Pytorch基础知识
Pytorch基础知识
-
Pytorch中文文档: https://pytorch-cn.readthedocs.io/zh/latest/
-
Pytorch英文文档: https://pytorch.org/docs/stable/torch.html
-
环境:
package 版本 torch 1.11.0 torchvision 0.12.0 tensorboard 2.6.0
文章目录
-
- Pytorch基础知识
-
- 一、 dir() 和 help()
- 二、 加载数据
-
- 2.1 torch.utils.data.Dataset
- 2.2 torchvision.transforms
- 2.3 torch.utils.data.DataLoader
- 2.4 使用torchvision.datasets下面的数据集
- 三、 Tensorboard
- 四、搭建网络
-
- 4.1 常用API及说明
- 4.2 正经写一个网络
- 4.3 Tensorboard可视化网络结构
- 4.4 官方封装好的的网络模型
- 五、训练
-
- 5.1 损失函数
- 5.2 优化器
- 5.3 模型的保存和加载
- 5.4 完整的训练代码(CPU)
- 5.5 在GPU上训练
一、 dir() 和 help()
import torch
# 1.dir查看该工具箱下有哪些方法,是针对工具箱的
dir(torch.cuda)
# 2.help 查看函数功能,是针对函数的
help(torch)
(前后的双下划线代表该变量/函数不允许被修改。)

二、 加载数据
-
pytorch中读取数据主要涉及到两个类: Dataset 和 DataLoader
-
数据集地址(蚂蚁蜜蜂二分类):
链接:https://pan.baidu.com/s/1ggnMhzq6wcc3XYjUYY96zg 提取码:2022 --来自百度网盘超级会员V1的分享
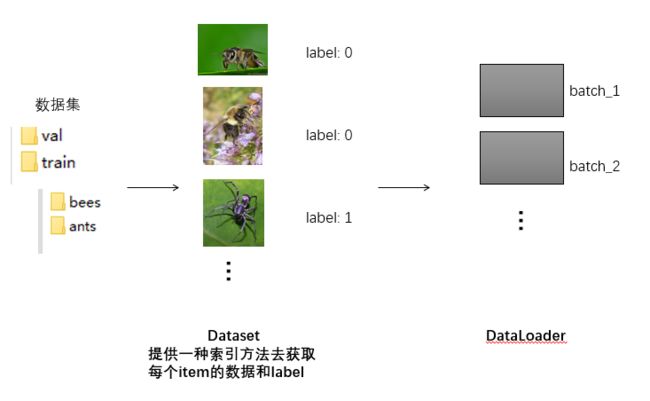
2.1 torch.utils.data.Dataset
from torch.utils.data import Dataset
help(Dataset)
#1. 所有的数据集都要继承Dataset类
#2. Dataset类中的__getitem__()和__len__()方法需要被重写
#3. 两个数据集类是可以直接加在一起的
from torch.utils.data import Dataset
import os
import cv2
class Mydata(Dataset):
def __init__(self, root_dir, label_dir):
'''
root_dir = 'dataset/train'
label_dir = 'ants'
'''
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
img = cv2.imread(img_item_path) #是np格式的
label = self.label_dir
return img,label
def __len__(self):
return len(self.img_path)
root_dir = '../input/hymenoptera-data/hymenoptera_data/train'
ants_label_dir = 'ants'
ants_dataset = Mydata(root_dir, ants_label_dir)
bees_label_dir = 'bees'
bees_dataset = Mydata(root_dir, bees_label_dir)
