hugging face 模型库的使用及加载 Bert 预训练模型
一、hugging face 模型库
Hugging face 是一个专注于 NLP 的公司,拥有一个开源的预训练模型库 Transformers ,里面囊括了非常多的模型例如 BERT、GPT、GPT2、ToBERTa、T5 等。
官网的模型库的地址如下:Hugging face 模型库官网
Hugging face 提供的 transformers 库主要用于预训练模型的载入,需要载入三个基本对象:
from transformers import BertConfig
from transformers import BertModel
from transformers import BertTokenizer
(1)BertConfig
是该库中模型配置的 class:控制模型的名称、最终输出的样式、隐藏层宽度和深度、激活函数的类别等。将Config类导出时文件格式为 json 格式。格式如下:

当然,也可以通过 config.json 来实例化 Config 类,这是一个互逆的过程。
(2)Model
也就是各种各样的模型:除了初始的 Bert、GPT 等基本模型,针对下游任务,还有其它的继承 BertPreTrainedModel 的派生类,对应不同的 Bert 任务,定义了 BertForQuestionAnswering、BertForNextSentencePrediction 以及 BertForSequenceClassification 等下游任务模型。模型导出时将生成 config.json 和 pytorch_model.bin 参数文件。前者就是 1 中的配置文件,这和我们的直觉相同,即 config 和 model 应该是紧密联系在一起的两个类。后者其实和 torch.save() 存储得到的文件是相同的,这是因为 Model 都直接或者间接继承了 Pytorch 的 Module 类。从这里可以看出,HuggingFace 在实现时很好地尊重了 Pytorch 的原生 API。
(3)Tokenizer
这是一个将纯文本转换为编码的过程。注意,Tokenizer 并不涉及将词转化为词向量的过程,仅仅是将纯文本分词,添加[MASK]标记、[SEP]、[CLS]标记,并转换为字典索引。Tokenizer 类导出时将分为三个文件,也就是:

利用分词器进行编码:
模型的所有分词器都是在 PreTrainedTokenizer 中实现的,分词的结果主要有以下内容:{
input_ids: list[int],
token_type_ids: list[int] if return_token_type_ids is True (default)
attention_mask: list[int] if return_attention_mask is True (default)
overflowing_tokens: list[int] if a max_length is specified and return_overflowing_tokens is True
