论文Is Space-Time Attention All You Need for Video Understanding?阅读笔记
目录
写在前面:
1.Introduction
2.TimeSformer model
2.1Joint Space-Time
2.2Divided Space-Time
2.3Other models
3.Experiments
3.1experiment 1 不同架构在K400与SSv2的精度比较
3.2experiment 2 joint space-time和divided space-time的成本比较
3.3experiment 3 与3D CNNS 的比较
3.4experiment 4增加帧数/增加patch个数对结果的影响
3.5experiment 5与SOTA的比较
3.6experiment 6Long-Term Video Modeling验证
3.7experiment 7额外的消融实验
3.8experiment 8 可视化结果
写在前面:
要从Transformer在NLP领域的一举成名说起,这种简单只使用注意力机制(attention)的结构在机器翻译等等方向都取得了不错的效果。顾名思义,这篇文章的方法基于Transformer提出了一种用于视频理解的框架,是Google提出的用于图像的Transformer-ViT(VisionTransformer)的扩展,将该方法命为TimeSformer(Time-Space Transformer)。
对于基本的Transformer不再赘述,对于 ViT进行简单介绍。ViT的目标是将标准 Transformer 直接应用于图片,做最少的修改,不做任何针对视觉任务的特定的改变。做法是将一幅图片(224*224)划分成很多 patches,每个 patch 元素 是 16 * 16,序列长度 14 * 14 = 196个元素。每一个 patch 经过一个 FC layer(fully connected layer)得到一个 linear embedding,但图片的 patches 是有顺序的,Patch embedding + position embedding == token ,包含 图片 patch 信息 和 patch 在原图中的位置信息。得到 tokens 之后,对其进行 NLP 操作。tokens 传入 Transformer encoder,得到很多输出。就将vision问题转化为NLP问题。
附ViT模型图:

总结ViT
- 打通了 CV 和 NLP 之间的鸿沟
- 挖了一个更大的多模态的坑 视频、音频、基于 touch 的信号 各种 modality 的信号都可以拿来用
ViT证明了Transformer可以应用于图片,对于具有时空信息的视频,文章《Is Space-Time Attention All You Need for Video Understanding?》提出了几种基于时空容量(space-time volume)的可扩展自我注意设计结构。这其中最好的设计是“分散注意力(divided attention)”架构,它分别在网络的每个区块内应用时间注意力和空间注意力。
论文阅读笔记:
1.Introduction
视频理解任务和NLP的相同点:
- Sequential 连续性:视频和句子基本上都是连续的。
- Contextual 具有上下文联系:句子中某个单词的意思通常需要通过将其与句子中的其他单词联系起来来理解;对于视频来说,为了消除歧义,片段中的行为也需要与视频的其余部分结合起来。
所以,NLP的自注意模型可能会对视频建模有效。因为其不仅可以捕捉跨时序的依赖关系,还可以通过对不同空间位置的特征进行两两比较,从而揭示每一帧中的上下文信息。
尽管在GPU硬件加速方面取得了进步,但训练深度cnn仍然非常昂贵,特别是当应用于高分辨率和长视频时。基于这些观察结果,文章提出了一个完全建立在self-atention之上的视频架构。通过将自注意力机制从图像空间扩展到时空三维体积,将图像模型“Vision Transformer”(ViT)应用于视频。提出的模型名为“TimeSformer”,将视频视为从单个帧中提取的patches序列。与ViT一样,每个patch都被线性映射到一个embedding中,并添加了位置信息。
自我注意的一个缺点是,它需要计算所有tokens的相似性度量。由于视频中存在大量的patches,这一计算成本很高。为了解决这一问题,文章提出了几种可扩展的时空自我注意设计,并在大规模行动分类数据集上对它们进行了实证评估。在所提出的方案中,发现最佳设计由一个“divided attention”架构表示,该架构在网络的每个区块内分别应用时间注意和空间注意。它实现的精度可与该领域的最先进技术相媲美,而且在某些情况下更先进。实验还表明,模型可以用于持续数分钟的视频的long-range 建模。
2.TimeSformer model
2.1Joint Space-Time

Input clip(模型输入):
![]()
代表F帧的RGB图像,每张图片尺寸为H×W。
![]()

