Python面试题目汇总(2022年10月最新)
面试题目录-后续内容补充中
- Python基础
-
- Python 新式类和旧式类的区别
- Python 中` __init__ `和 `__new__` 方法的区别
- Python 中的单例模式解决了什么问题?如何实现
- Python 变量的作用域有哪些?作用范围分别是哪里
- Python 中的 GIL 锁
- Python 中迭代器和生成器的区别
- Python 如何实现线程通信和进程通信?
- 开发模式中的观察者模式是什么?
- 良好的 Python 开发模式是什么样的?
- 前后端出现数据不一致如何排查?
- git-flow 是什么?
- 进程、线程、协程的区别?底层的实现逻辑?
- 垃圾回收机制是什么?
- 如何解决循环引用的问题?
- Python 的自省/反射是什么?
- 数据库
-
- 数据库的优化方式有哪些?
- 如何查看 SQL 查询时间及具体的查询过程?
- 联表查询的优化方式有哪些?
- 生产当中出现死锁导致整个数据挂了怎么办?
- Token 和 Session 的优缺点?
- 如何实现不同网站的直接登录?A登录后直接登录B
- 千万级的大表如何优化?
- 如何测试数据库并发?
- Redis 中的 HGET、GET、HSET、SET的区别和使用场景?读写效率?
- 什么是可hash的值?
- 什么是二进制安全?
- 什么是时序数据
- 常用的时序数据数据库
- 常见的树结构及其优缺点?
- 数据库为什么不推荐使用外键
- 为什么建议使用 tinyint 代替 enum
- 什么是前缀索引
- 实战题
-
- 求学生的平均成绩及选课数量
- 后端相关
-
- 常见的爬虫绕过方法?
- 字段放在 headers 和 cookie 里有什么区别?
- 同源策略是什么?
- Flask 是多线程还是多进程?如何解决 Flask 中线程与协程的冲突?
- 容器化
-
- 1. Docker 和虚拟系统的差别
Python基础
Python 新式类和旧式类的区别
新式类的多态继承采用 C3 算法,旧式类采用深度优先算法
Python 中__init__和 __new__ 方法的区别
创建新类时先调用__new__方法进行实例化,随后调用__init__方法将对应的参数赋予新的实例。如果没有创建新类而是直接调用只会触发 __init__ 函数,同时 __new__ 方法会返回一个实例,而 __init__ 方法不会
Python 中的单例模式解决了什么问题?如何实现
Python 中的单例模式解决了在程序中重复创建实例的问题,例如一个日志类可能在多个程序中被实例化,导致在程序中出现多个类对象影响程序性能,通过单例模式可以避免性能占用,一般实现单例模式有两种方式,第一种通过更新 __new__ 方法来实现,代码片段如下:
# 创建单实例对象 Singleton
class Singleton():
def __new__(cls, *args, **kwargs):
if no hasattr(cls, '_instance'):
cls._instance = super(Singleton, cls).__new__(cls, *args, **kwargs)
return cls._instance
class A(Singlenton):
pass
>>> a = A()
>>> id(a)
1302990860592
>>> b = A()
>>> id(b)
1302990860592
>>> a==b
True
>>> a is b
True
还可以使用装饰器完成单实例对象,使用装饰器可以在不修改原代码的情况下增加函数功能,一般用于对函数输入的检查、日志等相关功能的拓展,实现代码如下:
def singelton(cls, *args, **kwargs):
instance = {}
def _singelton(*args, **kwargs):
if cls not in instance:
instance[cls] = cls(*args, **kwargs)
return instance[cls]
return _singelton
@singleton
class MyClass3(object):
pass
Python 变量的作用域有哪些?作用范围分别是哪里
函数作用范围可以用 LEGB 来概括:
- L表示函数内部作用域 logcal,指的是在某个函数内部的变量会第一个进行搜索。
- 查找不到的情况下会进入函数内部嵌套的函数enclosing 进行查询。
- 再查不到的情况下进入到全局作用域 global 进行查找。
- 若是在全局定义域中都无法查询到,进入到 Python 自带的内置作用域 build-in 中进行查询。
Python 中的 GIL 锁
为了确保线程的安全运行,在某个线程运行时会自动加锁,使得 CPU 只执行当前线程内的任务,Python 的多线程没有优势,一般通过多进程和协程来提高自身的处理速度。在一个进程中可能存在多个线程,通过切换线程来确保进程任务的执行,然而线程的切换也需要时间,且切换时间由系统自行控制,因此提出了协程的概念,由用户决定合适对其进行切换,yield 就是在协程的基础上提出的
Python 中迭代器和生成器的区别
生成器最早在 Python2 中就已经出现,通过 yield 关键字在程序执行时设置一个断点,并在断点处返回一个结果,程序通过 next() 在断点处继续执行到下一个断电或是程序返回处,本身是为了实现一个简约版的迭代器。
生成器是一种特殊的迭代器,使用 yield 返回结果,不需要手动实现__iter__方法和__next__方法,而迭代器需要实现__iter__ 方法返回迭代器对象本身,还需要实现 __next__ 方法,用于获取迭代器中的下一个值。
