python实现自动检测核酸用码记录 ---- 自动化办公小技巧(摸鱼利器)
自动检测核酸用码记录
- 预备知识
-
- ✈️os库
-
- os.path.exists()
- os.mkdir()
- os.remove()
- os.listdir()
- Python 3 查看字符编码方法
- ⏰python3获取当前系统时间
- 读取图片,保存到指定目录
- 将数据保存到csv文件中
- python实现文字识别
-
- Tesseract
- python中解压rar和zip文件
-
- rar文件
- zip
-
- Python解压缩ZIP文件出现乱码问题的解决方案
- 利用Pycharm将python文件打包为exe文件
- 自动检验核酸展示
预备知识
✈️os库
os.path.exists()
os模块中的os.path.exists()方法用于检验文件是否存在。
如果不存在返回False ,存在则返回True
- 判断文件是否存在
import os
os.path.exists(test_file.txt) - 判断文件夹是否存在
import os
os.path.exists(test_dir)
os.mkdir()
os.mkdir() 方法用于以数字权限模式创建目录。用法:
os.mkdir(path[, mode])
- path – 要创建的目录,可以是相对或者绝对路径。
- mode – 要为目录设置的权限数字模式。
- 创建相对路径下的文件夹
import os
path = “./file1”
os.mkdir( path) - 创建绝对路径下的文件夹
import os
path = “D:\file1”
os.mkdir( path)
os.remove()
在Python中可以使用os.remove()函数删除文件(注意一定是一个文件)。
其原型如下所示:os.remov(path)
其参数path 为要删除的文件的路径。
- 如删除D盘下books目录下book目录中的book.txt的文件
import os
os.remove('d:\\books\\book\\book.txt')
os.listdir()
该函数返回指定路径下,文件和文件夹组成的列表
- 获取一个文件夹中所有图片的目录
# 文字图片的路径 path = 'Images\\' # 获取图片路径列表 imgs = [path + i for i in os.listdir(path)]
Python 3 查看字符编码方法
查看字符编码,需要用到chardet模块
TIp:chardet.detect 在查看字符串传的编码时,必须要把字符串encode后,才能查看当前字符串编码格式
- 查看某个字符串编码
import chardet s = '张三' print ( chardet . detect ( str . encode ( s ) ) ) 输出信息: { 'encoding' : 'utf-8' , 'confidence' : 0.7525 , 'language' : '' }
⏰python3获取当前系统时间
import time
print('时间显示')
for i in range(3):
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
time.sleep(1)
#每隔1秒打印一次系统时间,打印三次
#time.time() 返回当前时间的时间戳(1970纪元后经过的浮点秒数)
#time.localtime()格式化时间戳为本地的时间
#time.strftime()返回以可读字符串表示的当地时间
'''
python中时间日期格式化符号:
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
'''
- 实例
now = datetime.now() # 获取当前系统时间 current_time = now.strftime("%Y-%m-%d") # 得到当前日期,编码格式为ASCII码
``
读取图片,保存到指定目录
使用到了python中的PIL(pillow) 和 os库
- 代码
save_out_negative = 'errorImages\\' # 指定的文件夹 for i in range (len(ImagePath)): # ImagePath 保存图片原始路径 img = Image.open(ImagePath[i]) # 读取图片 if os.path.exists('errorImages') == False: # 判断是否已经存在这个目录了如果没有则增加 os.mkdir('./errorImages') # 采用相对路径创建 # 将图片路径只提取出图片名,我的路径格式为 Images\图片名 out_name = ImagePath[i].split('\\')[1] save_path = save_out_negative + out_name # 整合成新的路径 img.save(save_path) # 保存图片
将数据保存到csv文件中
- 实例
# 创建列表,保存header内容
header_list = ["图片路径","姓名"]
# 创建列表,保存数据
data_list = []
for i in range(len(errorImage)):
tempList = []
tempList.append(errorImage[i])
errorName = re.search(r'\\.*\.', errorImage[i])
errorName = errorName.group().replace("\\", "") # 得到图片路径
errorName = errorName.replace('.','')
tempList.append(errorName)
data_list.append(tempList)
# 以写方式打开文件。注意添加 newline="",否则会在两行数据之间都插入一行空白。
with open("notSubmitData.csv", mode="w", encoding="utf-8-sig", newline="") as f:
# 基于打开的文件,创建 csv.writer 实例
writer = csv.writer(f)
# 写入 header。
# writerow() 一次只能写入一行。
writer.writerow(header_list)
# 写入数据, writerows() 一次写入多行。
writer.writerows(data_list)
python实现文字识别
Tesseract
文字识别是ORC的一部分内容,ORC的意思是光学字符识别,通俗讲就是文字识别。Tesseract是一个用于文字识别的工具,我们结合Python使用可以很快的实现文字识别。但是在此之前我们需要完成一个繁琐的工作。
关于配置Tesseract 可以移步到这个博客:Python识别图片中的文字
注意点:
- 下载之后记得先运行再去配置系统变量。
- 所在目录有中文也没有关系。
- 如果没有该添加中文语言包会无法识别出中文。
python中解压rar和zip文件
rar文件
Python下的unrar还依赖RAR官方的库。因为我们用pip导入包之后还需要配置相应的环境。
-
安装unrar模块:
pip install unrar -
配置环境
-
下载UnRAR可执行文件:官网链接UnRAR ,找到UnRAR.dll下载即可。
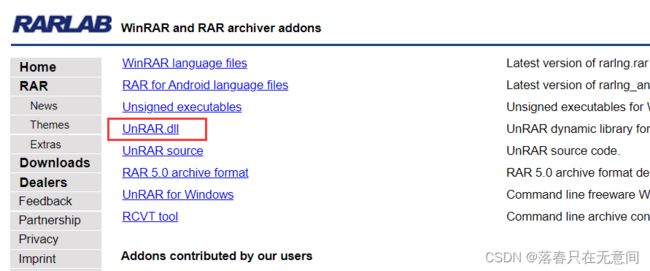
-
安装UnRAR,双击之后选择路径的时候选用默认的就可以了,也不是很大(避免出现问题)

