第十三届蓝桥杯C/C++省赛B组试题解析
一、AcWing 4402. 刷题统计
【题目描述】
小明决定从下周一开始努力刷题准备蓝桥杯竞赛。
他计划周一至周五每天做 a a a道题目,周六和周日每天做 b b b道题目。
请你帮小明计算,按照计划他将在第几天实现做题数大于等于 n n n题?
【输入格式】
输入一行包含三个整数 a , b a,b a,b和 n n n。
【输出格式】
输出一个整数代表天数。
【数据范围】
对于 50 % 50\% 50%的评测用例, 1 ≤ a , b , n ≤ 1 0 6 1≤a,b,n≤10^6 1≤a,b,n≤106。
对于 100 % 100\% 100%的评测用例, 1 ≤ a , b , n ≤ 1 0 18 1≤a,b,n≤10^{18} 1≤a,b,n≤1018。
【输入样例】
10 20 99
【输出样例】
8
【分析】
每七天一循环,令 s = 5 a + 2 b s=5a+2b s=5a+2b,表示一周可以刷的题数,那么 n / s n/s n/s即为所需的周数, n % s n\% s n%s即为经过 n / s n/s n/s周后还剩的题数,那么再模拟一下一周的七天即可。
【代码】
#include 二、AcWing 4403. 修剪灌木
【题目描述】
爱丽丝要完成一项修剪灌木的工作。
有 N N N棵灌木整齐的从左到右排成一排。
爱丽丝在每天傍晚会修剪一棵灌木,让灌木的高度变为 0 0 0厘米。
爱丽丝修剪灌木的顺序是从最左侧的灌木开始,每天向右修剪一棵灌木。
当修剪了最右侧的灌木后,她会调转方向,下一天开始向左修剪灌木。
直到修剪了最左的灌木后再次调转方向。
然后如此循环往复。
灌木每天从早上到傍晚会长高 1 1 1厘米,而其余时间不会长高。
在第一天的早晨,所有灌木的高度都是 0 0 0厘米。爱丽丝想知道每棵灌木最高长到多高。
【输入格式】
一个正整数 N N N,含义如题面所述。
【输出格式】
输出 N N N行,每行一个整数,第 i i i行表示从左到右第 i i i棵树最高能长到多高。
【数据范围】
对于 30 % 30\% 30%的数据, N ≤ 10 N≤10 N≤10。
对于 100 % 100\% 100%的数据, 1 < N ≤ 10000 1
【输入样例】
3
【输出样例】
4
2
4
【分析】
对于第 i i i棵树,有两种情况:第一种是从 i i i的左边修剪到 i i i,然后继续向右修剪,到右端点后再向左修剪到 i i i,那么 i i i长的高度为 2 ∗ ( n − i ) 2*(n-i) 2∗(n−i);第二种是从 i i i的右边修剪到 i i i,然后继续向左修剪,到左端点后再向右修剪到 i i i,那么 i i i长的高度为 2 ∗ ( i − 1 ) 2*(i-1) 2∗(i−1)。
假设第一棵树的坐标为 1 1 1,那么第 i i i棵树能长的最大高度即为 m a x ( i − 1 , n − i ) ∗ 2 max(i-1,n-i)*2 max(i−1,n−i)∗2。
【代码】
#include 三、AcWing 4404. X 进制减法
【题目描述】
进制规定了数字在数位上逢几进一。
X进制是一种很神奇的进制,因为其每一数位的进制并不固定!
