计算机视觉入门知识一:数据分类基础 (李飞飞斯坦福计算机视觉课程)
目录
数据驱动方法
第一个分类器:最近邻分类器(Nearest Neighbor)
计算机如何比较两张图片的差别(L1距离比较法)
KNN(K值最近邻算法)
关于L1和L2范数
超参数
如何在实验中选择合适的超参数
KNN在图像分类中不被使用的原因
KNN概要(中英版)
计算机存储图片(RGB模式)
数据驱动方法
使用具有不同类别和标签的数据集,然后使用机器学习去训练一个分类器,使用该分类器去识别新的图片。
训练数据集会会给定类别和对应的类别标签,分类器要识别的类从可以选的标签中进行选择
第一个分类器:最近邻分类器(Nearest Neighbor)
def train(images,labels):
#一系列机器学习算法
return model
def predict(model,test_images):
#使用训练好的模型去预测标签
return test_labels需要识别的图片从与他最相近的图片处复制标签,即图片的类别与其长得最像的图片标签相同。
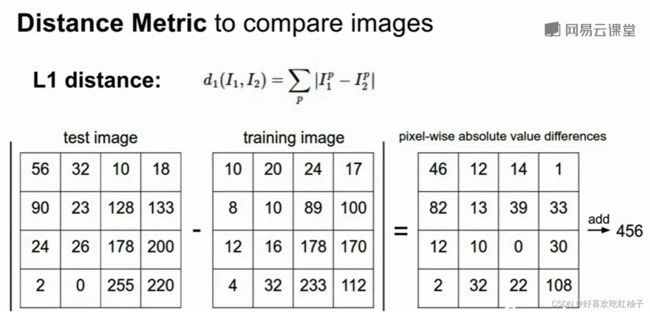
如何计算两个图片的差值?
计算机如何比较两张图片的差别(L1距离比较法)
使用L1距离,每个测试图片像素点和训练图片像素点的插值的总和
缺点:
- 训练时间短,我们只需要存储数据即可,时间复杂度为O(1)
- 预测时间很长,需要把预测图片与数据集中的每一个图片都进行比较,O(N)
- 会出现一个点影响一整片区域的情况
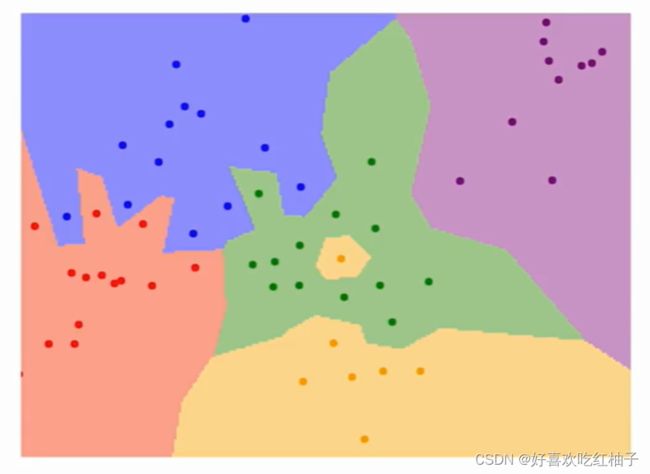
基于此,提出了KNN
KNN(K值最近邻算法)
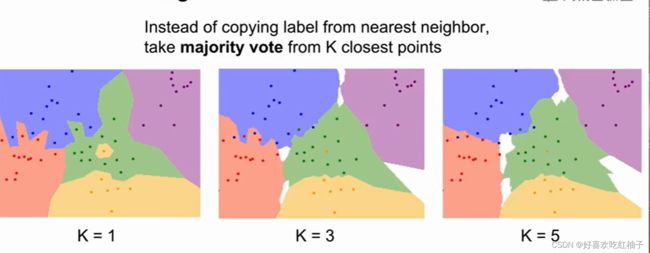
从距离最近的K个点进行投票, 在这些相邻点中进行投票,根据投票多的点来得出预测结果。
该算法的思想是: 一个样本与数据集中的k个样本最相似, 如果这k个样本中的大多数属于某一个类别, 则该样本也属于这个类别。
(63条消息) 机器学习之KNN(k近邻)算法详解_平原2018的博客-CSDN博客_knn
我们可以看出,取不同的K值对图像分类的效果不同,当K=5时,图像分类的边缘更加平滑,分类效果更好,而且不容易受单一像素点的干扰。
课程提供的KNN效果演示:
vision.stanford.edu/teaching/cs231n-demos/knn/
关于L1和L2范数
- L1范数是指向量中各个元素绝对值之和,对向量具有比较强的依赖性
- L2范数是指向量各元素的平方和然后求平方根,可以防止过拟合



