C++实现YoloV7目标识别与实例分割推理
前言
1.简介
7月份,由YOLOV4的原班人马Chien-Yao Wang、Alexey Bochkovskiy 和 Hong-Yuan Mark Liao推出的YoloV7,应该是目前开源的目标检测算法最好之一了,它在在5 FPS到160 FPS范围内的速度和精度达到了新的高度,优于 YOLOR、YOLOX、Scaled-YOLOv4、YOLOv5、DETR 等多种目标检测器。在GPU V100上具有30 FPS或更高的所有已知实时目标检测器中具有最高的精度56.8%AP。相对于其他类型的算法,YOLOv7-E6目标检测器(56 FPS V100,55.9% AP)比基于Transform的检测器SWINL Cascade-Mask R-CNN(9.2 FPS A100,53.9% AP)的速度和准确度分别高出509%和2%,以及基于卷积的检测器ConvNeXt-XL Cascade-Mask R-CNN (8.6 FPS A100, 55.2% AP) 速度提高551%,准确率提高0.7%。
而YOLOv7 除目标检测外,YOLOv7 作者还放出了实例分割的模型。实例分割的代码存放在分支 mask 里,目前还是在不断完善中,感兴趣的可以直接上git看看源码。
2.开发环境
开发环境是win10,显卡RTX3080,cuda10.2,cudnn7.1,OpenCV4.5,NCNN,IDE 是Vs2019。
一、Python推理
git clone https://github.com/WongKinYiu/yolov7.git -b mask yolov7-mask
cd yolov7-mask
# 创建新的虚拟环境
conda create -n pytorch1.8 python=3.8
conda activate pytorch1.8
# 安装 torch 1.8.2
pip install torch==1.8.2 torchvision==0.9.2 torchaudio===0.8.2 --extra-index-url https://download.pytorch.org/whl/lts/1.8/cu111
# 修改requirements.txt,将其中的torch和torchvision注释掉
pip install -r requirements.txt
# 安装detectron2
git clone https://github.com/facebookresearch/detectron2
cd detectron2
python setup.py install
cd ..
import matplotlib.pyplot as plt
import torch
import cv2
import yaml
from torchvision import transforms
import numpy as np
from utils.datasets import letterbox
from utils.general import non_max_suppression_mask_conf
from detectron2.modeling.poolers import ROIPooler
from detectron2.structures import Boxes
from detectron2.utils.memory import retry_if_cuda_oom
from detectron2.layers import paste_masks_in_image
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
with open('data/hyp.scratch.mask.yaml') as f:
hyp = yaml.load(f, Loader=yaml.FullLoader)
weigths = torch.load('yolov7-mask.pt')
model = weigths['model']
model = model.half().to(device)
_ = model.eval()
image = cv2.imread('inference/images/horses.jpg') # 504x378 image
image = letterbox(image, 640, stride=64, auto=True)[0]
image_ = image.copy()
image = transforms.ToTensor()(image)
image = torch.tensor(np.array([image.numpy()]))
image = image.to(device)
image = image.half()
output = model(image)
inf_out, train_out, attn, mask_iou, bases, sem_output = output['test'], output['bbox_and_cls'], output['attn'], output['mask_iou'], output['bases'], output['sem']
bases = torch.cat([bases, sem_output], dim=1)
nb, _, height, width = image.shape
names = model.names
pooler_scale = model.pooler_scale
pooler = ROIPooler(output_size=hyp['mask_resolution'], scales=(pooler_scale,), sampling_ratio=1, pooler_type='ROIAlignV2', canonical_level=2)
output, output_mask, output_mask_score, output_ac, output_ab = non_max_suppression_mask_conf(inf_out, attn, bases, pooler, hyp, conf_thres=0.25, iou_thres=0.65, merge=False, mask_iou=None)
pred, pred_masks = output[0], output_mask[0]
base = bases[0]
bboxes = Boxes(pred[:, :4])
original_pred_masks = pred_masks.view(-1, hyp['mask_resolution'], hyp['mask_resolution'])
pred_masks = retry_if_cuda_oom(paste_masks_in_image)( original_pred_masks, bboxes, (height, width), threshold=0.5)