# 数据集可以直接相加!
train_dataset = ants_dataset + bees_dataset
2.2 torchvision.transforms
-
transforms.ToTensor() 是最常用的
from torchvision import transforms import cv2 img = cv2.imread('../input/hymenoptera-data/hymenoptera_data/train/ants/VietnameseAntMimicSpider.jpg') tensor_trans = transforms.ToTensor() img_tensor = tensor_trans(img) #img_tensor.shape: torch.Size([3, 705, 646]) -
call方法的作用
class Person: def __call__(self, name): print("__call__ " + "Hello " + name + '!') def hello(self, name): print("hello" + name) person = Person() person('zhang san') person.hello('zhang san') -
transforms.Normalize(mean, std)
norm_trans = transform.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5]) # (均值,标准差) img_norm = norm_trans(img) -
transforms.Resize((H_new,W_new))
resize_trans = transforms.Resize((512,512)) img_resize = resize_trans(img_norm) -
transforms.Compose()
compose_trans = transforms.Compose([ transforms.ToTensor(), transform.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5]), transforms.Resize((512,512)) ]) img_compose = compose_trans(cv2.imread(img_path))
2.3 torch.utils.data.DataLoader
- 在windows下 num_workers=0 是必须的,否则会报错
- drop_last参数是判断余数部分的数据是否舍弃
from torch.utils.data import Dataset
import os
import cv2
import torch
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
class Mydata(Dataset):
def __init__(self, root_dir, label_dir):
'''
root_dir = 'dataset/train'
label_dir = 'ants'
'''
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
dic = {'ants':0, 'bees':1}
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
img = cv2.imread(img_item_path) #是np格式的
compose_trans = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5]),
transforms.Resize((224,224))
])
img = compose_trans(img)
label = dic[self.label_dir]
return img,label
def __len__(self):
return len(self.img_path)
root_dir = '../input/hymenoptera-data/hymenoptera_data/train'
ants_label_dir = 'ants'
ants_dataset = Mydata(root_dir, ants_label_dir)
bees_label_dir = 'bees'
bees_dataset = Mydata(root_dir, bees_label_dir)
train_dataset = ants_dataset + bees_dataset
train_DataLoader = DataLoader(dataset=train_dataset, batch_size=8, num_workers=0, shuffle=True)
root_dir = '../input/hymenoptera-data/hymenoptera_data/val'
ants_label_dir = 'ants'
ants_dataset = Mydata(root_dir, ants_label_dir)
bees_label_dir = 'bees'
bees_dataset = Mydata(root_dir, bees_label_dir)
test_dataset = ants_dataset + bees_dataset
test_DataLoader = DataLoader(dataset=train_dataset, batch_size=8, num_workers=0, shuffle=True)

2.4 使用torchvision.datasets下面的数据集
-
如果想自己下载一些经典的数据集,可以在这里下载: https://pytorch.org/vision/stable/datasets.html
import torchvision dataset_transform = torchvision.transforms.Compose([torchvision.ToTensor()]) train_set = torchvision.datasets.CIFAR10(root='./dataset', train=True, transform=dataset_transform, download=True) test_set = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=dataset_transform, download=True)不做transform时候的原始内容:

三、 Tensorboard
pytorch1.1 之后加入了Tensorboard功能
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('logs')
for i in range(100):
writer.add_scalar('y=x', i, i) # 注意('name',y轴, x轴)
writer.close()
之后在terminal运行:
tensorboard --logdir=logs


删除历史纪录的话,只需要删除掉logs文件夹下面的东西即可
下面的代码是展示图片的,一定注意加一个dataformats=‘HWC’
from torch.utils.tensorboard import SummaryWriter
import cv2
writer = SummaryWriter('logs')
img = cv2.imread('C:/Users/wuke2/Desktop/1.jpg')
writer.add_image('mnist', img , 1, dataformats='HWC') # 1代表step
writer.close()
四、搭建网络
4.1 常用API及说明
| API | 说明 |
|---|---|
| fc_1 = nn.Linear(in_features, out_features) | 输入:(∗,in_features) 输出:(∗,out_features) |
| conv_1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3) | 输入:(-1,C,H,W) 类型float |