例如说某种X进制数,最低数位为二进制,第二数位为十进制,第三数位为八进制,则X进制数 321 321 321转换为十进制数为 65 65 65。
现在有两个X进制表示的整数 A A A和 B B B,但是其具体每一数位的进制还不确定,只知道 A A A和 B B B是同一进制规则,且每一数位最高为 N N N进制,最低为二进制。
请你算出 A − B A-B A−B的结果最小可能是多少。
请注意,你需要保证 A A A和 B B B在X进制下都是合法的,即每一数位上的数字要小于其进制。
【输入格式】
第一行一个正整数 N N N,含义如题面所述。
第二行一个正整数 M a M_a Ma,表示X进制数 A A A的位数。
第三行 M a M_a Ma个用空格分开的整数,表示X进制数 A A A按从高位到低位顺序各个数位上的数字在十进制下的表示。
第四行一个正整数 M b M_b Mb,表示X进制数 B B B的位数。
第五行 M b M_b Mb个用空格分开的整数,表示X进制数 B B B按从高位到低位顺序各个数位上的数字在十进制下的表示。
请注意,输入中的所有数字都是十进制的。
【输出格式】
输出一行一个整数,表示X进制数 A − B A-B A−B的结果的最小可能值转换为十进制后再模 1000000007 1000000007 1000000007的结果。
【数据范围】
对于 30 % 30\% 30%的数据, N ≤ 10 N≤10 N≤10, M a , M b ≤ 8 M_a,M_b≤8 Ma,Mb≤8, A ≥ B A≥B A≥B。
对于 100 % 100\% 100%的数据, 2 ≤ N ≤ 1000 2≤N≤1000 2≤N≤1000, 1 ≤ M a , M b ≤ 100000 1≤M_a,M_b≤100000 1≤Ma,Mb≤100000, A ≥ B A≥B A≥B。
【输入样例】
11
3
10 4 0
3
1 2 0
【输出样例】
94
【样例解释】
当进制为:最低位 2 2 2进制,第二数位 5 5 5进制,第三数位 11 11 11进制时,减法得到的差最小。
此时 A A A在十进制下是 108 108 108, B B B在十进制下是 14 14 14,差值是 94 94 94。
【分析】
假设 A , B A,B A,B位数的最大值为 m m m,不足 m m m位的高位补零,即: A = a m − 1 a m − 2 … a 0 , B = b m − 1 b m − 2 … b 0 A=a_{m-1}a_{m-2}\dots a_0,B=b_{m-1}b_{m-2}\dots b_0 A=am−1am−2…a0,B=bm−1bm−2…b0。再设每一位的进制分别为 p m − 1 , p m − 2 , … , p 0 p_{m-1},p_{m-2},\dots ,p_0 pm−1,pm−2,…,p0,则 A = a m − 1 ∏ i = 0 m − 2 p i + a m − 2 ∏ i = 0 m − 3 + ⋯ + a 0 A=a_{m-1}\prod_{i=0}^{m-2}p_i+a_{m-2}\prod_{i=0}^{m-3}+\dots +a_0 A=am−1∏i=0m−2pi+am−2∏i=0m−3+⋯+a0, B = b m − 1 ∏ i = 0 m − 2 p i + b m − 2 ∏ i = 0 m − 3 + ⋯ + b 0 B=b_{m-1}\prod_{i=0}^{m-2}p_i+b_{m-2}\prod_{i=0}^{m-3}+\dots +b_0 B=bm−1∏i=0m−2pi+bm−2∏i=0m−3+⋯+b0。
设 a i − b i = d i a_i-b_i=d_i ai−bi=di,则 A − B = A = d m − 1 ∏ i = 0 m − 2 p i + d m − 2 ∏ i = 0 m − 3 + ⋯ + d 0 A-B=A=d_{m-1}\prod_{i=0}^{m-2}p_i+d_{m-2}\prod_{i=0}^{m-3}+\dots +d_0 A−B=A=dm−1∏i=0m−2pi+dm−2∏i=0m−3+⋯+d0。对于 p i p_i pi,只有第 i + 1 i+1 i+1位到第 m − 1 m-1 m−1位包括 p i p_i pi,因此对所有包含 p i p_i pi的项进行整理后得: ( d m − 1 ∏ k = i + 1 m − 2 p k + d m − 2 ∏ k = i + 1 m − 3 p k + ⋯ + d i + 1 ) ∗ p i ∗ p i − 1 ∗ ⋯ ∗ p 0 (d_{m-1}\prod_{k=i+1}^{m-2}p_k+d_{m-2}\prod_{k=i+1}^{m-3}p_k+\dots +d_{i+1})*p_i*p_{i-1}*\dots *p_0 (dm−1∏k=i+1m−2pk+dm−2∏k=i+1m−3pk+⋯+di+1)∗pi∗pi−1∗⋯∗p0。
显然 p i ∗ p i − 1 ∗ ⋯ ∗ p 0 > 0 p_i*p_{i-1}*\dots *p_0>0 pi∗pi−1∗⋯∗p0>0,剩余的项为 A − B A-B A−B的前缀(第 i + 1 i+1 i+1位到第 m − 1 m-1 m−1位),由于 A > B A>B A>B,因此 A A A的前缀一定大于等于 B B B的前缀,所以上式的结果大于等于 0 0 0,要使得结果尽可能小,则 p i p_i pi应取最小值,即 m a x ( a i + 1 , b i + 1 , 2 ) max(a_i+1,b_i+1,2) max(ai+1,bi+1,2)。
【代码】
#include 四、AcWing 4405. 统计子矩阵
【题目描述】
给定一个 N × M N×M N×M的矩阵 A A A,请你统计有多少个子矩阵(最小 1 × 1 1×1 1×1,最大 N × M N×M N×M)满足子矩阵中所有数的和不超过给定的整数 K K K?
