2021李宏毅机器学习笔记--14 conditional generation by RNN & attention
2021李宏毅机器学习笔记--14 Conditional Generation by RNN & Attention
- 摘要
- 一、Generation
-
- 1.1 Generation
- 1.2 Conditional Generation
- 二、Attention
-
- 2.1 Attention
- 2.2 Dynamic Conditional Generation
- 2.3 Machine Translation
- 2.4 Speech Recognition
- 2.5 Image Caption Generation(图片字幕生成)
- 2.6 Memory Network(在Memory上做attention)
- 2.7 Neural Turing Machine(神经图灵机)
- 三、Tips for Generation
-
- 3.1 Attention的正则化
- 3.2 Mismatch between Train and Test
-
- 3.2.1 question
- 3.2.2 solution(解决办法)
-
- 3.2.2.1 Modifying Training Process
- 3.2.2.2 Scheduled Sampling
- 3.2.2.3 Beam Search(光束搜索)
- 3.2.2.4 Better idea?(输入的再讨论)
- 3.3 Object level v.s.Component level
- 总结
摘要
本文主要介绍了生成,我们可以生成句子,生成语音或者生成图片,并且也可以让机器学会联系上下文避免陷入重复循环错误等。在生成的时候也会有的曝光偏差问题,当前面开始出现错误的结果时,下一步被当作输入,到最后会导致误差累积,本文也介绍了解决几种办法。
一、Generation
1.1 Generation
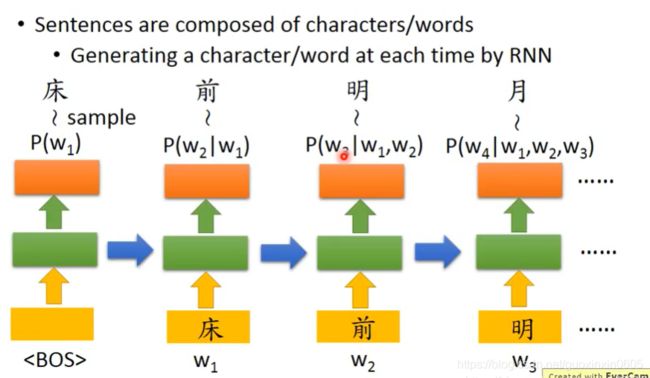
我们可以生成很多东西,比如生成一句话,一段音乐等等,拿生成句子为例,在我们生成好的RNNmodel里,我们输入开头,模型可以输出一系列的输出,如下图,我们根据输出得到了床,然后把床作为下一个时间点的输入,得到前,依次类推。当然,这是测试时的一种做法,并不是唯一做法。而在训练RNN模型的时候,并不是拿上一时刻的输出当作下一时刻的输入,而是拿真正的句子序列当作输入的。
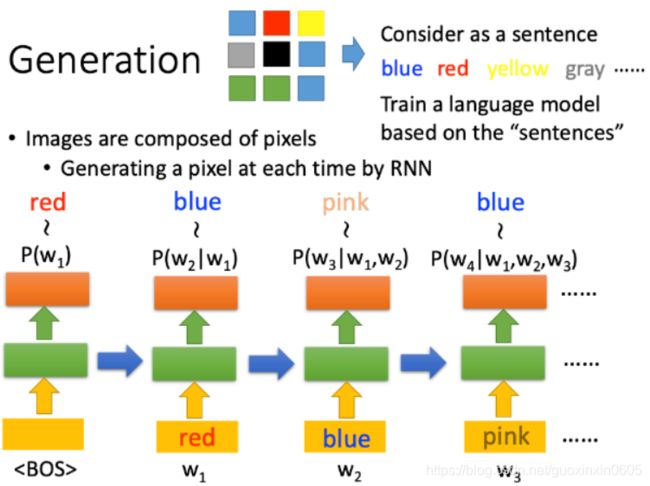
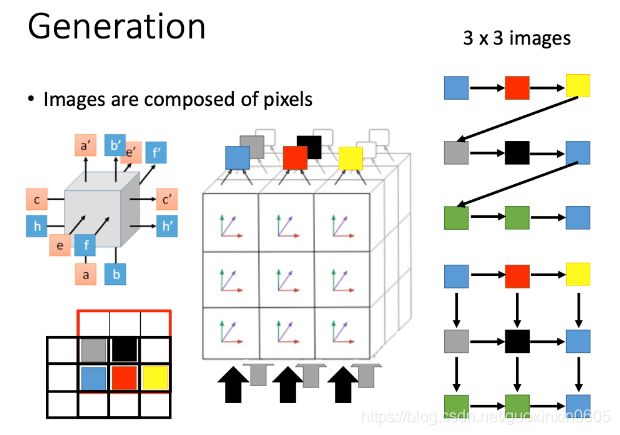
 如果想生成一张图片,我们可以把图片的每个pixel看成一个character,从而组成一个sentence,比如下图中蓝色pixel就表示blue,红色的pixel表示red,…
如果想生成一张图片,我们可以把图片的每个pixel看成一个character,从而组成一个sentence,比如下图中蓝色pixel就表示blue,红色的pixel表示red,…
