数字图像处理 第八章——图像压缩
目录
8.1 基础知识
8.1.1 编码冗余
8.1.2 空间冗余和时间冗余
8.1.3 不相关的信息
8.1.4 图像信息的度量
香农第一定理
8.1.5 保真度准则
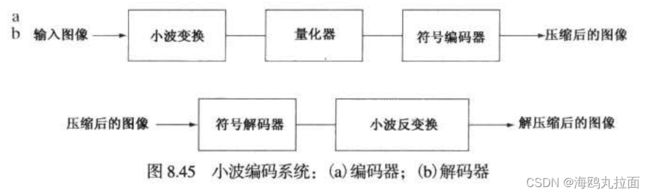
8.1.6 图像压缩模型
编码或压缩过程
在编码处理的第一个阶段,映射器吧f(x,...)变换为降低空间和事件冗余的形式(通常不可见)。这一操作通常是可逆的,并且可能会也可能不会直接减少表示图像所需的数据量。行程编码就是一个映射的例子,该映射通常在编码处理的第一步中就会得到压缩。
解码或解压缩过程
8.1.7 图像格式、容器和压缩标准
8.2 一些基本的压缩方法
8.2.1 霍夫曼编码
8.2.2 Golomb编码
8.2.3 算数编码
自适应上下文相关的概率估计
8.2.4 LZW编码
8.2.5 行程编码
8.2.6 基于符号的编码
8.2.7 比特平面编码
8.2.8 块变换编码
8.2.9 预测编码
8.2.10 小波编码
8.3 数字图像水印
图像压缩是一种减少描绘一幅图像所需数据量的技术和科学。图像和视频通常在计算机中表示会占用很大的空间,而出于节省硬盘空间的考虑,往往要进行压缩。
8.1 基础知识
数据压缩是指减少表示给定信息量所需数据量的处理不同数量的数据可以用来表示相同数量的信息,包含不相关或重复信息的表示被认为包含冗余数据。
若令b和b'代表相同信息的两种表示中的比特数(或信息携带单元),则用b比特表示的相对数据冗余R是
![]()
式中,C通常称为压缩率,定义为
![]()
二维灰度阵列受如下可被识别和利用的三种主要类型的数据冗余的影响:
- 编码冗余。编码是用于表示信息实体或事件集合的符号系统(字母、数字、比特和类似的符号等)。每个信息或事件被赋予一个编码符号的序列,称之为码子。每个码字中的符号数量就是该码字的长度。在多数二维灰度阵列中,用于表示灰度的8比特编码所包含的比特数要比表示该灰度所需要的比特数多。
- 空间和时间冗余。因为多数二维灰度阵列的像素是空间相关的(即每一个像素类似于或取决于相邻像素),在相关像素的表示中,信息被没有必要地重复了。在视频序列汇总,时间相关的像素(即类似于或取决于相邻帧中的那些像素)也是重复的信息。
- 不相关的信息。多数二维灰度阵列中包含有一些被人类视觉信息忽略或与用途无关的信息。从没有被利用的意义上看,它是冗余的。
8.1.1 编码冗余
假设在区间[0,L-1]内的一个离散随机变量rk用来表示一幅MxN的图像的灰度,并且每个rk发生的概率为pr(rk)。
![]()
其中,L是灰度级数,nk是第k级灰度在图像中出现的次数。如果用于表示每个rk值的比特数为l(rk),则表示每个像素所需的平均比特数为
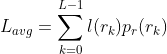
给每个灰度级分配的码字的平均长度,可通过对用于表示每个灰度的比特数与该灰度出现的概率的乘积求和来得到。
当对事件集合(如灰度值)分配码的时候,如果不取全部事件概率的优势,就会出现编码冗余。当用自然二进码表示一幅图像时,编码冗余几乎总是存在的。
8.1.2 空间冗余和时间冗余
在对应的二维灰度阵列中:
- 所有256种灰度都是等概率的。
- 因为每条线的灰度是随机选择的,在垂直方向上,每条线的像素彼此是独立的。
- 因为沿每条线的像素是相同的,因此在水平方向上它们是最大相关的(完全互相依赖)。
8.1.3 不相关的信息
压缩数据集的最简方法之一是,从集合中消除多余的数据。在数字图像压缩方面,被人类视觉系统忽略的信息或与图像预期的应用无关的信息显然都是要删除的对象。
8.1.4 图像信息的度量
