词频统计工程相关
(the format of this article is from SkYjoKEr)
//=======================开始干之前=======================
模块
1、WordClass 一个存放单词以及实现相关操作的类,其中单词以二元组<word, freq>的形式存储。 (20min)
2、WordCounter 完成单词统计,用一个List保存所有有效的单词。
3、在WordCounter里实现方法AddFile,对每添加的一个文件,提取出所有的单词,按规则加入到List中。(同2一起实现,3h)
4、quicksort实现一个双关键字的排序 (10min)
5、判断路径合法以及合法之后的文件名抽取,这部分不单独写成一个类(20min)
6、打印 (10min)
算上一些调试时间,预计花费5个小时完成这个小项目。
//=======================开始干之后=======================
写的时候模块顺序同设计时略有不同。
1、main函数。包括一个简单粗暴的命令行、有效路径判断及文件名抽取。实际使用了1hour,超出预计很多。问题出在抽取文件名,我一开始想使用GetFiles直接提取要求的四种格式的文件名,过滤掉其他格式。但是GetFiles方法里的参数好像不像正则表达式那么强大,它不能实现几种格式做或运算。后来上网一查,大家也说这个方法要么提取全部文件,要么提取一种格式的文件。最后我只能先把所有格式的文件都提出来,在调用addFile时做个判断。想通了这一点,实现起来倒是也不难。本来觉得还要写个文件夹里套文件夹的递归,GetFiles里有个searchoption.alldirectories参数,直接实现了,我只想说牛逼。
2、WordClass,正常时间完成。相关的操作包括构造函数,词频加1,get和set。
3、WordCounter和addFile。项目的核心和难点,需要实现写文件、分词、统计三大功能,写这个虽然用了4个小时,但我觉得自己的效率还算过得去。受到淡定大神的影响,我一开始打算用正则表达式实现分词,但是看了一会觉得这个难度不大适合我,最后老实的用StreamReader读一行,然后split分词。这两个工具在以前写C++大作业时用过,现在写起来算熟门熟路。为了辅助这三大功能,还写了两个小方法,legalWord判断单词是否合法,wordCompareEqual判断有没有相同的词出现(包括-e模式)。
4、双关键字快排,正常时间完成。
5、打印。先把所有内用缓冲到一个StreamBuilder里面,最后写到一个文件里。正常时间完成。
写完后调试也将近花了1个小时。写的时候不小心把legalWord的return都写成了false,运行的时候一个合法单词都没有,这个错误看了几遍都没看出来,最后还是调试调出来的。
最后用的总时间大概是7个小时。
//=======================提高性能=======================
感觉别的地方没什么可以优化的,要优化的话就是在判断是否出现重复的地方。因为我写的判断是O(n)的,借用树结构或者二分查找可以实现O(log n),Hash也能优化不少性能。可是我都没实现。
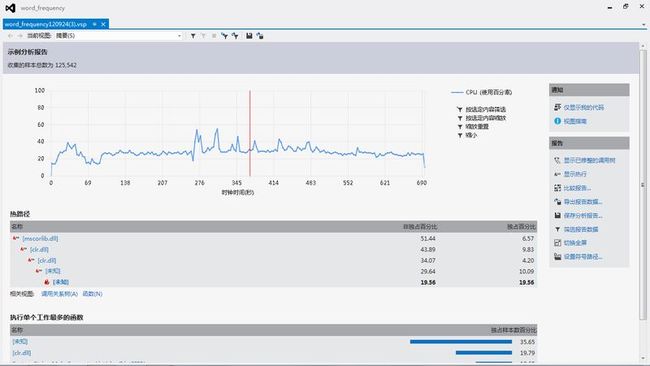
以I盘下的所有文件做测试。
优化前:
优化后:
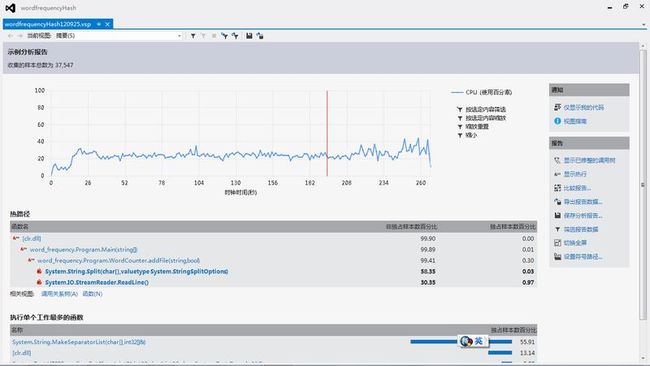
可以看到,用了HASH后,运行时间减少到1/3左右。
//=======================感想与总结=======================
C#的属性,真的很方便。
类的属性变量命名,用下划线打头,譬如词频用_freq,忽然感觉到自己可怜的词汇量够用了不少。
Split其实还是可以用用的,因为分隔符那里可以传进去一个分隔符数组。
文件操作相关的Directory和GetFiles,大爱。
VS2012按下F1就进去msdn了,这样比上网搜有效率多,久违的幸福感吗?……