python易忘 自用小甲鱼笔记
1.字符串.format
'{0:9=10}'.format(520)
#0表示format第0个参数,9表示用9填充,10表示宽度为10,=表示符号之后,数字之前
Out[150]: '9999999520'
'{0:9^10}'.format(520)#^表示居中,<表示靠左,>表示靠右
Out[151]: '9995209999'
'{0:^10}'.format(520)#默认用空格填充
Out[153]: ' 520 '2集合的运算
#交集
s={1,2}
s.intersection_update({1,3})
s
Out[409]: {1}
#并集
s.update({2,3})
s
Out[411]: {1, 2, 3}
#差集 s-{2,5}
s.difference_update({2,5})
s
Out[414]: {1, 3}
#对称差集,并集-交集
s.symmetric_difference_update({1,4,5})
s
Out[416]: {3, 4, 5}3.可变容器不可哈希,不可变容器可哈希,函数hash返回对应的哈希值
4.![]()
/左边不可以使用关键字参数,右边才可以
![]()
左边都行,右边只能是关键字参数
5.函数参数,*x元胞类型收集参数 **x字典类型收集参数
6.legb作用域原则:l:local e:enclosed嵌套函数 g:global全局 b:bif:built in function内置函数
当发生冲突时候,python选择左边的。例外情况:l e nonlocal关键字,e g global关键字。
所以一定小心不要起一个变量名和bif一样,就会把bif毁掉
7.函数的递归!!!居然是这么用,比如说求阶乘
def niubi(n)
if n==1
return 1
else:
return n*niubi(n-1)甲鱼老师的,妙啊,当时学C语言就没有想到
def jie():
m = 1
def bi(n):
if n>1:
nonlocal m
m = m * n
n = n-1
bi(n)
return m
return bi我的,,,傻傻的
8.虽然说天才程序员用递归,但是迭代的效率居然更高
9.函数文档、类型注释
查看函数文档 help(函数名)
创建函数文档

类型注释:

:s后边的内容表示作者的期望类型
->后表示返回值类型
诸如此类:

如果希望python做检测 ,可以使用mypy插件需要安装,小甲鱼有教程
内省:自我检测的机制
获取名字:

类型注释的查看:
![]()
查看函数文档:

10.高阶函数:其他函数作为变量传入
为此搞了一个模块functools:
reduce()函数:

偏函数:类似于闭包,将多个参数分次传递
@wraps装饰器:装饰器装饰的函数名字会发生改变,有这个就不会改变(没彻底学会怎么用)
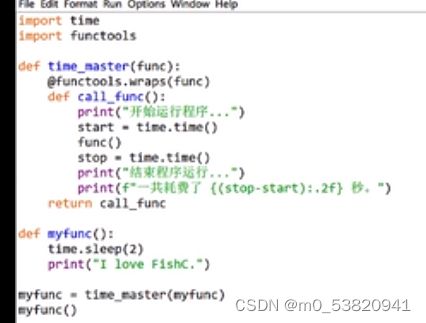
11.1永久存储(上)
速查宝典 open()
f = open('fish.txt','w') #当前目录下创建该文件,如果已经存在会清除内容。
#写内容
f.write('dfdf')
f.writelines({'fdjkf\n','dkfjs'})
#关闭文件后才会显示
f.close()
#想不关闭就显示
f.flush()
f = open('fish.txt','r+')#更新方式打开
f.readable()#判断是否可读
f.writable()#判断是否可写
#读取文件
f.read()
f.readline()
f.tell()#显示目前指针所在位置
f.seek()#设置指针位置
f.truncate(29)#只要前29个字符
11.2 永久存储(中):速查宝典pathlib os.path 拓展阅读:新旧路径处理模块大比拼
路径处理(win\与转义字符矛盾,需要换成/或\\)
以前常用模块os.path,现在用pathlib