| pool_1 = nn.MaxPool2d(kernel_size=3, stride=2) | 输入:(-1,C,H,W) 类型float |
| x = nn.ReLU(x) | 输入: (batchsize,***) |
| bn_1 = nn.BatchNorm2d(num_features=C) | 输入:(-1,C,H,W) |
| nn.Squential(layer_1, layer_2 …) | 不用写class了(forward方法) |
| nn.Transformer、nn.LSTM、etc. | 套件层 |
| nn.Flatten() | 展平 |
-
所有的神经网络必须继承nn.Module类
import torch.nn as nn import torch.nn.functional as F # 激活函数 class Model(nn.Module): def __init__(self): super(Model, self).__init__() ... def forward(self,x): # forward方法必须要自己重写 ...torch.nn是对torch.nn.functional的一个高层封装。
-
torch.nn.functional.conv2d
# torch.nn.functional.conv2d
import torch
import torch.nn.functional as F
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
kernel = torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
input = torch.reshape(input, (1,1,5,5))
kernel = torch.reshape(kernel, (1,1,3,3))
output = F.conv2d(input, kernel, stride=1)
-
torch.nn.Conv2d 输入必须是float32
import torch import torch.nn.functional as F import torch.nn as nn input = torch.tensor([[1,2,0,3,1], [0,1,2,3,1], [1,2,1,0,0], [5,2,3,1,1], [2,1,0,1,1]], dtype=torch.float32) input = torch.reshape(input, (1,1,5,5)) conv_layer = nn.Conv2d(1,1,3) output = conv_layer(input) -
nn.MaxPool2d
cell_mo del=True: 保留边界部分
cell_model=False:不保留边界部分
import torch import torch.nn as nn pool1 = nn.MaxPool2d(3, stride=2) input = torch.randn(1,16,224,224) output = pool1(input) -
nn.Linear
import torch.nn as nn import torch fc_1 = nn.Linear(3,2) input = torch.tensor([[1,1,1],[2,2,2],[3,3,3]],dtype=torch.float32) input == torch.reshape(input,(1,1,3,3)) output = fc_1(input) # (1,1,3,3) -> (1,1,3,2) 对每一行加权求和,改变列数 -
nn.Sequential
model = nn.Sequential( nn.Conv2d(1,20,5), nn.ReLU(), nn.Conv2d(20,64,5), nn.ReLU() )
4.2 正经写一个网络
我们选择VGG16, input(-1, 3, 224, 224)
参考地址:https://blog.csdn.net/qq_42012782/article/details/123222042
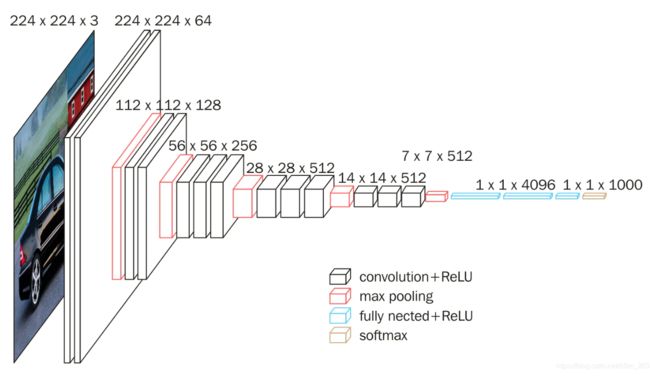
import torch.nn as nn
import torch
from torch.nn import Linear, Conv2d, Sequential, ReLU, MaxPool2d, Flatten
class VGG16(nn.Module):
def __init__(self):
super(VGG16, self).__init__()
self.conv_1_1 = Conv2d(3, 64, kernel_size=3, padding=1)
self.conv_1_2 = Conv2d(64, 64, kernel_size=3, padding=1)
self.relu = ReLU()
self.pool_1 = MaxPool2d(kernel_size=2, stride=2)
self.conv_2_1 = Conv2d(64, 128, kernel_size=3, padding=1)
self.conv_2_2 = Conv2d(128, 128, kernel_size=3, padding=1)
self.pool_2 = MaxPool2d(kernel_size=2, stride=2)
self.conv_3_1 = Conv2d(128, 256, kernel_size=3, padding=1)
self.conv_3_2 = Conv2d(256, 256, kernel_size=3, padding=1)
self.conv_3_3 = Conv2d(256, 256, kernel_size=3, padding=1)
self.pool_3 = MaxPool2d(kernel_size=2, stride=2)
self.conv_4_1 = Conv2d(256, 512, kernel_size=3, padding=1)
self.conv_4_2 = Conv2d(512, 512, kernel_size=3, padding=1)
self.conv_4_3 = Conv2d(512, 512, kernel_size=3, padding=1)
self.pool_4 = MaxPool2d(kernel_size=2, stride=2)
self.conv_5_1 = Conv2d(512, 512, kernel_size=3, padding=1)
self.conv_5_2 = Conv2d(512, 512, kernel_size=3, padding=1)
self.conv_5_3 = Conv2d(512, 512, kernel_size=3, padding=1)
self.pool_5 = MaxPool2d(kernel_size=2, stride=2)
self.flatten = Flatten()
self.fc_1 = Linear(25088,4096)
self.fc_2 = Linear(4096,4096)
self.fc_3 = Linear(4096,1000)
self.fc_4 = Linear(1000,2)
def forward(self, x):
x = self.conv_1_1(x)
x = self.conv_1_2(x)
x = self.relu(x)
x = self.pool_1(x)
x = self.conv_2_1(x)
x = self.conv_2_2(x)
x = self.relu(x)
x = self.pool_2(x)
x = self.conv_3_1(x)
x = self.conv_3_2(x)
x = self.conv_3_3(x)
x = self.relu(x)
x = self.pool_3(x)
x = self.conv_4_1(x)
x = self.conv_4_2(x)
x = self.conv_4_3(x)
x = self.relu(x)
x = self.pool_4(x)
x = self.conv_5_1(x)
x = self.conv_5_2(x)
x = self.conv_5_3(x)
x = self.relu(x)
x = self.pool_5(x)
x = self.flatten(x)
