动手强化学习(九):策略梯度算法
动手强化学习(七):DQN 改进算法——Dueling DQN
- 1. 简介
- 2. 策略梯度
- 3. REINFORCE
- 4. REINFORCE 代码实践
- 5. 小结
- 6. 扩展:策略梯度证明
文章转于 伯禹学习平台-动手学强化学习 (强推)
本文所有代码均可在jupyter notebook运行
与君共勉,一起学习。
1. 简介
之前介绍的 Q-learning、DQN 及 DQN 改进算法都是基于价值(value-based)的方法,其中 Q-learning 是处理有限状态的算法,而 DQN 可以用来解决连续状态的问题。在强化学习中,除了基于值函数的方法,还有一支非常经典的方法,那就是基于策略(policy-based)的方法。对比两者,基于值函数的方法主要是学习值函数,然后根据值函数导出一个策略,学习过程中并不存在一个显式的策略;而基于策略的方法则是直接显式地学习一个目标策略。策略梯度是基于策略的方法的基础,本章从策略梯度算法说起。
2. 策略梯度
基于策略的方法首先需要将策略参数化。假设目标策略 π θ \pi_{\theta} πθ 是一个随机性策略,并且处处可微,其中 θ {\theta} θ是对应的参数。我们可以用一个线性模型或者神经网络模型来为这样一个策略函数建模,输入某个状态,然后输出一个动作的概率分布。我们的目标是要寻找一个最优策略并最大化这个策略在环境中的期望回报。我们将策略学习的目标函数定义为
J ( θ ) = E s 0 [ V π θ ( s 0 ) ] J(\theta)=\mathbb{E}_{s_{0}}\left[V^{\pi_{\theta}}\left(s_{0}\right)\right] J(θ)=Es0[Vπθ(s0)]
其中, s 0 s_{0} s0 表示初始状态。现在有了目标函数,我们将目标函数对策略 θ \theta θ 求导,得到导数后,就可以用梯度上升方法来最大化这个目标函数,从而得到最优策略。
第 3 章讲解过策略 π \pi π 下的状态访问分布,在此用 ν π \nu \pi νπ 表示。然后我们对目标函数求梯度,可以得到如下式子,更详细的推导过程将在 后面给出。
∇ θ J ( θ ) ∝ ∑ s ∈ S ν π θ ( s ) ∑ a ∈ A Q π θ ( s , a ) ∇ θ π θ ( a ∣ s ) = ∑ s ∈ S ν π θ ( s ) ∑ a ∈ A π θ ( a ∣ s ) Q π θ ( s , a ) ∇ θ π θ ( a ∣ s ) π θ ( a ∣ s ) = E π θ [ Q π θ ( s , a ) ∇ θ log π θ ( a ∣ s ) ] \begin{aligned} \nabla_{\theta} J(\theta) & \propto \sum_{s \in \mathcal{S}} \nu^{\pi_{\theta}}(s) \sum_{a \in A} Q^{\pi_{\theta}}(s, a) \nabla_{\theta} \pi_{\theta}(a \mid s) \\ &=\sum_{s \in \mathcal{S}} \nu^{\pi_{\theta}}(s) \sum_{a \in A} \pi_{\theta}(a \mid s) Q^{\pi_{\theta}}(s, a) \frac{\nabla_{\theta} \pi_{\theta}(a \mid s)}{\pi_{\theta}(a \mid s)} \\ &=\mathbb{E}_{\pi_{\theta}}\left[Q^{\pi_{\theta}}(s, a) \nabla_{\theta} \log \pi_{\theta}(a \mid s)\right] \end{aligned} ∇θJ(θ)∝s∈S∑νπθ(s)a∈A∑Qπθ(s,a)∇θπθ(a∣s)=s∈S∑νπθ(s)a∈A∑πθ(a∣s)Qπθ(s,a)πθ(a∣s)∇θπθ(a∣s)=Eπθ[Qπθ(s,a)∇θlogπθ(a∣s)]
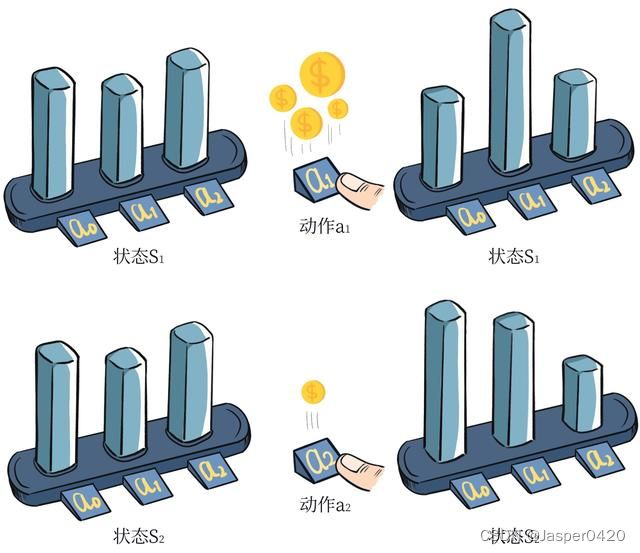
一个状态下,梯度的修改是让策略更多地去采样到带来较高 Q Q Q 值的动作,更少地去采样到带来较低 Q Q Q 值的动作,如图 所示。
∇ θ J ( θ ) = E π θ [ ∑ t = 0 T ( ∑ t ′ = t T γ t ′ − t r t ′ ) ∇ θ log π θ ( a t ∣ s t ) ] \nabla_{\theta} J(\theta)=\mathbb{E}_{\pi_{\theta}}\left[\sum_{t=0}^{T}\left(\sum_{t^{\prime}=t}^{T} \gamma^{t^{\prime}-t} r_{t^{\prime}}\right) \nabla_{\theta} \log \pi_{\theta}\left(a_{t} \mid s_{t}\right)\right] ∇θJ(θ)=Eπθ[t=0∑T(t′=t∑Tγt′−trt′)∇θlogπθ(at∣st)]
其中, T T T 是和环境交互的最大步数。例如,在车杆环境中, T = 200 T=200 T=200 。
3. REINFORCE
REINFORCE 算法的具体算法流程如下:
- 初始化策略参数 θ \theta θ
- for 序列 e = 1 → E e=1 \rightarrow E e=1→E do :
- 用当前策略 π θ \pi_{\theta} πθ 采样轨迹 { s 1 , a 1 , r 1 , s 2 , a 2 , r 2 , … s T , a T , r T } \left\{s_{1}, a_{1}, r_{1}, s_{2}, a_{2}, r_{2}, \ldots s_{T}, a_{T}, r_{T}\right\} {s1,a1,r1,s2,a2,r2,…sT,aT,rT}
- 计算当前轨迹每个时刻 t t t 往后的回报 ∑ t ′ = t T γ t ′ − t r t ′ \sum_{t^{\prime}=t}^{T} \gamma^{t^{\prime}-t} r_{t^{\prime}} ∑t′=tTγt′−trt′ ,记为 ψ t \psi_{t} ψt
- 对 θ \theta θ 进行更新, θ = θ + α ∑ t T ψ t ∇ θ log π θ ( a t ∣ s t ) \theta=\theta+\alpha \sum_{t}^{T} \psi_{t} \nabla_{\theta} \log \pi_{\theta}\left(a_{t} \mid s_{t}\right) θ=θ+α∑tTψt∇θlogπθ(at∣st)
- end for
这便是 REINFORCE 算法的全部流程了。接下来让我们来用代码来实现它,看看效果如何吧!