信息论的基本前提是,细心地产生可用一个概率过程建模,该过程可以用一种与直觉一致的方式加以度量。根据这一推测,我们可以说概率为P(E)的随机事件E包含
![]()
单位的信息。如果P(E)=1(即事件总会发生),则I(E)=0,并认为它没有信息。因为没有与该事件相关的不确定性,所以在通信中不会传递关于这个事件已经发生的任何信息。
从一个可能事件的离散集合{a1,a2,...,aj},给定一个统计独立随机事件的信源,与该集合相联系的概率为{P(a1),P(a2),...,P(aj)},则每个信源输出的平均信息称为该信源的熵,即
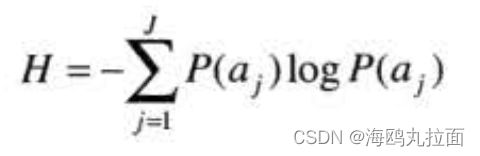
香农第一定理
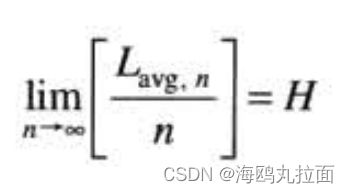
式中![]() 是表示所有n重符号组所需编码符号的平均数。
是表示所有n重符号组所需编码符号的平均数。
8.1.5 保真度准则
评估方法:
- 客观保真度准则
- 主观保真度准则
当信息损失可以表示为压缩处理的输入和输出的数学函数时,则称其是以客观保真度准则为基础的。令f(x,y)是输入图像,并令![]() 是f(x,y)的近似,它是对输入先压缩后解压缩的结果。对任意x和y的值,f(x,y)和
是f(x,y)的近似,它是对输入先压缩后解压缩的结果。对任意x和y的值,f(x,y)和![]() 之间的误差e(x,y)为
之间的误差e(x,y)为
![]()
因此,两幅图像间总误差为
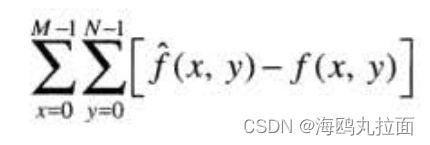
其中,图像的大小为MxN。而f(x,y)和![]() 之间的均方根误差erms是在MxN阵列上平均误差的平方的平方根,或写为
之间的均方根误差erms是在MxN阵列上平均误差的平方的平方根,或写为
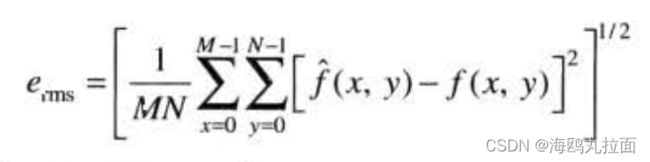
输出图像的均方信噪比
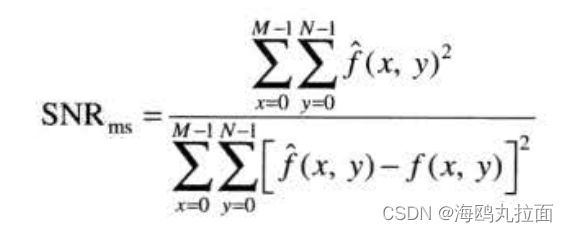
8.1.6 图像压缩模型
图像压缩系统是由两个不同的功能部分组成的:一个编码器和一个解码器。编码器执行压缩操作,解码器执行解压缩操作。
编码或压缩过程
在编码处理的第一个阶段,映射器吧f(x,...)变换为降低空间和事件冗余的形式(通常不可见)。这一操作通常是可逆的,并且可能会也可能不会直接减少表示图像所需的数据量。行程编码就是一个映射的例子,该映射通常在编码处理的第一步中就会得到压缩。
量化器根据预设的保真度准则降低映射器输出的精度,目的是排除压缩表示的无关信息。这一操作不可逆,当我们希望进行无误差压缩时,这一步必须省略。
在第三阶段,即信源编码处理的最后阶段,符号编码器生成一个定长编码或变长编码来表示量化器的输出,并根据该编码来映射输出。大多数情况下会使用变长编码。
解码或解压缩过程
解码器仅包含两个部分:一个符号解码器和一个反映射器。它们以相反的顺序执行编码器的符号编码器和映射器的反操作。
8.1.7 图像格式、容器和压缩标准
图像文件格式是组织和存储图像数据的标准方法。它定义了数据排列方式和所用的压缩类型——如果有的话。图像容器类似于文件格式,但处理多种类型的图像数据。另一方面,图像压缩标准对压缩和解压缩图像定义了过程,也就是定义减少表示一幅图像所需数据量的过程。
8.2 一些基本的压缩方法
8.2.1 霍夫曼编码
单独对信源的符号进行编码时,霍夫曼编码对每个信源符号产生最小数量的编码符号。
霍夫曼编码步骤:
- 创建一系列简化信源。

- 对每个化简后的信源进行编码,从最小的信源开始,直到遍历每个信源。

class Node(object):