pred_masks_np = pred_masks.detach().cpu().numpy()
pred_cls = pred[:, 5].detach().cpu().numpy()
pred_conf = pred[:, 4].detach().cpu().numpy()
nimg = image[0].permute(1, 2, 0) * 255
nimg = nimg.cpu().numpy().astype(np.uint8)
nimg = cv2.cvtColor(nimg, cv2.COLOR_RGB2BGR)
nbboxes = bboxes.tensor.detach().cpu().numpy().astype(np.int)
pnimg = nimg.copy()
for one_mask, bbox, cls, conf in zip(pred_masks_np, nbboxes, pred_cls, pred_conf):
if conf < 0.25:
continue
color = [np.random.randint(255), np.random.randint(255), np.random.randint(255)]
pnimg[one_mask] = pnimg[one_mask] * 0.5 + np.array(color, dtype=np.uint8) * 0.5
pnimg = cv2.rectangle(pnimg, (bbox[0], bbox[1]), (bbox[2], bbox[3]), color, 2)
#label = '%s %.3f' % (names[int(cls)], conf)
#t_size = cv2.getTextSize(label, 0, fontScale=0.5, thickness=1)[0]
#c2 = bbox[0] + t_size[0], bbox[1] - t_size[1] - 3
#pnimg = cv2.rectangle(pnimg, (bbox[0], bbox[1]), c2, color, -1, cv2.LINE_AA) # filled
#pnimg = cv2.putText(pnimg, label, (bbox[0], bbox[1] - 2), 0, 0.5, [255, 255, 255], thickness=1, lineType=cv2.LINE_AA)
cv2.imwrite("instance_result.jpg", pnimg)
二、C++推理
1. C++推理要依赖OpenCV和NCNN库。
#pragma once
#include #include "YoloDetect.h"
#define MAX_STRIDE 32
#define MASK_RESOLUTION 56
#define ATTN_RESOLUTION 14
#define NUM_BASE 5
template <typename T>
struct PreCalc {
int pos1;
int pos2;
int pos3;
int pos4;
T w1;
T w2;
T w3;
T w4;
};
template <typename T>
void pre_calc_for_bilinear_interpolate(
const int height, const int width,
const int pooled_height, const int pooled_width,
T roi_start_h, T roi_start_w,
T bin_size_h, T bin_size_w,
int roi_bin_grid_h, int roi_bin_grid_w,
std::vector<PreCalc<T>>& pre_calc)
{
int pre_calc_index = 0;
for (int ph = 0; ph < pooled_height; ph++)
{
for (int pw = 0; pw < pooled_width; pw++)
{
for (int iy = 0; iy < roi_bin_grid_h; iy++)
{
const T yy = roi_start_h + ph * bin_size_h +
static_cast<T>(iy + .5f) * bin_size_h /
static_cast<T>(roi_bin_grid_h); // e.g., 0.5, 1.5
for (int ix = 0; ix < roi_bin_grid_w; ix++)
{
const T xx = roi_start_w + pw * bin_size_w +
static_cast<T>(ix + .5f) * bin_size_w /
static_cast<T>(roi_bin_grid_w);
T x = xx;
T y = yy;
// deal with: inverse elements are out of feature map boundary
if (y < -1.0 || y > height || x < -1.0 || x > width) {
// empty
PreCalc<T> pc;
pc.pos1 = 0;
pc.pos2 = 0;
pc.pos3 = 0;
pc.pos4 = 0;
pc.w1 = 0;
pc.w2 = 0;
pc.w3 = 0;
pc.w4 = 0;
pre_calc[pre_calc_index] = pc;
pre_calc_index += 1;
continue;
}
if (y <= 0)
{
y = 0;
}
if (x <= 0)
{
x = 0;
}
int y_low = (int)y;
int x_low = (int)x;
int y_high;
int x_high;
if (y_low >= height - 1) {
y_high = y_low = height - 1;
y = (T)y_low;
}
else {
y_high = y_low + 1;
}
if (x_low >= width - 1) {
x_high = x_low = width - 1;
x = (T)x_low;
}
else {
x_high = x_low + 1;
}
T ly = y - y_low;
T lx = x - x_low;
T hy = 1. - ly, hx = 1. - lx;
T w1 = hy * hx, w2 = hy * lx, w3 = ly * hx, w4 = ly * lx;
// save weights and indeces
PreCalc<T> pc;
pc.pos1 = y_low * width + x_low;
pc.pos2 = y_low * width + x_high;
pc.pos3 = y_high * width + x_low;