4. REINFORCE 代码实践
我们在车杆环境中进行 REINFORCE 算法的实验。
import gym
import torch
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
import rl_utils
首先定义策略网络PolicyNet,其输入是某个状态,输出则是该状态下的动作概率分布,这里采用在离散动作空间上的softmax()函数来实现一个可学习的多项分布(multinomial distribution)。
class PolicyNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super(PolicyNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
return F.softmax(self.fc2(x), dim=1)
再定义我们的 REINFORCE 算法。在函数take_action()函数中,我们通过动作概率分布对离散的动作进行采样。在更新过程中,我们按照算法将损失函数写为策略回报的负数,即,对求导后就可以通过梯度下降来更新策略。
class REINFORCE:
def __init__(self, state_dim, hidden_dim, action_dim, learning_rate, gamma,
device):
self.policy_net = PolicyNet(state_dim, hidden_dim,
action_dim).to(device)
self.optimizer = torch.optim.Adam(self.policy_net.parameters(),
lr=learning_rate) # 使用Adam优化器
self.gamma = gamma # 折扣因子
self.device = device
def take_action(self, state): # 根据动作概率分布随机采样
state = torch.tensor([state], dtype=torch.float).to(self.device)
probs = self.policy_net(state)
action_dist = torch.distributions.Categorical(probs)
action = action_dist.sample()
return action.item()
def update(self, transition_dict):
reward_list = transition_dict['rewards']
state_list = transition_dict['states']
action_list = transition_dict['actions']
G = 0
self.optimizer.zero_grad()
for i in reversed(range(len(reward_list))): # 从最后一步算起
reward = reward_list[i]
state = torch.tensor([state_list[i]],
dtype=torch.float).to(self.device)
action = torch.tensor([action_list[i]]).view(-1, 1).to(self.device)
log_prob = torch.log(self.policy_net(state).gather(1, action))
G = self.gamma * G + reward
loss = -log_prob * G # 每一步的损失函数
loss.backward() # 反向传播计算梯度
self.optimizer.step() # 梯度下降
定义好策略,我们就可以开始实验了,看看 REINFORCE 算法在车杆环境上表现如何吧!
learning_rate = 1e-3
num_episodes = 1000
hidden_dim = 128
gamma = 0.98
device = torch.device("cuda") if torch.cuda.is_available() else torch.device(
"cpu")
env_name = "CartPole-v0"
env = gym.make(env_name)
env.seed(0)
torch.manual_seed(0)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
agent = REINFORCE(state_dim, hidden_dim, action_dim, learning_rate, gamma,
device)
return_list = []
for i in range(10):
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)):
episode_return = 0
transition_dict = {
'states': [],
'actions': [],
'next_states': [],
'rewards': [],
'dones': []