Python 如何实现线程通信和进程通信?
线程当中使用队列 Queue 进行通信,采用生产-消费者模式对队列内容进行监控,当队列为空时自动结束队列。进程间通信可以使用 multiprocessing.Manager,
开发模式中的观察者模式是什么?
当一个对象发生改变时,通知其他依赖该对象的其他对象。目的是解决一个对象发生状态改变时如何通知其他对象,并保证各个对象之间是松耦合。缺点是当一个对象有许多观察者时,通知到每一个观察者比较浪费资源,若是彼此之间存在循环引用可能导致崩溃,其次观察者模式只能告知状态发生改变,无法侦测改变的原因。示范代码如下:
# Observer Pattern
# create Observer
class Observer:
def update(self, temp, humidity, pressure):
pass
def display(self):
pass
# create Subject
class Subject:
def register_observer(self, observer):
return
def remove_observer(self, observer):
return
def notify_observer(self):
return
class WeatherData(Subject):
def __init__(self):
# use to save observer
self.observer = []
self.temperature = 0.0
self.humidity = 0.0
self.pressure = 0.0
return
def register_observer(self, observer):
self.observer.append(observer)
return
def remove_observer(self, observer):
self.observer.remove(observer)
return
def get_Humidity(self):
return self.humidity
def get_temperature(self):
return self.temperature
def get_pressure(self):
return self.pressure
def measurements_changed(self):
self.notify_observer()
return
def set_measuerment(self, temp, humidity, pressure):
self.temperature = temp
self.humidity = humidity
self.pressure = pressure
self.measurements_changed()
return
def notify_observer(self):
for item in self.observer:
item.update(self.temperature, self.humidity, self.pressure)
return
class CurrentConditionDisplay(Observer):
def __init__(self, weatherData):
self.weather_data = weatherData
self.temperature = 0.0
self.humidity = 0.0
self.pressure = 0.0
weatherData.register_observer(self)
return
def update(self, temp, humidity, pressure):
self.temperature = temp
self.humidity = humidity
self.pressure = pressure
self.display()
return
def display(self):
print("temprature = %f, humidity = %f" % (self.temperature, self.humidity))
return
class StatiticDisplay(Observer):
def __init__(self, WeatherData):
self.weather_data = WeatherData
self.temperature = 0.0
self.humidity = 0.0
self.pressure = 0.0
WeatherData.register_observer(self)
return
def update(self, temp, humidity, pressure):
self.temperature = temp
self.humidity = humidity
self.pressure = pressure
self.display()
return
def display(self):
print("Statictic = %f, pressuer = %f" % (self.temperature, self.pressure))
return
if __name__ == '__main__':
weather = WeatherData()
display = CurrentConditionDisplay(weather)
weather.set_measuerment(2.0, 3.0, 4.0)
display = StatiticDisplay(weather)
weather.set_measuerment(3.0, 4.0, 5.0)
良好的 Python 开发模式是什么样的?