接下来就可以用language model来生成图片,最初时间步的输入是特殊字符BOS
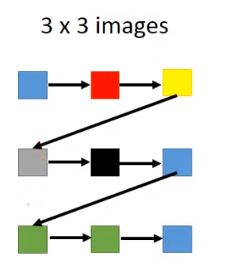
对于一般的generation,如下图所示,先根据蓝色pixel生成红色pixel,再根据红色pixel生成黄色pixel,再根据黄色pixel生成灰色pixel,…,并没有考虑pixel之间的位置关系
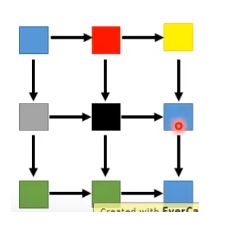
 还有另外一个比较理想的生成图像方法,如果考虑了pixel之间的位置关系,如下图所示,黑色pixel由附近的红色和灰色pixel生成
还有另外一个比较理想的生成图像方法,如果考虑了pixel之间的位置关系,如下图所示,黑色pixel由附近的红色和灰色pixel生成
 那么怎么建立模型呢?用到之前了解过的LSTM
那么怎么建立模型呢?用到之前了解过的LSTM
看下图的左上角,该lstm块输入了三组参数,也输出了三组参数,把这些方块叠起来就可以达到右部位置图像的效果
1.2 Conditional Generation
有时候,我们不想仅仅是随机生成一些句子,我们希望根据一些情景来生成我们的句子,比如对话系统,根据问题来生成我们的答案,再比如翻译系统,我们要根据给出的句子得到对应的翻译
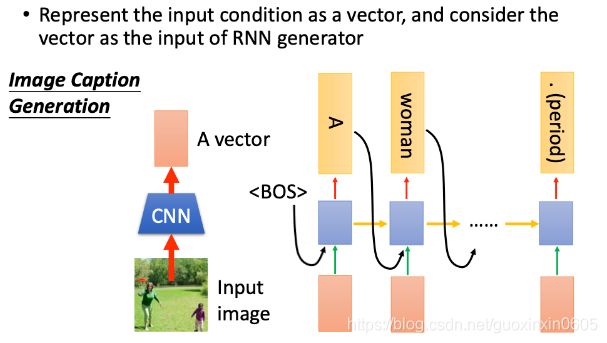
 如果要对一张图片进行解释,我们先使用一个CNN model将image转化为一个vector(红色方框),先生成了第一个单词"A",在生成第二个单词时,还需要将整个image的vector作为输入,不然RNN可能会忘记image的一些信息
如果要对一张图片进行解释,我们先使用一个CNN model将image转化为一个vector(红色方框),先生成了第一个单词"A",在生成第二个单词时,还需要将整个image的vector作为输入,不然RNN可能会忘记image的一些信息
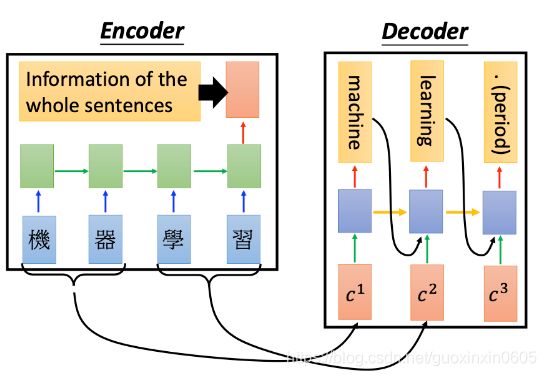
 RNN也可以用来做机器翻译,比如我们想要翻译“机器学习”,就先把这四个字分别输入绿色的RNN里面,最后一个时间节点的输出(红色方框)就包含了整个sentence的information,这个过程称之为Encoder
RNN也可以用来做机器翻译,比如我们想要翻译“机器学习”,就先把这四个字分别输入绿色的RNN里面,最后一个时间节点的输出(红色方框)就包含了整个sentence的information,这个过程称之为Encoder
把encoder的information再作为另外一个rnn的input,再进行output,这个过程称之为Decoder
encoder和decoder是jointly train(联合训练)的,这两者的参数可以是一样的,也可以是不一样的
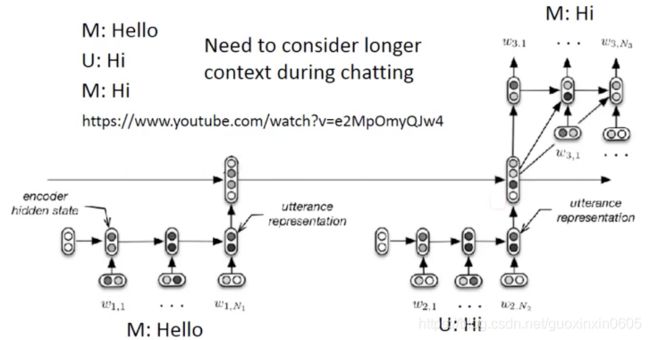
 在做Chat-bot的场景要更加复杂一点,正常的对话是
在做Chat-bot的场景要更加复杂一点,正常的对话是
人:hi
机器:hi
但是有可能有其他的情况
机器:hello
人:hi
机器:hi
这种情况就说明是异常的!!!