def __init__(self,name=None,value=None):
self._name=name
self._value=value
self._left=None
self._right=None
class HuffmanTree(object):
#根据Huffman树的思想:以节点为基础,反向建立Huffman树
def __init__(self,char_weights):
self.Leav=[Node(part[0],part[1]) for part in char_weights]
#根据输入的字符及其频数生成节点
while len(self.Leav)!=1:
#当reverse不为true时(默认为false),sort就是从小到大输出
#因为要排序的是结构体里面的某个值,所以要用参数key
#lambda是一个隐函数,是固定写法
self.Leav.sort(key=lambda node:node._value,reverse=True)
c=Node(value=(self.Leav[-1]._value+self.Leav[-2]._value))
#数组pop默认删除最后一个元素,参数为-1可加可不加,并返回该值
c._left=self.Leav.pop(-1)
c._right=self.Leav.pop(-1)
#在数组最后添加新对象
self.Leav.append(c)
#最后一个节点作为根节点
self.root=self.Leav[0]
self.Buffer=list(range(10))
#用递归的思想生成编码
def pre(self,tree,length):
node=tree
if (not node):
return
elif node._name:
print (node._name + ' encoding:',end=''),
for i in range(length):
print (self.Buffer[i],end='')
print ('\n')
return
self.Buffer[length]=0
self.pre(node._left,length+1)
self.Buffer[length]=1
self.pre(node._right,length+1)
#生成哈夫曼编码
def get_code(self):
self.pre(self.root,0)
if __name__=='__main__':
#输入的是字符及其频数
char_weights=[('a',6),('b',4),('c',10),('d',8),('f',12),('g',2)]
tree=HuffmanTree(char_weights)
tree.get_code()
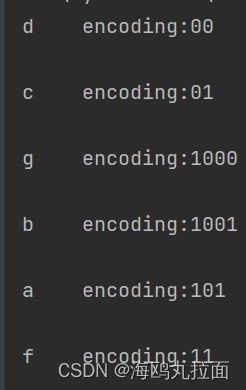
0和1仅作为区分,没有硬性规定概率大或概率小为1。在编码过程中,概率小的信源被分配了更长的码长,概率大的信源被分配了更短的码长。
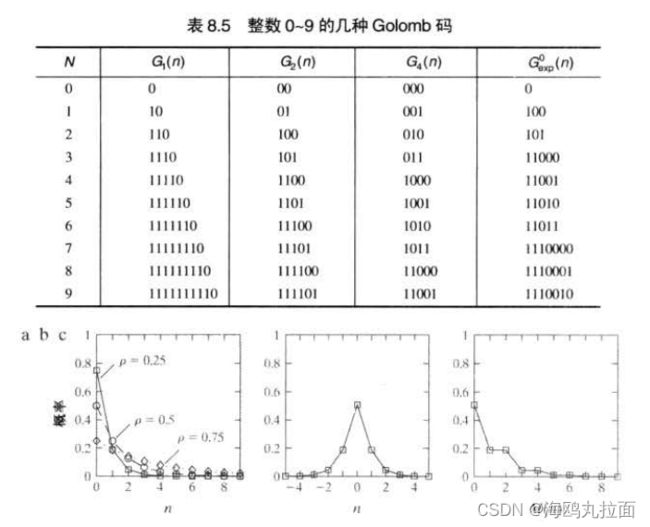
8.2.2 Golomb编码
Golomb编码是具有指数衰减概率分布的非负整数输入的编码。下面的讨论中,符号![]() 表示小于等于x的最大整数,
表示小于等于x的最大整数,![]() 表示大于等于x的最小整数,x mod y表示x被y除的余数。
表示大于等于x的最小整数,x mod y表示x被y除的余数。
- 步骤1 形成商
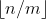 的一元编码(整数q的一元编码定义为q个1紧跟着一个0).