num_truncated_tokens: int if a max_length is specified and return_overflowing_tokens is True
special_tokens_mask: list[int] if add_special_tokens if set to True and return_special_tokens_mask is True
}

二、Bert 模型
BERT 模型的全称是:BidirectionalEncoder Representations from Transformer。从名字中可以看出,BERT 模型的目标是利用大规模无标注语料训练、获得文本的包含丰富语义信息的 Representation,即:文本的语义表示,然后将文本的语义表示在特定NLP任务中作微调,最终应用于该NLP任务。煮个栗子,BERT模型训练文本语义表示的过程就好比我们在高中阶段学习语数英、物化生等各门基础学科,夯实基础知识;而模型在特定NLP任务中的参数微调就相当于我们在大学期间基于已有基础知识、针对所选专业作进一步强化,从而获得能够应用于实际场景的专业技能。
1、模型结构
BERT 模型是基于 Transformer 的Encoder,主要模型结构就是Transformer的堆叠。
当我们组建好Bert模型之后,只要把对应的token喂给BERT,每一层Transformer层吐出相应数量的hidden vector,一层层传递下去,直到最后输出。模型就这么简单,专治花里胡哨,这大概就是谷歌的暴力美学。
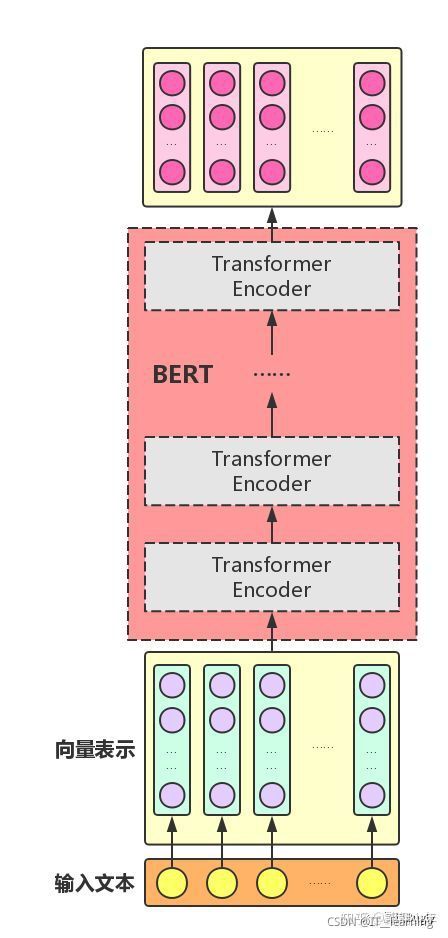
BERT模型的全称是:BidirectionalEncoder Representations from Transformer,也就是说,Transformer是组成BERT的核心模块,而Attention机制又是Transformer中最关键的部分
(1)Attention
Attention机制的中文名叫“注意力机制”,顾名思义,它的主要作用是让神经网络把“注意力”放在一部分输入上,即:区分输入的不同部分对输出的影响。这里,我们从增强字/词的语义表示这一角度来理解一下Attention机制。
我们知道,一个字/词在一篇文本中表达的意思通常与它的上下文有关。比如:光看“鹄”字,我们可能会觉得很陌生(甚至连读音是什么都不记得吧),而看到它的上下文“鸿鹄之志”后,就对它立马熟悉了起来。因此,字/词的上下文信息有助于增强其语义表示。同时,上下文中的不同字/词对增强语义表示所起的作用往往不同。比如在上面这个例子中,“鸿”字对理解“鹄”字的作用最大,而“之”字的作用则相对较小。为了有区分地利用上下文字信息增强目标字的语义表示,就可以用到Attention机制。
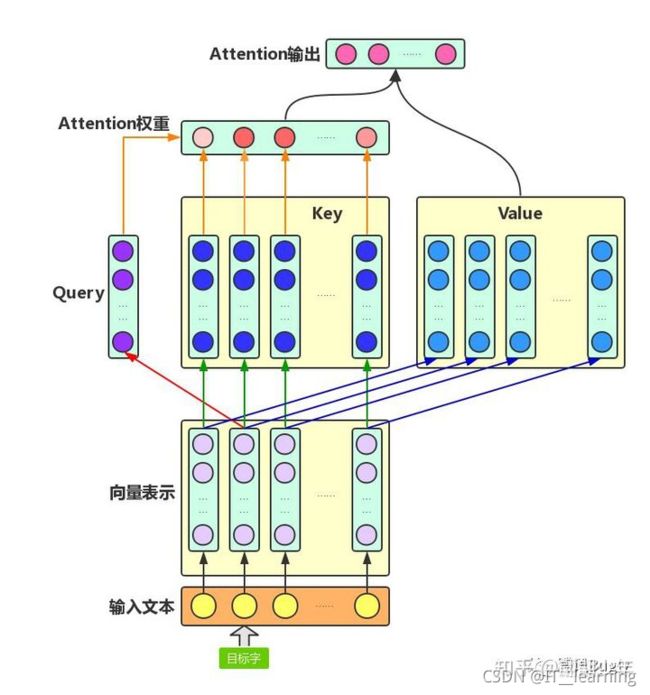