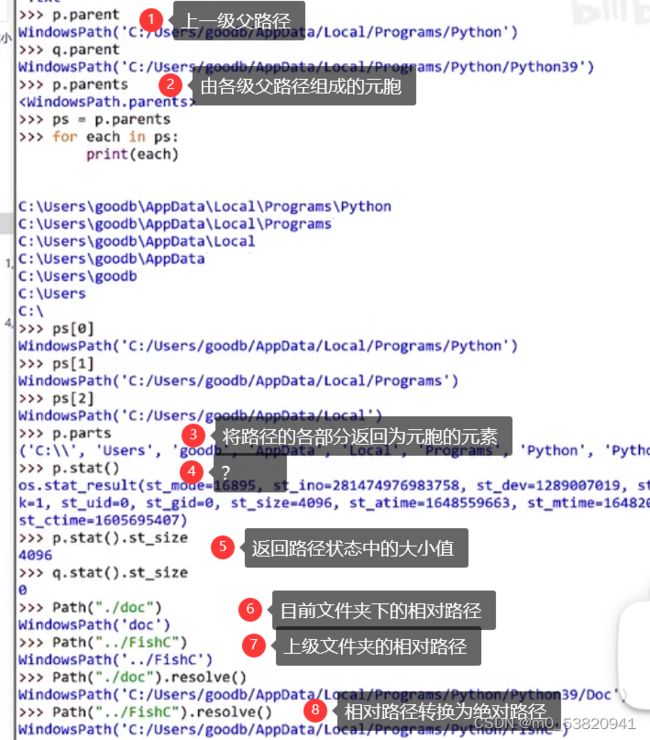
上图2好像不是元胞
4文件或文件夹的状态
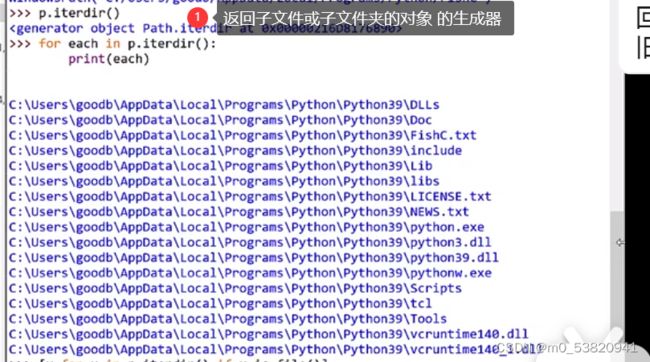
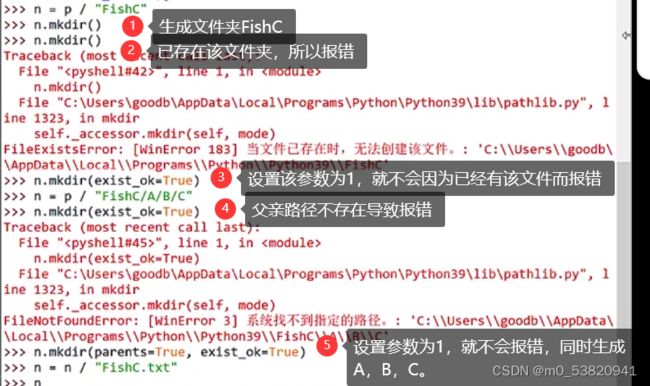
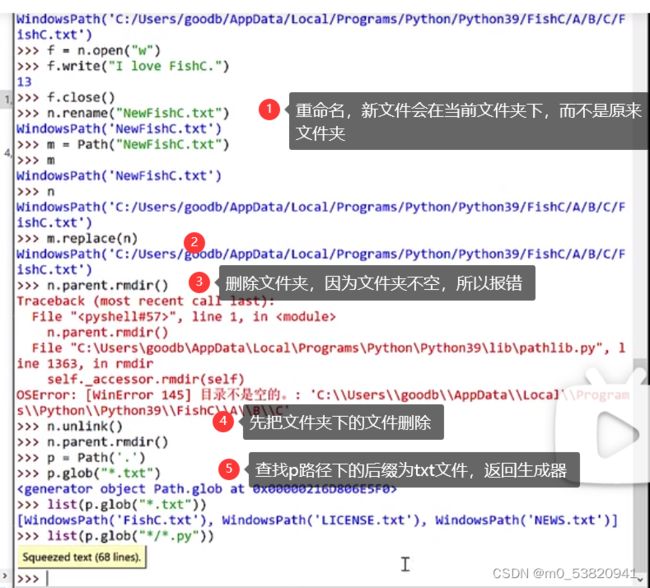
当前文件夹下*。![]()
当前目录下的下一级目录下的所有![]()
当前目录及所有子目录![]()
11.3
| 本节首先讲了with语句(上下文管理器),其为文件操作提供了一种更为优雅的操作方式,确保资源的释放,既省去了手动关闭文件的麻烦,还可避免程序出错时数据未能写入文件的悲哀。随后讲了pickle模块,其用于解决Python对象的永久存储问题,允许将字符串、列表、字典等Python对象序列化,保存为文件的形式。所谓序列化,就是将Python对象转换为二进制字节流的过程。pickle模块中的dump()函数可将Python对象写入扩展名为pkl的二进制文件,load()函数则用于读取二进制文件,将其还原为Python对象。因二进制文件无法被文本文件编辑器正常读取,这一过程有点类似于使用二进制对Python对象进行加密和解密,神奇又有趣! (copy自鱼C论坛:小古比鱼) |
12异常exception: 速查宝典:python内置异常大合集 报错后可以直接来这里搜索
处理异常