其中![]() 代表一个可学习的位置嵌入,添加用来编码每个patch的时空位置。嵌入向量的结果序列表示Transformer的输入,类似于NLP中单词序列的作用。与BERT Transformer一样,在序列第一个位置添加一个特殊向量
代表一个可学习的位置嵌入,添加用来编码每个patch的时空位置。嵌入向量的结果序列表示Transformer的输入,类似于NLP中单词序列的作用。与BERT Transformer一样,在序列第一个位置添加一个特殊向量![]() 表示分类token的embedding。
表示分类token的embedding。

其中,LN()代表LayerNorm层归一化,不采用BN的原因在于, BN是对数据的每个channel进行Norm,LN是对单个数据的指定维度进行Norm,因为数据不同channel长短不齐,因此采用LN。
得到三个重要的虚拟值后,下一步就是搬出softmax公式,计算attention值。在这里要注意,q值和k值是点乘操作,需要对q进行转置。由于transformer是多头attention结构,a表示当前是多头attention的第几个attention。![]() 代表每个attention的维度,SM代表softmax。
代表每个attention的维度,SM代表softmax。
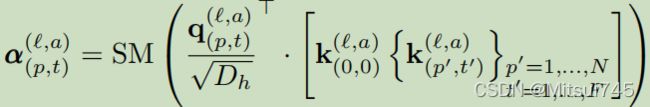
softmax操作结束后,最后一步——把得到的attention值和value值相乘求和,得到当前patch和相邻空间/时间上patch的关联信息。

最后,将attention模块中multi-head的部分做处理,把这些单个的attention结构得到的值拼接到一起。然后乘上权重,与编码器输出的![]() 相加,实现short-cut的操作。
相加,实现short-cut的操作。

下面就是MLP部分,通过感知机嵌套LN计算得到的值,再和attention部分得到的![]() 相加,得到最后的输出值。
相加,得到最后的输出值。

最后收尾步骤就是完成分类任务。使用一个hidden layer的感知机,输出视频类别。

2.2Divided Space-Time
提出了一种更有效的时空注意结构,名为“Divided Space-Time Attention”(用T+S表示),其中时间注意和空间注意分别相互应用。即在计算attention值部分,将时序与空间分别计算:
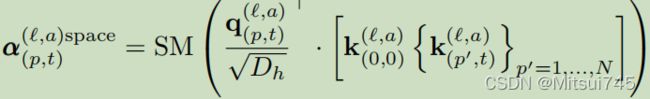

实验表明,这种时空分解不仅效率更高,而且提高了分类精度。
2.3Other models
文章还实验了“稀疏局部全局”(L+G)和“轴向”(T+W+H)注意模型。它们的体系结构如图所示。

这些模型注意的patches如下所示

- 空间注意力机制(S):只取同一帧内的图像块进行自注意力机制;
- 时空共同注意力机制(ST):取所有帧中的所有图像块进行注意力机制;
- 分开的时空注意力机制(T+S):先对不同帧中,相同位置的patch进行注意力机制,再对同一帧中的所有图像块进行自注意力机制;
- 稀疏局部全局注意力机制(L+G):先利用所有帧中,相邻的 H/2 和 W/2 的图像块计算局部的注意力,然后在空间上,使用2个图像块的步长,在整个序列中计算自注意力机制,这个可以看做全局的时空注意力更快的近似;
- 轴向的注意力机制(T+W+H):先在时间维度上进行自注意力机制,然后在纵坐标相同的图像块上进行自注意力机制,最后在横坐标相同的图像块上进行自注意力机制。
3.Experiments
在四个数据集上进行实验:Kinetics-400,Kinetics-600, Something-Something-v2,Diving-48,采用在ImageNet-1k上预训练的“基础”ViT模型架构。使用大小为8×224×224的clip,帧采样率为1/16。patch大小设置为16 × 16。
3.1experiment 1 不同架构在K400与SSv2的精度比较

注意到Space(S)的TimeSformer仅在K400上表现良好。事实上,之前的研究(Sevilla-Lara等人,2021)已经表明,在K400上,空间线索比时间信息更重要,以获得较强的准确性。在这里,我们证明了在没有任何时间建模的情况下,可以对K400获得可靠的精度。但是,请注意,仅限空间的注意在SSv2上的表现很差。这强调了对后一个数据集的时间建模的重要性。此外,我们观察到Divided Space-Time在K400和SSv2上都取得了最好的精度。这是有道理的,因为与联合时空注意相比,Divided Space-Time具有更大的学习能力(见表1),因为它包含了不同的时间注意和空间注意的学习参数。
3.2experiment 2 joint space-time和divided space-time的成本比较