Attention机制主要涉及到三个概念:Query、Key和Value。在上面增强字的语义表示这个应用场景中,目标字及其上下文的字都有各自的原始Value,Attention机制将目标字作为Query、其上下文的各个字作为Key,并将Query与各个Key的相似性作为权重,把上下文各个字的Value融入目标字的原始Value中。如下图所示,Attention机制将目标字和上下文各个字的语义向量表示作为输入,首先通过线性变换获得目标字的Query向量表示、上下文各个字的Key向量表示以及目标字与上下文各个字的原始Value表示,然后计算Query向量与各个Key向量的相似度作为权重,加权融合目标字的Value向量和各个上下文字的Value向量,作为Attention的输出,即:目标字的增强语义向量表示。
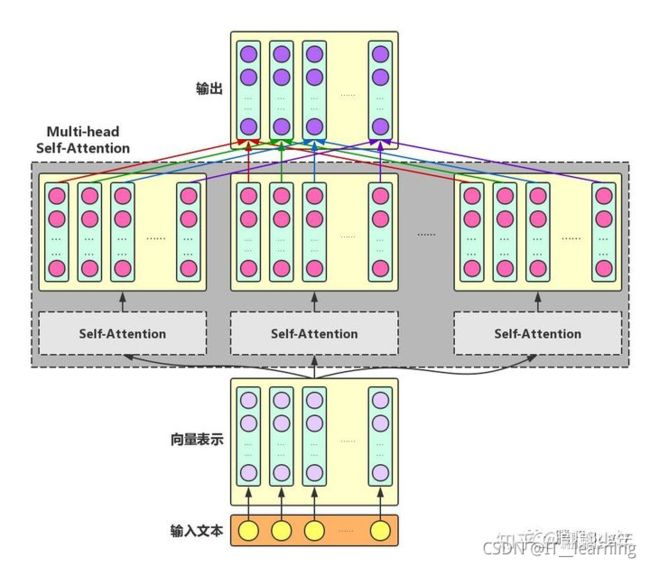
1)Self-Attention:对于输入文本,我们需要对其中的每个字分别增强语义向量表示,因此,我们分别将每个字作为Query,加权融合文本中所有字的语义信息,得到各个字的增强语义向量,如下图所示。在这种情况下,Query、Key和Value的向量表示均来自于同一输入文本,因此,该Attention机制也叫Self-Attention。

2)Multi-head Self-Attention:为了增强Attention的多样性,文章作者进一步利用不同的Self-Attention模块获得文本中每个字在不同语义空间下的增强语义向量,并将每个字的多个增强语义向量进行线性组合,从而获得一个最终的与原始字向量长度相同的增强语义向量,如下图所示。
(2)Transformer Encoder
在Multi-headSelf-Attention的基础上再添加一些“佐料”,就构成了大名鼎鼎的Transformer Encoder。实际上,Transformer模型还包含一个Decoder模块用于生成文本,但由于BERT模型中并未使用到Decoder模块,因此这里对其不作详述。下图展示了Transformer Encoder的内部结构,可以看到,Transformer Encoder在Multi-head Self-Attention之上又添加了三种关键操作:1)残差连接(ResidualConnection):将模块的输入与输出直接相加,作为最后的输出。这种操作背后的一个基本考虑是:修改输入比重构整个输出更容易(“锦上添花”比“雪中送炭”容易多了!)。这样一来,可以使网络更容易训练。
2)Layer Normalization:对某一层神经网络节点作0均值1方差的标准化。3)线性转换:对每个字的增强语义向量再做两次线性变换,以增强整个模型的表达能力。这里,变换后的向量与原向量保持长度相同。
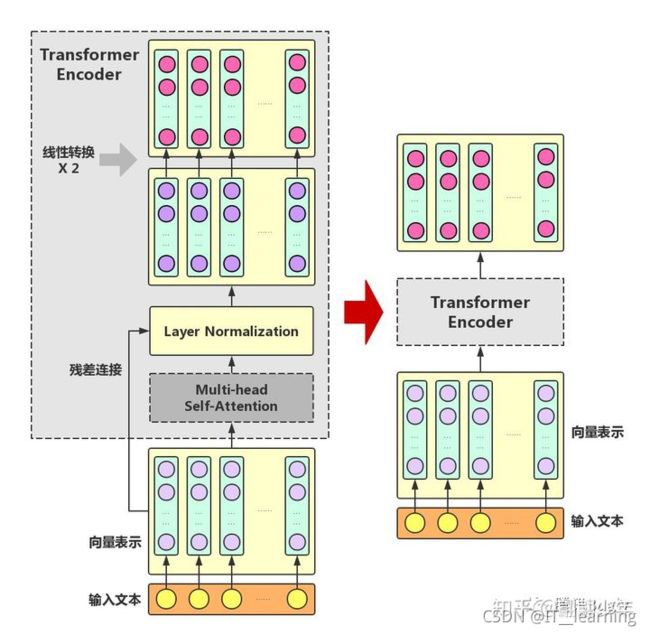
可以看到,Transformer Encoder的输入和输出在形式上还是完全相同,因此,Transformer Encoder同样可以表示为将输入文本中各个字的语义向量转换为相同长度的增强语义向量的一个黑盒。
组装好TransformerEncoder之后,再把多个Transformer Encoder一层一层地堆叠起来,BERT模型就大功告成了!