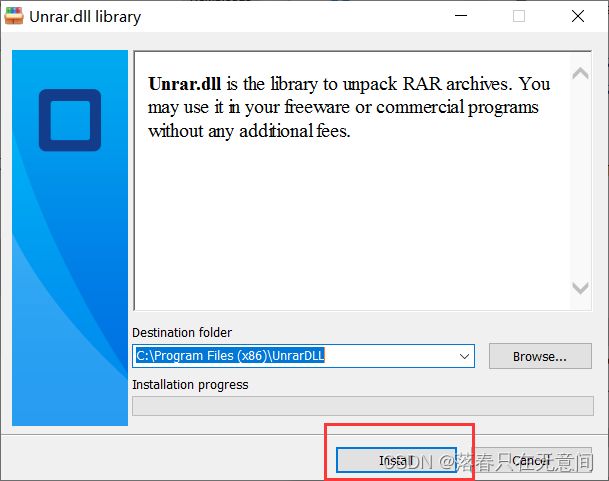
-
然后重要的一步,就是添加环境变量。是在系统变量中添加新的,不是在path中,变量名:
UNRAR_LIB_PATH, 变量值: 64位机C:\Program Files (x86)\UnrarDLL\x64\UnRAR64.dll; 32位机C:\Program Files (x86)\UnrarDLL\UnRAR.dll
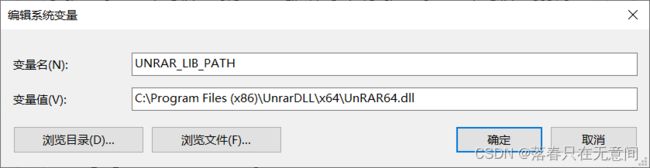
-
确定保存环境变量后,就配置成功了。
-
-
简单的使用实例:
from unrar import rarfile file = rarfile.RarFile('file_name') #这里写入的是需要解压的文件,别忘了加路径 file.extractall('you_want_path') #这里写入的是你想要解压到的文件夹
- 更多关于使用unrar可以去这里:unrar
rf = rarfile.RarFile(_rarfile, mode='r') # mode的值只能为'r'
rf_list = rf.namelist() # 得到压缩包里所有的文件
print('rar文件内容', rf_list)
for f in rf_list:
rf.extract(f, folder_abs) # 循环解压,将文件解压到指定路径
# 一次性解压所有文件到指定目录
# rf.extractall(path) # 不传path,默认为当前目录
解压rar文件不会出现解压之后文件名中文乱码现象。
zip
使用zipfile模块, ZIP 文件格式是一个常用的归档与压缩标准。 这个模块提供了创建、读取、写入、添加及列出 ZIP 文件的工具。
官网介绍链接
- pip 安装命令:
pip install zipfile - 基本操作
import zipfile
'''
基本格式:zipfile.ZipFile(filename[,mode[,compression[,allowZip64]]])
mode:可选 r,w,a 代表不同的打开文件的方式;r 只读;w 重写;a 添加
compression:指出这个 zipfile 用什么压缩方法,默认是 ZIP_STORED,另一种选择是 ZIP_DEFLATED;
allowZip64:bool型变量,当设置为True时可以创建大于 2G 的 zip 文件,默认值 True;
'''
zip_file = zipfile.ZipFile(path)
zip_list = zip_file.namelist() # 得到压缩包里所有文件
for f in zip_list:
zip_file.extract(f, folder_abs) # 循环解压文件到指定目录
zip_file.close() # 关闭文件,必须有,释放内存
Python解压缩ZIP文件出现乱码问题的解决方案
原因:原来编码不能被正确识别为utf-8的时候,会被是被识别并decode为cp437编码,如果原来是gbk编码的话就会变成乱码。
解决方法:解决的办法也很简单,那就是将文件名先使用cp437编码encode,然后再用gbk编码decode即可。
- 代码实例:
for file in zip_file_contents.namelist():
filename = file.encode('cp437').decode('gbk') # 先使用cp437编码,然后再使用gbk解码
zip_file_contents.extract(file, release_file_dir) # 解压缩ZIP文件
os.chdir(release_file_dir) # 切换到目标目录,用于改变当前工作目录的路径。
os.rename(file, filename) # 重命名文件,将原本乱码的file,变成正确编码的filename
os.chdir(retval) #切换回解压的正确路径
利用Pycharm将python文件打包为exe文件
1、PyInstaller简介
PyInstaller是一个跨平台的Python应用打包工具,支持 Windows/Linux/MacOS三大主流平台,能够把 Python 脚本及其所在的 Python 解释器打包成可执行文件,从而允许最终用户在无需安装 Python 的情况下执行应用程序。
PyInstaller 制作出来的执行文件并不是跨平台的,如果需要为不同平台打包,就要在相应平台上运行PyInstaller进行打包。
2、PyInstaller安装
pip install Pyinstaller
3、利用PyInstaller对pycharm中的python文件进行打包:利用Pycharm将python文件打包为exe文件(超详细,附带如何设置文件图标)
自动检验核酸展示
原始文件:
- Images中存放要识别的图片

里边为一个压缩包
开始处理,

- 将Images中的压缩包进行解压
- errorImages 存放的是不符合条件的图片
- imagePath为图片路径。
- notSubmitData 存放的是不符合条件的人员名单

参考文章:
- 添加链接描述
- zip中文乱码