所以需要把前面说过的话要记住,然后考虑到当前的输出。一种方式是使用双层encoder把前面的话的向量表示加入当当前上文表示中,综合考虑
二、Attention
2.1 Attention
注意力这东西其实挺有意思,但是很容易被人忽略。让我们来直观地体会一下什么是人脑中的注意力模型。首先,请您睁开眼并确认自己处于意识清醒状态;第二步,请找到本文最近出现的一个“Attention Model”字眼(就是“字眼”前面的两个英文单词,…@@)并盯住看三秒钟。好,假设此刻时间停止,在这三秒钟你眼中和脑中看到的是什么?对了,就是“Attention Model”这两个词,但是你应该意识到,其实你眼中是有除了这两个单词外的整个一副画面的,但是在你盯着看的这三秒钟,时间静止,万物无息,仿佛这个世界只有我和你……对不起,串景了,仿佛这个世界只有“Attention Model”这两个单词。这是什么?这就是人脑的注意力模型,就是说你看到了整幅画面,但在特定的时刻t,你的意识和注意力的焦点是集中在画面中的某一个部分上,其它部分虽然还在你的眼中,但是你分配给它们的注意力资源是很少的。其实,只要你睁着眼,注意力模型就无时不刻在你身上发挥作用,比如你过马路,其实你的注意力会被更多地分配给红绿灯和来往的车辆上,虽然此时你看到了整个世界;比如你很精心地偶遇到了你心仪的异性,此刻你的注意力会更多的分配在此时神光四射的异性身上,虽然此刻你看到了整个世界,但是它们对你来说跟不存在是一样的……
这就是人脑的注意力模型,说到底是一种资源分配模型,在某个特定时刻,你的注意力总是集中在画面中的某个焦点部分,而对其它部分视而不见。
其实吧,深度学习里面的注意力模型工作机制啊,它跟你看见心动异性时荷尔蒙驱动的注意力分配机制是一样一样的。
2.2 Dynamic Conditional Generation
如果需要翻译的文字非常复杂,无法用一个vector来表示,就算可以表示也没办法表示全部的关键信息,这时候如果decoder每次input的都还是同一个vector,就不会得到很好的结果。
在输出machine这个单词的时候,没有必要去考虑输入中的【学习】这个部分,只用考虑【机器】这个部分就好,要把注意力关注到不同的部分。翻译的时候关注的输入不一样(之前的模型都是把整句话的向量丢过去)。因此我们现在先把“机器”作为decoder的第一个输入,这样就可以得到更好的结果
2.3 Machine Translation
绿色方块为RNN中hidden layer的output;还有一个vector,是可以通过network学出来的;把这两者输入一个match函数,可以得到match分数,这个match函数可以自己设计,可以有参数,也可以没有参数。
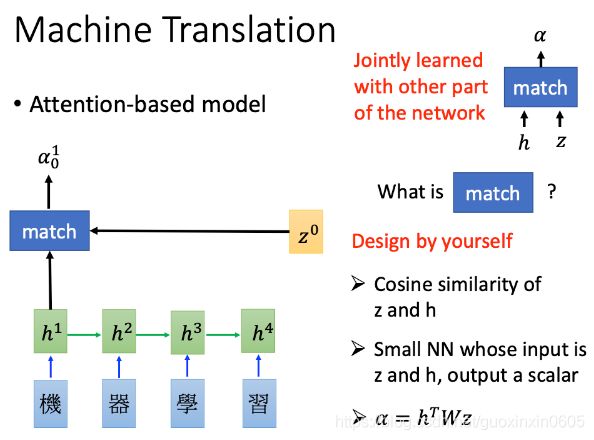 得出的结果再输入softmax函数,并且计算c0,c0和起始向量表示得到第一个output
得出的结果再输入softmax函数,并且计算c0,c0和起始向量表示得到第一个output
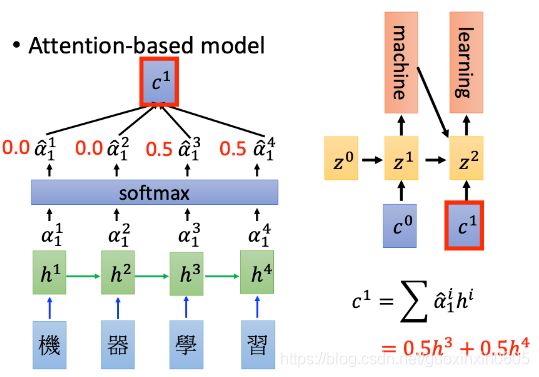
