python数据分析前端招聘信息分析大作业
1.导入库 和数据表
#导入
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import re
import warnings
from pyecharts import options as opts
import numpy as np
#导入数据表
data=pd.read_excel('data.xlsx')2.查看表数据是否导入成功和审核数据
#查看
print(data.head(10))
#审核数据类型
print(data.dtypes)
#分析数据分布趋势
print(data.describe(include='all').round(2))3.查看重复值和去除重复值
#判断重复值
print(data[data.duplicated()])#获取查看缺失值列
na_records = data.isnull().any(axis=1) # 获取每行是否包含NA判断结果
print(na_records.sum()) # NA记录的总数量
print(na_records[na_records]==True) # NA记录的行号#清洗掉空格
raw_data=data.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
print(raw_data.head(10))


4.可视化
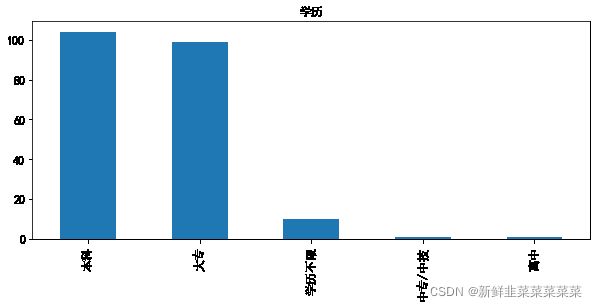
#可视化--柱状图--学历
#统计
education_data=raw_data.education.value_counts()
#学历 绘图
# 柱形图
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
education_data.plot(kind='bar', x='education', figsize=(10, 4),title='学历',fontsize=12)
plt.show()
#饼图
plt.figure(figsize=(12,12))
raw_data.education.value_counts().plot.pie(autopct='%2.0f%%')
plt.show()
#行业分布-饼图
plt.figure(figsize=(12,12))
raw_data.industryName.value_counts().plot.pie(autopct='%2.0f%%')
plt.show()
#经验需求
# 柱形图
workingExp_data=raw_data.workingExp.value_counts()
print(workingExp_data)
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
workingExp_data.plot(kind='bar', x='workingExp', figsize=(10, 4),title='经验',fontsize=12)
plt.show() 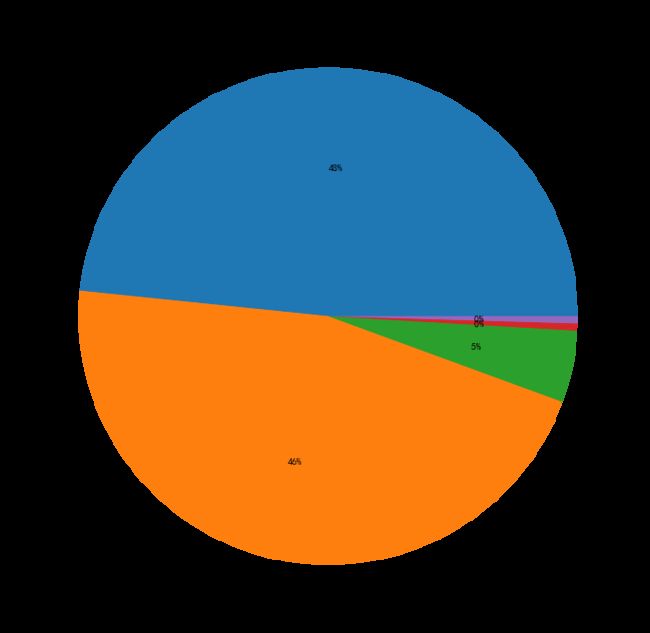
5。计算平均工资
因为所得工资是一个范围值5000-8000这样的数字,所以要先求一个平均数

# 总平均工资
mean = np.mean(raw_data.mean_salary)
print(mean)
#可视化--直方图--工资
raw_data.mean_salary.plot.hist()
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.ylabel('') #y轴
plt.xlabel('mean_salary') #x轴
plt.title('薪酬分布直方图')
plt.show()
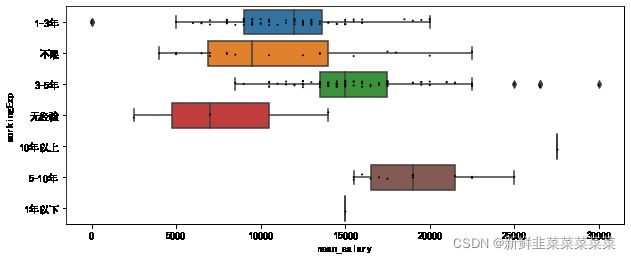
#经验-薪酬关系分布
#散点图
raw_data.plot(kind='scatter',x='mean_salary', y='workingExp', figsize=(10, 4),title='薪酬和工作经验关系')
#箱型图+散点图
plt.figure(figsize=(10,4))
sns.boxplot(x='mean_salary', y='workingExp', data=raw_data)
sns.stripplot(x='mean_salary', y='workingExp', data=raw_data, color='k', size=2)
词云
#云词
import pyecharts
from pyecharts.charts import WordCloud
#计算数量
skillLabel_data=raw_data.skillLabel.value_counts()
#先写入一个文件中
data_file = 'skillLabel.xlsx'
# 写入单个sheet到Excel
skillLabel_data.to_excel('skillLabel.xlsx')
# 读取源数据
data1=pd.read_excel('skillLabel.xlsx')
print(data1.head(3))
#处理为词云用的格式
wordcloud_data = data1.to_records(index=False).tolist()
# # 展示词云结果
wc = WordCloud()#实例化对象
wc.add("", wordcloud_data, word_size_range=[15, 1500])
wc.set_global_opts(title_opts=opts.TitleOpts(title="词云关键字展示"))
wc.render_notebook()