编码风格遵守 PEP8,函数关键语句及定义下方使用注释表明代码作用,具备日志输出能力,具备异常处理能力可以保证出现异常程序可继续运行保留现场供后续分析,数据内容以日志或是本地化数据的形式进行保存,方便后续排查
前后端出现数据不一致如何排查?
观察日志文件和本地缓存文件,确定数据不一致发生的位置。例如通过前端控制台查看网络响应,判断后端数据是否出现问题,若无问题排查后端,通过断点、日志等方式确定数据不一致发生的问题。若是前端发生的问题则进入前端的脚本文件中排查。
git-flow 是什么?
git-flow 是通过脚本将开发流程进行规范化的工具,通过 master-develop两个分支实现生产环境和开发环境的切割,当测试通过后自动通过 release 进行版本发布,同时提供 hotfix 分支进行热修复。
进程、线程、协程的区别?底层的实现逻辑?
-
进程是 CPU 执行程序的单元,在一个 CPU 上同时只能执行一个进程,多进程的本质就是多个进程按照一定的规则轮流执行,进程由内存空间(空间内包含代码、数据、进程空间、打开的文件)和一个或多个线程组成。
-
在进程之中存在多个线程,多线程之间也会互相切换。一个标准的线程由线程ID、当前指令指针(PC)、寄存器和堆栈组成。
进程是 CPU 可以操作系统分配的最小单位,线程是程序自身可以控制的最小单位。其中线程切换的开销远小于进程切换。进程彼此之间相互独立,而同一个进程下的不同线程可以同享进程空间。
垃圾回收机制是什么?
Python 当中主要采用引用计数的方式进行垃圾回收,每当一个内存地址被引用时则增加一个引用计数,当引用计数为 0 时回收该内存。
引用计数存在循环引用的问题,因此增加了分代回收及垃圾回收机制进行辅助。当用户创建一个对象时放入一个新的链表,当用户创建的对象充满第一个链表时,通过垃圾回收机制对链表进行检查,随后将链表上最老的对象移至第二个链表上,这样的链表共有 3 个,以此实现分代回收机制。
垃圾回收机制依靠 Pyhton 提供的 gc 模块实现,消除程序中的不可达对象。
如何解决循环引用的问题?
Python 中引用某个包时,若是第一次引用该包则会执行 __init__.py中的代码,同时执行导入模块的顶层代码(全局变量、导入等),循环引用问题往往都是在这部分发生的。
解决方案:
- 直接导入模块,通过
module.function的形式对函数进行调用 - 使用延迟导入,在函数中或是底部进行导入
- 重新设计代码结构,使用统一的入口对模块进行导入和引用
Python 的自省/反射是什么?
在编码时有时一些属性的名称需要用户或是在实例化时才能确定,可以通过字符串对实例化后的对象进行属性和方法的添加,这种行为称为自省/反射。
反射是通过字符串直接对类中的函数进行操作的一种行为,在程序中我们通过直接调用函数名的方式来调用函数,当用户输入一个字符串时,可以使用getattr(classers, function_name)函数来对类中的函数进行查找,返回值即是该类的函数,可以直接进行使用。在使用前可以配合hasattr(classes, function_name)来判断一个类当中是否存在对应名称的方法。
数据库
数据库的优化方式有哪些?