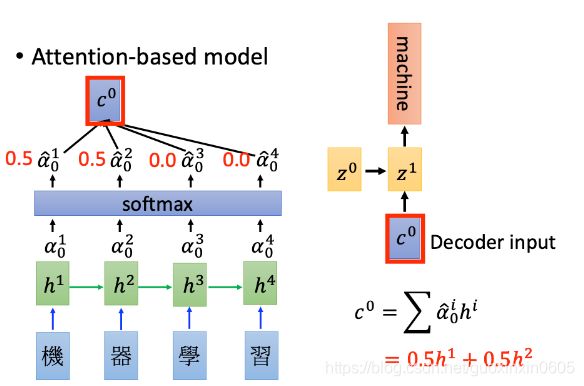 然后根据z1再算注意力和output
然后根据z1再算注意力和output
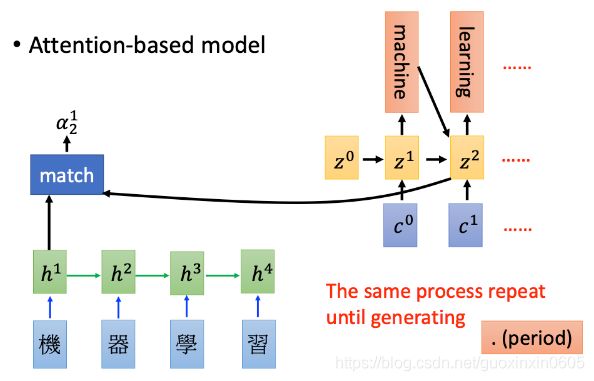
 一直重复这个过程,只到全部翻译完成
一直重复这个过程,只到全部翻译完成
2.4 Speech Recognition
语音信号也可以看成一系列的vector sequence,第一个红色方框所在的帧match分数很高,就把对应的vector放到decoder,machine就会得出“h”
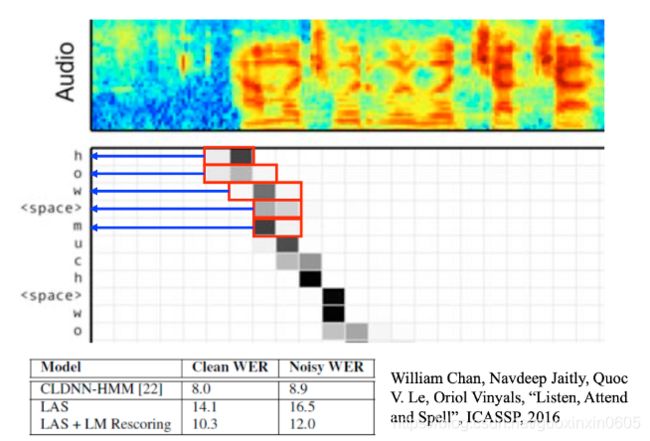
 结果虽然没有比传统方法好,但是这个方法还是很牛,应该是因为端到端的训练,而且结果也没有太烂
结果虽然没有比传统方法好,但是这个方法还是很牛,应该是因为端到端的训练,而且结果也没有太烂
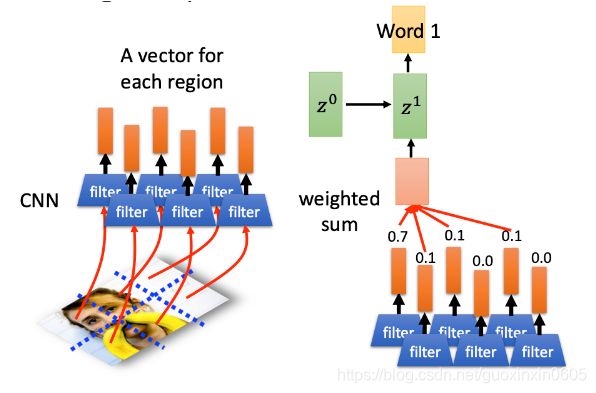
2.5 Image Caption Generation(图片字幕生成)
image可以分成多个region,每个region可以用一个vector来表示,计算这些vector和z0之间match的分数,为0.7、0.1…,再进行weighted sum,得到红色方框的结果,再输入RNN,得到Word1,此时hidden layer的输出为z^1
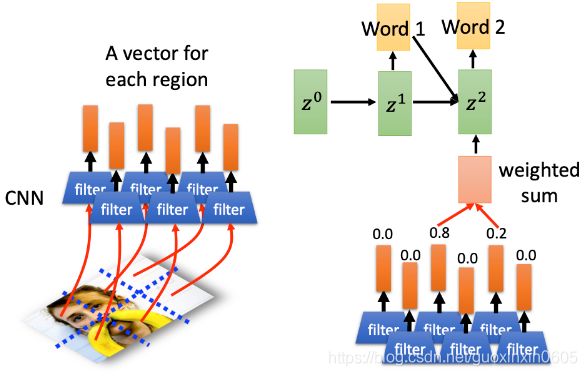
 再计算z1和vector之间的match分数,把分数作为RNN的input,从而得出Word 2
再计算z1和vector之间的match分数,把分数作为RNN的input,从而得出Word 2
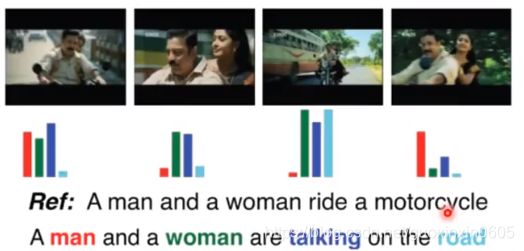
 attention可视化:
attention可视化:
 视频文字生成:
视频文字生成:

2.6 Memory Network(在Memory上做attention)
在Memory上做attention,最早是用在阅读理解上,给机器看一篇文章Document,然后让它回答Answer与文章相关的问题Query。
Document可以分为N个句子,每个句子可以表示为一个向量: x1,x2……xn
Query也可以表示为一个向量q
然后用q和Document中的每个句子算match score(相似度)得到 α 1 , α 2 , α 3 , . . . , α N
然后用match score和句向量做加权和。
这一系列操作就是算注意力的标准操作,意思就是我们计算了与Query有关的句子。
然后把Query和注意力的结果丢到DNN里面,得到Answer
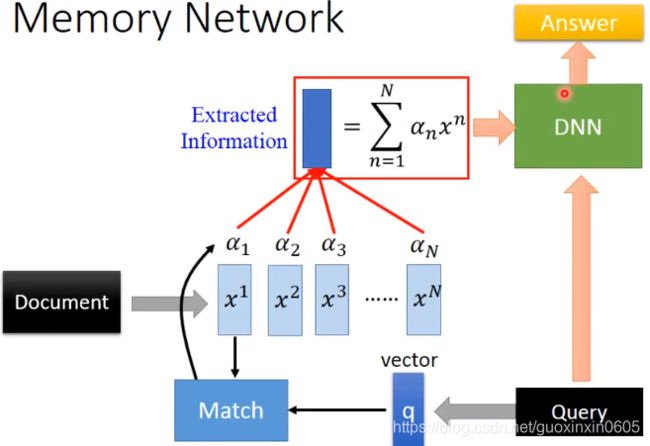 Sentence to vector can be jointly trained.
Sentence to vector can be jointly trained.