pc.pos4 = y_high * width + x_high;
pc.w1 = w1;
pc.w2 = w2;
pc.w3 = w3;
pc.w4 = w4;
pre_calc[pre_calc_index] = pc;
pre_calc_index += 1;
}
}
}
}
}
static void roi_align_forrawd_kernrl_impl(
const int n_rois, const float* bottom_data, const float& spatial_scale,
const int channels, const int height, const int width, const int pooled_height,
const int pooled_width, const int sampling_ratio, const float* bottom_rois,
float* top_data)
{
for (int n = 0; n < n_rois; n++) {
int index_n = n * channels * pooled_width * pooled_height;
const float* offset_bottom_rois = bottom_rois + n * 5;
int roi_batch_ind = offset_bottom_rois[0];
float offset = 0.5f;
// Do not using rounding; this implementation detail is critical
float roi_start_w = offset_bottom_rois[1] * spatial_scale - offset;
float roi_start_h = offset_bottom_rois[2] * spatial_scale - offset;
float roi_end_w = offset_bottom_rois[3] * spatial_scale - offset;
float roi_end_h = offset_bottom_rois[4] * spatial_scale - offset;
// Force malformed ROIs to be 1x1
float roi_width = roi_end_w - roi_start_w;
float roi_height = roi_end_h - roi_start_h;
float bin_size_h = static_cast<float>(roi_height) / static_cast<float>(pooled_height);
float bin_size_w = static_cast<float>(roi_width) / static_cast<float>(pooled_width);
// We use roi_bin_grid to sample the grid and mimic integral
int roi_bin_grid_h = (sampling_ratio > 0) ? sampling_ratio : ceil(roi_height / pooled_height); // e.g., = 2
int roi_bin_grid_w = (sampling_ratio > 0) ? sampling_ratio : ceil(roi_width / pooled_width);
// We do average (integral) pooling inside a bin
const float count = std::max(roi_bin_grid_h * roi_bin_grid_w, 1); // e.g. = 4
// we want to precalculate indeces and weights shared by all chanels,
// this is the key point of optimiation
std::vector<PreCalc<float>> pre_calc(roi_bin_grid_h * roi_bin_grid_w * pooled_width * pooled_height);
pre_calc_for_bilinear_interpolate(
height,
width,
pooled_height,
pooled_width,
roi_start_h,
roi_start_w,
bin_size_h,
bin_size_w,
roi_bin_grid_h,
roi_bin_grid_w,
pre_calc);
for (int c = 0; c < channels; c++) {
int index_n_c = index_n + c * pooled_width * pooled_height;
const float* offset_bottom_data = bottom_data + (roi_batch_ind * channels + c) * height * width;
int pre_calc_index = 0;
for (int ph = 0; ph < pooled_height; ph++) {
for (int pw = 0; pw < pooled_width; pw++) {
int index = index_n_c + ph * pooled_width + pw;
float output_val = 0.;
for (int iy = 0; iy < roi_bin_grid_h; iy++) {
for (int ix = 0; ix < roi_bin_grid_w; ix++) {
PreCalc<float> pc = pre_calc[pre_calc_index];
output_val += pc.w1 * offset_bottom_data[pc.pos1] +
pc.w2 * offset_bottom_data[pc.pos2] +
pc.w3 * offset_bottom_data[pc.pos3] +
pc.w4 * offset_bottom_data[pc.pos4];
pre_calc_index += 1;
}
}
output_val /= count;
top_data[index] = output_val;
} // for pw
} // for ph
} // for c
} // for n
}
static void roi_align_forward_kernel(const ncnn::Mat& input, const ncnn::Mat& rois, float spatial_scale, int pooled_height, int pooled_width, int sampling_ratio, float* output)
{
int num_rois = rois.h;
