对抗生成网络(GAN)
目录
基本概念介绍
生成器(generator)
为什么需要输出一个分布
Generative Adversarial Network (GAN)
discriminator(鉴别器)
GAN的基本思想
计算分布距离与训练
计算 Divergence靠 Discriminator 的力量
从Objective Function到JS divergence
使用其他的divergence
JS divergence存在的问题
PG和Pdata重叠的范围很小
重叠部分少导致的问题
Wasserstein distance
Wasserstein distance概念
Wasserstein distance好处
计算方法和WGAN
GAN is still challenging
GAN for Sequence Generation
Conditional Generation(CGAN)
cycle GAN
实现方式
应用
生成器效能评估
图片质量:使用分类判别
图像的多样性
Mode Collapse
Mode Dropping
Mode Collapse与Mode Dropping的区别
如何衡量生成图片的多样性
Frechet Inception Distance (FID)
We don’t want memory GAN
总结
基本概念介绍
生成器(generator)
区别于之前给定x输出y的神经网络,现在给神经网络的输入添加一个从简单分布(Simple Distribution)中采的 sample,生成一个复杂的满足特定分布规律的输出(Complex Distribution)
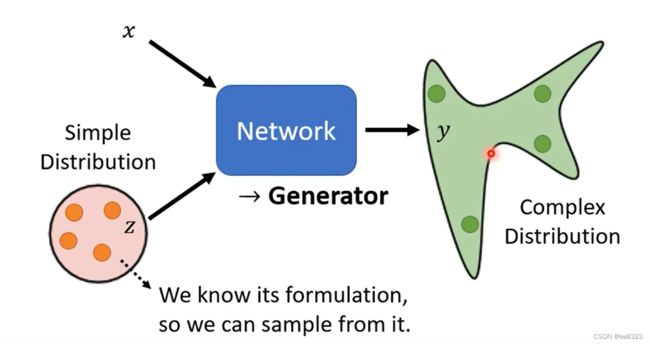
为什么需要输出一个分布
当我们的任务需要一点创造力的时候,一个输入有多种可能的输出,这些不同的输出都是对的,但又只需要输出一个对象,这时就需要使用generator,在网络中加入随机输入,让网络在复杂分布中随机选择一个对象输出(输出有几率的分布)。

Generative Adversarial Network (GAN)
GAN是众多generator中比较有代表性的一个,而GAN的种类也非常多,常常会出现重名的GAN和奇奇怪怪的GAN名字。
以unconditional generation(不考虑x,只考虑z)为例,假设Z是从一个normal distribution里采样出来的向量,通常会是一个low dimensional的向量,维度是你自己决定的,丢到generator裡面,输出一个非常高维的向量,希望是一个二次元人物的脸
 discriminator(鉴别器)
discriminator(鉴别器)
Discriminator也是一个神经网络(可以考虑使用CNN、transformer等),可以将generator输出的图像转换成数字,越接近于1,说明图像越真实,品质越高。

GAN的基本思想
generator和discriminator是对抗关系,discriminator通过真实的图像来监督generator的图形生成,两者不断相互进化。
1、随机初始化generator和discriminator。
2、固定generator不变,更新discriminator。
将generator产生的图像和数据库样本比较,让discriminator分辨二者之间的差异,把二者区分开。具体地说,就是 real ones 经过 D,输出值大(接近 1),generator 产生的数据 (generated ones) 经过 D,输出值小(接近 0)。该训练可以当作分类的问题来做(把样本当作类别1,Generator產生的图片当作类别2),也可以当作regression的问题来做(样本对应输出1,generator產生的图形对应输出0)