【输入格式】
第一行包含三个整数 N , M N,M N,M和 K K K。
之后 N N N行每行包含 M M M个整数,代表矩阵 A A A。
【输出格式】
一个整数代表答案。
【数据范围】
对于 30 % 30\% 30%的数据, N , M ≤ 20 N,M≤20 N,M≤20。
对于 70 % 70\% 70%的数据, N , M ≤ 100 N,M≤100 N,M≤100。
对于 100 % 100\% 100%的数据, 1 ≤ N , M ≤ 500 1≤N,M≤500 1≤N,M≤500, 0 ≤ A i j ≤ 1000 0≤A_{ij}≤1000 0≤Aij≤1000, 1 ≤ K ≤ 250000000 1≤K≤250000000 1≤K≤250000000。
【输入样例】
3 4 10
1 2 3 4
5 6 7 8
9 10 11 12
【输出样例】
19
【样例解释】
满足条件的子矩阵一共有 19 19 19,包含:
- 大小为 1 × 1 1×1 1×1的有 10 10 10个。
- 大小为 1 × 2 1×2 1×2的有 3 3 3个。
- 大小为 1 × 3 1×3 1×3的有 2 2 2个。
- 大小为 1 × 4 1×4 1×4的有 1 1 1个。
- 大小为 2 × 1 2×1 2×1的有 3 3 3个。
【分析】
本题如果使用二维前缀和做时间复杂度为 O ( n 4 ) O(n^4) O(n4),能过 70 % 70\% 70%的数据。如果使用一维前缀和与双指针做法,那么时间复杂度为 O ( n 3 ) O(n^3) O(n3)。
我们先预处理出 s [ i ] [ j ] s[i][j] s[i][j]表示第 j j j列的前缀和,在枚举的时候我们只枚举行,将每一列的元素之和看成是一行中的一个数,假设当前枚举到第 i i i行与第 j j j行( j ≥ i j\ge i j≥i),如下图所示,然后我们再枚举矩形的右边界 r r r,由于所有元素均为非负的,因此对于每一个 r r r,满足区间和小于等于 k k k的最小的矩形左边界 l l l一定是随着 r r r的增加而单调递增的,对于每个 r r r,所能构造出的满足条件的子矩形即为 r − l + 1 r-l+1 r−l+1个。
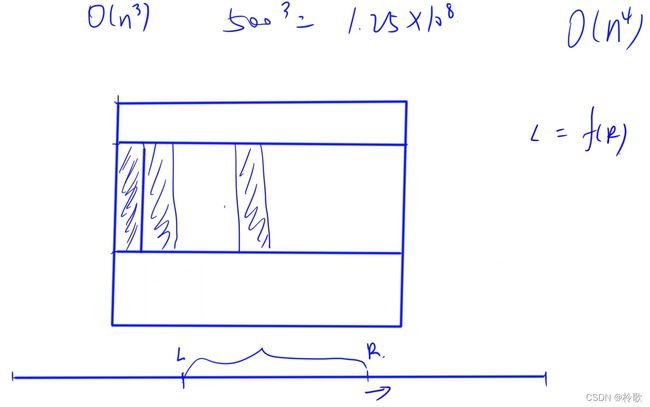
【代码】
#include 五、AcWing 4406. 积木画
【题目描述】
小明最近迷上了积木画,有这么两种类型的积木,分别为 I I I型(大小为 2 2 2个单位面积)和 L L L型(大小为 3 3 3个单位面积):

同时,小明有一块面积大小为 2 × N 2×N 2×N的画布,画布由 2 × N 2×N 2×N个 1 × 1 1×1 1×1区域构成。
小明需要用以上两种积木将画布拼满,他想知道总共有多少种不同的方式?