int channels = input.c;
int height = input.h;
int width = input.w;
roi_align_forrawd_kernrl_impl(
num_rois,
(float*)input.data,
spatial_scale,
channels,
height,
width,
pooled_height,
pooled_width,
sampling_ratio,
(float*)rois.data,
output);
}
static int pooler(const ncnn::Mat& x, const ncnn::Mat& box_lists, int sample_ratio, float scale, ncnn::Mat& pooled_bases)
{
pooled_bases = ncnn::Mat(MASK_RESOLUTION, MASK_RESOLUTION, NUM_BASE, box_lists.h);
roi_align_forward_kernel(x, box_lists, scale, MASK_RESOLUTION, MASK_RESOLUTION, sample_ratio, pooled_bases.channel(0));
return 0;
}
static inline float intersection_area(const Object& a, const Object& b)
{
cv::Rect_<float> inter = a.rect & b.rect;
return inter.area();
}
static void qsort_descent_inplace(std::vector<Object>& objects, int left, int right)
{
int i = left;
int j = right;
float p = objects[(left + right) / 2].prob;
while (i <= j)
{
while (objects[i].prob > p)
i++;
while (objects[j].prob < p)
j--;
if (i <= j)
{
// swap
std::swap(objects[i], objects[j]);
i++;
j--;
}
}
#pragma omp parallel sections
{
#pragma omp section
{
if (left < j) qsort_descent_inplace(objects, left, j);
}
#pragma omp section
{
if (i < right) qsort_descent_inplace(objects, i, right);
}
}
}
static void qsort_descent_inplace(std::vector<Object>& objects)
{
if (objects.empty())
return;
qsort_descent_inplace(objects, 0, objects.size() - 1);
}
static void nms_sorted_bboxes(const std::vector<Object>& faceobjects, std::vector<int>& picked, float nms_threshold, bool agnostic = false)
{
picked.clear();
const int n = faceobjects.size();
std::vector<float> areas(n);
for (int i = 0; i < n; i++)
{
areas[i] = faceobjects[i].rect.area();
}
for (int i = 0; i < n; i++)
{
const Object& a = faceobjects[i];
int keep = 1;
for (int j = 0; j < (int)picked.size(); j++)
{
const Object& b = faceobjects[picked[j]];
if (!agnostic && a.label != b.label)
continue;
// intersection over union
float inter_area = intersection_area(a, b);
float union_area = areas[i] + areas[picked[j]] - inter_area;
// float IoU = inter_area / union_area
if (inter_area / union_area > nms_threshold)
keep = 0;
}
if (keep)
picked.push_back(i);
}
}
static inline float sigmoid(float x)
{
return static_cast<float>(1.f / (1.f + exp(-x)));
}
static void generate_proposals(const ncnn::Mat& anchors, int stride,
const ncnn::Mat& in_pad,
const ncnn::Mat& feat_blob,
const ncnn::Mat& attn_blob,
float prob_threshold, std::vector<Object>& objects)
{
const int num_grid = feat_blob.h;
int num_grid_x;
int num_grid_y;
if (in_pad.w > in_pad.h)
{
num_grid_x = in_pad.w / stride;
num_grid_y = num_grid / num_grid_x;
}
else
{
num_grid_y = in_pad.h / stride;
num_grid_x = num_grid / num_grid_y;
}
const int num_class = feat_blob.w - 5;
const int num_anchors = anchors.w / 2;
for (int q = 0; q < num_anchors; q++)
{
const float anchor_w = anchors[q * 2];
const float anchor_h = anchors[q * 2 + 1];
const ncnn::Mat feat = feat_blob.channel(q);
const ncnn::Mat attn = attn_blob.channel(q);
for (int i = 0; i < num_grid_y; i++)
{
