用 uppercase 标志 √
ws 跳过所有前导空白字符 √
iomanip 中定义的操作符:
操作符 描述 输入 输出
resetiosflags(long f) 关闭被指定为f的标志 √ √
setbase(int base) 设置数值的基本数为base √
setfill(int ch) 设置填充字符为ch √
setiosflags(long f) 启用指定为f的标志 √ √
setprecision(int p) 设置数值的精度(四舍五入) √
setw(int w) 设置域宽度为w √
数据类型
实例:输出您电脑上各种数据类型的大小。
#include::max)() << "\t最小值:" << (numeric_limits::min)() << endl;
cout << "type: \t\t" << "************size**************"<< endl;
return 0;
}
输出结果:
type: ************size**************
bool: 所占字节数:1 最大值:1 最小值:0
char: 所占字节数:1 最大值: 最小值:€
signed char: 所占字节数:1 最大值: 最小值:€
unsigned char: 所占字节数:1 最大值: 最小值:
wchar_t: 所占字节数:2 最大值:65535 最小值:0
short: 所占字节数:2 最大值:32767 最小值:-32768
int: 所占字节数:4 最大值:2147483647 最小值:-2147483648
unsigned: 所占字节数:4 最大值:4294967295 最小值:0
long: 所占字节数:4 最大值:2147483647 最小值:-2147483648
unsigned long: 所占字节数:4 最大值:4294967295 最小值:0
double: 所占字节数:8 最大值:1.79769e+308 最小值:2.22507e-308
long double: 所占字节数:8 最大值:1.79769e+308 最小值:2.22507e-308
float: 所占字节数:4 最大值:3.40282e+038 最小值:1.17549e-038
size_t: 所占字节数:4 最大值:4294967295 最小值:0
string: 所占字节数:32
type: ************size**************
限定符
C++ 中的类型限定符
类型限定符提供了变量的额外信息。
限定符 含义
const const 类型的对象在程序执行期间不能被修改改变。
volatile 修饰符 volatile 告诉编译器不需要优化volatile声明的变量,让程序可以直接从内存中读取变量。对于一般的变量编译器会对变量进行优化,将内存中的变量值放在寄存器中以加快读写效率。
restrict 由 restrict 修饰的指针是唯一一种访问它所指向的对象的方式。只有 C99 增加了新的类型限定符 restrict。
存储类
C++ 存储类
存储类定义 C++ 程序中变量/函数的范围(可见性)和生命周期。这些说明符放置在它们所修饰的类型之前。下面列出 C++ 程序中可用的存储类:
auto
register
static
extern
mutable
thread_local (C++11)
从 C++ 17 开始,auto 关键字不再是 C++ 存储类说明符,且 register 关键字被弃用。
auto 存储类,根据初始化表达式自动推断被声明的变量的类型,如:
auto f=3.14; //double
auto s("hello"); //const char*
auto z = new auto(9); // int*
auto x1 = 5, x2 = 5.0, x3='r';//错误,必须是初始化为同一类型
static 存储类
static 存储类指示编译器在程序的生命周期内保持局部变量的存在,而不需要在每次它进入和离开作用域时进行创建和销毁。因此,使用 static 修饰局部变量可以在函数调用之间保持局部变量的值。
static 修饰符也可以应用于全局变量。当 static 修饰全局变量时,会使变量的作用域限制在声明它的文件内。
实例:
#include 输出结果为:
变量 i 为 6 , 变量 count 为 9
变量 i 为 7 , 变量 count 为 8
变量 i 为 8 , 变量 count 为 7
变量 i 为 9 , 变量 count 为 6
变量 i 为 10 , 变量 count 为 5
变量 i 为 11 , 变量 count 为 4
变量 i 为 12 , 变量 count 为 3
变量 i 为 13 , 变量 count 为 2
变量 i 为 14 , 变量 count 为 1
变量 i 为 15 , 变量 count 为 0
extern 存储类
extern 存储类用于提供一个全局变量的引用,全局变量对所有的程序文件都是可见的。当您使用 ‘extern’ 时,对于无法初始化的变量,会把变量名指向一个之前定义过的存储位置。
当您有多个文件且定义了一个可以在其他文件中使用的全局变量或函数时,可以在其他文件中使用 extern 来得到已定义的变量或函数的引用。可以这么理解,extern 是用来在另一个文件中声明一个全局变量或函数。