-
使用 join 代替子查询进行查找,join 通过将两张表进行笛卡尔积,通过某个特定列的值来连接两张表的数据,常见的查询算法有Inner Join,Left Outer Join和Right Outer Join
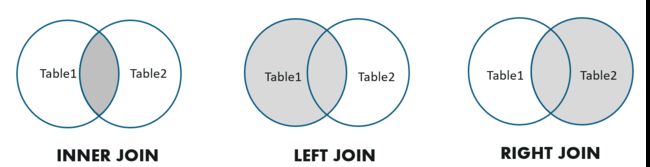
Nested-Loop Join 是最原始的查询方式,将两张表中数量较小的表缓存到内存中,并针对外表的每一行数据进行查询,满足查询条件后输入,效率最低一般在表数量不大或是 join 条件不含等值的情况下使用。
Hash Join 是常见的查询方式,拉取较小的表的全部数据写入哈希表中,遍历外表的每行数据使用等值条件 JOIN KEY 在哈希表中进行查询,取出 0-N 匹配的行,构造结果行后与查询条件进行对比,输出结果。
Lookup Join是另一种等值 JOIN 算法,遍历较小的表根据数量
如何查看 SQL 查询时间及具体的查询过程?
通过 EXPLAIN 查询本次 SQL 查询的过程和时间,需要关注 ROWS 和临时表的创建,分别是查询的行数和创建的临时表数量,尽量减少查询的行数和创建的临时表数量。
| 字段名 | 用处 |
|---|---|
| table | 显示的数据关于哪张表 |
| type | 重要的列及类型(由好到差const, eq_reg, ref,range,indexhe,all) |
| possible_keys | 可能应用在表中的索引,为空则没有可用的索引 |
| key | 实际使用的索引 |
| key_len | 使用的索引长度,越短越好 |
| ref | 显示索引的哪一列被使用了 |
| rows | 本次查询必须检查的行数 |
| extra | 关于本次查询额外的操作信息 |
联表查询的优化方式有哪些?
解决方案:
- 增加索引:主键索引、普通索引、唯一索引、全文索引、聚合索引(多列索引)
- 避免子查询,使用 join 代替
- 避免在 where 语句中对字段进行 null 判断,否则会放弃索引使用全表扫描
- 避免使用 in 和 not in,这两个关键字也会导致全表扫描,可以使用 exists 代替 in
- 尽量使用数字型而不是字符型
- 避免使用模糊查询
- 避免使用 or 作为连接条件,可以使用 union all 代替
生产当中出现死锁导致整个数据挂了怎么办?
- 通过重启服务或使用备用数据库的方式优先恢复生产运行
- 通过日志查看死锁原因
- 对死锁的现场进行断点调试,并检查触发代码
Token 和 Session 的优缺点?
Token 用于弥补 HTTP 协议无状态登录的一种方法,当用户登录后通过服务器使用密钥进行加密签名得到一个 JSON 字符串,用户在发送请求时一同发送该字符串,服务器对其进行验证后可以直接判断其登录状态,可以解决用户在不同域名下跨域登录的问题。优点在于 Token 信息保存在客户端上,可以节约服务器资源
Session 也是用于弥补 HTTP 协议无状态登陆的方法,当用户登陆后在服务器端保存用户的相关信息进入 Session 库中,返回对应的 session ID,当用户访问内容时服务器对 Session ID 进行检索,确认用户身份。
token 在客户端可能被人分析出相关的数据导致进行欺骗,session 避免了这个问题。
如何实现不同网站的直接登录?A登录后直接登录B
使用 JWT ,利用自签名的方式来验证用户的登录信息是否有效。
千万级的大表如何优化?
先确定千万级大表中的数据属于哪种数据:
- 流水型数据,例如交易流水,支付流水,主要业务内容为插入。业务拆分改为分布式存储
- 状态型数据,业务上主要为查询和修改,并对数据的准确性有要求,如余额、状态。尽量不拆分,进行水平扩展
- 配置型数据,如系统配置、路径、权限点等。
针对业务场景进行优化,将混合业务拆分为独立业务,将状态数据和历史数据进行拆分,数据可以根据日期、分区等方式进行拆分并以表名的形式进行重命名。
针对读多写少的场景可以采用缓存、内存式数据库的方式降低数据库压力,对于读少写多的场景可以采用异步提交、队列写入等方式降低写入频率。水平扩展上增加中间件、读写分离、负载均衡等方式提高数据库可用性。
代码上对事务的使用进行规范避免滥用,优化 SQL 查询语句提高查询效率,增加索引。
运维上定期清理数据,切分冷热数据。
如何测试数据库并发?