for (int j = 0; j < num_grid_x; j++)
{
const float* featptr = feat.row(i * num_grid_x + j);
const float* attnptr = attn.row(i * num_grid_x + j);
float box_confidence = sigmoid(featptr[4]);
if (box_confidence >= prob_threshold)
{
// find class index with max class score
int class_index = 0;
float class_score = -FLT_MAX;
for (int k = 0; k < num_class; k++)
{
float score = featptr[5 + k];
if (score > class_score)
{
class_index = k;
class_score = score;
}
}
float confidence = box_confidence * sigmoid(class_score);
if (confidence >= prob_threshold)
{
float dx = sigmoid(featptr[0]);
float dy = sigmoid(featptr[1]);
float dw = sigmoid(featptr[2]);
float dh = sigmoid(featptr[3]);
float pb_cx = (dx * 2.f - 0.5f + j) * stride;
float pb_cy = (dy * 2.f - 0.5f + i) * stride;
float pb_w = pow(dw * 2.f, 2) * anchor_w;
float pb_h = pow(dh * 2.f, 2) * anchor_h;
float x0 = pb_cx - pb_w * 0.5f;
float y0 = pb_cy - pb_h * 0.5f;
float x1 = pb_cx + pb_w * 0.5f;
float y1 = pb_cy + pb_h * 0.5f;
Object obj;
obj.rect.x = x0;
obj.rect.y = y0;
obj.rect.width = x1 - x0;
obj.rect.height = y1 - y0;
obj.label = class_index;
obj.prob = confidence;
obj.mask.create(980, 1, 1);
std::memcpy((float*)obj.mask.data, attnptr, sizeof(float) * 980);
objects.push_back(obj);
}
}
}
}
}
}
static void upsample(const ncnn::Mat& in, const float& scale, ncnn::Mat& out)
{
ncnn::Option opt;
opt.num_threads = 4;
opt.use_fp16_storage = false;
opt.use_packing_layout = false;
ncnn::Layer* op = ncnn::create_layer("Interp");
// set param
ncnn::ParamDict pd;
pd.set(0, 2);// resize_type
pd.set(1, scale);// height_scale
pd.set(2, scale);// width_scale
op->load_param(pd);
op->create_pipeline(opt);
// forward
op->forward(in, out, opt);
op->destroy_pipeline(opt);
delete op;
}
static void softmax(ncnn::Mat& bottom, int axis)
{
ncnn::Option opt;
opt.num_threads = 4;
opt.use_fp16_storage = false;
opt.use_packing_layout = false;
ncnn::Layer* op = ncnn::create_layer("Softmax");
// set param
ncnn::ParamDict pd;
pd.set(0, axis);// axis
pd.set(1, 1);
op->load_param(pd);
op->create_pipeline(opt);
// forward
op->forward_inplace(bottom, opt);
op->destroy_pipeline(opt);
delete op;
}
static void reduction(ncnn::Mat& bottom, ncnn::Mat& top)
{
ncnn::Option opt;
opt.num_threads = 4;
opt.use_fp16_storage = false;
opt.use_packing_layout = false;
ncnn::Layer* op = ncnn::create_layer("Reduction");
// set param
ncnn::ParamDict pd;
pd.set(0, 0);// sum
pd.set(1, 0);// reduce_all
pd.set(4, 0);//keepdims
pd.set(5, 1);
ncnn::Mat axes = ncnn::Mat(1);
axes.fill(1);
pd.set(3, axes);
op->load_param(pd);
op->create_pipeline(opt);
// forward
op->forward(bottom, top, opt);
op->destroy_pipeline(opt);
delete op;
}
static void sigmoid(ncnn::Mat& bottom)
{
ncnn::Option opt;
opt.num_threads = 4;
opt.use_fp16_storage = false;
opt.use_packing_layout = false;
ncnn::Layer* op = ncnn::create_layer("Sigmoid");
op->create_pipeline(opt);
// forward
op->forward_inplace(bottom, opt);
op->destroy_pipeline(opt);
delete op;
}
static int decode_mask(const std::vector<Object>& proposals, std::vector<int> picked,