extern 修饰符通常用于当有两个或多个文件共享相同的全局变量或函数的时候,如下所示:
第一个文件:main.cpp
#include 第二个文件:support.cpp
#include 在这里,第二个文件中的 extern 关键字用于声明已经在第一个文件 main.cpp 中定义的 count。现在 ,编译这两个文件,如下所示:
$ g++ main.cpp support.cpp -o write
这会产生 write 可执行程序,尝试执行 write,它会产生下列结果:
$ ./write
Count is 5
随机数
C++ 随机数
在许多情况下,需要生成随机数。关于随机数生成器,有两个相关的函数。一个是 rand(),该函数只返回一个伪随机数。生成随机数之前必须先调用 srand() 函数。
下面是一个关于生成随机数的简单实例。实例中使用了 time() 函数来获取系统时间的秒数,通过调用 rand() 函数来生成随机数:
#include 运行结果:
随机数: 1748144778
随机数: 630873888
随机数: 2134540646
随机数: 219404170
随机数: 902129458
随机数: 920445370
随机数: 1319072661
随机数: 257938873
随机数: 1256201101
随机数: 580322989
C随机数 用于生成随机噪声数据
实例:
#include运行结果:
**********分隔栏************
rand:15526 ;random1:9
rand:4284 ;random1:0
rand:12136 ;random1:3
rand:7907 ;random1:2
rand:14223 ;random1:8
rand:22645 ;random1:8
rand:22640 ;random1:9
rand:25105 ;random1:7
rand:5947 ;random1:8
rand:778 ;random1:5
**********分隔栏************
rand:21376 ;random2:0.891
rand:25101 ;random2:0.263
rand:2290 ;random2:0.429
rand:29956 ;random2:0.139
rand:24170 ;random2:0.985
rand:10299 ;random2:0.424
rand:9775 ;random2:0.884
rand:193 ;random2:0.502
rand:13172 ;random2:0.668
rand:15890 ;random2:0.518
**********分隔栏************
rand:10530 ;random3:-0.4180
rand:16114 ;random3:0.7680
rand:9688 ;random3:-0.5785
rand:11676 ;random3:0.2696
rand:28976 ;random3:-0.5148
rand:14108 ;random3:-0.2738
rand:3653 ;random3:-0.7893
rand:20986 ;random3:0.4246
rand:22386 ;random3:-0.0584
rand:22552 ;random3:0.9688
**********分隔栏************
字符串
C++ 字符串
C++ 提供了以下两种类型的字符串表示形式:
C 风格字符串
C++ 引入的 string 类类型
C 风格字符串
C 风格的字符串起源于 C 语言,并在 C++ 中继续得到支持。字符串实际上是使用 null 字符 ‘\0’ 终止的一维字符数组。因此,一个以 null 结尾的字符串,包含了组成字符串的字符。
下面的声明和初始化创建了一个 “Hello” 字符串。由于在数组的末尾存储了空字符,所以字符数组的大小比单词 “Hello” 的字符数多一个。
char greeting[6] = {'H', 'e', 'l', 'l', 'o', '\0'};
依据数组初始化规则,您可以把上面的语句写成以下语句:
char greeting[] = "Hello";
其实,您不需要把 null 字符放在字符串常量的末尾。C++ 编译器会在初始化数组时,自动把 ‘\0’ 放在字符串的末尾。让我们尝试输出上面的字符串:
实例:
#include C++ 中有大量的函数用来操作以 null 结尾的字符串:
序号 函数 & 目的
1 strcpy(s1, s2); 复制字符串 s2 到字符串 s1。
2 strcat(s1, s2); 连接字符串 s2 到字符串 s1 的末尾。
3 strlen(s1); 返回字符串 s1 的长度。
4 strcmp(s1, s2); 如果 s1 和 s2 是相同的,则返回 0;如果 s1<s2 则返回值小于 0;如果 s1>s2 则返回值大于 0。
5 strchr(s1, ch); 返回一个指针,指向字符串 s1 中字符 ch 的第一次出现的位置。
6 strstr(s1, s2); 返回一个指针,指向字符串 s1 中字符串 s2 的第一次出现的位置。
C++ 中的 String 类