积木可以任意旋转,且画布的方向固定。
【输入格式】
输入一个整数 N N N,表示画布大小。
【输出格式】
输出一个整数表示答案。
由于答案可能很大,所以输出其对 1000000007 1000000007 1000000007取模后的值。
【数据范围】
1 ≤ N ≤ 1 0 7 1≤N≤10^7 1≤N≤107
【输入样例】
3
【输出样例】
5
【样例解释】
五种情况如下图所示,颜色只是为了标识不同的积木:

【分析】
状态表示: f [ i ] [ j ] f[i][j] f[i][j]表示已将前 i i i列填满且填了第 i + 1 i+1 i+1列 j j j个位置的方案数。
状态计算:
- 如果将第 i i i列填满且填了第 i + 1 i+1 i+1列 0 0 0个位置,那么有两种情况,一种是第 i i i列竖着放了一个 I I I型的积木,这样需要满足从第 i − 1 i-1 i−1列延伸出来的方块数量为 0 0 0,即 f [ i − 1 ] [ 0 ] f[i-1][0] f[i−1][0];另一种是第 i i i列已经被从第 i − 1 i-1 i−1列延伸出来的方块占满了,即 f [ i − 1 ] [ 2 ] f[i-1][2] f[i−1][2]。
- 如果将第 i i i列填满且填了第 i + 1 i+1 i+1列 1 1 1个位置,那么有两种情况,一种是第 i i i列放一个 L L L型的积木且突出的那一块朝向第 i + 1 i+1 i+1列,有两种摆法,这样需要满足从第 i − 1 i-1 i−1列延伸出来的方块数量为 0 0 0,即 2 ∗ f [ i − 1 ] [ 0 ] 2*f[i-1][0] 2∗f[i−1][0];另一种是第 i i i列已经被第 i − 1 i-1 i−1列延伸出来的方块占了一个位置,那么在剩下的那个位置横着放一块 I I I型的积木延伸到第 i + 1 i+1 i+1列,即 f [ i − 1 ] [ 1 ] f[i-1][1] f[i−1][1]。
- 如果将第 i i i列填满且填了第 i + 1 i+1 i+1列 1 1 1个位置,那么有两种情况,一种是第 i i i列横着放两个 I I I型的积木,这样需要满足从第 i − 1 i-1 i−1列延伸出来的方块数量为 0 0 0,即 f [ i − 1 ] [ 0 ] f[i-1][0] f[i−1][0];另一种是第 i i i列已经被第 i − 1 i-1 i−1列延伸出来的方块占了一个位置,那么在剩下的那个位置放一块 L L L型的积木,将第 i + 1 i+1 i+1列占满,即 f [ i − 1 ] [ 1 ] f[i-1][1] f[i−1][1]。
综上,状态转移方程为:
- f [ i ] [ 0 ] = f [ i − 1 ] [ 0 ] + f [ i − 1 ] [ 2 ] f[i][0]=f[i-1][0]+f[i-1][2] f[i][0]=f[i−1][0]+f[i−1][2];
- f [ i ] [ 1 ] = 2 ∗ f [ i − 1 ] [ 0 ] + f [ i − 1 ] [ 1 ] f[i][1]=2*f[i-1][0]+f[i-1][1] f[i][1]=2∗f[i−1][0]+f[i−1][1];
- f [ i ] [ 2 ] = f [ i − 1 ] [ 0 ] + f [ i − 1 ] [ 1 ] f[i][2]=f[i-1][0]+f[i-1][1] f[i][2]=f[i−1][0]+f[i−1][1]。
初始化:第 1 1 1列可以竖着放一个 I I I型积木,有一种放法,即 f [ 1 ] [ 0 ] = 1 f[1][0]=1 f[1][0]=1,可以放一个 L L L型积木,有两种放法,即 f [ 1 ] [ 1 ] = 2 f[1][1]=2 f[1][1]=2,可以横着放两个 I I I型积木,有一种放法,即 f [ 1 ] [ 2 ] = 1 f[1][2]=1 f[1][2]=1。