2、模型的输入/输出
在基于深度神经网络的NLP方法中,文本中的字/词通常都用一维向量来表示(一般称之为“词向量”);在此基础上,神经网络会将文本中各个字或词的一维词向量作为输入,经过一系列复杂的转换后,输出一个一维词向量作为文本的语义表示。特别地,我们通常希望语义相近的字/词在特征向量空间上的距离也比较接近,如此一来,由字/词向量转换而来的文本向量也能够包含更为准确的语义信息。因此,BERT模型的主要输入是文本中各个字/词的原始词向量,该向量既可以随机初始化,也可以利用Word2Vector等算法进行预训练以作为初始值;输出是文本中各个字/词融合了全文语义信息后的向量表示,如下图所示(为方便描述且与BERT模型的当前中文版本保持一致,本文统一以字向量作为输入):
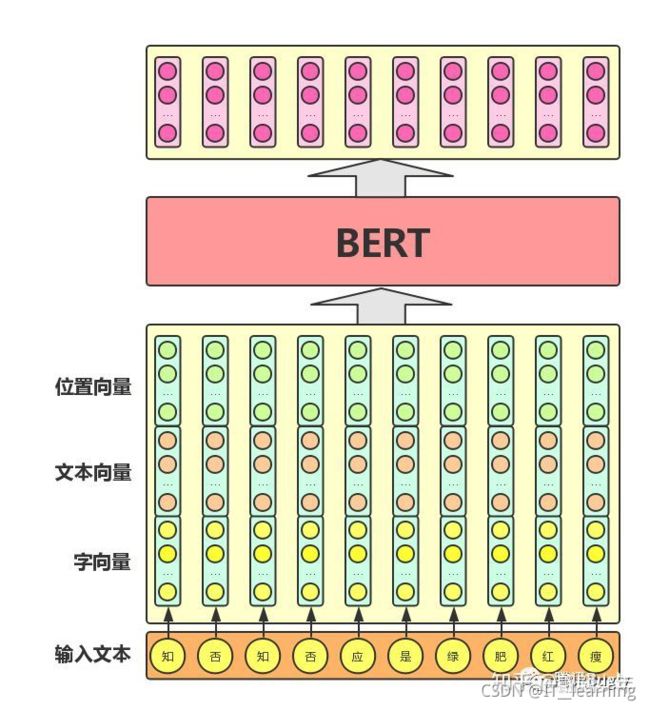
从上图中可以看出,BERT 模型通过查询字向量表将文本中的每个字转换为一维向量,作为模型输入;模型输出则是输入各字对应的融合全文语义信息后的向量表示。此外,模型输入除了字向量,还包含另外两个部分:1)文本向量,该向量的取值在模型训练过程中自动学习,用于刻画文本的全局语义信息,并与单字/词的语义信息相融合;2)位置向量,由于出现在文本不同位置的字/词所携带的语义信息存在差异(比如:“我爱你”和“你爱我”),因此,BERT模型对不同位置的字/词分别附加一个不同的向量以作区分。最后,BERT模型将字向量、文本向量和位置向量的加和作为模型输入。
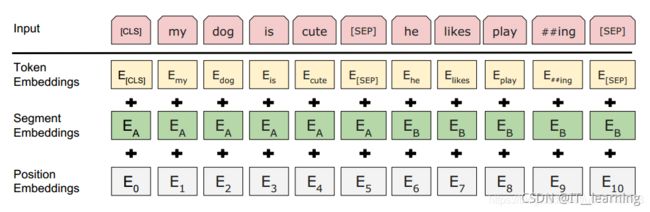
在BERT中,输入的向量是由三种不同的embedding求和而成,分别是:
1)wordpiece embedding:单词本身的向量表示。WordPiece是指将单词划分成一组有限的公共子词单元,能在单词的有效性和字符的灵活性之间取得一个折中的平衡。
2)position embedding:将单词的位置信息编码成特征向量。因为我们的网络结构没有RNN 或者LSTM,因此我们无法得到序列的位置信息,所以需要构建一个position embedding。构建position embedding有两种方法:BERT是初始化一个position embedding,然后通过训练将其学出来;而Transformer是通过制定规则来构建一个position embedding
3)segment embedding:用于区分两个句子的向量表示。这个在问答等非对称句子中是用区别的。BERT模型的输入就是wordpiece token embedding + segment embedding + position embedding,如图所示:
三、从模型库导入 Bert 预训练模型
1、通过官网自动导入
该方式通过 hugging face 官网自动导入(此方法需要外网连接),这个方法需要从官方的 s3 数据库下载模型配置、参数等信息(代码中已配置好位置)。
首先需要安装 transformers 库,使用以下命令安装:
pip install transformers
然后导入预训练模型
from transformers import BertTokenizer,BertModel
model_name = 'hfl/chinese-roberta-wwm-ext'
config = BertConfig.from_pretrained(model_name) # 这个方法会自动从官方的s3数据库下载模型配置、参数等信息(代码中已配置好位置)
tokenizer = BertTokenizer.from_pretrained(model_name) # 这个方法会自动从官方的s3数据库读取文件下的vocab.txt文件
model = BertModel.from_pretrained(model_name) # 这个方法会自动从官方的s3数据库下载模型信息
运行后系统会自动下载相关的模型文件并存放在电脑中。
1)使用 Windows 模型保存的路径在 C:\Users[用户名].cache\torch\transformers\ 目录下,根据模型的不同下载的东西也不相同
2)使用 Linux 模型保存的路径在 ~/.cache/torch/transformers/ 目录下
至此,预训练模型和分词工具已经载入完成,下面是一个简单的实例。
s_a, s_b = "李白拿了个锤子", "锤子?"