3、固定discriminator不变,更新generator。
从gaussian distribution采样作為generator输入,產生一个图片,把这个图片丢到Discriminator裡面,Discriminator会给这个图片一个分数,Generator训练的目标是要Discriminator的输出值越大越好,说明产生的“假”数据让 discriminator 误认为是真的
4、不断循环上述过程,直至产生很好的图像
实际中可以把 generator 和 discriminator 组成一个大的网络结构,如下图所示,前几层为 generator,后几层为 discriminator,中间 hidden Layer 的输出就是 generator 的输出,更新generator的时候就只更改前面几层,而更新discriminator的时候就只更改后面几层。
Generator 或 Discriminator每次只有一个在训练。训练时,所掌握的是对方上一轮训练的信息。其实这就像是双方每一次交手后,知道对方最新的技术水平,然后回去提升自己。精妙,但是对训练过程提出了更高要求:如果其中一个训练过程中某几步loss上升,就会对另一个的训练会产生负面影响,后者又可能会对前者产生负面影响,恶性循环,导致训练“坏掉”。

计算分布距离与训练
GAN 的训练目标:从给定简单的 Normal Distribution 采样的数据,经过 Generator,得到的输出分布PG,使其接近目标分布Pdata。于是要计算PG与Pdata这两个分布之间的距离,用Divergence表征,找一个genenrator尽量使Divergence小。
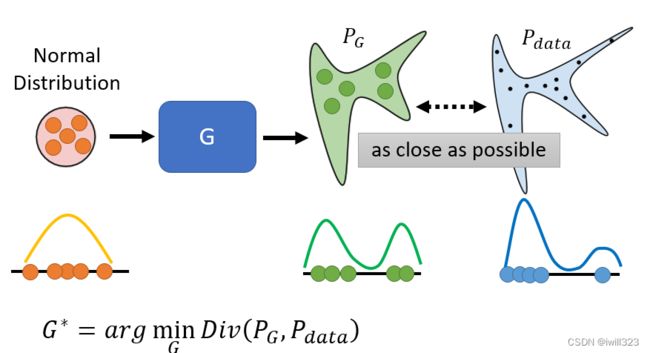
问题在于我们无法知道PG和Pdata的分布。GAN 告诉我们,不需要知道 PG 跟Pdata的分布具体长什麼样子,只要能从 PG 和 Pdata这两个分布中采样,就有办法算 Divergence。
关于采样:从数据库裡面随机采样一些图片出来,就得到 Pdata;从 Normal Distribution 裡面采样向量丢给 Generator,让 Generator 產生一堆图片出来,那这些图片就是从 PG采样出来的结果

计算 Divergence靠 Discriminator 的力量
Discriminator训练目标是看到Pdata给一个较高的分数,看到PG给一个比较低的分数。这个 Optimization 的问题如下(要Maximize 的东西叫 Objective Function,如果 Minimize 就叫它 Loss Function):

之所以写成这个样子,是因为在最开始设计时,希望在训练Discriminator时能够按照分类问题的方式考虑,事实上这个 Objective Function 就是 Cross Entropy 乘一个负号。Discriminator可以当做是一个分类器,它做的事情就是把从 Pdata 采样出来的真实 Image当作 Class 1,把从 PG 采样出来的假 Image当作 Class 2,训练这个 Binary Classifier 就等同於解了这一个 Optimization 的问题。
从Objective Function到JS divergence
(,)的最大值和JS divergence相关,详细的证明请参见 GAN 原始的 Paper。直观上也可以理解:如果Discriminator 很难分辨 PG 和 Pdata,没办法准确打分,那么Objective Function的最大值就比较小,所以小的 Divergence对应小的Max (,),反之假如PG 和 Pdata的 divergence大,Discriminator 很容易就把两者分开了,得到的Max (,)大。
本来,Generator的目标是使PG 和 Pdata的 JS divergence 尽量小

卡在不知道怎麼计算 Divergence。现在因为maxV(D, G)与divergence有关,所以可以用maxV(D, G)代替Div(PG, Pdata),这样就实现了不用了解PG和Pdata具体样貌即可计算divergence。
于是Generator的目标函数写成如下。

使用其他的divergence
改变objective function即V(D, G)就可以计算其他类型的divergence。这里有一篇文章https://arxiv.org/abs/1606.00709,会告诉你不同的divergence要怎样设计Objective Function