观察到每次状态转移只会涉及 i i i和 i − 1 i-1 i−1两个状态,因此可以将 f f f的第一维改为滚动数组。
【代码】
#include 六、AcWing 4407. 扫雷
【题目描述】
小明最近迷上了一款名为《扫雷》的游戏。
其中有一个关卡的任务如下:
在一个二维平面上放置着 n n n个炸雷,第 i i i个炸雷 ( x i , y i , r i ) (x_i,y_i,r_i) (xi,yi,ri)表示在坐标 ( x i , y i ) (x_i,y_i) (xi,yi)处存在一个炸雷,它的爆炸范围是以半径为 r i r_i ri的一个圆。
为了顺利通过这片土地,需要玩家进行排雷。
玩家可以发射 m m m个排雷火箭,小明已经规划好了每个排雷火箭的发射方向,第 j j j个排雷火箭 ( x j , y j , r j ) (x_j,y_j,r_j) (xj,yj,rj)表示这个排雷火箭将会在 ( x j , y j ) (x_j,y_j) (xj,yj)处爆炸,它的爆炸范围是以半径为 r j r_j rj的一个圆,在其爆炸范围内的炸雷会被引爆。
同时,当炸雷被引爆时,在其爆炸范围内的炸雷也会被引爆。
现在小明想知道他这次共引爆了几颗炸雷?
你可以把炸雷和排雷火箭都视为平面上的一个点。
一个点处可以存在多个炸雷和排雷火箭。
当炸雷位于爆炸范围的边界上时也会被引爆。
【输入格式】
输入的第一行包含两个整数 n , m n,m n,m。
接下来的 n n n行,每行三个整数 x i , y i , r i x_i,y_i,r_i xi,yi,ri,表示一个炸雷的信息。
再接下来的 m m m行,每行三个整数 x j , y j , r j x_j,y_j,r_j xj,yj,rj,表示一个排雷火箭的信息。
【输出格式】
输出一个整数表示答案。
【数据范围】
对于 40 % 40\% 40%的评测用例: 0 ≤ x , y ≤ 1 0 9 , 0 ≤ n , m ≤ 1 0 3 , 1 ≤ r ≤ 10 0≤x,y≤10^9,0≤n,m≤10^3,1≤r≤10 0≤x,y≤109,0≤n,m≤103,1≤r≤10。
对于 100 % 100\% 100%的评测用例: 0 ≤ x , y ≤ 1 0 9 , 0 ≤ n , m ≤ 5 × 1 0 4 , 1 ≤ r ≤ 10 0≤x,y≤10^9,0≤n,m≤5×10^4,1≤r≤10 0≤x,y≤109,0≤n,m≤5×104,1≤r≤10。
【输入样例】
2 1
2 2 4
4 4 2
0 0 5
【输出样例】
2
【样例解释】
示例图如下,排雷火箭 1 1 1覆盖了炸雷 1 1 1,所以炸雷 1 1 1被排除;炸雷 1 1 1又覆盖了炸雷 2 2 2,所以炸雷 2 2 2也被排除。
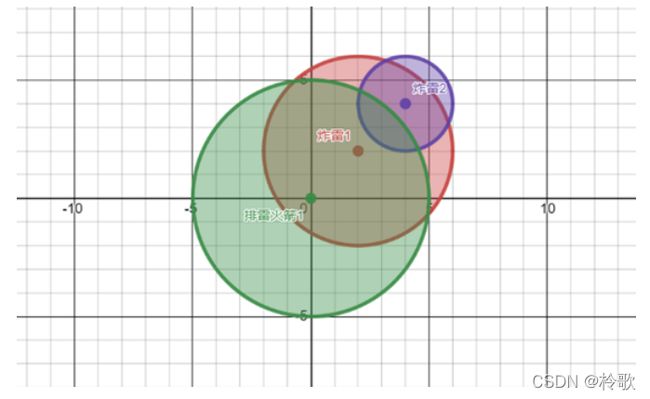
【分析】
首先可以将本题抽象成一个图论问题,如果排雷火箭或者炸雷 a a a爆炸后能够炸到炸雷 b b b,则连一条 a → b a→b a→b的有向边,所有的排雷火箭为起点,使用DFS或BFS遍历整个图求出能遍历到的炸雷的数量即为答案。由于是有向边,因此需要注意不能使用并查集求解。
本题的难点在于哈希,我们需要考虑怎么将这个图建出来,同一个点可能有多个炸雷。如果所有雷都在同一个点上,那么任意两点间都是有边的,对于 1 × 1 0 5 1\times 10^5 1×105个点,就需要建 1 × 1 0 10 1\times 10^{10} 1×1010条边,会爆空间和时间。所以在做这题时最好不要把图建出来。
首先我们如何判断某个点炸了之后能炸到哪些点呢?肯定不能遍历所有炸雷,不然会TLE。由于所有点的半径不会超过 10 10 10,因此每个点最多只会引爆三百多个点,那么我们可以直接枚举该点爆炸范围内的所有点,判断一下这个点上有没有炸雷。快速判断某个点有没有雷可以使用哈希表。