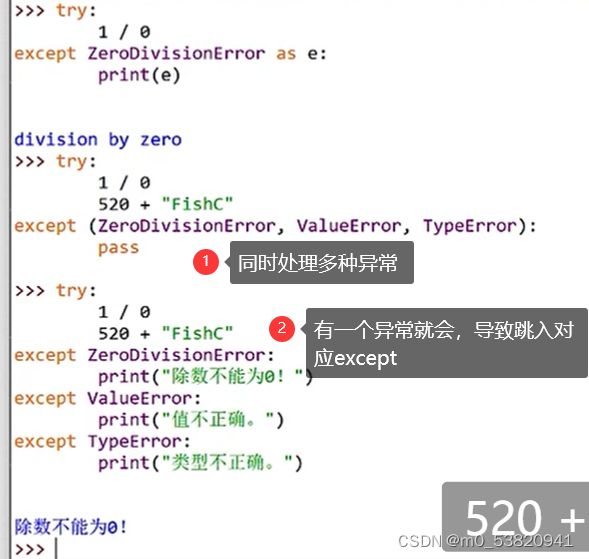
还可以与else结合,当没有异常时候
还可以与finally结合,无论是否出现异常
还可以异常嵌套

可以随时抛出异常(不能是胡编乱造的异常)
raise

异常链

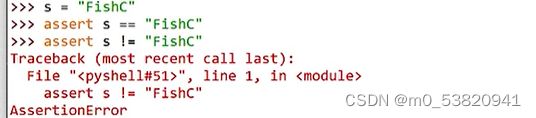
assert 用于代码调试 抛出异常
利用异常实现 goto

13 类和对象
class A
classB(A)
class C(A,B)
此时C中的数据优先使用A中
MRO

super()扩展阅读:MRO 的核心工作原理就是 DFLR(Depth First,Left to Right)查找规则。
super() 的做法是根据 MRO 顺序,找到第一个匹配的方法,就停下了脚步。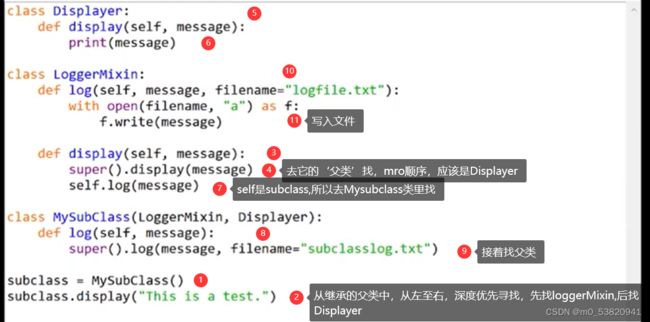
秒~
继承自父类的__slots__属性不会生效
property
python中property的用法_Jayeeeee的博客-CSDN博客_python中property的用法
14魔法方法:相当于C++的重载
Python 魔法方法详解_Wain丶的博客-CSDN博客_python魔法方法
没太搞懂这里
15.模块
import 模块名 (如果模块不在目前文件夹下,
需要import sys sys.path.append('路径‘)后再import)
import 太长模块名 as 缩写
import 包名.模块名 包就是一个文件夹名,该文件夹中需要有一个文件,名为__init__.py
如果写模块时候,有的代码只是用来测试,并不希望导入的时候也调用的话,就可以在模块中使用
if __name__ == '__main__':
test()甲鱼老师说:要学会自己查文档。ctrl + q快速文档 shift + F1 官方外部文档pycharm中查看快速帮助和python官方帮助文档_adz41455的博客-CSDN博客
python官方文档链接3.9.13 Documentation (python.org)
还有很多扩展包可以去pypi下载,网址如下
PyPI · The Python Package Index
实例:
文档中进行索引
print(模块名.__doc__) 文档
dir(模块名)显示有哪些类 如果有__all__
模块名.__all__ 可供外界调用的属性
模块名.__file__ 该模块所在路径
help(模块)
拓展阅读:timeit模块详解
16终于到了激动人心的爬虫了
URL
lib www
模块 urllib
(原来小甲鱼是一只蜘蛛/(ㄒoㄒ)/~~,好喜欢小甲鱼,希望小甲鱼可以健健康康快快乐乐,他爱的人也是!~)
getcode()获取当前的网页的状态码: 200状态码表示网页正常,403表示不正常。
#鱼C官网关键字:python编码问题的解决方案总结
json轻量级数据交换格式,对python数据类型的封装
import urllib.request
import urllib.parse
import json
while(1):
content = input('请输入需要翻译的内容:')
#f12打开控制台,网络,添加方法,找到post,点击post对应元素
#url 标头->请求url 注意要删去_o,好像是有道的反爬虫机制