的一元编码(整数q的一元编码定义为q个1紧跟着一个0). - 步骤2 令k=
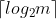 ,c=
,c=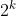 -m,r=n mod m,并计算截短的余数r'。
-m,r=n mod m,并计算截短的余数r'。 - 步骤3 连接步骤1和步骤2的结果。
8.2.3 算数编码
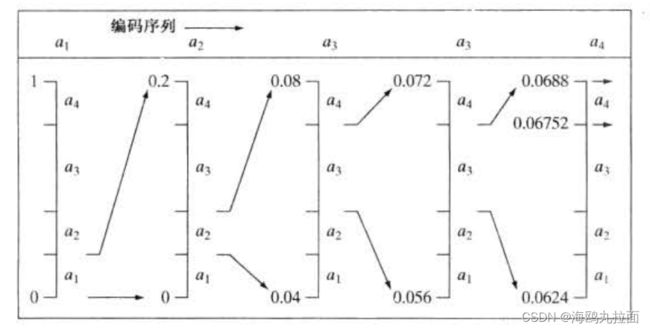
算数编码生成非块码。在算数编码中,信源符号和码字之间不存在一一对应关系。相反,信源符号(或消息)的整个序列被分配了单一的算数码字。这个码字本身定义了一个介于0和1之间的实数间隔。当消息中的符号数量增加时,用于表示消息的间隔会变小,而表示该间隔所需的信息单位(假设为比特)的数量则会变大。消息的每个符号根据其出现的概率来减小该区间的大小。
下图说明了算数编码的基本过程。
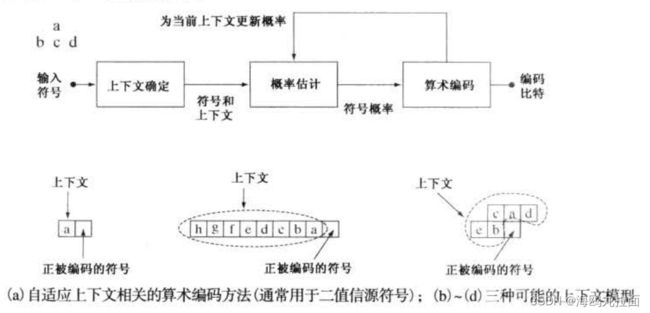
自适应上下文相关的概率估计
上图给出了二值信源符号的自适应上下文相关算数编码包括的步骤。当对二值符号编码时,通常使用算术编码。当对每个符号(或比特)开始编码过程时,其上下文由(a)的上下文决定模块形成。(b)到(d)显示了3种可被使用的上下文:(1)前一符号;(2)前一组符号;(3)前一些符号加上前一扫描行上的符号。
8.2.4 LZW编码
LZW编码思想:不断地从字符流中提取新的字符串,通俗地理解为新“词条”,然后用“代号”也就是码字表示这个“词条”。这样一来,对字符流的编码就变成了用码字去替换字符流,生成码字流,从而达到压缩数据的目的。
特点:编码字典或码书是在对数据进行编码的同时创建的。在LZW解码器对编码数据流进行解码的同时,建立了一个同样的解压缩字典。
8.2.5 行程编码
行程编码技术是沿其行(或列)重复灰度的图像,通常可用相同灰度的行程表示为行程对来压缩,其中每个行程对指定一个新灰度的开始和具有该灰度的连续像素的数量。
压缩二值图像时,行程编码特别有效。因为仅有两种可能的灰度(黑和白),所以邻近像素的灰度更可能是相同的。
接下来使用二值图像进行行程编码处理尝试。首先对一张普通图片进行处理,获得其二值化图像。
from PIL import Image
img = Image.open(r'G:\9.jpg')
# 模式L”为灰色图像,它的每个像素用8个bit表示,0表示黑,255表示白,其他数字表示不同的灰度。
Img = img.convert('L')
Img.save("G:\9-huidu.jpg")
# 自定义灰度界限,大于这个值为白色,小于这个值为黑色
threshold = 200
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
# 图片二值化
photo = Img.point(table, '1')
photo.save("G:\9-2zhi.jpg")

接下来对获得二值图像进行RLE压缩
import cv2 as cv
import numpy as np
##彩色图像灰度化
# image = cv.imread('image/shayu.jpg',1)
image = cv.imread(r'G:\9-2zhi.jpg', 1)
grayimg = cv.cvtColor(image, cv.COLOR_BGR2GRAY)