这个模型还有一个更加复杂的版本
就是计算相似度和抽取句向量两部分分开,相当于把句子用不同的参数变成两组不同的向量h和x
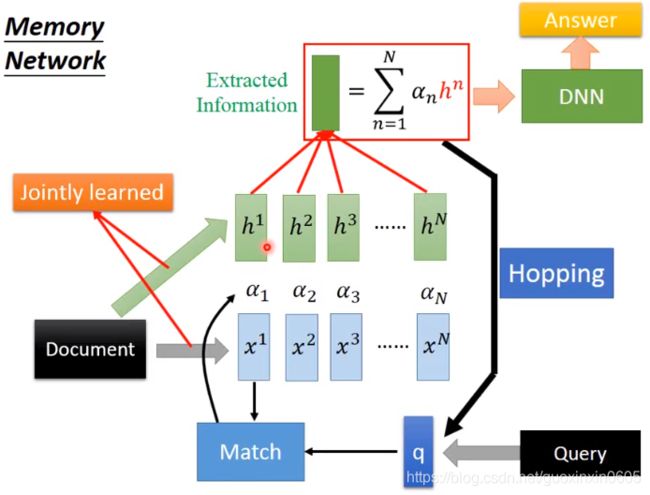 注意上面还有一个Hopping,相当于机器算出来注意力之后,再返回去算Match score,相当于不断的思考的过程。
注意上面还有一个Hopping,相当于机器算出来注意力之后,再返回去算Match score,相当于不断的思考的过程。
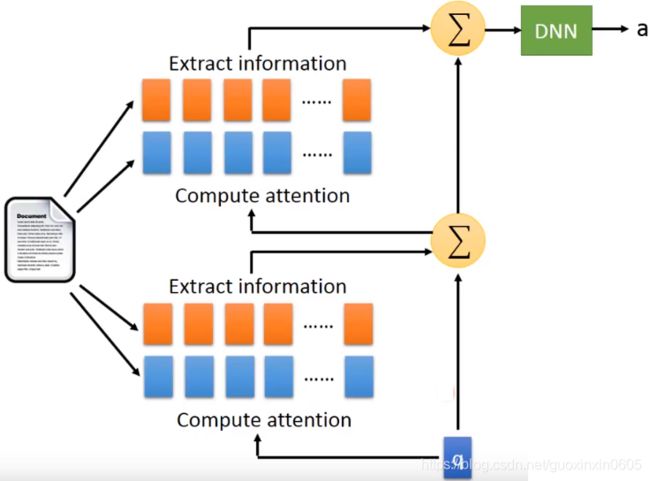
把这过程展开,实际上相当于两层注意力计算的叠加。当然下面的图中上下共四组句向量表示可以是都不一样的。
2.7 Neural Turing Machine(神经图灵机)
除了在memory中进行读之外,还可以在memory中写。
Neural Turing Machine not only read from memory Also modify the memory through attention.
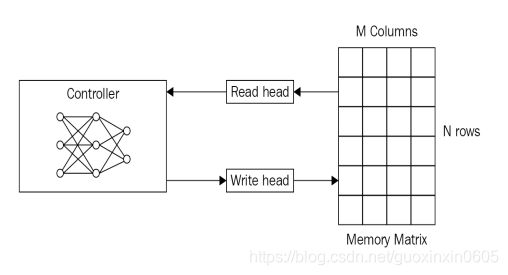
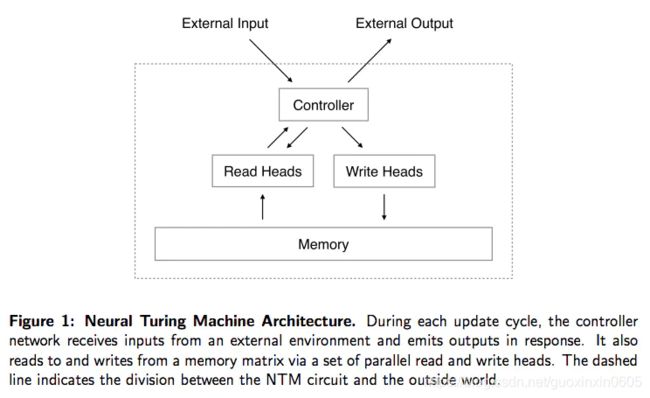 从上图可以看出,神经图灵机包含两个基本组成部分:神经网络控制器和记忆库。
从上图可以看出,神经图灵机包含两个基本组成部分:神经网络控制器和记忆库。
控制器: 这是一个基础的前馈神经网络或者递归神经网络,其主要负责从记忆库中读取信息或者在记忆库中写入信息。
记忆库: 记忆库通常以记忆矩阵或者记忆池的形式进行展现。我们将在记忆库中存储信息。一般情况下,记忆库是通过两个维度的矩阵所构成,矩阵中的每一个元素是一个记忆细胞。整个记忆矩阵包括N行M列。通过使用控制器,我们可以从记忆库中获取信息,因此,控制器可以从额外的环境中接受内容,并且能够通过与记忆矩阵的交互来做出反应
读头和写头: 读头和写头是包含记忆库地址的两个指针,记忆库地址指的是需要读取的地址和需要写入的地址
最简单的策略是通过记录记忆矩阵中行和列的地址来位置index,进而通过索引来访问和写入到记忆矩阵。当时这样存在一个问题,由于我们不能通过一个索引来执行梯度下降算法,所以我们利用这种方式就无法利用梯度下降算法来更新参数。所以NTM的作者就定义了基于读头和写头的模糊操作。这种模糊操作和记忆库中的部分信息进行交互。该操作的核心在于利用Attention机制来重点关注于记忆库的局部那些对于读写重要的信息,而忽略记忆库中的其他位置。因此,我们可以使用一个特殊的读和写操作来决定那些区域需要进行关注。
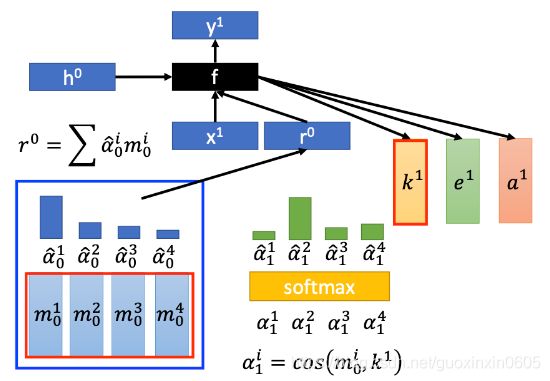
上面的过程是现有一个初始的attention(蓝色),计算的结果是 r 0 然后把 r 0丢到一个DNN(controller)里面,然后得到一组新的用于调整attention的参数,然后用softmax算出新attention权重(绿色)。上面是最简单的原理图,实际上要比这个复杂(不展开)
实际上,k与memory产生四个新值其实有5个步骤。如下