JS divergence存在的问题
PG和Pdata重叠的范围很小
大多数情况下,PG和Pdata重叠的范围很小。理由如下:
1、PG和Pdata在高维空间中时低维的形态
在高维空间裡面随便采样一个点,它通常都没有办法构成一个二次元人物的头像,所以二次元人物的头像的分布,在高维的空间中其实是非常狭窄的,除非PG 跟 Pdata 刚好重合,不然它们相交的范围几乎是可以忽略的
2、采样的数量可能不够多
也许 PG 跟 Pdata有非常大的 Overlap 的范围,但是在计算 PG和Pdata的 Divergence 的时候,从 Pdata和PG 裡面分布采样一些点出来,如果采样的点不够多、不够密,那么就算是这两个Distribution 实际上有重叠,对 Discriminator 来说,它也是没有重叠的
重叠部分少导致的问题
如果两个分布不重合,不管这两个分布长什麼样,他们计算出来的JS divergence永远都是log2,所以改变了generator之后,根本看不出generator有没有更好,永远无法进化generator。用 Binary Classifier当作 Discriminator,训练 GAN 的时候会发现,几乎每次训练完Discriminator 以后,正确率都是 100%。两组 Image 都是采样出来的,它硬背都可以得到100% 的正确率,
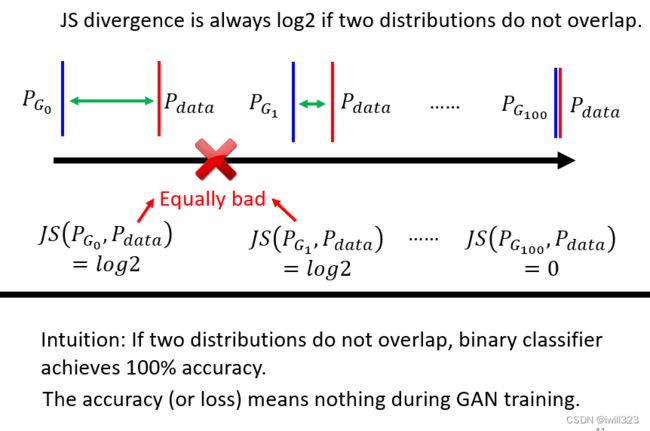
Wasserstein distance
Wasserstein distance概念
考虑换一种计算divergence的方法。把分布想象成一个小土堆,从土堆P 变换到土堆Q有很多种变换的方式,最小的平均移动距离(smallest average distance)就是Wasserstein distance

Wasserstein distance好处
假如我们能算出Wasserstein distance,与JS divergence相比,能看出改进之后的generator是否更好。这样,Generator 就可以根据结果来一点点提高。

计算方法和WGAN
WGAN就是用W distance取代JS distance的GAN
其中的D有限制条件:D必须要是一个 1-Lipschitz 的 Function,即D 不可以是变动很剧烈的 Function,必须要是一个足够平滑的 Function。
原因:W distance计算公式要求Pdata的 D(y) 越大越好,让 PG 的 D(y) 越小越好,所以在Pdata分布和PG分布没有任何重叠的地方,对于Pdata采样,Discriminator 会让D(y) = +∞,对于PG采样, Discriminator 会让D(y) = -∞,算出来的Maximum 值都是无限大,训练中学不到东西。1-Lipschitz限制条件让曲线要连续而不能剧烈变化,保证真实与生成之间的差异不太大,于是它们不会都跑到无限大。
其中的1-lipschitz是怎么实现的呢?有以下三种主要方式:

- Train Network 的时候,参数要求在 C跟 -C 之间,用 Gradient Descent Update 后,如果超过 C,设為 C,小於 -C,就直接设為 -C。这个方法并不一定真的能够让 Discriminator变成 1-Lipschitz Function
- Improved WGAN是指,从PG中取一个点,从Pdata中取一个点,两个点连线中间取一个点,让这个点的梯度为1,具体为什么这么做,见原始论文。
- 还有一种是谱归一化(Spectral Normalization)的方式,具体也是见原始论文
GAN is still challenging
虽然说已经有 WGAN,但GAN 的训练仍然不是一件容易的事情。Generator 跟 Discriminator是互相砥砺才能互相成长的,只要其中一者发生什麼问题停止训练,另外一者就会跟著停下训练。假设在训练Discriminator 的时候一下子没有训练好,Discriminator 没有办法分辨真的跟產生出来的图片的差异,那么 Generator就失去了可以进步的目标,没有办法再进步了。如果 Generator 没有办法再进步,它没有办法再產生更真实的图片,那么 Discriminator 就没有办法再跟著进步了。
训练过程中没有办法保证 Loss 就一定会下降,如果有一次没有下降,就会出现连锁反应,整个结构都不再改进。要让 Network训练起来,往往需要调一下 Hyperparameter

Train GAN 的诀窍有关的文献:
GAN for Sequence Generation
最难的是拿 GAN 来生成文字。如果要生成一段文字,可以把 Transformer 的 Decoder 部分看成是 GAN 的 Generator,生成的 sequence 送入 Discriminator 中判断是不是真的文字

真正的的难点在於,如果要用 Gradient Descent去训练Decoder,会发现loss 没办法做微分。
如果Decoder 的参数有一点小小的变化,那么它现在输出的这个 Distribution也会有小小的变化,Generator 的输出是取概率最大的那个Token(Token是產生一个句子的单位), 会发现概率最大的那个 Token没有改变,那对 Discriminator 来说,它输出的就没有改变,所以没有办法算微分,也就没有办法做 Gradient Descent。

一篇 Paper 叫做 ScrachGAN,可以直接从随机的初始化参数开始Train 它的 Generator,然后让 Generator 產生文字,最关键的就是爆调 Hyperparameter,跟一大堆的 Tips
Conditional Generation(CGAN)
unconditional generation 产生的图片天马行空,可能不是我们想要的,所以要加入一些限制条件x,操控 Generator 的输出。

unconditional generation 是不需要标注的,这里的 conditional GAN 则需要一些标注,也就是说引入了有监督学习。这也好理解,既然对机器产生的数据有一定要求,肯定要有示例告诉机器应该怎么做。

以文字生成图片 (Text-to-image) 为例,Discriminator 的输入为带有标签的图片(paired image)。标签要有多样性,这样条件式生成器的效果才好。Discriminator 的训练目标是:输入为(文字,对应的训练图片)时,输出为 1;输入为(文字,生成的图片)时,输出为 0。除此之外,还需要一种 negative sample:(文字,不对应的训练图片),输出为 0。如下图所示:

更多应用例子:
1.Image translation (pix2pix),比如:黑白到彩色,白天景物到夜景,轮廓素描到实物图。

例如:从建筑结构图到房屋照片的转换效果如下图所示,如果用 supervised learning,得到的图片很模糊,为什么?因为一个建筑结构图对应有多种房屋外形,Generator学到的就是把不同的可能平均起来,结果变成一个模糊的结果。如果用 GAN,机器有点自由发挥了,房屋左上角有一个烟囱或窗户的东西。而用 GAN+supervised,也就是 conditional GAN,生成的图片效果就很好。