超参数

超参数的选择是依赖于具体问题的,需要通过实验去测试选择超参数
如何在实验中选择合适的超参数
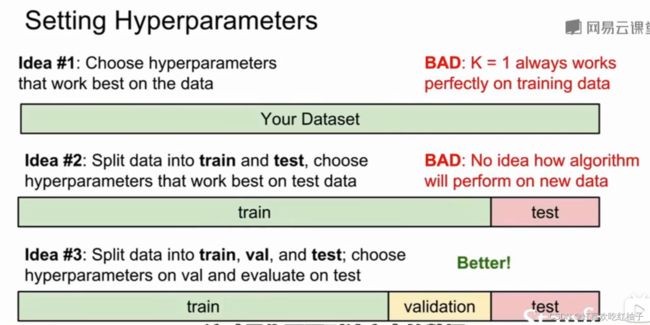
一般我们把数据集分为三部分:训练集、验证集和测试集,首先我们在训练集中选择不同的超参数进行实验,选出效果最好的超参数组,在验证集上进行验证,然后再把该组超参数放在测试集中使用,得出最终结果。
(63条消息) 训练集、验证集、测试集以及交验验证的理解_Kieven2oo8的博客-CSDN博客_验证集
- 训练集(train set) —— 用于模型拟合的数据样本。
- 验证集(validation set)—— 是模型训练过程中单独留出的样本集,它可以用于调整模型的超参数和用于对模型的能力进行初步评估。 通常用来在模型迭代训练时,用以验证当前模型泛化能力(准确率,召回率等),以决定是否停止继续训练。
一个形象的比喻:
训练集-----------学生的课本;学生 根据课本里的内容来掌握知识。
验证集------------作业,通过作业可以知道 不同学生学习情况、进步的速度快慢。
测试集-----------考试,考的题是平常都没有见过,考察学生举一反三的能力。
传统上,一般三者切分的比例是:6:2:2,验证集并不是必须的。
KNN在图像分类中不被使用的原因
- 时间长,效率低
- 向量化的距离函数(如L1、L2)不适合表达图像之间视觉的相似度(比如但图像整体向下平移或者变化颜色时,距离函数就会得到整体不同的值

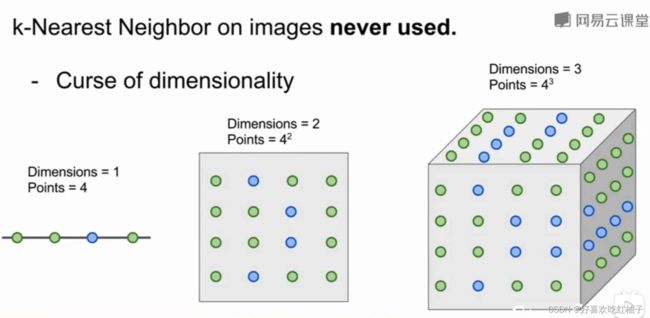
3. 维度灾难:需要指数级别的数据量
KNN分类器需要样本空间分成几部分来进行数据的训练,验证和测试,想要KNN分类器表现效果好,那么我们需要让训练数据能够密集的分布在样本空间中,一维时需要4个点覆盖整个空间,二维需要4*4个点,三维需要4*4*4个点,因此维度越高我们需要的数据就越多,因此会造成所需数据的指数级爆炸增长
KNN概要(中英版)
- In image classification, we start with a training set of images and labels, and must predict labels on the test set.
在图像分类中,我们在训练集中提供图像和标签,然后在测试集中预测图像的标签
- The K-Nearest Neighbors classifier predict labels based on nearest training examples.
在K最近邻分类器中基于K个最相近的训练集图像的标签来预测测试集图片的标签
- Distance metric and K are hyperparameters.
距离测度和K值是超参数
- Choose hyperparameters using the validation set; only run on the test set once at the very end.
使用验证集选择合适的超参数,选择出最合适的超参数后再在测试集上运行一次,得出最后的测试结果。
计算机存储图片(RGB模式)
计算机在看图片时,看到的是一个像素矩阵,长乘宽乘3,rgb三基色。
rgb模式的原理就是通过一个二维数组来记录每个像素点的位置,每个像素点都有rgb三个属性值用来记录对应的数值(实际上应该是一个三维数组)