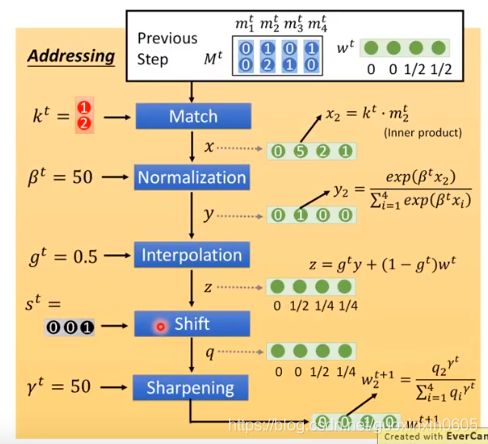 继续看原理图,在图中我们算出了 e 1和 a 1, e 1的作用是把memory的值清空, a 1的作用是把新的值写入memory,具体公式如下图所示。这个公式专注于修改分布中比较尖的部分,例如下图中 α 1 2 ^ hat比较尖,那么公式倾向于把 α12 ^ hat对应的值清 m 0 2 空,加入新的值。可以想象,如果m的维度是1(尖尖肯定是你),那么每次都是清空,换新的值。
继续看原理图,在图中我们算出了 e 1和 a 1, e 1的作用是把memory的值清空, a 1的作用是把新的值写入memory,具体公式如下图所示。这个公式专注于修改分布中比较尖的部分,例如下图中 α 1 2 ^ hat比较尖,那么公式倾向于把 α12 ^ hat对应的值清 m 0 2 空,加入新的值。可以想象,如果m的维度是1(尖尖肯定是你),那么每次都是清空,换新的值。
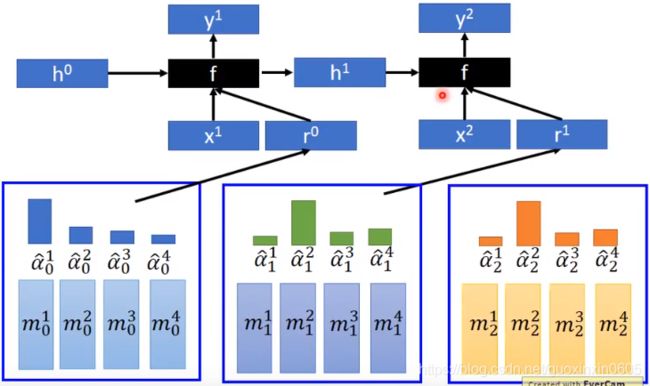
 以上步骤可以不断循环,f(黑方块)如果是RNN的话,还会单独参数当前的一个输出h,用于下一个attention的调整:
以上步骤可以不断循环,f(黑方块)如果是RNN的话,还会单独参数当前的一个输出h,用于下一个attention的调整:
三、Tips for Generation
3.1 Attention的正则化
attention是可以调节的,有时会出现一些bad attention,在产生第二个word(women)时,focus到第二个component,在产生第四个word时,也focus到第二个component上,也是women,多次attent在同一个frame上,就会产生一些很奇怪的结果。
i表示每一个部分(component),t表示每一个迭代。

3.2 Mismatch between Train and Test
3.2.1 question
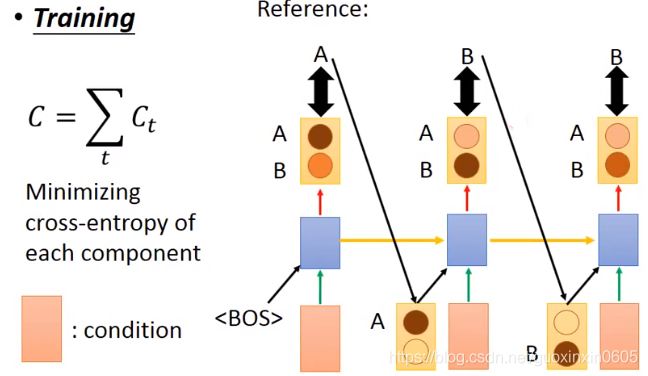 在训练阶段,我们在生成第一个A的时候考虑的是开始标签和条件(粉色块),输出第二个B的时候,考虑的是之前的标签A和条件,输出第三个B的时候,考虑的是之前的标签B和条件,整个模型要使得所有生成结果与标签之间的交叉熵的差异越小越好
在训练阶段,我们在生成第一个A的时候考虑的是开始标签和条件(粉色块),输出第二个B的时候,考虑的是之前的标签A和条件,输出第三个B的时候,考虑的是之前的标签B和条件,整个模型要使得所有生成结果与标签之间的交叉熵的差异越小越好
在生成阶段,我们不知道具体的标签,所以我们只能把RNN生成的结果接过来。在生成结果的时候应该是生成一个分布,然后从这个分布里面进行sample得到生成结果。
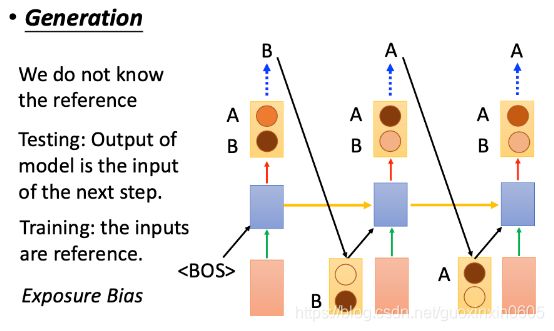 发现两个阶段的不同就是参考不一样,一个是看的参考答案,一个是凭感觉。
发现两个阶段的不同就是参考不一样,一个是看的参考答案,一个是凭感觉。
这个现象叫:Exposure Bias(曝光偏差)。这两个setting不一致会导致误差累积(error accumulate)。误差累积是因为,你在测试的时候,如果前面单元的输出已经是错的,那么你把这个错的输出作为下一单元的输入,那么理所当然就是“一错再错”,造成错误的累积。