2.sound-to image:从声音生成相应的图片,比如输入水声,生成溪流图片。
3.talking head generation:静态图转动态,让照片里的人物动起来。
cycle GAN
实际中,常常有大量未标注数据,怎么利用上这部分数据呢?有一个方法是 semi-supervised learning,只需要少量标注数据,未标注数据可以用模型标注 (pseudo label)。但是尽管是少量,还是要用标注数据来训练模型,否则模型效果不好,标注也不好。
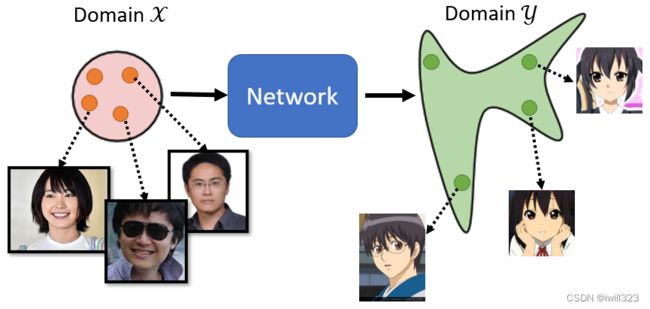
有的时候连一点标注数据都没有,例如图像风格转换,假设我们有一些人脸图片,另外有一些动漫头像,两者没有对应关系,也就是 unpaired data,如下图所示。Cycle GAN 就是为了解决这个问题。
实现方式
与前面介绍的 GAN 不同,Cycle GAN 的输入不是从 Gaussian Distribution 采样,而是从 original data 采样,生成动漫头像图片,如下图所示:

如果我们完全只套用一般的GAN的做法,显然是不够的,因為discriminator只会鉴别y是不是二次元图片,训练出来的generator可以產生二次元人物的头像,但是跟输入的真实的照片没有什麼特别的关係。又不能用 conditional GAN 来做,因為在conditional GAN裡面是有成对的资料

Cycle GAN 增加了一个generator,把生成的动漫图片再变换到人物图片,训练使生成的人物图片与原图尽量接近,以此达到了原图和生成动漫头像的对应。怎麼让两张图片越接近越好呢?两张图片就是两个向量,这两个向量之间的距离越接近,两张图片就越像,叫做Cycle consistency


可能会有的一个问题就是,Cycle GAN只保证有一些关係,也许机器会学到很奇怪的转换(比如将图像左右翻转),反正只要第二个generator可以转得回来就好了,怎么确保这个关係是我们要的呢。目前没有什麼特别好的解法。但是在真实的实作上,即使没有用cycle的普通GAN,训练出来的结果也还是不错,输入跟输出往往非常像(因为模型很懒,不想改动太多)
此外,还可以反向训练,从动漫图片到人物图片,再到动漫图片,依然要让输入跟输出越接近越好。要训练一个discriminator,看一张图片像不像是真实人脸。训练 Cycle GAN 时可以两个方向同时训练。

Cycle GAN、Disco GAN、Dual GAN是一样的,不同研究团队在同一时间提出,因此有不同命名。

效果

应用
可以做影像风格转换的版本,叫做StarGAN,可以在多种风格间做转换
Text Style Transfer:把消极的文字都转换为积极的文字

有很多长的文章和另外一堆摘要,这些摘要不是这些长的文章的摘要,是不同的来源,让机器学习文字风格的转换,可以让机器学会把长的文章变成简短的摘要,让它学会怎麼精简的写作,把长的文章变成短的句子
unsupervised的翻译,收集一堆英文的句子,一堆中文的句子,没有任何成对的资料,用Cycle GAN做,机器学会把中文翻成英文
非督导式的语音辨识,机器只听了一堆声音,这些声音没有对应的文字,机器上网爬一堆文字,这些文字没有对应的声音,用Cycle GAN做,看看机器有没有办法把声音转成文字