const ncnn::Mat& bases, int sample_ratio, float scale, ncnn::Mat& pred_masks)
{
std::vector<Object> proposals_nms;
int picked_num = picked.size();
for (int i = 0; i < picked_num; i++) {
proposals_nms.push_back(proposals[picked[i]]);
}
int proposals_num = proposals_nms.size();
ncnn::Mat boxes = ncnn::Mat(NUM_BASE, proposals_num);
ncnn::Mat coeffs = ncnn::Mat(MASK_RESOLUTION, MASK_RESOLUTION, NUM_BASE, proposals_num);
for (int i = 0; i < proposals_num; i++) {
float* coeffs_ptr = coeffs.channel(i);
float* boxes_ptr = boxes.row(i);
boxes_ptr[0] = 0.f;
boxes_ptr[1] = proposals_nms[i].rect.x;
boxes_ptr[2] = proposals_nms[i].rect.y;
boxes_ptr[3] = proposals_nms[i].rect.x + proposals_nms[i].rect.width;
boxes_ptr[4] = proposals_nms[i].rect.y + proposals_nms[i].rect.height;
ncnn::Mat mask = proposals_nms[i].mask.reshape(ATTN_RESOLUTION, ATTN_RESOLUTION, NUM_BASE);
upsample(mask, 4.0, proposals_nms[i].mask);
softmax(proposals_nms[i].mask, 0);
int size = proposals_nms[i].mask.h * proposals_nms[i].mask.w * proposals_nms[i].mask.c;
std::memcpy(coeffs_ptr, (float*)proposals_nms[i].mask.data, sizeof(float) * size);
}
ncnn::Mat rois;
pooler(bases, boxes, sample_ratio, scale, rois);
ncnn::Mat merge_bases = ncnn::Mat(MASK_RESOLUTION, MASK_RESOLUTION, NUM_BASE, rois.c);
int size = rois.c * rois.d * rois.h * rois.w;
for (int i = 0; i < size; i++) {
merge_bases[i] = rois[i] * coeffs[i];
}
reduction(merge_bases, pred_masks);
sigmoid(pred_masks);
return 0;
}
static void paste_mask_in_image(const float* pred_mask, int img_w, int img_h, Object& obj)
{
cv::Mat mask(MASK_RESOLUTION, MASK_RESOLUTION, CV_32FC1, (float*)pred_mask);
cv::Mat mask_org;
cv::resize(mask, mask_org, cv::Size(obj.rect.width, obj.rect.height));
obj.cv_mask = cv::Mat::zeros(img_h, img_w, CV_8UC1);
int roi_x = obj.rect.x;
int roi_y = obj.rect.y;
for (int y = 0; y < mask_org.rows; y++) {
const float* mask_org_ptr = mask_org.ptr<const float>(y);
uchar* cv_mask_ptr = obj.cv_mask.ptr<uchar>(y + roi_y);
for (int x = 0; x < mask_org.cols; x++) {
if (mask_org_ptr[x] > 0.5f)
cv_mask_ptr[x + roi_x] = 255;
else
cv_mask_ptr[x + roi_x] = 0;
}
}
}
YoloDetect::YoloDetect()
{
}
int YoloDetect::init_model(const std::string& models_path,bool use_gpu)
{
bool has_gpu = false;
#if NCNN_VULKAN
ncnn::create_gpu_instance();
has_gpu = ncnn::get_gpu_count() > 0;
#endif
bool to_use_gpu = has_gpu && use_gpu;
net.opt.use_vulkan_compute = to_use_gpu;
net.opt.use_fp16_arithmetic = false;
int rp = net.load_param((models_path + ".param").c_str());
int rm = net.load_model((models_path + ".bin").c_str());
if (rp < 0 || rm < 0)
{
return -70;
}
if (to_use_gpu)
{
return 1;
}
return 0;
}
void YoloDetect::detect_image(const cv::Mat& cv_src, std::vector<Object>& objects)
{
int img_w = cv_src.cols;
int img_h = cv_src.rows;
// letterbox pad to multiple of MAX_STRIDE
int w = img_w;
int h = img_h;
float scale = 1.f;
if (w > h) {
scale = (float)target_size / w;
w = target_size;
h = h * scale;
}
else {
scale = (float)target_size / h;
h = target_size;
w = w * scale;
}