url = 'https://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
#data 负载->表单数据
data = {}
data['i']= content
data['from']= 'AUTO'
data['to']= 'AUTO'
data['smartresult']= 'dict'
data['client']= 'fanyideskweb'
data['salt']= '16557774287213'
data['sign']= 'c7a6547baca9f65483f9c5e3b6458bd1'
data['lts']= '1655777428721'
data['bv']= '09e377475805a2fb71b566de21e0dc2b'
data['doctype']= 'json'
data['version']= '2.1'
data['keyfrom']= 'fanyi.web'
data['action']= 'FY_BY_REALTlME'
data = urllib.parse.urlencode(data).encode('utf-8')#转换为utf-8
response = urllib.request.urlopen(url,data)
html = response.read().decode('utf-8')#将utf-8解码
target = json.loads(html)#将json格式转换为字典格式
a = target['translateResult'][0][0]['tgt']
print('翻译结果:',a)
#缺陷只能翻译一句隐藏:
一种是使用,自己的header,外加time延时
一种是使用代理:云代理 - 高品质http代理ip供应平台/每天分享大量免费代理IP (ip3366.net)
国内高匿免费HTTP代理IP - 快代理 (kuaidaili.com)
都得多试很多个才能碰到能用的,注意要使用高匿名,透明的和不用一样
import random
import urllib.request
url = 'http://www.whatismyip.com.tw'
iplist = ['120.194.55.139:6969','202.55.5.209:8090','58.20.235.180:9091']
#步骤1:参数是一个字典(’类型‘:’代理ip端口号‘)
#proxy_support = urllib.request.ProxyHandler({'http':'183.247.202.208:30001'})
proxy_support = urllib.request.ProxyHandler({'http':random.choice(iplist)})
#步骤2:定制创建一个opener
opener = urllib.request.build_opener(proxy_support)
opener.addheaders = {('User-Agent','Mo##换自己电脑44')}
#步骤3:安装一个opener
urllib.request.install_opener(opener)
response = urllib.request.urlopen(url)
html = response.read().decode('utf-8')
print(html)正则表达式
(后续。。。