}
state = env.reset()
done = False
while not done:
action = agent.take_action(state)
next_state, reward, done, _ = env.step(action)
transition_dict['states'].append(state)
transition_dict['actions'].append(action)
transition_dict['next_states'].append(next_state)
transition_dict['rewards'].append(reward)
transition_dict['dones'].append(done)
state = next_state
episode_return += reward
return_list.append(episode_return)
agent.update(transition_dict)
if (i_episode + 1) % 10 == 0:
pbar.set_postfix({
'episode':
'%d' % (num_episodes / 10 * i + i_episode + 1),
'return':
'%.3f' % np.mean(return_list[-10:])
})
pbar.update(1)
-------------------------------------------------------------------------------------------
Iteration 0: 100%|███████████████████████████████████████| 100/100 [00:02<00:00, 47.36it/s, episode=100, return=55.500]
Iteration 1: 100%|███████████████████████████████████████| 100/100 [00:04<00:00, 21.26it/s, episode=200, return=75.300]
Iteration 2: 100%|██████████████████████████████████████| 100/100 [00:09<00:00, 10.55it/s, episode=300, return=178.800]
Iteration 3: 100%|██████████████████████████████████████| 100/100 [00:11<00:00, 8.74it/s, episode=400, return=164.600]
Iteration 4: 100%|██████████████████████████████████████| 100/100 [00:11<00:00, 8.74it/s, episode=500, return=156.500]
Iteration 5: 100%|██████████████████████████████████████| 100/100 [00:11<00:00, 8.54it/s, episode=600, return=187.400]
Iteration 6: 100%|██████████████████████████████████████| 100/100 [00:11<00:00, 8.52it/s, episode=700, return=194.500]
Iteration 7: 100%|██████████████████████████████████████| 100/100 [00:13<00:00, 7.57it/s, episode=800, return=200.000]
Iteration 8: 100%|██████████████████████████████████████| 100/100 [00:12<00:00, 7.84it/s, episode=900, return=200.000]
Iteration 9: 100%|█████████████████████████████████████| 100/100 [00:12<00:00, 7.89it/s, episode=1000, return=186.100]
在 CartPole-v0 环境中,满分就是 200 分,我们发现 REINFORCE 算法效果很好,可以达到 200 分。接下来我们绘制训练过程中每一条轨迹的回报变化图。由于回报抖动比较大,往往会进行平滑处理。
episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('REINFORCE on {}'.format(env_name))
plt.show()
mv_return = rl_utils.moving_average(return_list, 9)
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('REINFORCE on {}'.format(env_name))
plt.show()

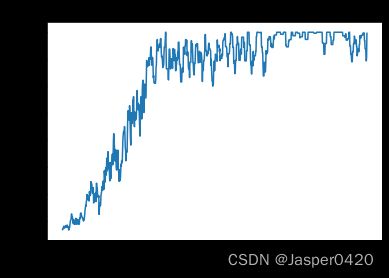
