关于文本数据预处理的一些方法
最近在进行一个关于深度学习的文本情感分类的项目,从数据获取到清洗,以及文本标注这些都在准备。文本预处理是NLP中十分关键的一个流程,正所谓数据是否优质决定着神经网络的训练效果,以及后续对神经网络的调参,本文分享一些基本的文本预处理方法。
文章目录
- 数据浏览
- 一、数据整合以及体量观测
- 二、文本数据分词
- 三、词云
- 四、句长统计
- 总结
数据浏览
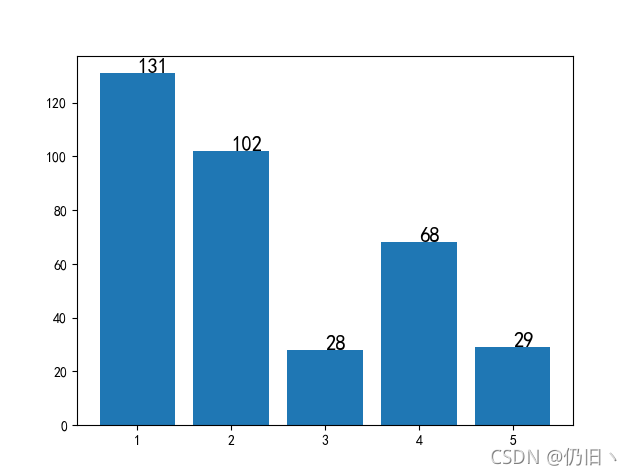
由于项目上运用到的情感分类数据是要用于进行5分类的情感分类,数据体量较大,本文只选取其中很小一部分进行预处理,大体数据集合如下:

一、数据整合以及体量观测
这部分更多是对数据进行读取以及对各个标签数据集合进行整合,对各个标记进行整合
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
one = pd.read_csv('情感-1.csv', encoding='gbk', header=None, )
two = pd.read_csv('情感-2.csv', encoding='gbk', header=None, )
three = pd.read_csv('情感-3.csv', encoding='gbk', header=None, )
four = pd.read_csv('情感-4.csv', encoding='gbk', header=None, )
five = pd.read_csv('情感-5.csv', encoding='gbk', header=None, )
# 画图进行各个数据量观测
def chart():
len_list = [len(one), len(two), len(three), len(four), len(five), ]
# plt.plot(range(1, 6), list)
plt.bar(range(1, 6), len_list, )
text = dict(list(zip(range(1, 6), len_list)))
for i, j in text.items():
plt.text(i, j, j, size = 15)
plt.show()
# 数据文件整合,把5个文件进行整合成一个,以便于后续分词和词向量训练
def to_data():
path = [one, two, three, four, five]
data = pd.concat(path)
data.to_csv('data.csv', header=False, index=False)
chart()
to_data()
结果预览:
二、文本数据分词
接下来就是对保存的文本进行一个分词操作,我们选用jieba分词,该分词有三种模式:
精确模式(jieba.cut()):把文本精确的切分开,不存在冗余单词
全模式(jieba.lcut()):把文本中所有可能的词语都扫描出来,有部分冗余单词
搜索引擎模式(jieba.lcut_for_search()):在精确模式基础上,对长词再次切分
import jieba
import pandas as pd
def cut_word():
data = pd.read_csv('data.csv', header=None, )[0]
# 创建新文件以构建分词文本文件
with open('cut_word.txt', 'w', encoding='utf-8')as fp:
for i in data:
fp.write(str(' '.join(jieba.lcut(i))))
fp.write(str('\n'))
cut_word()
效果展示:

由于是运用到文本情感分析上没有对分词进行停用词以及去掉一些符串操作,在情感分析中一些停用词的由于往往具有不同的情感。
三、词云
对分词文本进行词云统计,以获取该语料的词频特性,在词云绘制中我们需要对用于词云绘制的语料进行去停用词操作,停用词往往是一段话、一篇文章出现最多的,如果不去除我们生成的词云将会难以判断出语料的词频特性。
import numpy as np
import wordcloud
from PIL import Image
import matplotlib.pyplot as plt
def cloud(Save = False):
text = 'cut_word.txt'
with open(text, encoding='utf-8') as f:
text = f.read()
stopwords = set()
word = [line.strip() for line in open('Stopword.txt', 'r', encoding='utf-8').readlines()]
stopwords.update(word)
mask = np.array(Image.open('t01d0ea9f758acc4ce1.jpg'))
# 运用WordCloud自带的stopwords进行筛选
w = wordcloud.WordCloud(width=800,height=600,
background_color='white', font_path='SIMLI.TTF',
mask=mask, stopwords=stopwords)
w.generate(text)
plt.imshow(w)
plt.show()
if Save:
save_path = 'wordCloud.png' #保存词云图
w.to_file(save_path)
cloud(Save=True)
词云图片展示:通过这个图片我们就能直观得展示出语料得核心词,以及语料是什么性质的。