x = self.fc_1(x)
x = self.relu(x)
x = self.fc_2(x)
x = self.relu(x)
x = self.fc_3(x)
x = self.relu(x)
x = self.fc_4(x)
return x
4.3 Tensorboard可视化网络结构
from torch.utils.tensorboard import SummaryWriter
input = torch.randn((1,3,224,224))
vgg16 = VGG16()
writer = SummaryWriter('../logs')
writer.add_graph(vgg16, input)
writer.close()
在命令行:
tensorboard --logdir=logs

4.4 官方封装好的的网络模型
-
torchvision.models
查询都有啥模型: https://pytorch.org/vision/stable/models.html
import torchvision model = torchvision.models.vgg16(pretrained=True) input = torch.randn((1,3,224,224)) output = model(input) output.shape -
外加: 注意,外加层的话必须重写forward函数
import torchvision class Model(nn.Module): def __init__(self): super(Model, self).__init__() self.backbone = torchvision.models.vgg16(pretrained=False) self.fc = nn.Linear(1000,2) def forward(self,x): return self.fc(self.backbone(x)) input = torch.randn((1,3,224,224)) model = Model() output = model(input) output.shape
五、训练
5.1 损失函数
| API | 说明 |
|---|---|
| nn.L1Loss | 输入: (N,C,H,W) |
| nn.MSELoss | 输入: (N,C) |
-
nn.L1Loss
import torch from torch.nn import L1Loss inputs = torch.reshape(torch.tensor([1,2,3],dtype=torch.float32),(1,1,1,3)) targets = torch.reshape(torch.tensor([1,2,5],dtype=torch.float32),(1,1,1,3)) loss = L1Loss() result = loss(inputs, targets) result -
nn.MSELoss
import torch from torch.nn import L1Loss, MSELoss inputs = torch.reshape(torch.tensor([1,2,3],dtype=torch.float32),(1,1,1,3)) targets = torch.reshape(torch.tensor([1,2,5],dtype=torch.float32),(1,1,1,3)) loss = MSELoss() result = loss(inputs, targets) result -
nn.CrossEntropyLoss
输入(N,C) 输出(N)
分类问题最常用的损失函数
l o s s ( x , c l a s s ) = − l n ( e x [ c l a s s ] Σ e x [ c l a s s ] ) = − x [ c l a s s ] + l n ( Σ e x [ c l a s s ] ) loss(x,class) = -ln(\frac{e^{x[class]}}{\Sigma e^{x[class]}}) \\ = -x[class] + ln(\Sigma e^{x[class]}) loss(x,class)=−ln(Σex[class]ex[class])=−x[class]+ln(Σex[class])
以三分类为例:
y = ( 0.1 , 0.2 , 0.8 ) , l a b e l = ( 0 , 0 , 1 ) l o s s = − 0.8 + l n ( e 0.1 + e 0.2 + e 0.8 ) y = (0.1,0.2,0.8), \quad label=(0,0,1) \\ loss = -0.8 + ln(e^{0.1} +e^{0.2}+e^{0.8} ) y=(0.1,0.2,0.8),label=(0,0,1)loss=−0.8+ln(e0.1+e0.2+e0.8)import torch from torch.nn import L1Loss, MSELoss, CrossEntropyLoss inputs = torch.reshape(torch.tensor([[0.1,0.2,0.9],[0,0,1]],dtype=torch.float32),(2,3)) targets = torch.reshape(torch.tensor([[0,0,1],[0,0,1]],dtype=torch.float32),(2,3)) loss = CrossEntropyLoss() result = loss(inputs, targets) # [-0.9+ln(4.78), 0] result
5.2 优化器
torch.optim
- 定义 -> 梯度清零 -> step
optim = torch.optim.SGD(vgg16.parameters(), lr=0.1)
EPOCH = 20
for epoch in range(EPOCH):
print('--epoch--')
for data in train_DataLoader:
imgs, targets = data
outputs = vgg16(imgs)
result_loss = loss(outputs, targets)
print(result_loss)
optim.zero_grad()
result_loss.backward()
optim.step()
5.3 模型的保存和加载
-
模型的保存与加载有两种方式:
-
方式① 完整的保存模型的结构和参数到’.pth’文件中
-
方式② 将模型的参数保存到字典中,但是load时,需要用定义结构好的类去load
-
-
方式①
import torchvision
import torch
# 同时保存网络的结构和参数
vgg16 = torchvision.models.vgg16(pretrained=False)
torch.save(vgg16, './vgg16.pth')
model_load = torch.load('./vgg16.pth')
- 方式②
import torchvision
import torch
vgg16 = torchvision.models.vgg16(pretrained=True)
torch.save(vgg16.state_dict(), './vgg16_para.pth')
model = torchvision.models.vgg16(pretrained=False)
model.load_state_dict( './vgg16_para.pth')
5.4 完整的训练代码(CPU)
print("训练集的长度为:{}".format(len(train_dataset)))
print("测试集的长度为:{}".format(len(test_dataset)))
# 设置超参数
learning_rate, epoch_num = 1e-3, 20
# 网络、损失、优化器
vgg16 = VGG16()
loss = nn.CrossEntropyLoss()
optim = torch.optim.SGD(vgg16.parameters(), lr=learning_rate)
# 开始训练
total_train_step = 0
for epoch in range(epoch_num):
print('--epoch:' + str(epoch_num) + 'th start!')