C++ 标准库提供了 string 类类型,支持上述所有的操作,另外还增加了其他更多的功能。我们将学习 C++ 标准库中的这个类,现在让我们先来看看下面这个实例:
现在您可能还无法透彻地理解这个实例,因为到目前为止我们还没有讨论类和对象。所以现在您可以只是粗略地看下这个实例,等理解了面向对象的概念之后再回头来理解这个实例。
#include 输出结果如下:
str3 : Hello
str1 + str2 : HelloWorld
str3.size() : 10
结构体
C++ 数据结构
访问结构成员
为了访问结构的成员,我们使用成员访问运算符(.)。成员访问运算符是结构变量名称和我们要访问的结构成员之间的一个句号。
下面的实例演示了结构的用法:
#include 运行结果:
第一本书标题 : 机器人学导论(第四版)
第一本书作者 : JOHN J.Craig
第一本书类目 : 人工智能/机器人
第一本书 ID : -1118877268
第二本书标题 : 机器人控制系统的设计与MATLAB仿真
第二本书作者 : 刘金坤
第二本书类目 : 机器人/自动控制
第二本书 ID : -927997501
结构作为函数参数
您可以把结构作为函数参数,传参方式与其他类型的变量或指针类似。您可以使用上面实例中的方式来访问结构变量:
#include 运行结果:
书标题 : 数值方法(MATLAB版)
书作者 : John H.Mathews
书类目 : 数学教材-计算机计算方法
书 ID : 3214995
书标题 : 机器人手册
书作者 : Bruno Siciliano
书类目 : 工业技术/机器人
书 ID : 73745757
指向结构的指针
您可以定义指向结构的指针,方式与定义指向其他类型变量的指针相似,如下所示:
struct Books *struct_pointer;
现在,您可以在上述定义的指针变量中存储结构变量的地址。为了查找结构变量的地址,请把 & 运算符放在结构名称的前面,如下所示:
struct_pointer = &Book1;
为了使用指向该结构的指针访问结构的成员,您必须使用 -> 运算符,如下所示:
struct_pointer->title;
让我们使用结构指针来重写上面的实例,这将有助于您理解结构指针的概念:
#include 运行结果:
书标题 : C++ 教程
书作者 : Runoob
书类目 : 编程语言
书 ID : 12345
书标题 : CSS 教程
书作者 : Runoob
书类目 : 前端技术
书 ID : 12346
类(class)&对象(object)
参考:C语言中文网 :http://c.biancheng.net/cpp/biancheng/view/2968.html
概念
C++中的类(Class)可以看做C语言中结构体(Struct)的升级版。结构体是一种构造类型,可以包含若干成员变量,每个成员变量的类型可以不同;可以通过结构体来定义结构体变量,每个变量拥有相同的性质。C++中的类也是一种构造类型,但是进行了一些扩展,类的成员不但可以是变量,还可以是函数;通过类定义出来的变量也有特定的称呼,叫做“对象”。例如:
#include C语言中的 struct 只能包含变量,而C++中的 class 除了可以包含变量,还可以包含函数。display() 是用来处理成员变量的函数,在C语言中,我们将它放在了 struct Student 外面,它和成员变量是分离的;而在C++中,我们将它放在了 class Student 内部,使它和成员变量聚集在一起,看起来更像一个整体。
结构体和类都可以看做一种由用户自己定义的复杂数据类型,在C语言中可以通过结构体名来定义变量,在C++中可以通过类名来定义变量。不同的是,通过结构体定义出来的变量还是叫变量,而通过类定义出来的变量有了新的名称,叫做对象(Object)。
类只是一张图纸,起到说明的作用,不占用内存空间;对象才是具体的零件,要有地方来存放,才会占用内存空间。
在C++中,通过类名就可以创建对象,即将图纸生产成零件,这个过程叫做类的实例化,因此也称对象是类的一个实例(Instance)。
有些资料也将类的成员变量称为属性(Property),将类的成员函数称为方法(Method)。(说的是Python吗?)
面向对象编程(Object Oriented Programming,OOP)
类是一个通用的概念,C++、Java、C#、PHP 等很多编程语言中都支持类,都可以通过类创建对象。可以将类看做是结构体的升级版,C语言的晚辈们看到了C语言的不足,尝试加以改善,继承了结构体的思想,并进行了升级,让程序员在开发或扩展大中型项目时更加容易。
因为 C++、Java、C#、PHP 等语言都支持类和对象,所以使用这些语言编写程序也被称为面向对象编程,这些语言也被称为面向对象的编程语言。C语言因为不支持类和对象的概念,被称为面向过程的编程语言。
面向对象编程在代码执行效率上绝对没有任何优势,它的主要目的是方便程序员组织和管理代码,快速梳理编程思路,带来编程思想上的革新。
C语言中项目的组织方式
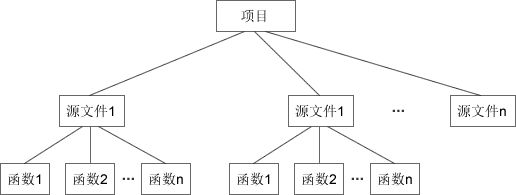
C++中项目的组织方式
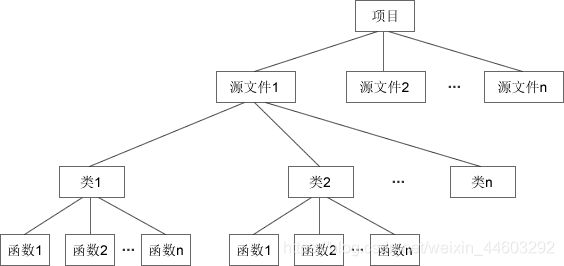