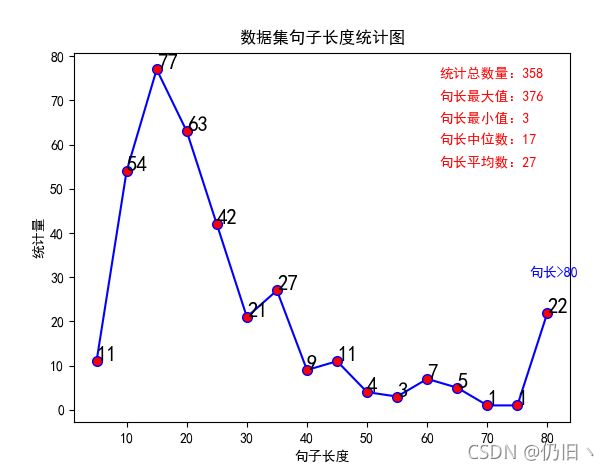
四、句长统计
在我们进行词嵌入以及需要设定的句子序列长短时,就要考虑文本数据的句子长度信息,这就使得对句子长短的统计显得更加重要。
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
data = pd.read_csv('data.csv', header=None)[0]
data_len = []
for j in data:
data_len.append(len(j))
print(data_len)
print('总句子数:', len(data))
print('最长句子:',np.max(data_len))
print('最小值:', np.min(data_len))
print('中位数:', int(np.median(data_len)))
print('平均值:', int(np.mean(data_len)))
data_list = {
5: 0, 10: 0, 15: 0, 20: 0, 25: 0, 30: 0, 35: 0, 40: 0,
45: 0, 50: 0, 55: 0, 60: 0, 65: 0, 70: 0, 75: 0,
80:0
}
for i in data:
if len(i) < 5:
data_list[5] += 1
elif len(i) < 10:
data_list[10] += 1
elif len(i) < 15:
data_list[15] += 1
elif len(i) < 20:
data_list[20] += 1
elif len(i) < 25:
data_list[25] += 1
elif len(i) < 30:
data_list[30] += 1
elif len(i) < 35:
data_list[35] += 1
elif len(i) < 40:
data_list[40] += 1
elif len(i) < 45:
data_list[45] += 1
elif len(i) < 50:
data_list[50] += 1
elif len(i) < 55:
data_list[55] += 1
elif len(i) < 60:
data_list[60] += 1
elif len(i) < 65:
data_list[65] += 1
elif len(i) < 70:
data_list[70] += 1
elif len(i) < 75:
data_list[75] += 1
elif len(i) > 75:
data_list[80] += 1
print(data_list)
x = []
y = []
for key, index in data_list.items():
x.append(key)
y.append(index)
print(x)
print(y)
plt.plot(x, y ,color='b', marker='o',
markerfacecolor='red', markersize=7)
plt.title("数据集句子长度统计图")
plt.xlabel('句子长度')
plt.ylabel('统计量')
# 设置数字标签
for a, b in data_list.items():
print(a, b)
plt.text(a, b, b, size=15)
plt.text(77, 30, '句长>80', size=10, color="b")
plt.text(62, 75, "统计总数量:%d" % len(data), size=10, color="r")
plt.text(62, 70, "句长最大值:%d" % np.max(data_len), size=10, color="r")
plt.text(62, 65, "句长最小值:%d" % np.min(data_len), size=10, color="r")
plt.text(62, 60, "句长中位数:%d" % int(np.median(data_len)), size=10, color="r")
plt.text(62, 55, "句长平均数:%d" % int(np.mean(data_len)), size=10, color="r")
plt.show()
总结
本文介绍了一些基础方法对文本数据预处理的方法,这些方法虽然简单但是很大程度上有利于后续我们对于情感分类的进行,以及神经网络的构建。其中有一些代码或者其他的可能是我借鉴其他大佬博主的,如有雷同十分抱歉!如果对您产生影响希望能告知我一下。谢谢!~ 。~