# 训练
vgg16.train()
for data in train_DataLoader:
imgs, targets = data
outputs = vgg16(imgs)
result_loss = loss(outputs, targets)
optim.zero_grad()
result_loss.backward()
optim.step()
total_train_step += 1
print('训练次数:{}, Loss:{}'.format(total_train_step,result_loss.item()))
# 测试
vgg16.eval()
with torch.no_grad():
total_loss = 0
total_acc = 0
for data in test_DataLoader:
imgs, targets = data
outputs = vgg16(imgs)
result_loss = loss(outputs, targets)
total_loss += result_loss
accuracy = (outputs.argmax(1) == targets).sum()
total_acc += accuracy
total_acc = total_acc/len(test_dataset)
print('Test epoch:{}, Loss:{}, Acc:{}'.format(epoch,total_loss.item(),total_acc))
5.5 在GPU上训练
!nvidia-smi #查看GPU信息

都是在train函数中改,(model,loss,imgs,labels)这四个需要cuda()方法
# 网络、损失、优化器
vgg16 = VGG16()
vgg16 = vgg16.cuda()
loss = nn.CrossEntropyLoss()
loss = loss.cuda()
optim = torch.optim.SGD(vgg16.parameters(), lr=learning_rate) #优化器不需要cuda
for data in train_DataLoader:
imgs, targets = data
imgs, targets = imgs.cuda(), targets.cuda()
完整版:
print("训练集的长度为:{}".format(len(train_dataset)))
print("测试集的长度为:{}".format(len(test_dataset)))
# 设置超参数
learning_rate, epoch_num = 1e-2, 20
# device
device = torch.device('cuda:0')
# 网络、损失、优化器
vgg16 = VGG16()
vgg16 = vgg16.cuda()
# vgg16 = vgg16.to(device)
loss = nn.CrossEntropyLoss()
loss = loss.cuda()
# loss = loss.to(device)
optim = torch.optim.SGD(vgg16.parameters(), lr=learning_rate)
# 开始训练
total_train_step = 0
for epoch in range(epoch_num):
print('--epoch:' + str(epoch_num) + 'th start!')
# 训练
vgg16.train()
for data in train_DataLoader:
imgs, targets = data
imgs, targets = imgs.cuda(), targets.cuda()
# imgs, targets = imgs.to(device), targets.to(device)
outputs = vgg16(imgs)
result_loss = loss(outputs, targets)
optim.zero_grad()
result_loss.backward()
optim.step()
total_train_step += 1
print('训练次数:{}, Loss:{}'.format(total_train_step,result_loss.item()))
# 测试
vgg16.eval()
with torch.no_grad():
total_loss = 0
total_acc = 0
for data in test_DataLoader:
imgs, targets = data
imgs, targets = imgs.cuda(), targets.cuda()
outputs = vgg16(imgs)
result_loss = loss(outputs, targets)
total_loss += result_loss
accuracy = (outputs.argmax(1) == targets).sum()
total_acc += accuracy
total_acc = total_acc/len(test_dataset)
print('Test epoch:{}, Loss:{}, Acc:{}'.format(epoch,total_loss.item(),total_acc))