本题使用unordered_map无论存字符串还是存 l o n g l o n g long\ long long long都会被卡超时,因此我们需要手写一个哈希表。对于一个点 ( x , y ) (x,y) (x,y),可以使用公式 x ∗ ( 1 0 9 + 1 ) + y x*(10^9+1)+y x∗(109+1)+y将其唯一地映射成一个 l o n g l o n g long\ long long long值,我们将其当做 h a s h hash hash值。使用数组 h h h将 h a s h hash hash值转换成一个比较小的 i n t int int值,表示某个点;使用数组 i d id id表示某个点对应的炸雷编号是多少,如果同一个点有多个炸雷,那么我们只记录爆炸半径最大的那个炸雷;使用数组 s t st st表示某个点是否被引爆过。最后我们通过 D F S DFS DFS搜索出所有存在炸雷且会被引爆的点即可。
【代码】
#include 七、AcWing 4408. 李白打酒加强版
【题目描述】
话说大诗人李白,一生好饮。
幸好他从不开车。
一天,他提着酒壶,从家里出来,酒壶中有酒 2 2 2斗。
他边走边唱:
无事街上走,提壶去打酒。
逢店加一倍,遇花喝一斗。
这一路上,他一共遇到店 N N N次,遇到花 M M M次。
已知最后一次遇到的是花,他正好把酒喝光了。
请你计算李白这一路遇到店和花的顺序,有多少种不同的可能?
注意:壶里没酒( 0 0 0斗)时遇店是合法的,加倍后还是没酒;但是没酒时遇花是不合法的。
【输入格式】
第一行包含两个整数 N N N和 M M M。
【输出格式】
输出一个整数表示答案。由于答案可能很大,输出模 1000000007 1000000007 1000000007的结果。
【数据范围】
对于 40 % 40\% 40%的评测用例: 1 ≤ N , M ≤ 10 1≤N,M≤10 1≤N,M≤10。
对于 100 % 100\% 100%的评测用例: 1 ≤ N , M ≤ 100 1≤N,M≤100 1≤N,M≤100。
【输入样例】
5 10
【输出样例】
14
【样例解释】
如果我们用 0 0 0代表遇到花, 1 1 1代表遇到店, 14 14 14种顺序如下:
010101101000000
010110010010000
011000110010000
100010110010000
011001000110000
100011000110000
100100010110000
010110100000100
011001001000100
100011001000100
100100011000100
011010000010100
100100100010100
101000001010100
【分析】
状态表示: f [ i ] [ j ] [ k ] f[i][j][k] f[i][j][k]表示一共遇到 i i i个店, j j j朵花,且有 k k k斗酒的方案数。
状态计算:
- 如果最后遇到的为店,则上一个状态遇到的店的数量为 i − 1 i-1 i−1,花的数量为 j j j,且有 k / 2 k/2 k/2斗酒,即 f [ i ] [ j ] [ k ] = f [ i − 1 ] [ j ] [ k / 2 ] f[i][j][k]=f[i-1][j][k/2] f[i][j][k]=f[i−1][j][k/2]。需要满足 i > 0 i>0 i>0且 k % 2 = 0 k\% 2=0 k%2=0;
- 如果最后遇到的为花,则上一个状态遇到的店的数量为 i i i,花的数量为 j − 1 j-1 j−1,且有 k + 1 k+1 k+1斗酒,即 f [ i ] [ j ] [ k ] = f [ i ] [ j − 1 ] [ k + 1 ] f[i][j][k]=f[i][j-1][k+1] f[i][j][k]=f[i][j−1][k+1]。需要满足 j > 0 j>0 j>0。