面向对象编程是针对开发中大规模的程序而提出来的,目的是提高软件开发的效率。不要把面向对象和面向过程对立起来,面向对象和面向过程不是矛盾的,而是各有用途、互为补充的。如果你希望开发一个贪吃蛇游戏,类和对象或许是多余的,几个函数就可以搞定;但如果开发一款大型游戏,那你绝对离不开面向对象。
类的定义和创建
类是创建对象的模板,一个类可以创建多个对象,每个对象都是类类型的一个变量;创建对象的过程也叫类的实例化。每个对象都是类的一个具体实例(Instance),拥有类的成员变量和成员函数。
有些教程将类的成员变量称为类的属性(Property),将类的成员函数称为类的方法(Method)。在面向对象的编程语言中,经常把函数(Function)称为方法(Method)。
与结构体一样,类只是一种复杂数据类型的声明,不占用内存空间。而对象是类这种数据类型的一个变量,或者说是通过类这种数据类型创建出来的一份实实在在的数据,所以占用内存空间。
类只是一个模板(Template),编译后不占用内存空间,所以在定义类时不能对成员变量进行初始化,因为没有地方存储数据。只有在创建对象以后才会给成员变量分配内存,这个时候就可以赋值了。
类可以理解为一种新的数据类型,该数据类型的名称是 Student。与 char、int、float等基本数据类型不同的是,Student是一种复杂数据类型,可以包含基本类型,而且还有很多基本类型中没有的特性,以后大家会见到。
对象指针
C语言中经典的指针在 C++ 中仍然广泛使用,尤其是指向对象的指针,没有它就不能实现某些功能。
上面代码中创建的对象 stu 在栈上分配内存,需要使用&获取它的地址,例如:
Student stu;
Student *pStu = &stu;
pStu 是一个指针,它指向 Student类型的数据,也就是通过 Student 创建出来的对象。
当然,你也可以在堆上创建对象,这个时候就需要使用前面讲到的new关键字,例如:
Student *pStu = new Student;
在栈上创建出来的对象都有一个名字,比如stu,使用指针指向它不是必须的。但是通过 new 创建出来的对象就不一样了,它在堆上分配内存,没有名字,只能得到一个指向它的指针,所以必须使用一个指针变量来接收这个指针,否则以后再也无法找到这个对象了,更没有办法使用它。也就是说,使用 new 在堆上创建出来的对象是匿名的,没法直接使用,必须要用一个指针指向它,再借助指针来访问它的成员变量或成员函数。
栈内存是程序自动管理的,不能使用 delete 删除在栈上创建的对象;堆内存由程序员管理,对象使用完毕后可以通过delete 删除。在实际开发中,new 和delete 往往成对出现,以保证及时删除不再使用的对象,防止无用内存堆积。
栈(Stack)和堆(Heap)是 C/C++ 程序员必须要了解的两个概念,我们已在《C语言和内存》专题中进行了深入讲解,相信你必将有所顿悟。
有了对象指针后,可以通过箭头->来访问对象的成员变量和成员函数,这和通过结构体指针来访问它的成员类似,请看下面的示例:
pStu -> name = "小明";
pStu -> age = 15;
pStu -> score = 92.5f;
pStu -> say();
下面是一个完整的例子:
#include 总结
本节重点讲解了两种创建对象的方式:一种是在栈上创建,形式和定义普通变量类似;另外一种是在堆上创建,必须要用一个指针指向它,读者要记得 delete 掉不再使用的对象。
通过对象名字访问成员使用点号.,通过对象指针访问成员使用箭头->,这和结构体非常类似。
类的成员变量和成员函数
类可以看做是一种数据类型,它类似于普通的数据类型,但是又有别于普通的数据类型。类这种数据类型是一个包含成员变量和成员函数的集合。
类的成员变量和普通变量一样,也有数据类型和名称,占用固定长度的内存。但是,在定义类的时候不能对成员变量赋值,因为类只是一种数据类型或者说是一种模板,本身不占用内存空间,而变量的值则需要内存来存储。
类的成员函数也和普通函数一样,都有返回值和参数列表,它与一般函数的区别是:成员函数是一个类的成员,出现在类体中,它的作用范围由类来决定;而普通函数是独立的,作用范围是全局的,或位于某个命名空间内。
上节我们在示例中给出了 Student 类的定义,如下所示:
class Student{
public:
//成员变量
char *name;
int age;
float score;
//成员函数
void say(){
cout<<name<<"的年龄是"<<age<<",成绩是"<<score<<endl;
}
};
这段代码在类体中定义了成员函数。你也可以只在类体中声明函数,而将函数定义放在类体外面,如下图所示:
class Student{
public:
//成员变量
char *name;
int age;
float score;
//成员函数
void say(); //函数声明
};
//函数定义
void Student::say(){
cout<<name<<"的年龄是"<<age<<",成绩是"<<score<<endl;
}
在类体中直接定义函数时,不需要在函数名前面加上类名,因为函数属于哪一个类是不言而喻的。
但当成员函数定义在类外时,就必须在函数名前面加上类名予以限定。::被称为域解析符(也称作用域运算符或作用域限定符),用来连接类名和函数名,指明当前函数属于哪个类。