ncnn::Mat in = ncnn::Mat::from_pixels_resize(cv_src.data, ncnn::Mat::PIXEL_BGR, img_w, img_h, w, h);
int wpad = (w + MAX_STRIDE - 1) / MAX_STRIDE * MAX_STRIDE - w;
int hpad = (h + MAX_STRIDE - 1) / MAX_STRIDE * MAX_STRIDE - h;
ncnn::Mat in_pad;
ncnn::copy_make_border(in, in_pad, hpad / 2, hpad - hpad / 2, wpad / 2, wpad - wpad / 2, ncnn::BORDER_CONSTANT, 114.f);
const float norm_vals[3] = { 1 / 255.f, 1 / 255.f, 1 / 255.f };
in_pad.substract_mean_normalize(0, norm_vals);
ncnn::Extractor ex = net.create_extractor();
ex.input("images", in_pad);
std::vector<Object> proposals;
// stride 8
{
ncnn::Mat out;
ex.extract("759", out);
ncnn::Mat attn;
ex.extract("attn1", attn);
ncnn::Mat anchors(6);
anchors[0] = 12.f;
anchors[1] = 16.f;
anchors[2] = 19.f;
anchors[3] = 36.f;
anchors[4] = 40.f;
anchors[5] = 28.f;
std::vector<Object> objects8;
generate_proposals(anchors, 8, in_pad, out, attn, prob_threshold, objects8);
proposals.insert(proposals.end(), objects8.begin(), objects8.end());
}
// stride 16
{
ncnn::Mat out;
ex.extract("799", out);
ncnn::Mat attn;
ex.extract("attn2", attn);
ncnn::Mat anchors(6);
anchors[0] = 36.f;
anchors[1] = 75.f;
anchors[2] = 76.f;
anchors[3] = 55.f;
anchors[4] = 72.f;
anchors[5] = 146.f;
std::vector<Object> objects16;
generate_proposals(anchors, 16, in_pad, out, attn, prob_threshold, objects16);
proposals.insert(proposals.end(), objects16.begin(), objects16.end());
}
// stride 32
{
ncnn::Mat out;
ex.extract("839", out);
ncnn::Mat attn;
ex.extract("attn3", attn);
ncnn::Mat anchors(6);
anchors[0] = 142.f;
anchors[1] = 110.f;
anchors[2] = 192.f;
anchors[3] = 243.f;
anchors[4] = 459.f;
anchors[5] = 401.f;
std::vector<Object> objects32;
generate_proposals(anchors, 32, in_pad, out, attn, prob_threshold, objects32);
proposals.insert(proposals.end(), objects32.begin(), objects32.end());
}
ncnn::Mat bases;
ex.extract("bases", bases);
// sort all proposals by score from highest to lowest
qsort_descent_inplace(proposals);
// apply nms with nms_threshold
std::vector<int> picked;
nms_sorted_bboxes(proposals, picked, nms_threshold);
//decode masks
ncnn::Mat pred_masks;
decode_mask(proposals, picked, bases, sample_ratio, down_scale, pred_masks);
int count = picked.size();
objects.resize(count);
for (int i = 0; i < count; i++) {
objects[i] = proposals[picked[i]];
// adjust offset to original unpadded
float x0 = (objects[i].rect.x - (wpad / 2)) / scale;
float y0 = (objects[i].rect.y - (hpad / 2)) / scale;
float x1 = (objects[i].rect.x + objects[i].rect.width - (wpad / 2)) / scale;
float y1 = (objects[i].rect.y + objects[i].rect.height - (hpad / 2)) / scale;
// clip
x0 = std::max(std::min(x0, (float)(img_w - 1)), 0.f);
y0 = std::max(std::min(y0, (float)(img_h - 1)), 0.f);
x1 = std::max(std::min(x1, (float)(img_w - 1)), 0.f);
y1 = std::max(std::min(y1, (float)(img_h - 1)), 0.f);
objects[i].rect.x = x0;
objects[i].rect.y = y0;
objects[i].rect.width = x1 - x0;
objects[i].rect.height = y1 - y0;
paste_mask_in_image(pred_masks.channel(i), img_w, img_h, objects[i]);
}
}