Redis 中的 HGET、GET、HSET、SET的区别和使用场景?读写效率?
Reids 为常见的数据提供了 5 种类型的数据:
- 字符串 string
- 哈希散列 hash,通常用于存储键值对信息
- 列表 list ,可以存储字符串,允许重复插入,最多可以插入2^32-1个,可以添加在列表开头或是结尾
- 集合 set,集合是无序的,通过 hash 映射表实现,增删改查时间复杂度都为 O(1)
- 有序集合 set,字符串元素组成的集合,每个元素关联一个 double 类型的分数,该分数允许重复,通过该分数进行排序
- 位图 bitmaps,通过类似 map 结构存放 0 或 1作为值,通常用于统计状态
- 基数统计 HyperLogLogs,接受多个元素作为输入,并计算元素的基数
对于这些数据类型有不同的操作进行存储和读取
| 数据类型 | 读操作 | 写操作 |
|---|---|---|
| string | get foo | set foo “this is simple" |
| String(批量操作) | Mget foo foo1 | Meet foo “1” foo1 “2” |
| hash | hget dict:1 | Set dict:1 “123” |
| hash(批量操作) | Hgetall user:1 | Hmset user:1 “23” “45” |
| list | LRANGE user 0 1 | LPUSH user tom |
| set | SMEMBERS user | SADD user tom |
| zset | zrange user 0 10 | zadd user 0 tom |
| bitmaps | SETBIT user:0001 10003 1 | |
| HyperLogLog | PFADD user tom |
什么是可hash的值?
不可变的数据结构如字符串、元组等,可以将大体量的数据转为较小的数据,方便我们在一个固定的复杂度下对其进行查询。
什么是二进制安全?
在存储字符串时往往采用二进制进行存储,然而在某些语言当中需要对字符串的结尾或是开头进行判断,导致某个字符串输入后返回的结果不符合预期。二进制安全的情况下,应该不对输入的字符串数据做任何特殊处理,字符串的长度是已知的,不受其他终止符影响。
什么是时序数据
时序数据就是以时间为索引的数据,具有写入平稳持续,高并发高吞吐的特性,自身写多读少,大部分情况下只有数据写入,极少数情况下人为进行修改。同时时序数据的冷热数据区分较大,大部分人关心近期一段的时序数据,对于早期的数据很少进行读写,同时随着监控的时间间隔越短,产生的数据量越大
常用的时序数据数据库
时序数据库本身要能支撑高并发高吞吐的写入,同时支持在 TB 级甚至更高级别的数据量下进行交互查询,并且自身能够支持该体量的数据存储。一般采用使用 LSM 树存储的 NoSQL 数据库,例如HBase,Cassandra,TableStore等。
常见的树结构及其优缺点?