rows, cols = grayimg.shape
image1 = grayimg.flatten() # 把灰度化后的二维图像降维为一维列表
# print(len(image1))
# 二值化操作
for i in range(len(image1)):
if image1[i] >= 127:
image1[i] = 255
if image1[i] < 127:
image1[i] = 0
data = []
image3 = []
count = 1
# 行程压缩编码
for i in range(len(image1) - 1):
if (count == 1):
image3.append(image1[i])
if image1[i] == image1[i + 1]:
count = count + 1
if i == len(image1) - 2:
image3.append(image1[i])
data.append(count)
else:
data.append(count)
count = 1
if (image1[len(image1) - 1] != image1[-1]):
image3.append(image1[len(image1) - 1])
data.append(1)
# 压缩率
ys_rate = len(image3) / len(image1) * 100
print('压缩率为' + str(ys_rate) + '%')
# 行程编码解码
rec_image = []
for i in range(len(data)):
for j in range(data[i]):
rec_image.append(image3[i])
rec_image = np.reshape(rec_image, (rows, cols))
# cv.imwrite('image/output.jpg',rec_image)
cv.imshow('rec_image', rec_image) # 重新输出二值化图像
cv.waitKey(0)使用同样的方法对原图像进行压缩,对原图像(左上)、二值图像(右上)、RLE处理后原图像(左下)、RLE处理后二值图像(右下)进行比较,可以发现RLE处理的二值图像比原图像效果更佳。




8.2.6 基于符号的编码
在基于符号或记号的编码中,图像被表示为多幅频繁发生的子图像的一个集合,称为符号。每个这样的符号都存储在一个符号字典中,且该图像以一个三元组{(x1,y1,t1),(x2,y2,t2),...}的集合来编码,其中每个(xi,yi)对规定了图像中的一个符号的位置,而记号ti是该符号或子图像在字典中的地址。即每个三元组表示图像中的一个字典符号的一个实例。通过仅存储一次重复的符号,可以有效地压缩图像,特别是在文档存储和检索应用中,在这种情况下,符号通常是重复多次的字符位图。
8.2.7 比特平面编码
先前讨论的行程编码技术和基于符号的编码技术,可通过单独处理图像的比特平面的方法用于两级以上灰度的图像。概念:把一幅多级(单色或彩色)图像分解为一系列二值图像,并使用几种熟知的二值压缩方法之一来压缩每幅二值图像。
一幅m比特单色图像的灰度可以用如下形式的基2多项式来表示:
![]()
基于这种特性,可以将该图像分解为二值图像集的一种简单方法是把该多项式的m个系数分离为m个1比特的比特平面。一般来讲,每个比特平面都由给其像素置一个来自原始图像每一像素的合适的比特值或多项式系数来重建。例如,一个灰度为127(二进制为:01111111)的像素与一个灰度为128(二进制:10000000)的像素相邻,每个比特平面将包含一个对应0到1的转换。