初始化:一个店和一朵花都还没遇到的时候有 2 2 2斗酒的方案数为 1 1 1,即 f [ 0 ] [ 0 ] [ 2 ] = 1 f[0][0][2]=1 f[0][0][2]=1。
由于最后一步的转移一定是唯一的,遇到花且将酒全部喝完,因此最后一个状态的前一个状态为遇到了 n n n个店, m − 1 m-1 m−1朵花,酒的数量为 1 1 1斗,即 f [ n ] [ m − 1 ] [ 1 ] f[n][m-1][1] f[n][m−1][1]。
【代码】
#include 八、AcWing 4409. 砍竹子
【题目描述】
这天,小明在砍竹子,他面前有 n n n棵竹子排成一排,一开始第 i i i棵竹子的高度为 h i h_i hi。
他觉得一棵一棵砍太慢了,决定使用魔法来砍竹子。
魔法可以对连续的一段相同高度的竹子使用,假设这一段竹子的高度为 H H H,那么使用一次魔法可以把这一段竹子的高度都变为 ⌊ ⌊ H / 2 ⌋ + 1 ⌋ \lfloor \sqrt{\lfloor H/2\rfloor +1}\rfloor ⌊⌊H/2⌋+1⌋,其中 ⌊ x ⌋ \lfloor x\rfloor ⌊x⌋表示对 x x x向下取整。
小明想知道他最少使用多少次魔法可以让所有的竹子的高度都变为 1 1 1。
【输入格式】
第一行为一个正整数 n n n,表示竹子的棵数。
第二行共 n n n个空格分开的正整数 h i h_i hi,表示每棵竹子的高度。
【输出格式】
一个整数表示答案。
【数据范围】
对于 20 % 20\% 20%的数据,保证 1 ≤ n ≤ 1000 , 1 ≤ h i ≤ 1 0 6 1≤n≤1000,1≤h_i≤10^6 1≤n≤1000,1≤hi≤106。
对于 100 % 100\% 100%的数据,保证 1 ≤ n ≤ 2 × 1 0 5 , 1 ≤ h i ≤ 1 0 18 1≤n≤2×10^5,1≤h_i≤10^{18} 1≤n≤2×105,1≤hi≤1018。
【输入样例】
6
2 1 4 2 6 7
【输出样例】
5
【样例解释】
其中一种方案:
2 1 4 2 6 7
→ 2 1 4 2 6 2
→ 2 1 4 2 2 2
→ 2 1 1 2 2 2
→ 1 1 1 2 2 2
→ 1 1 1 1 1 1
共需要 5 5 5步完成。
【分析】
首先每棵竹子最多砍 6 6 6次其高度就会变成 1 1 1,因此我们可以先预处理出砍每棵竹子的高度变化过程,将初始高度记为最高层,每操作一次层数减一,高度为 1 1 1是第 0 0 0层,使用 f [ i ] [ j ] f[i][j] f[i][j]表示第 i i i棵竹子第 j j j层的高度,示意图如下图所示:

首先我们统计不考虑合并的情况下所有竹子砍到 1 1 1所需的总步数 r e s res res,并记下所有竹子中层数的最大值 m m m。高度相同且相邻的竹子可以合并,而高度相同的情况只可能在同一层中出现。由于需要求最少操作次数,因此根据贪心的思想如果相邻的竹子高度相同那么一定要合并,所以我们可以先枚举每一层 j j j,再枚举每一棵竹子 i i i,如果 f [ i ] [ j ] ≠ 0 f[i][j]\ne 0 f[i][j]=0,即第 i i i棵竹子在第 j j j层是存在的,且 f [ i ] [ j ] = f [ i − 1 ] [ j ] f[i][j]=f[i-1][j] f[i][j]=f[i−1][j],即和前一棵竹子在这层的高度相同,那么就可以合并起来一起砍,总操作次数可以减一次,即 r e s − − res-- res−−。最后的 r e s res res即为所需的最少的操作次数。
【代码】
#include