成员函数必须先在类体中作原型声明,然后在类外定义,也就是说类体的位置应在函数定义之前。
inline成员函数
在类体中和类体外定义成员函数是有区别的:在类体中定义的成员函数会自动成为内联函数,在类体外定义的不会。当然,在类体内部定义的函数也可以加 inline 关键字,但这是多余的,因为类体内部定义的函数默认就是内联函数。
内联函数一般不是我们所期望的,它会将函数调用处用函数体替代,所以我建议在类体内部对成员函数作声明,而在类体外部进行定义,这是一种良好的编程习惯,实际开发中大家也是这样做的。
当然,如果你的函数比较短小,希望定义为内联函数,那也没有什么不妥的。
如果你既希望将函数定义在类体外部,又希望它是内联函数,那么可以在定义函数时加 inline 关键字。当然你也可以在函数声明处加inline,不过这样做没有效果,编译器会忽略函数声明处的 inline,我们已在《如何规范地使用C++内联函数》中对这点进行了详细讲解。
下面是一个将内联函数定义在类外部的例子:
class Student{
public:
char *name;
int age;
float score;
void say(); //内联函数声明,可以增加 inline 关键字,但编译器会忽略
};
//函数定义
inline void Student::say(){
cout<<name<<"的年龄是"<<age<<",成绩是"<<score<<endl;
}
这样,say() 就会变成内联函数。
这种在类体外定义inline 函数的方式,必须将类的定义和成员函数的定义都放在同一个头文件中(或者同一个源文件中),否则编译时无法进行嵌入(将函数代码的嵌入到函数调用出),具体原因我们已在《如何规范地使用C++内联函数》中进行了讲解。
再次强调,虽然 C++ 支持将内联函数定义在类的外部,但我强烈建议将函数定义在类的内部,这样它会自动成为内联函数,何必费力不讨好地将它定义在类的外部呢,这样并没有任何优势。
类成员的访问权限(封装)
C++通过public、protected、private 三个关键字来控制成员变量和成员函数的访问权限,它们分别表示公有的、受保护的、私有的,被称为成员访问限定符。所谓访问权限,就是你能不能使用该类中的成员。
在类的内部(定义类的代码内部),无论成员被声明为 public、protected 还是 private,都是可以互相访问的,没有访问权限的限制。
在类的外部(定义类的代码之外),只能通过对象访问成员,并且通过对象只能访问 public 属性的成员,不能访问 private、protected 属性的成员。
本节重点讲解 public 和 private,protected将在继承中讲解。
下面通过一个 Student 类来演示成员的访问权限:
#include 运行结果:
小明的年龄是15,成绩是92.5
李华的年龄是16,成绩是96
类的声明和成员函数的定义都是类定义的一部分,在实际开发中,我们通常将类的声明放在头文件中,而将成员函数的定义放在源文件中。
类中的成员变量 m_name、m_age 和m_ score 被设置成 private 属性,在类的外部不能通过对象访问。也就是说,私有成员变量和成员函数只能在类内部使用,在类外都是无效的。
成员函数setname()、setage() 和 setscore()被设置为public属性,是公有的,可以通过对象访问。
private后面的成员都是私有的,直到有 public出现才会变成共有的;public之后再无其他限定符,所以 public 后面的成员都是共有的。
成员变量大都以m_开头,这是约定成俗的写法,不是语法规定的内容。以m_开头既可以一眼看出这是成员变量,又可以和成员函数中的形参名字区分开。
以 setname()为例,如果将成员变量m_name的名字修改为name,那么 setname()的形参就不能再叫name了,得换成诸如name1、_name这样没有明显含义的名字,否则name=name;这样的语句就是给形参name赋值,而不是给成员变量name赋值。
因为三个成员变量都是私有的,不能通过对象直接访问,所以必须借助三个public 属性的成员函数来修改它们的值。下面的代码是错误的:
Student stu;
//m_name、m_age、m_score 是私有成员变量,不能在类外部通过对象访问
stu.m_name = "小明";
stu.m_age = 15;
stu.m_score = 92.5f;
stu.show();
简单地谈类的封装
private 关键字的作用在于更好地隐藏类的内部实现,该向外暴露的接口(能通过对象访问的成员)都声明为public,不希望外部知道、或者只在类内部使用的、或者对外部没有影响的成员,都建议声明为 private。
根据C++软件设计规范,实际项目开发中的成员变量以及只在类内部使用的成员函数(只被成员函数调用的成员函数)都建议声明为 private,而只将允许通过对象调用的成员函数声明为 public。
另外还有一个关键字 protected,声明为 protected 的成员在类外也不能通过对象访问,但是在它的派生类内部可以访问,这点我们将在后续章节中介绍,现在你只需要知道 protected 属性的成员在类外无法访问即可。
有读者可能会提出疑问,将成员变量都声明为 private,如何给它们赋值呢,又如何读取它们的值呢?