正常的应该这样
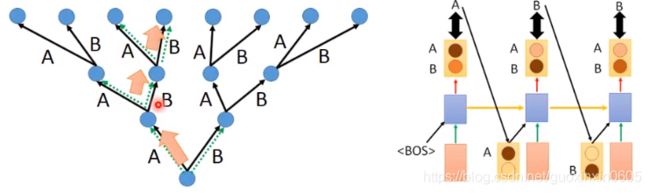 训练出错是这样:
训练出错是这样:
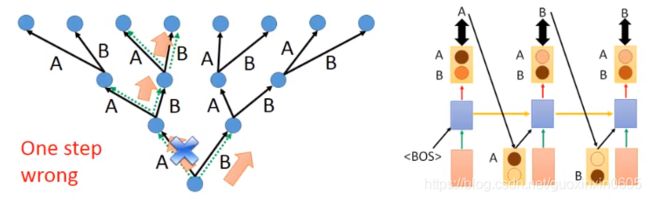 生成的时候出错直接一步错,步步错
生成的时候出错直接一步错,步步错

3.2.2 solution(解决办法)
3.2.2.1 Modifying Training Process
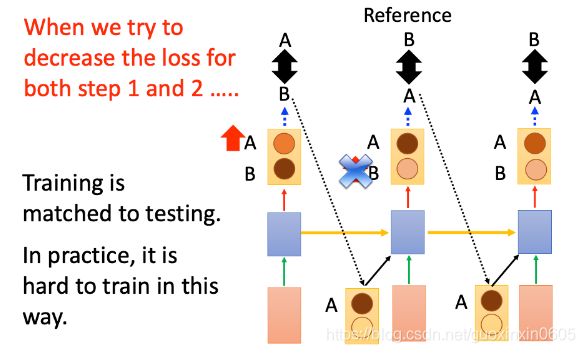
那么我们如何解决这种mismatch问题呢?可以尝试modify训练process
如果machine现在output B,即使是错误的output(和reference A不一样),我们也应该让这个错误的output作为下一次的input,那么training和testing就是match的;
但在实际操作中,training是非常麻烦的;现在我们使用gradient descent来进行training,第一个gradient的方向告诉我们要把A的几率增大,output B,在第二个时间点,input为B,看到reference为B,把B的几率增大,就可以和reference相对应起来;
但实际上,第一个output为A的几率上升,那么output发生了变化,第二个时间点的input就发生了变化,是A;那么我们之前学习到的让B上升就没有意义了
3.2.2.2 Scheduled Sampling
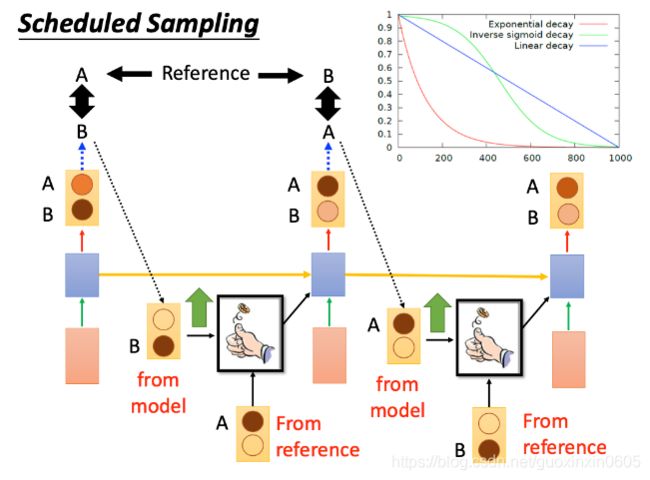
由于使用Modifying Training Process很难train,现在我们就使用Scheduled Sampling
对于到底是model里的ouput,还是reference来作为input,我们可以给一个几率;铜板是正面,就使用model的output,如果是反面,就用reference
右上角的图,纵轴表示from reference的几率,一开始只看reference,reference的几率不断变小,model的几率不断增加
 如果使用Scheduled Sampling,效果好很多。
如果使用Scheduled Sampling,效果好很多。
3.2.2.3 Beam Search(光束搜索)
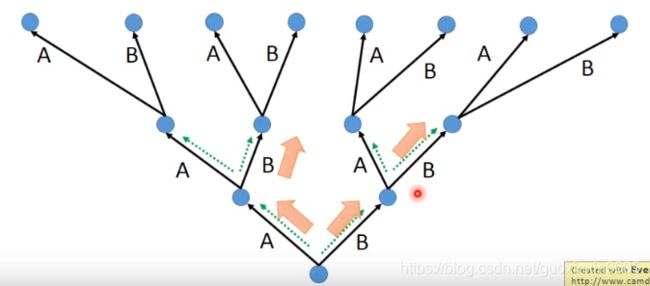
The green path has higher score. Not possible to check all the paths
绿色路径得分较高。无法检查所有路径
 Beam Search就类似动态规划算法,找出最优路径。
Beam Search就类似动态规划算法,找出最优路径。
Keep several best path at each step.
假设:Beam size=2
选两条最大值
3.2.2.4 Better idea?(输入的再讨论)
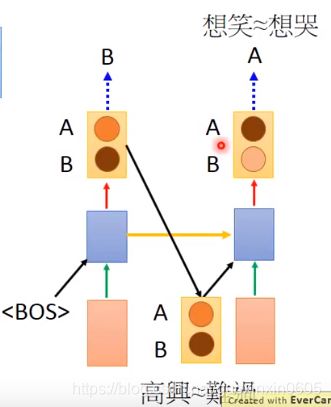
上面讨论的是用模型训练的结果或者标签作为下一个预测的输入。能不能直接用得到的分布作为输入?不好,老师给出的理解:
U : 你得如何?