一种代替分解方法(降低较小灰度变化带来的影响)是,首先用一个m比特格雷码表示图像。
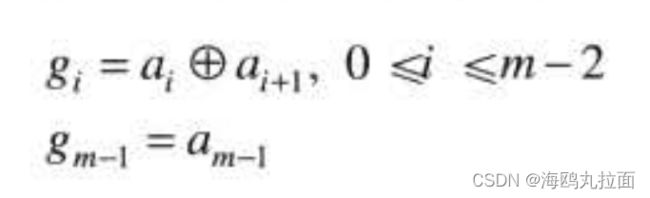
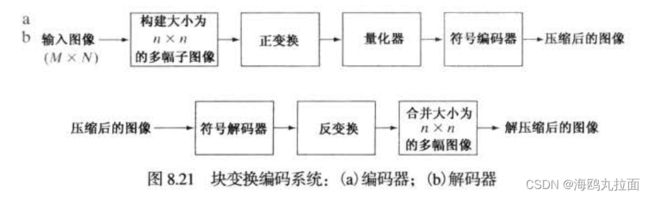
8.2.8 块变换编码
块变换编码技术把图像分成大小相等切不重叠的小块,并使用二维变换单独地处理这些块。在块变换编码中,用一种可逆线性变换(如傅里叶变换)把每个块或子图像映射为变换系数集合,然后对这些变换系数进行量化和编码。
8.2.9 预测编码
预测编码不需要较大的计算开销就可实现较好的压缩效果,并且可以是无误差的或有损的压缩。
预测编码通过消除紧邻像素在空间和时间上的冗余来实现,他仅对每个像素中的新信息进行提取和编码,一个像素的新信息定义为该像素的实际值与预测值之间的差。
8.2.10 小波编码
小波编码基于以下概念:对图像像素解除相关的变换系数进行编码,比对原图像像素本身进行编码的效率更高。如果变换的基函数(此时为小波函数)将大多数重要的可视信息包装到少量系数中,则剩下的系数可被粗略地量化或截取为零,而图像几乎没有失真。
小波的选择
上图中正变换和逆变换的基所选择的小波影响着小波编码系统的设计和性能的各个方面,它们直接影响到变换的计算复杂性,或间接影响压缩和重建具有可接受误差的图像系统能力。基于小波的压缩广泛使用的展开函数是Daubechies小波和双正交小波
分解级别的选取
另一种影响小波编码计算复杂性和重建误差的因素是变换分解级别的数量。由于P尺寸快速小波变换涉及P个滤波器组的迭代,正变换和反变换计算中的操作次数会随分解级数的增加而增加。此外,对更高分解级别导致的越来越低的尺度系数进行量化,会影响重建图像中越来越大的区域。
量化器设计
影响小波编码压缩和重建误差的最重要因素是系数量化。尽管最广泛使用的量化器是均匀的,但量化的效果可以通过以下方法进一步改进:
- 引入一个以零为中心的较大量化间隔,称为死区。
- 从一个尺度到另一个尺度自适应调整量化间隔的大小。
不论哪种情况,选择的量化间隔都必须随着编码图像的比特流传送给解码器。间隔本身可被试探地决定,或根据被压缩的图像自动地计算。
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 需要安装python小波分析库PyWavelets
from pywt import dwt2, idwt2
def put(path):
# 0是表示直接读取灰度图
img = cv2.imread(r'G:\10.jpg', 0)
# 对img进行haar小波变换:,haar小波
cA, (cH, cV, cD) = dwt2(img, 'haar')
# 小波变换之后,低频分量对应的图像:
a = np.uint8(cA / np.max(cA) * 255)
# 小波变换之后,水平方向高频分量对应的图像:
b = np.uint8(cH / np.max(cH) * 255)
# 小波变换之后,垂直平方向高频分量对应的图像:
c = np.uint8(cV / np.max(cV) * 255)
# 小波变换之后,对角线方向高频分量对应的图像:
d = np.uint8(cD / np.max(cD) * 255)