以看到,随着收集到的轨迹越来越多,REINFORCE 算法有效地学习到了最优策略。不过,相比于前面的 DQN 算法,REINFORCE 算法使用了更多的序列,这是因为 REINFORCE 算法是一个在线策略算法,之前收集到的轨迹数据不会被再次利用。此外,REINFORCE 算法的性能也有一定程度的波动,这主要是因为每条采样轨迹的回报值波动比较大,这也是 REINFORCE 算法主要的不足。
5. 小结
REINFORCE 算法是策略梯度乃至强化学习的典型代表,智能体根据当前策略直接和环境交互,通过采样得到的轨迹数据直接计算出策略参数的梯度,进而更新当前策略,使其向最大化策略期望回报的目标靠近。这种学习方式是典型的从交互中学习,并且其优化的目标(即策略期望回报)正是最终所使用策略的性能,这比基于价值的强化学习算法的优化目标(一般是时序差分误差的最小化)要更加直接。 REINFORCE 算法理论上是能保证局部最优的,它实际上是借助蒙特卡洛方法采样轨迹来估计动作价值,这种做法的一大优点是可以得到无偏的梯度。但是,正是因为使用了蒙特卡洛方法,REINFORCE 算法的梯度估计的方差很大,可能会造成一定程度上的不稳定,这也是第 10 章将介绍的 Actor-Critic 算法要解决的问题。
6. 扩展:策略梯度证明
策略梯度定理是强化学习中的重要理论。本节我们来证明
∇ θ J ( θ ) ∝ ∑ s ∈ S ν π θ ( s ) ∑ a ∈ A Q π θ ( s , a ) ∇ θ π θ ( a ∣ s ) \nabla_{\theta} J(\theta) \propto \sum_{s \in S} \nu^{\pi_{\theta}}(s) \sum_{a \in A} Q^{\pi_{\theta}}(s, a) \nabla_{\theta} \pi_{\theta}(a \mid s) ∇θJ(θ)∝s∈S∑νπθ(s)a∈A∑Qπθ(s,a)∇θπθ(a∣s)
先从状态价值函数的推导开始:
∇ θ V π θ ( s ) = ∇ θ ( ∑ a ∈ A π θ ( a ∣ s ) Q π θ ( s , a ) ) = ∑ a ∈ A ( ∇ θ π θ ( a ∣ s ) Q π θ ( s , a ) + π θ ( a ∣ s ) ∇ θ Q π θ ( s , a ) ) = ∑ a ∈ A ( ∇ θ π θ ( a ∣ s ) Q π θ ( s , a ) + π θ ( a ∣ s ) ∇ θ ∑ s ′ , r p ( s ′ , r ∣ s , a ) ( r + γ V π θ ( s ′ ) ) = ∑ a ∈ A ( ∇ θ π θ ( a ∣ s ) Q π θ ( s , a ) + γ π θ ( a ∣ s ) ∑ s ′ , r p ( s ′ , r ∣ s , a ) ∇ θ V π θ ( s ′ ) ) = ∑ a ∈ A ( ∇ θ π θ ( a ∣ s ) Q π θ ( s , a ) + γ π θ ( a ∣ s ) ∑ s ′ p ( s ′ ∣ s , a ) ∇ θ V π θ ( s ′ ) ) \begin{aligned} \nabla_{\theta} V^{\pi_{\theta}}(s) &=\nabla_{\theta}\left(\sum_{a \in A} \pi_{\theta}(a \mid s) Q^{\pi_{\theta}}(s, a)\right) \\ &=\sum_{a \in A}\left(\nabla_{\theta} \pi_{\theta}(a \mid s) Q^{\pi_{\theta}}(s, a)+\pi_{\theta}(a \mid s) \nabla_{\theta} Q^{\pi_{\theta}}(s, a)\right) \\ &=\sum_{a \in A}\left(\nabla_{\theta} \pi_{\theta}(a \mid s) Q^{\pi_{\theta}}(s, a)+\pi_{\theta}(a \mid s) \nabla_{\theta} \sum_{s^{\prime}, r} p\left(s^{\prime}, r \mid s, a\right)\left(r+\gamma V^{\pi_{\theta}}\left(s^{\prime}\right)\right)\right.\\ &=\sum_{a \in A}\left(\nabla_{\theta} \pi_{\theta}(a \mid s) Q^{\pi_{\theta}}(s, a)+\gamma \pi_{\theta}(a \mid s) \sum_{s^{\prime}, r} p\left(s^{\prime}, r \mid s, a\right) \nabla_{\theta} V^{\pi_{\theta}}\left(s^{\prime}\right)\right) \\ &=\sum_{a \in A}\left(\nabla_{\theta} \pi_{\theta}(a \mid s) Q^{\pi_{\theta}}(s, a)+\gamma \pi_{\theta}(a \mid