我们可以额外添加两个public 属性的成员函数,一个用来设置成员变量的值,一个用来修改成员变量的值。上面的代码中,setname()、setage()、setscore()函数就用来设置成员变量的值;如果希望获取成员变量的值,可以再添加三个函数getname()、getage()、getscore()。
给成员变量赋值的函数通常称为 set 函数,它们的名字通常以set开头,后跟成员变量的名字;读取成员变量的值的函数通常称为 get 函数,它们的名字通常以get开头,后跟成员变量的名字。
除了 set函数和 get函数,在创建对象时还可以调用构造函数来初始化各个成员变量,我们将在《C++构造函数》一节中展开讨论。不过构造函数只能给成员变量赋值一次,以后再修改还得借助 set函数。
这种将成员变量声明为 private、将部分成员函数声明为 public 的做法体现了类的封装性。所谓封装,是指尽量隐藏类的内部实现,只向用户提供有用的成员函数。
有读者可能会说,额外添加 set 函数和 get函数多麻烦,直接将成员变量设置为 public 多省事!确实,但将成员变量设置为 private 是一种软件设计规范,尤其是在大中型项目中,还是请大家尽量遵守这一原则。
为了减少代码量,方便说明问题,本教程中的类可能会将成员变量设置为public,请读者不要认为这是一种错误。
对private和public的更多说明
声明为 private 的成员和声明为public 的成员的次序任意,既可以先出现 private 部分,也可以先出现 public 部分。如果既不写 private 也不写 public,就默认为 private。
在一个类体中,private 和 public 可以分别出现多次。每个部分的有效范围到出现另一个访问限定符或类体结束时(最后一个右花括号)为止。但是为了使程序清晰,应该养成这样的习惯,使每一种成员访问限定符在类定义体中只出现一次。
下面的类声明也是完全正确的:
class Student{
private:
char *m_name;
private:
int m_age;
float m_score;
public:
void setname(char *name);
void setage(int age);
public:
void setscore(float score);
void show();
};
构造函数(Constructor)
在C++中,有一种特殊的成员函数,它的名字和类名相同,没有返回值,不需要用户显式调用(用户也不能调用),而是在创建对象时自动执行。这种特殊的成员函数就是构造函数(Constructor)。
在《C++类成员的访问权限》一节中,我们通过成员函数 setname()、setage()、setscore()分别为成员变量 name、age、score赋值,这样做虽然有效,但显得有点麻烦。有了构造函数,我们就可以简化这项工作,在创建对象的同时为成员变量赋值,请看下面的代码(示例1):
#include 运行结果:
小明的年龄是15,成绩是92.5
李华的年龄是16,成绩是96
该例在 Student 类中定义了一个构造函数Student(char *, int, float),它的作用是给三个private属性的成员变量赋值。要想调用该构造函数,就得在创建对象的同时传递实参,并且实参由( )包围,和普通的函数调用非常类似。
在栈上创建对象时,实参位于对象名后面,例如Student stu("小明", 15, 92.5f);在堆上创建对象时,实参位于类名后面,例如new Student("李华", 16, 96)。
构造函数必须是 public 属性的,否则创建对象时无法调用。当然,设置为 private、protected 属性也不会报错,但是没有意义。
构造函数没有返回值,因为没有变量来接收返回值,即使有也毫无用处,这意味着:
不管是声明还是定义,函数名前面都不能出现返回值类型,即使是void 也不允许;函数体中不能有 return 语句。
构造函数的重载
和普通成员函数一样,构造函数是允许重载的。一个类可以有多个重载的构造函数,创建对象时根据传递的实参来判断调用哪一个构造函数。
构造函数的调用是强制性的,一旦在类中定义了构造函数,那么创建对象时就一定要调用,不调用是错误的。如果有多个重载的构造函数,那么创建对象时提供的实参必须和其中的一个构造函数匹配;反过来说,创建对象时只有一个构造函数会被调用。
对示例1中的代码,如果写作Student stu或者new Student就是错误的,因为类中包含了构造函数,而创建对象时却没有调用。
更改示例1的代码,再添加一个构造函数(示例2):
#include 运行结果:
小明的年龄是15,成绩是92.5
成员变量还未初始化
李华的年龄是16,成绩是96