M:高舆想笑or难过想哭
有以上对话,那么机器的回答其实没有标准答案,两个都是对的,只要不是高舆想哭or难过想笑就可以。
当我们用确定的某个结果作为下一个预测的输入:
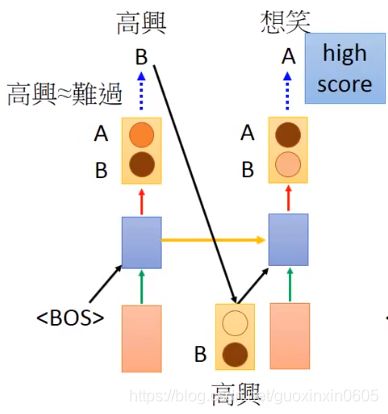
机器无论把高舆或难过的几率作为下一个输出的预测的输入是一样的。但是高兴对应想笑的几率比较高,难过对应想哭的几率比较高。
如果把分布作为预测的输入,那么机器学到的东西就是无论是输入高兴还是难过,输出想哭和想笑的几率是一样的。这样就会乱掉了。
3.3 Object level v.s.Component level
要考虑生成对象的整体效果,而不是注重细节。
例如:
下图中的标签是:The dog is running fast.
然后用的累加的交叉熵来衡量损失。
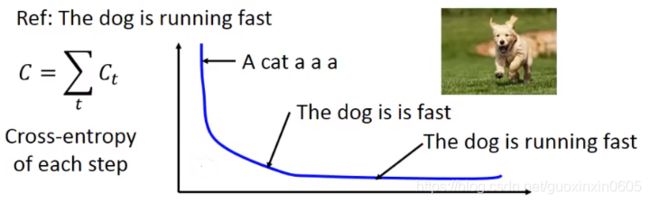 从函数损失曲线看,刚开始错误了5个单词,所以交叉熵比较大,当生成的结果是:
从函数损失曲线看,刚开始错误了5个单词,所以交叉熵比较大,当生成的结果是:
The dog is is fast,会发现损失值和正确标签的损失值差不多了,但是实际上这句话根本就不符合语法。如果用这个模型去做看图说话,就会有一大堆的语法错误(这里是叠字)。
意思是loss很好,但是表现很差。
因此我们要:Optimize object-level criterion instead of component-level cross-entropy.
用整体的效果来衡量损失。object-level criterion: R(y,y^)
y: generated utterance, y^: ground truth
但是这个玩意是否能求偏导做GD?不可以。
但是可以转换思路,用强化学习的思路来解决这个问题,把生成的句子和最后的标签做比较,生成reward,然后目标是最大这个reward。
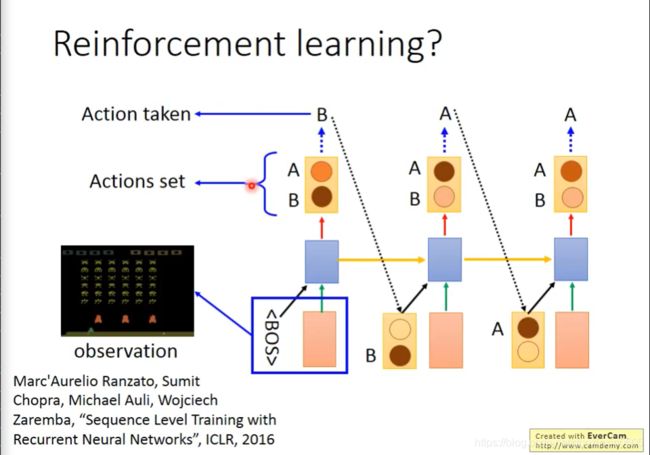 把 generation 这件事,当成 reinforcement learning 来做。
把 generation 这件事,当成 reinforcement learning 来做。
在结束后,通过R函数判断奖励值。
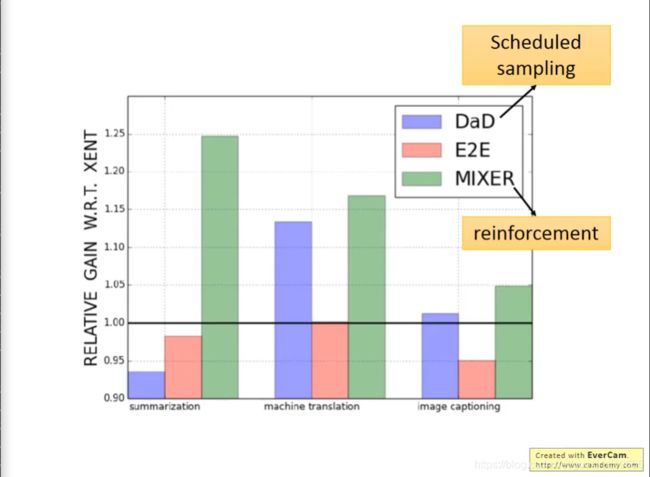
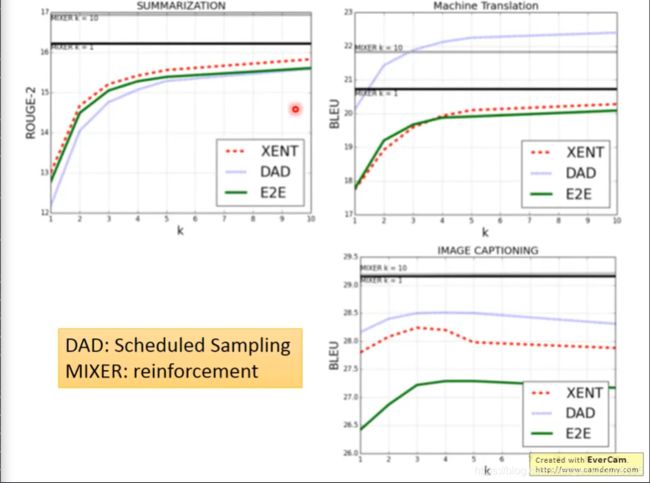 如上,MIXER是使用了强化学习与传统方法相结合的方法。
如上,MIXER是使用了强化学习与传统方法相结合的方法。
总结
本文主要介绍了生成以及注意力机制,针对摘要中提出的问题,文中也给了四种解决办法,可以修改培训流程,也可以预定采样,也可以重新讨论输入来解决问题。