void YoloDetect::draw_objects(const cv::Mat& cv_src, cv::Mat& cv_dst, std::vector<Object>& objects, std::vector<std::string>& class_names)
{
static const unsigned char colors[81][3] = {
{56, 0, 255},
{226, 255, 0},
{0, 94, 255},
{0, 37, 255},
{0, 255, 94},
{255, 226, 0},
{0, 18, 255},
{255, 151, 0},
{170, 0, 255},
{0, 255, 56},
{255, 0, 75},
{0, 75, 255},
{0, 255, 169},
{255, 0, 207},
{75, 255, 0},
{207, 0, 255},
{37, 0, 255},
{0, 207, 255},
{94, 0, 255},
{0, 255, 113},
{255, 18, 0},
{255, 0, 56},
{18, 0, 255},
{0, 255, 226},
{170, 255, 0},
{255, 0, 245},
{151, 255, 0},
{132, 255, 0},
{75, 0, 255},
{151, 0, 255},
{0, 151, 255},
{132, 0, 255},
{0, 255, 245},
{255, 132, 0},
{226, 0, 255},
{255, 37, 0},
{207, 255, 0},
{0, 255, 207},
{94, 255, 0},
{0, 226, 255},
{56, 255, 0},
{255, 94, 0},
{255, 113, 0},
{0, 132, 255},
{255, 0, 132},
{255, 170, 0},
{255, 0, 188},
{113, 255, 0},
{245, 0, 255},
{113, 0, 255},
{255, 188, 0},
{0, 113, 255},
{255, 0, 0},
{0, 56, 255},
{255, 0, 113},
{0, 255, 188},
{255, 0, 94},
{255, 0, 18},
{18, 255, 0},
{0, 255, 132},
{0, 188, 255},
{0, 245, 255},
{0, 169, 255},
{37, 255, 0},
{255, 0, 151},
{188, 0, 255},
{0, 255, 37},
{0, 255, 0},
{255, 0, 170},
{255, 0, 37},
{255, 75, 0},
{0, 0, 255},
{255, 207, 0},
{255, 0, 226},
{255, 245, 0},
{188, 255, 0},
{0, 255, 18},
{0, 255, 75},
{0, 255, 151},
{255, 56, 0},
{245, 255, 0}
};
int color_index = 0;
cv_dst = cv_src.clone();
for (size_t i = 0; i < objects.size(); i++) {
const Object& obj = objects[i];
const unsigned char* color = colors[color_index % 80];
color_index++;
cv::Scalar cc(color[0], color[1], color[2]);
fprintf(stderr, "%d = %.5f at %.2f %.2f %.2f x %.2f\n", obj.label, obj.prob,
obj.rect.x, obj.rect.y, obj.rect.width, obj.rect.height);
for (int y = 0; y < cv_dst.rows; y++)
{
uchar* image_ptr = cv_dst.ptr(y);
const uchar* mask_ptr = obj.cv_mask.ptr<uchar>(y);
for (int x = 0; x < cv_dst.cols; x++) {
if (mask_ptr[x] > 0) {
image_ptr[0] = cv::saturate_cast<uchar>(image_ptr[0] * 0.5 + color[2] * 0.5);
image_ptr[1] = cv::saturate_cast<uchar>(image_ptr[1] * 0.5 + color[1] * 0.5);
image_ptr[2] = cv::saturate_cast<uchar>(image_ptr[2] * 0.5 + color[0] * 0.5);
}
image_ptr += 3;
}
}
cv::rectangle(cv_dst, obj.rect, cc, 2);
char text[256];
sprintf(text, "%s %.1f%%", class_names[obj.label], obj.prob * 100);
int baseLine = 0;
cv::Size label_size = cv::getTextSize(text, cv::FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
int x = obj.rect.x;
int y = obj.rect.y - label_size.height - baseLine;
if (y < 0)
y = 0;
if (x + label_size.width > cv_dst.cols)
x = cv_dst.cols - label_size.width;
cv::rectangle(cv_dst, cv::Rect(cv::Point(x, y), cv::Size(label_size.width, label_size.height + baseLine)),
cc, -1);
cv::putText(cv_dst, text, cv::Point(x, y + label_size.height),
cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(255, 255, 255));
}
}
#include "YoloDetect.h"
#include三、检测结果
四、源码
1.C++ 源码与依赖的环境以上传:https://download.csdn.net/download/matt45m/86786974
2. 源码配置
1.文件目录

2.配置include和lib路径
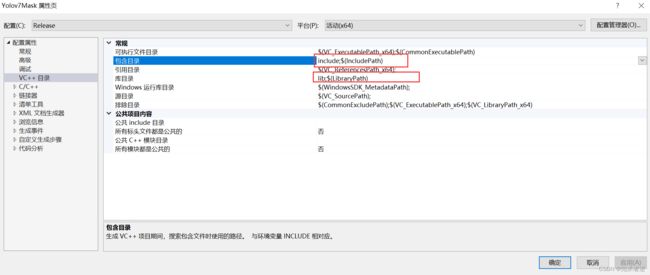
3.添加lib名,就是源码目录里面所有点lib后缀的名称。

4.IDE的配置