s) \sum_{s^{\prime}} p\left(s^{\prime} \mid s, a\right) \nabla_{\theta} V^{\pi_{\theta}}\left(s^{\prime}\right)\right) \end{aligned} ∇θVπθ(s)=∇θ(a∈A∑πθ(a∣s)Qπθ(s,a))=a∈A∑(∇θπθ(a∣s)Qπθ(s,a)+πθ(a∣s)∇θQπθ(s,a))=a∈A∑⎝⎛∇θπθ(a∣s)Qπθ(s,a)+πθ(a∣s)∇θs′,r∑p(s′,r∣s,a)(r+γVπθ(s′))=a∈A∑⎝⎛∇θπθ(a∣s)Qπθ(s,a)+γπθ(a∣s)s′,r∑p(s′,r∣s,a)∇θVπθ(s′)⎠⎞=a∈A∑(∇θπθ(a∣s)Qπθ(s,a)+γπθ(a∣s)s′∑p(s′∣s,a)∇θVπθ(s′))
为了简化表示,我们让 ϕ ( s ) = ∑ a ∈ A ∇ θ π θ ( a ∣ s ) Q π θ ( s , a ) \phi(s)=\sum_{a \in A} \nabla_{\theta} \pi_{\theta}(a \mid s) Q^{\pi_{\theta}}(s, a) ϕ(s)=∑a∈A∇θπθ(a∣s)Qπθ(s,a), 定义 d π θ ( s → x , k ) d^{\pi_{\theta}}(s \rightarrow x, k) dπθ(s→x,k) 为策略 π \pi π 从状态 s s s 出发 k k k 步后到达状态 x x x 的概率。我们继续推导:
∇ θ V π θ ( s ) = ϕ ( s ) + γ ∑ a π θ ( a ∣ s ) ∑ s ′ P ( s ′ ∣ s , a ) ∇ θ V π θ ( s ′ ) = ϕ ( s ) + γ ∑ a ∑ s ′ π θ ( a ∣ s ) P ( s ′ ∣ s , a ) ∇ θ V π θ ( s ′ ) = ϕ ( s ) + γ ∑ s ′ d π θ ( s → s ′ , 1 ) ∇ θ V π θ ( s ′ ) = ϕ ( s ) + γ ∑ s ′ d π θ ( s → s ′ , 1 ) [ ϕ ( s ′ ) + γ ∑ s ′ ′ d π θ ( s ′ → s ′ ′ , 1 ) ∇ θ V π θ ( s ′ ′ ) ] = ϕ ( s ) + γ ∑ s ′ d π θ ( s → s ′ , 1 ) ϕ ( s ′ ) + γ 2 ∑ s ′ ′ d π θ ( s → s ′ ′ , 2 ) ∇ θ V π θ ( s ′ ′ ) = ϕ ( s ) + γ ∑ s ′ d π 0 ( s → s ′ , 1 ) ϕ ( s ′ ) + γ 2 ∑ s ′ ′ d π θ ( s ′ → s ′ ′ , 2 ) ϕ ( s ′ ′ ) + γ 3 ∑ s ′ ′ ′ d π θ ( s → s ′ ′ ′ , 3 ) ∇ θ V π θ ( s ′ ′ ′ ) = ⋯ = ∑ x ∈ S ∑ k = 0 ∞ γ k d π θ ( s → x , k ) ϕ ( x ) \begin{aligned} \nabla_{\theta} V^{\pi_{\theta}}(s) &=\phi(s)+\gamma \sum_{a} \pi_{\theta}(a \mid s) \sum_{s^{\prime}} P\left(s^{\prime} \mid s, a\right) \nabla_{\theta} V^{\pi_{\theta}}\left(s^{\prime}\right) \\ &=\phi(s)+\gamma \sum_{a} \sum_{s^{\prime}} \pi_{\theta}(a \mid s) P\left(s^{\prime} \mid s, a\right) \nabla_{\theta} V^{\pi_{\theta}}\left(s^{\prime}\right) \\ &=\phi(s)+\gamma \sum_{s^{\prime}} d^{\pi_{\theta}}\left(s \rightarrow s^{\prime}, 1\right) \nabla_{\theta} V^{\pi_{\theta}}\left(s^{\prime}\right) \\ &=\phi(s)+\gamma \sum_{s^{\prime}} d^{\pi_{\theta}}\left(s \rightarrow s^{\prime}, 1\right)\left[\phi\left(s^{\prime}\right)+\gamma \sum_{s^{\prime \prime}} d^{\pi_{\theta}}\left(s^{\prime} \rightarrow s^{\prime \prime}, 1\right) \nabla_{\theta} V^{\pi_{\theta}}\left(s^{\prime \prime}\right)\right] \\ &=\phi(s)+\gamma \sum_{s^{\prime}} d^{\pi_{\theta}}\left(s \rightarrow s^{\prime}, 1\right) \phi\left(s^{\prime}\right)+\gamma^{2} \sum_{s^{\prime \prime}} d^{\pi_{\theta}}\left(s \rightarrow s^{\prime \prime}, 2\right) \nabla_{\theta} V^{\pi_{\theta}}\left(s^{\prime \prime}\right) \\ &=\phi(s)+\gamma \sum_{s^{\prime}} d^{\pi_{0}}\left(s \rightarrow s^{\prime}, 1\right) \phi\left(s^{\prime}\right)+\gamma^{2} \sum_{s^{\prime \prime}} d^{\pi_{\theta}}\left(s^{\prime} \rightarrow s^{\prime \prime}, 2\right) \phi\left(s^{\prime \prime}\right)+\gamma^{3} \sum_{s^{\prime \prime \prime}} d^{\pi_{\theta}}\left(s \rightarrow s^{\prime \prime \prime}, 3\right) \nabla_{\theta} V^{\pi_{\theta}}\left(s^{\prime \prime \prime}\right) \\ &=\cdots \\ &=\sum_{x \in S} \sum_{k=0}^{\infty} \gamma^{k} d^{\pi_{\theta}}(s \rightarrow x, k) \phi(x) \end{aligned} ∇θVπθ(s)=ϕ(s)+γa∑πθ(a∣s)s′∑P(s′∣s,a)∇θVπθ(s′)=ϕ(s)+γa∑s′∑πθ(a∣s)P(s′∣s,a)∇θVπθ(s′)=ϕ(s)+γs′∑dπθ(s→s′,1)∇θVπθ(s′)=ϕ(s)+γs′∑dπθ(s→s′,1)[ϕ(s′)+γs′′∑dπθ(s′→s′′,1)∇θVπθ(s′′)]=ϕ(s)+γs′∑dπθ(s→s′,1)ϕ(s′)+γ2s′′∑dπθ(s→s′′,2)∇θVπθ(s′′)=ϕ(s)+γs′∑dπ0(s→s′,1)ϕ(s′)+γ2s′′∑dπθ(s′→s′′,2)ϕ(s′′)+γ3s′′′∑dπθ(s→s′′′,3)∇θVπθ(s′′′)=⋯=x∈S∑k=0∑∞γkdπθ(s→x,k)ϕ(x)
定义 η ( s ) = E s 0 [ ∑ k = 0 ∞ γ k d π θ ( s 0 → s , k ) ] 。至此,回到目标函数: \eta(s)=\mathbb{E}_{s_{0}}\left[\sum_{k=0}^{\infty} \gamma^{k} d^{\pi_{\theta}}\left(s_{0} \rightarrow s, k\right)\right]_{\text {。至此,回到目标函数: }} η(s)=Es0[∑k=0∞γkdπθ(s0→s,k)]。至此,回到目标函数: :
∇ θ J ( θ ) = ∇ θ E s 0 [ V π θ ( s 0 ) ] = ∑ s E s 0 [ ∑ k = 0 ∞ γ k d π θ ( s 0 → s , k ) ] ϕ ( s ) = ∑ s η ( s ) ϕ ( s ) = ( ∑ s η ( s ) ) ∑ s η ( s ) ∑ s η ( s ) ϕ ( s ) ∝ ∑ s η ( s ) ∑ s η ( s ) ϕ ( s ) = ∑ s ν π θ ( s ) ∑ a Q π θ ( s , a ) ∇ θ π θ ( a ∣ s ) \begin{aligned} \nabla_{\theta} J(\theta) &=\nabla_{\theta} \mathbb{E}_{s_{0}}\left[V^{\pi_{\theta}}\left(s_{0}\right)\right] \\ &=\sum_{s} \mathbb{E}_{s_{0}}\left[\sum_{k=0}^{\infty} \gamma^{k} d^{\pi_{\theta}}\left(s_{0} \rightarrow s, k\right)\right] \phi(s) \\ &=\sum_{s} \eta(s) \phi(s) \\ &=\left(\sum_{s} \eta(s)\right) \sum_{s} \frac{\eta(s)}{\sum_{s} \eta(s)} \phi(s) \\ & \propto \sum_{s} \frac{\eta(s)}{\sum_{s} \eta(s)} \phi(s) \\ &=\sum_{s} \nu^{\pi_{\theta}}(s) \sum_{a} Q^{\pi_{\theta}}(s, a) \nabla_{\theta} \pi_{\theta}(a \mid s) \end{aligned} ∇θJ(θ)=∇θEs0[Vπθ(s0)]=s∑Es0[k=0∑∞γkdπθ(s0→s,k)]ϕ(s)=s∑η(s)ϕ(s)=(s∑η(s))s∑∑sη(s)η(s)ϕ(s)∝s∑∑sη(s)η(s)ϕ(s)=s∑νπθ(s)a∑Qπθ(s,a)∇θπθ(a∣s)
证明完毕 !
相关资源来自:伯禹学习平台-动手学强化学习