# 根据小波系数重构回去的图像
rimg = idwt2((cA, (cH, cV, cD)), 'haar')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.subplot(231), plt.imshow(img, 'gray'), plt.title('原始图像'), plt.axis('off')
plt.subplot(232), plt.imshow(a, 'gray'), plt.title('低频分量'), plt.axis('off')
plt.subplot(233), plt.imshow(b, 'gray'), plt.title('水平方向高频分量'), plt.axis('off')
plt.subplot(234), plt.imshow(c, 'gray'), plt.title('垂直平方向高频分量'), plt.axis('off')
plt.subplot(235), plt.imshow(d, 'gray'), plt.title('对角线方向高频分量'), plt.axis('off')
plt.subplot(236), plt.imshow(rimg, 'gray'), plt.title('重构图像'), plt.axis('off')
# plt.savefig('3.new-img.jpg')
plt.show()
# 图像处理函数,要传入路径
put(r'../image/image1.jpg')
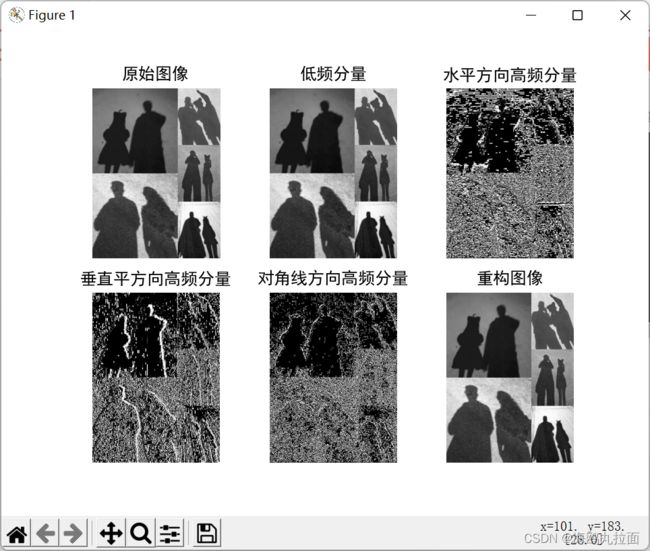
低频分量代表图像中亮度或灰度变化缓慢的区域,高频分量代表图像变化剧烈的部分,即轮廓边缘或者噪声及细节部分。
JPEG-2000
JPEG-2000扩充了流行的JPEG标准,在连续色调静止图像的亚索和压缩数据的访问方面提供了更大的灵活性。
编码过程的第一步是,通过减去![]() ,对被编码的Size比特的无符号图像的样本进行直流电平平移。如果图像具有多于一个的分量:如彩色图像的红色、绿色和蓝色平面,则单独平移每个分量。如果恰好有三个分量,就可用使用一个可逆的或非可逆的线性组合来对它们有选择的进行去相关处理。
,对被编码的Size比特的无符号图像的样本进行直流电平平移。如果图像具有多于一个的分量:如彩色图像的红色、绿色和蓝色平面,则单独平移每个分量。如果恰好有三个分量,就可用使用一个可逆的或非可逆的线性组合来对它们有选择的进行去相关处理。
图像经过级别平移和选择性去相关后,其分量可以被分成多个像块,这些像块是被单独处理的像素的矩形阵列。之后计算每个像块分量的行和列的一维离散小波变换,对于无误差压缩,这种变换是以双正交、5-3系数尺度-小波向量为基础的。对于非整数值变换系数还定义了一个四舍五入过程。在有损应用中,采用了9-7系数尺度-小波向量。
8.3 数字图像水印
数字图像水印不能从图像本身分离出来,作为水印图像的组成部分,它们以各种方法保护所有者的权益,包括:
- 版权识别。当所有者的权益受到侵犯时,数字水印可提供作为所有权证据的信息。
- 用户识别或指纹。合法用户的神分可以再水印中编码,并用于识别非法复制源。
- 著作权认定。水印的存在可保证一幅图像不被篡改——假定水印被设计成对图像的任何修改都将破坏水印。
- 自动监视。水印可以通过系统来监测,系统可在任何时间和地点跟踪所使用的的图像(可搜索放在Web网页上的图像)。对于征收版税和/或非法用户定位监测很有用。
- 复制保护。水印可制定使用和复制图像的规则(如对DVD播放器)。