文章还比较了在使用更高的空间分辨率(左)和更长的(右)视频时,joint space-time和divided space-time的计算成本。我们注意到,在这两种设置下,divided space-time的方案显然更优越。相比之下,当增加分辨率或视频长度时,joint space-time方案的成本显著提高。
3.3experiment 3 与3D CNNS 的比较
旨在理解TimeSformer与三维卷积架构相比的区别特性,这是近年来视频理解的突出方法。
模型容量:

虽然TimeSfromer具有较大的学习能力(参数数为121.4M),但它的推理成本较低(TFLOPs中为0.59)。相比之下,尽管SlowFast8x8R50只包含34.6M个的参数,但它具有更大的推理成本(1.97TFLOPs)。这表明,TimeSformer更适合于涉及大规模学习的设置。相比之下,现代3Dcnn的巨大计算成本使得其难以在进一步提高模型容量的同时也难以保持效率。
视频训练时间:
TimeSformer可以在训练时间更少的情况下获得更高的精度。
预训练的重要性:
由于参数的大量存在,从头开始训练我们的模型是很困难的。因此,在对视频数据进行训练时间分析器之前,我们用从ImageNet学习到的权重来初始化它。

由上表可见,在ImageNet-21K上预训练后获得的精度大于ImageNet-1k所得精度。另一方面,在SSv2上,我们观察到ImageNet-1K和ImageNet-21K的预训练导致了相似的精度。这是有道理的,因为SSv2需要复杂的时空推理,而K400更偏向于空间场景信息,因此,它从更大的训练前数据集学习的特征中获益更多。
视频数据尺寸的影响:

在K400上,TimeSformer在所有训练子集上都优于其他模型。然而,我们在SSv2上观察到一个不同的趋势,其中TimeSformer只有在75%或100%的完整数据上训练时才是最强的模型。这可能是因为与K400相比,SSv2需要学习更复杂的时间模式,因此时间器需要更多的例子来有效地学习这些模式。
3.4experiment 4增加帧数/增加patch个数对结果的影响

在空间上,增加到一定数量,精度会下降;而时序上,增加输入帧的数量,精度持续增加。
这里由于显存的限制,没有办法测试 96 帧以上的视频片段。作者说,这已经是一个很大的提升了, 因为目前的卷积模型,输入一般都被限制在 8-32 帧。
3.5experiment 5与SOTA的比较
文章使用了三种TimeSformer的变体:
TimeSformer :输入 8×224×224,8为帧数
TimeSformer-HR:空间清晰度比较高,输入为 16×448×448
TimeSformer-L:时间范围比较广,输入为 96×224×224



SSv2和Diving48上的结果,SSv2并没有达到最好的结果,作者提到说所提方法采用了完全不同的结构,对于这么有挑战性的数据集来说已经是比较好的了,有进一步发展的空间。
3.6experiment 6Long-Term Video Modeling验证
这部分实验在HowTo100M数据集上完成。它包含大约100万个教学网络视频,展示人类执行超过23K种不同的任务,如烹饪、修理、编织和艺术创作。这些视频的平均时长是7分钟。

3.7experiment 7额外的消融实验
3.8experiment 8 可视化结果

我们的研究结果表明,TimeSformer学习注意视频中的相关区域,以执行复杂的时空推理。例如,我们可以观察到,模型专注于手的配置,只关注不可见时的对象。
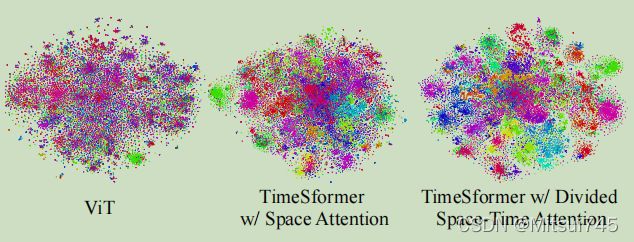
我们还可视化了时间分析器在V2上学习到的特性。可视化使用t-SNE(vanderMaaten&Hinton,2008)完成,其中每个点代表一个视频,不同的颜色描述不同的动作类别。在此基础上,我们观察到有划分时空注意的时间形成器比只有空间注意或ViT的TimeSformer学习更多的可分离特征.