构造函数Student(char *, int, float)为各个成员变量赋值,构造函数Student()将各个成员变量的值设置为空,它们是重载关系。根据Student()创建对象时不会赋予成员变量有效值,所以还要调用成员函数 setname()、setage()、setscore()来给它们重新赋值。
构造函数在实际开发中会大量使用,它往往用来做一些初始化工作,例如对成员变量赋值、预先打开文件等。
默认构造函数
如果用户自己没有定义构造函数,那么编译器会自动生成一个默认的构造函数,只是这个构造函数的函数体是空的,也没有形参,也不执行任何操作。比如上面的 Student类,默认生成的构造函数如下:
Student(){}
一个类必须有构造函数,要么用户自己定义,要么编译器自动生成。一旦用户自己定义了构造函数,不管有几个,也不管形参如何,编译器都不再自动生成。在示例1中,Student类已经有了一个构造函数Student(char *, int, float),也就是我们自己定义的,编译器不会再额外添加构造函数Student(),在示例2中我们才手动添加了该构造函数。
实际上编译器只有在必要的时候才会生成默认构造函数,而且它的函数体一般不为空。默认构造函数的目的是帮助编译器做初始化工作,而不是帮助程序员。这是C++的内部实现机制,这里不再深究,初学者可以按照上面说的“一定有一个空函数体的默认构造函数”来理解。
最后需要注意的一点是,调用没有参数的构造函数也可以省略括号。对于示例2的代码,在栈上创建对象可以写作Student stu()或Student stu,在堆上创建对象可以写作Student *pstu = new Student()或Student *pstu = new Student,它们都会调用构造函数 Student()。
以前我们就是这样做的,创建对象时都没有写括号,其实是调用了默认的构造函数。
构造函数的参数初始化表
构造函数的一项重要功能是对成员变量进行初始化,为了达到这个目的,可以在构造函数的函数体中对成员变量一一赋值,还可以采用参数初始化表。
参数初始化表使得代码更加简洁,请看下面的例子:
#include 运行结果:
小明的年龄是15,成绩是92.5
李华的年龄是16,成绩是96
如本例所示,定义构造函数时并没有在函数体中对成员变量一一赋值,其函数体为空(当然也可以有其他语句),而是在函数首部与函数体之间添加了一个冒号:,后面紧跟m_name(name), m_age(age), m_score(score)语句,这个语句的意思相当于函数体内部的m_name = name; m_age = age; m_score = score;语句,也是赋值的意思。
使用参数初始化表并没有效率上的优势,仅仅是书写方便,尤其是成员变量较多时,这种写法非常简明明了。
参数初始化表可以用于全部成员变量,也可以只用于部分成员变量。下面的示例只对 m_name使用参数初始化表,其他成员变量还是一一赋值:
Student::Student(char *name, int age, float score): m_name(name)
{
m_age = age;
m_score = score;
}
注意,参数初始化顺序与初始化表列出的变量的顺序无关,它只与成员变量在类中声明的顺序有关。请看代码:
#include 运行结果:
2130567168, 100
在参数初始化表中,我们将 m_b 放在了 m_a 的前面,看起来是先给 m_b 赋值,再给 m_a 赋值,其实不然!成员变量的赋值顺序由它们在类中的声明顺序决定,在 Demo 类中,我们先声明的 m_a,再声明的 m_b,所以构造函数和下面的代码等价:
Demo::Demo(int b): m_b(b), m_a(m_b){
m_a = m_b;
m_b = b;
}
给 m_a 赋值时,m_b还未被初始化,它的值是不确定的,所以输出的m_a 的值是一个奇怪的数字;给 m_a 赋值完成后才给 m_b 赋值,此时 m_b 的值才是 100。obj 在栈上分配内存,成员变量的初始值是不确定的。
初始化 const 成员变量
参数初始化表还有一个很重要的作用,那就是初始化 const 成员变量。初始化 const成员变量的唯一方法就是使用参数初始化表。例如 VS/VC 不支持变长数组(数组长度不能是变量),我们自己定义了一个 VLA 类,用于模拟变长数组,请看下面的代码:
class VLA{
private:
const int m_len;
int *m_arr;
public:
VLA(int len);
};
//必须使用参数初始化表来初始化 m_len
VLA::VLA(int len): m_len(len){
m_arr = new int[len];
}
VLA 类包含了两个成员变量,m_len 和 m_arr 指针,需要注意的是 m_len 加了 const 修饰,只能使用参数初始化表的方式赋值,如果写作下面的形式是错误的:
class VLA{
private:
const int m_len;
int *m_arr;
public:
VLA(int len);
};
VLA::VLA(int len){
m_len = len;
m_arr = new int[len];
}
析构函数(Destructor)
this指针详解
static静态成员变量
http://c.biancheng.net/cpp/biancheng/view/2968.html
static静态成员函数
http://c.biancheng.net/cpp/biancheng/view/2968.html
类与const关键字
http://c.biancheng.net/cpp/biancheng/view/2968.html
class和struct的区别
http://c.biancheng.net/cpp/biancheng/view/2968.html
动态内存
模板 template
函数模板
类模板
STL模板类:string,vector、array
STL(标准模板库)
参考:https://www.runoob.com/cplusplus/cpp-stl-tutorial.html
C++ STL(标准模板库)是一套功能强大的 C++ 模板类,提供了通用的模板类和函数,这些模板类和函数可以实现。
多种流行和常用的算法和数据结构,如向量、链表、队列、栈。
C++ 标准模板库的核心包括以下三个组件:
容器 Containers;算法 Algorithms;迭代器 iterators
容器 Containers
算法 Algorithms
迭代器 iterators
几个重要类: string array vector
参考:C++ Primer
http://c.biancheng.net/cpp/biancheng/view/2968.html
https://www.cnblogs.com/wenruo/p/4492694.html
string
array
vector
三:编程实践
应用案例
应用案例如下所示,但限于篇幅,会另外辟文展开。
矩阵运算与线性代数
包括:矩阵求逆、矩阵转置、矩阵相乘、矩阵分解、线性方程组最小二乘解
SCARA运动学建模、DH参数标定
相机手眼标定
运动规划
路径规划/轨迹规划:直线与圆弧规划
轨迹规划:圆弧/多项式/抛物线过渡
轨迹规划:局部贝塞尔曲线与全局B样条曲线
速度规划-指定时间七段加减速算法
循环顺序线性队列
OpenGL实时(双缓冲技术)绘制散点图
用于绘制散点数据,数据来源为二维数组或者循环队列,维度:空间一维/二维/三维。
多线程与线程锁
线程库
数值计算方法
优化算法
Debug日志杂记
1-VS2010 WIN32 控制台 预编译头文件(非空那个)。F5:走断点;F10:函数内部单步调试;F11:断点处进入函数内部。SouceInght:Ctrl+F查找。解决跨平台编辑文本编码不一致,VS 报错C4819,改为unicode,SI乱码先在VS改为简体中文2312,Linux gedit乱码可以在norepad改为utf-8编码,或者VS改为简体中文。
2-动态内存分配报错:0xC0000374: 堆已损坏。问题一般出在当前报错的molloc函数上一次调用molloc函数,原因是内存溢出,好好检查内存分配与实际数据结构是否匹配?索引是否超出边界?molloc分配内存后需进行强制类型转换,并写判断是否成功,若失败则需置NULL或者再次分配;free与malloc成对使用,对于函数内部进行动态内存分配,并返回函数指针的,尤其要注意,该指针变量使用完后进行释放,且释放完必须置NULL!!!对于二维数组指针或者内部成员有指针嵌套的结构体,需进行多次释放,要注意释放顺序,最好写一个函数进行二次封装。例如:对于成员包含数组指针的结构体指针,先释放结构体内部的数组指针,再释放结构体指针;对于二维数组双重指针,需视动态内存分配方式而定,对于整体分配(保证内存连续),然后依次进行二次分配(指定偏移值为列数),先释放行指针,再释放双重指针!!!(具体参见MatrixOperation.c,后续给出)。
3-C语言和matlab语法规则区别:对于纯C,所有变量必须严格先进行声明然后再调用?也就是所有变量必须在文件头部同一声明,不能后续要用再临时声明(不过本人并没有遵守,但gcc通过,为啥?)此外,自定义函数不要太长,最多100行,便于后续调试维护;变量初始化赋值只能指定常量而不能是变量,后续通过语句一个个赋值,这是推荐使用memcopy进行内存拷贝,不要想当然用m语言的规则操作。
4-C语言专题:二维数组/嵌套结构体(指针成员)动态内存分配与释放、结构体作为全局变量与跨函数调用、双重指针作为函数参数/函数返回结构体指针以及二维数组指针(指针函数)、结构体内部函数指针(面向对象)+静态函数。