# 分词是tokenizer.tokenize, 分词并转化为id是tokenier.encode
# 简单调用一下, 不作任何处理经过transformer
input_id = tokenizer.encode(s_a)
input_id = torch.tensor([input_id]) # 输入数据是tensor且batch形式的
sequence_output, pooled_output = model(input_id) # 输出形状分别是[1, 9, 768], [1, 768]
# 但是输入BertModel的还需要指示前后句子的信息的token type, 以及遮掉PAD部分的attention mask
inputs = tokenizer.encode_plus(s_a, text_pair=s_b, return_tensors="pt") # 还有些常用的可选参数max_length, pad_to_max_length等
print(inputs.keys()) # 返回的是一个包含id, mask信息的字典
# dict_keys(['input_ids', 'token_type_ids', 'attention_mask']
sequence_output, pooled_output = model(**inputs)
2、下载到本地再导入
该方法总体是将所需要的预训练模型、词典等文件下载至本地文件夹中 ,然后加载的时候 model_name_or_path 参数指向文件的路径即可。
(1)下载模型文件
在 hugging face 模型库 https://huggingface.co/models 里选择需要的预训练模型并下载。例如,点击手动下载 hfl/chinese-roberta-wwm-ext 模型。
如下图,可以看到模型的所有文件:
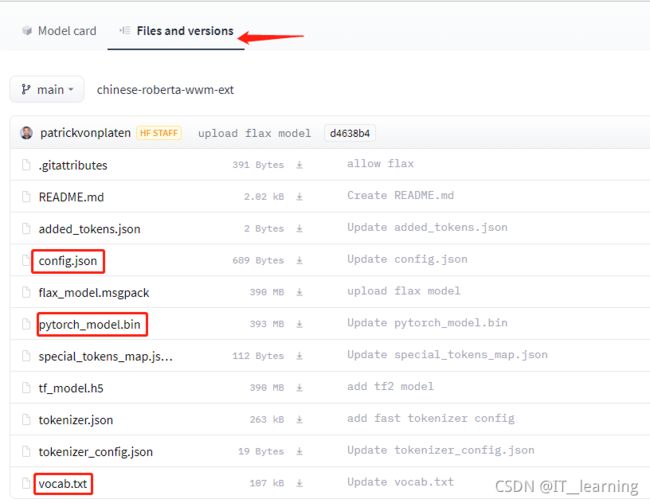
通常我们需要保存的是三个文件及一些额外的文件,第一个是配置文件;config.json。第二个是词典文件,vocab.json。第三个是预训练模型文件,如果你使用pytorch则保存pytorch_model.bin文件,如果你使用tensorflow 2,则保存tf_model.h5。
额外的文件,指的是merges.txt、special_tokens_map.json、added_tokens.json、tokenizer_config.json、sentencepiece.bpe.model等,这几类是tokenizer需要使用的文件,如果出现的话,也需要保存下来。没有的话,就不必在意。如果不确定哪些需要下,哪些不需要的话,可以把图1中类似的文件全部下载下来。
下载必须的三个文件(config.json、pytorch_model.bin、vocab.txt)以及额外的文件保存到自己新建的一个文件夹下面(注意:这些文件名称注意必须要完全一致,不可修改)。
(2)使用本地下载的模型文件
huggingface 的 transformers 框架主要有三个类model类、config类、tokenizer类,这三个类,所有相关的类都衍生自这三个类,他们都有 from_pretained() 方法和 save_pretrained() 方法。
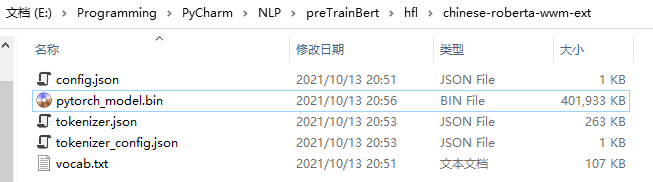
本例将 config.json、pytorch_model.bin、vocab.txt 以及 tokenizer 相关文件全部下载下来,文件如下:
1)from_pretrained 方法的第一个参数都是 pretrained_model_name_or_path,这个参数设置为我们下载的文件目录即可。
from transformers import BertConfig,BertTokenizer
model_name = 'E:\Programming\PyCharm\NLP\preTrainBert\hfl\chinese-roberta-wwm-ext'
tokenizer = BertTokenizer.from_pretrained(model_name) # 通过词典导入分词器
model_config = BertConfig.from_pretrained(model_name) # 导入配置文件
model = BertModel.from_pretrained(model_name, config=model_config)