生成器效能评估
对于监督学习,模型输出可以和 label 比对,而 Generator 生成的图片与原来的图片相似但不相同,怎么去判断呢
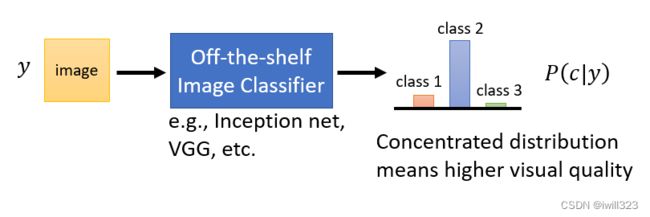
图片质量:使用分类判别
输入图片y,经过图片分类系统Classifier,得出一个概率分布P(c|y),虽然我们不知道產生的图片裡面有什麼东西,但是如果概率分布集中在某个类别,说明 Classifier 对于输出的类别很确定,也许是比较接近真实的图片,所以Classifier才辨识得出来,也就是这张图片质量好。如果概率分布平均,说明Classifier 不太确定看到的图片属于哪个类别,Generator 生成的图片可能是一个四不像,质量不佳,故而Classifier 都认不出这是什么。
图像的多样性
Mode Collapse
只采用P(c|y)评估方法则会产生Mode Collapse问题,即生成的分布只学习到真实分布的很小一部分。当 Generator 產生可以骗过Discriminator图片以后,它就可以反复地生成这种图片来骗过Discriminator,最后发现生成的图片里面有很多同一张脸,只是有头发等细节的微小变化而已,造成了多样性的降低。
解决:在训练Generator的时候,一路上都会把Model的checkpoint 存下来,在 Mode Collapse 之前把训练停下来,然后就把之前的 Model 拿出来用

Mode Dropping
產生出来的资料只有真实资料的一部分,单纯看產生出来的资料,可能会觉得还不错,而且它的多样性也够,但真实的资料的多样性的分布其实是更大的。比如下图,人的多样性也有,但还是远小于实际上人的多样性,因为产生的人脸总是这么几十个人,每一个训练轮次之间只是有肤色等整体细节的细微差别而已。

Mode Collapse与Mode Dropping的区别
前者是针对一张图片而言的,generator针对一张真实图片反复生成能骗过discriminator的图片;后者是针对一堆图片而言,generator针对几十张真实图片反复生成能骗过discriminator的图片。但两者都是多样性问题。
如何衡量生成图片的多样性
每一张照片经过图片辨识系统后Classifier,会产生几率分布,也就是图片是属于哪一类。把一组 generated data 输入Classifier,将这些几率分布做平均,用P(y)表示。如果P(y)非常集中,就代表现在多样性不够,如果平均之后的分布平坦,表明图片的多样性足够了。


疑问:为什么前面 Quality of Image 说要概率分布集中在某个类别好,这里 Diversity 又说要概率分布均匀好,这不是互相矛盾吗?
看 Quality of Image 时,Classifier 的输入是一张图片。看 Diversity 时,Classifier 的输入是 Generater 生成的所有图片,对所有的输出取平均来衡量。
Inception Score (IS) 就是结合了 Quality of Image 和 Diversity。Quality 高,Diversity 大,对应的 IS 就大。
Frechet Inception Distance (FID)
而对于作业中的生成二次元人物头像图片,不能用 Inception Score,因为都是人脸图片,Classifier 都识别为一类,因此 Diveristy 不高。
用 Frechet Inception Distance (FID)。FID与IS的区别是,IS是采用图片分类的分布情况来评估,而FID不取最后的类别,而是取在决定这个类别之前的一个高维向量(即 Softmax 的输入)来评估。下图中的红点代表:真实图片的Hidden Layer输出,蓝点代表:生成图片的Hidden Layer
输出。假设这两个分布都是高斯分布,计算出两者之间的Frechet Distance就行了,越小越好

We don’t want memory GAN
有时生成图片的 Quality 和 FID 都不错,可是你看图片总觉得哪里不对,比如下图中第二行的图片:

和训练图片 (real data) 一对比,发现机器学到的是和训练图片一模一样。
应对方法:把 generated data 和 real data 计算相似度,看是不是一样。
新的问题:机器可能会学到把训练图片左右反转一下,如图中第三行图片所示,计算相似度是不同,其实还是原图片。
所以说,衡量 Generative Model 的好坏挺难的。https://arxiv.org/abs/1802.03446裡面列举了
二十几种GAN Generator 的评估的方式

总结

参考:
李宏毅机器学习笔记05 GAN - 知乎
李宏毅老师《机器学习》课程笔记-6 GAN - 知乎
Conditional Generation