树的度取决于其中链接结点最多的结点数量,深度指的是树从根节点到最远的一个叶子结点中间的层数。左右结点可以交换的树称为无序树反之为有序树,二叉树就是结点的度为2的树。
线性结构在插入和读取时都会话费大量的时间,一般情况下都采用树状结构进行存储,目前主流的动态查找树有:二叉查找树、平衡二叉树、红黑树、B树及 B+ 树。前三种树的查询复杂度与树的深度有关,一般采用后两种即平衡多路查找树。
二叉搜索树的特点:
- 若该树的左子树不为空,则左子树上所有节点值小于其根节点
- 若该树的右子树不为空,则右子树上所有节点值大于其根节点
- 该树的左右子树也是二叉搜索树
二叉树节点的命名:
- 没有父结点的称为根结点,二叉树仅有一个根结点
- 有父结点的称为子结点,拥有共同父结点的子结点间互为兄弟结点
- 没有子结点的称为叶子结点,二叉树可以有多个叶子结点
二叉树的数学特性:
- 二叉树中第i层的最多有2(i-1)个结点,深度为k的二叉树最多有2k-1个结点
- 二叉树中若叶子结点数量为n0,度为 2 的结点数量为n2,则n0=n2+1
数据库为什么不推荐使用外键
外键用于约束和检查数据库表之间的关系,在插入数据时会对外键连接的表进行检查,确保不会插入脏数据,删除时也会采用级联删除的方式将无效数据删除,可以保证数据的可靠性和准确性。
在生产环境中这些特性会带来一定的麻烦:
- 每次插入数据时需要对其他表进行检查,影响效率
- 每次删除数据时会引发其他数据删除,可能因数据量造成数据大量删除导致崩溃
- 插入数据时会锁定对应的外键表中的行,影响其他业务进行
- 数据库结构被限制,难以分库分表
为什么建议使用 tinyint 代替 enum
tinyint 可以通过数字来表示内容,enum 作为枚举值既可以通过值进行查询,也可以通过枚举值的索引进行查询,例如:
enum = {'a','b','c'}
select * from tbl_name whre enum = 2
select * from tbl_name where enum = 'b'
二者是等价的,当使用 insert into 进行插入时,若 enmu 设计为数字,则可能出现本来想插入数字却变成插入枚举值的索引,同时在 enum 中新增枚举值时,若不是在最后进行添加而是添加在其中的某一个位置时,会导致其他地方的记录出现混乱,最后 enmu 是 MySQL 的特色字段,在其他数据库中不被支持,影响数据的导入与导出。
什么是前缀索引
对文本和字符串类型进行前缀索引,适用于前缀差别比较大的文本,缩小索引长度
ALTER TABLE table_name ADD KEY(column_name(prefix_length))
实战题
求学生的平均成绩及选课数量
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wy8GYap8-1666748452406)(/Users/tomjerry/Library/Application%20Support/typora-user-images/image-20221022215437619.png)]
已知:S为学号,sc表为学生对应每科成绩记录
问题1:编写一条 SQL 语句求出每个学生的学号及平均成绩,并显示平均成绩 90 分以上的记录
select S, avg(score)
from sc
group by S
having avg(score) > 90
问题2:编写一条SQL语句求出学生的学号、姓名、选课数和总成绩
select t1.S, t1.Sname, count(t2.C), sum(t2.score)
from student t1
inner join sc t2
on t1.S = t2.S
group by t1.S
后端相关
常见的爬虫绕过方法?
| 反爬措施 | 解决方案 |
|---|---|
| 检测 IP 来源 | 使用 IP 代理 |
| 验证码 | 图像识别、打码平台 |
| 加密参数 | JS 逆向 |
| 浏览器头校验 | user-agent 伪装 |
| 来源校验 | 增加 refer 头 |
| 登陆查看 | 模拟登陆、cookie伪装 |
| 限制单个用户访问次数 | 多线程 |
| JS 反调试 | 打断点绕过 |
字段放在 headers 和 cookie 里有什么区别?
cookie 只会在同域名访问时增加在请求头当中,headers 则会在所有域名的请求当中携带该字段。
同源策略是什么?
根据同协议、同 IP、同端口的要求进行访问,不允许其他页面访问当前页面的资源。
Flask 是多线程还是多进程?如何解决 Flask 中线程与协程的冲突?
默认的开发 web 服务器可以进行自定义,默认为单进程单线程,threadad = Ture 开启多线程,processes=2开启多进程。
线程中的协程会共享线程资源,因此需要对其进行改造
容器化
1. Docker 和虚拟系统的差别
虚拟系统是在宿主机上创建虚拟层,通过虚拟化的操作系统安装应用。使用 Docker 时通过宿主系统创建 Docker 引擎,并在此基础上安装应用。因此可以实现秒级启动,更小的资源占用,可以通过 Dockerfile 创建配置文件实现自动化创建即部署。
在容器直接通过命名空间将不同容器进行隔离