2)利用分词器进行编码:
# encode仅返回input_ids
tokenizer.encode("我爱你")
Out : [101, 2769, 4263, 872, 102]
# encode_plus返回所有编码信息
input_id = tokenizer.encode_plus("我爱你", "你也爱我")
Out :
{'input_ids': [101, 2769, 4263, 872, 102, 872, 738, 4263, 2769, 102],
'token_type_ids': [0, 0, 0, 0, 0, 1, 1, 1, 1, 1],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
3)将分词结果输入模型,得到编码:
# 添加batch维度并转化为tensor
input_ids = torch.tensor(input_id['input_ids'])
token_type_ids = torch.tensor(input_id['token_type_ids'])
attention_mask_ids=torch.tensor(input_id['attention_mask'])
# 将模型转化为eval模式
model.eval()
# 将模型和数据转移到cuda, 若无cuda,可更换为cpu
device = 'cuda'
tokens_tensor = input_ids.to(device).unsqueeze(0)
segments_tensors = token_type_ids.to(device).unsqueeze(0)
attention_mask_ids_tensors = attention_mask_ids.to(device).unsqueeze(0)
model.to(device)
# 进行编码
with torch.no_grad():
# See the models docstrings for the detail of the inputs
outputs = model(tokens_tensor, segments_tensors, attention_mask_ids_tensors)
# Transformers models always output tuples.
# See the models docstrings for the detail of all the outputs
# In our case, the first element is the hidden state of the last layer of the Bert model
encoded_layers = outputs
# 得到最终的编码结果encoded_layers
4)Bert 最终输出的结果为:
sequence_output, pooled_output, (hidden_states), (attentions)
bert 的输出是由四部分组成:
(1)last_hidden_state:shape是(batch_size, sequence_length, hidden_size),hidden_size=768,它是模型最后一层输出的隐藏状态。(通常用于命名实体识别)
(2)pooler_output:shape是(batch_size, hidden_size),这是序列的第一个token(classification token)的最后一层的隐藏状态,它是由线性层和Tanh激活函数进一步处理的。(通常用于句子分类,至于是使用这个表示,还是使用整个输入序列的隐藏状态序列的平均化或池化,视情况而定)
(3)hidden_states:这是输出的一个可选项,如果输出,需要指定config.output_hidden_states=True,它也是一个元组,它的第一个元素是embedding,其余元素是各层的输出,每个元素的形状是(batch_size, sequence_length, hidden_size)
(4)attentions:这也是输出的一个可选项,如果输出,需要指定config.output_attentions=True,它也是一个元组,它的元素是每一层的注意力权重,用于计算self-attention heads的加权平均值。
以输入序列长度为 14 为例:
