【机器学习】异常检测
前言
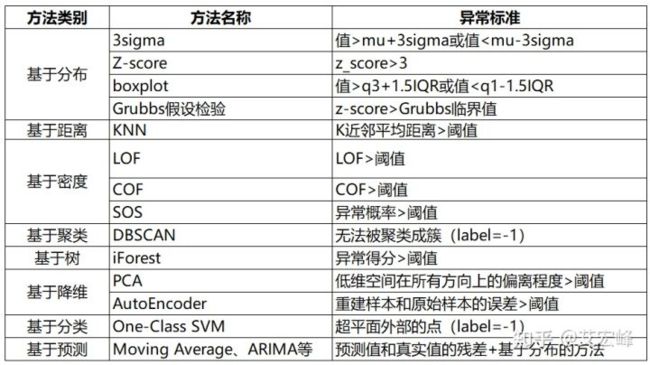
异常检测实际案例:网络安全中的攻击检测,金融交易欺诈检测,疾病侦测,和噪声数据过滤等。时间序列的异常又分为点异常和模式异常。
对于一个新观测值进行判断:
- 离群点检测: 训练数据包含离群点,即远离其它内围点。离群点检测估计器会尝试拟合出训练数据中内围点聚集的区域, 会忽略有偏离的观测值。
- 新奇点检测: 训练数据未被离群点污染,我们对新观测值是否为离群点感兴趣。在这个语境下,离群点被认为是新奇点。
离群点检测 也被称之为 无监督异常检测; 而 新奇点检测 被称之为 半监督异常检测。 在离群点检测的语境下, 离群点/异常点 不能够形成一个稠密的聚类簇,因为可用的估计器都假定了 离群点/异常点 位于低密度区域。相反的,在新奇点检测的语境下,新奇点/异常点 是可以形成 稠密聚类簇的,只要它们在训练数据的一个低密度区域,这被认为是正常的。
I. 传统机器学习
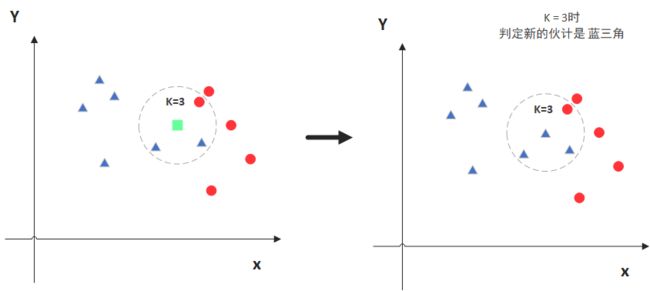
KNN算法
def KNeighborsClassifier(n_neighbors = 5,
weights='uniform',
algorithm = '',
leaf_size = '30',
p = 2,
metric = 'minkowski',
metric_params = None,
n_jobs = None
)
from sklearn.neighbors import KNeighborsClassifierLOF算法(Local Outlier Factor)
LOF算法计算出反映观测异常程度的得分(称为局部离群因子)。 它测量给定数据点相对于其邻近点的局部密度偏差。 算法思想是检测出具有比其邻近点明显更低密度的样本。
LOF 算法的优点是考虑到数据集的局部和全局属性:即使在具有不同潜在密度的离群点数据集中,它也能够表现得很好。 问题不在于样本是如何被分离的,而是样本与周围近邻的分离程度有多大。
from sklearn.neighbors import LocalOutlierFactor
lof= LocalOutlierFactor(n_neighbors=2)
lof.fit_predict()
## 计算每个样本相反的异常值得分,越接近-1,LOF得分越高
outfactor = lof.negative_outlier_factor_
## 将得分标准化
radius = (outfactor.max() - outfactor) / (outfactor.max() - outfactor.min())
iris.plot(kind = "scatter",x= "SepalWidthCm",y = "PetalWidthCm",
c = "r",figsize = (10,6),label = "data")
plt.scatter(iris["SepalWidthCm"], iris["PetalWidthCm"], s =800 * radius,
edgecolors="k",facecolors="none", label="LOF得分")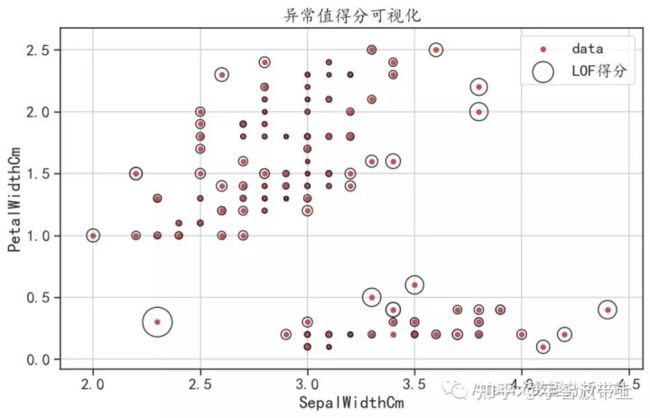
COF 连通性离群因子
COF是LOF的变种,相比于LOF,COF可以处理低密度下的异常值,COF的局部密度是基于平均链式距离计算得到。
from pyod.models.cof import COF
cof = COF(contamination = 0.06, ## 异常值所占的比例
n_neighbors = 20, ## 近邻数量
)
cof_label = cof.fit_predict(iris.values)SOS算法 stochastic outlier selection algorithm
SOS算法是一种无监督的异常检测算法,其将和其它所有点的关联度(affinity)很小的筛选出来
输入:特征矩阵(feature martrix)或者相异度矩阵(dissimilarity matrix)
输出:一个异常概率值向量(每个点对应一个)
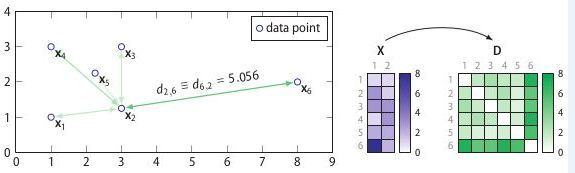
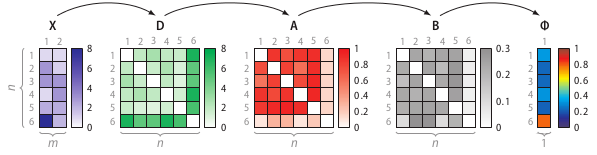
SOS算法的整个流程:
- 计算相异度矩阵D
- 计算关联度矩阵A
- 计算关联概率矩阵B
- 算出异常概率向量
pip install scikit-sos
>>> import pandas as pd
>>> from sksos import SOS
>>> iris = pd.read_csv("http://bit.ly/iris-csv")
>>> X = iris.drop("Name", axis=1).values
>>> detector = SOS()
>>> iris["score"] = detector.predict(X)
>>> iris.sort_values("score", ascending=False).head(10)
SepalLength SepalWidth PetalLength PetalWidth Name score
41 4.5 2.3 1.3 0.3 Iris-setosa 0.981898
106 4.9 2.5 4.5 1.7 Iris-virginica 0.964381
22 4.6 3.6 1.0 0.2 Iris-setosa 0.957945
134 6.1 2.6 5.6 1.4 Iris-virginica 0.897970
24 4.8 3.4 1.9 0.2 Iris-setosa 0.871733
114 5.8 2.8 5.1 2.4 Iris-virginica 0.831610
62 6.0 2.2 4.0 1.0 Iris-versicolor 0.821141
108 6.7 2.5 5.8 1.8 Iris-virginica 0.819842
44 5.1 3.8 1.9 0.4 Iris-setosa 0.773301
100 6.3 3.3 6.0 2.5 Iris-virginica 0.765657GitHub - jeroenjanssens/scikit-sos: A Python implementation of the Stochastic Outlier Selection algorithmA Python implementation of the Stochastic Outlier Selection algorithm - GitHub - jeroenjanssens/scikit-sos: A Python implementation of the Stochastic Outlier Selection algorithm https://github.com/jeroenjanssens/scikit-sos
https://github.com/jeroenjanssens/scikit-sos
DBSCAN密度聚类
1)eps: DBSCAN算法参数,即我们的ϵ-邻域的距离阈值,和样本距离超过ϵ的样本点不在ϵ-邻域内。默认值是0.5.一般需要通过在多组值里面选择一个合适的阈值。eps过大,则更多的点会落在核心对象的ϵ-邻域,此时我们的类别数可能会减少, 本来不应该是一类的样本也会被划为一类。反之则类别数可能会增大,本来是一类的样本却被划分开。
2)min_samples: DBSCAN算法参数,即样本点要成为核心对象所需要的ϵ-邻域的样本数阈值。默认值是5. 一般需要通过在多组值里面选择一个合适的阈值。通常和eps一起调参。在eps一定的情况下,min_samples过大,则核心对象会过少,此时簇内部分本来是一类的样本可能会被标为噪音点,类别数也会变多。反之min_samples过小的话,则会产生大量的核心对象,可能会导致类别数过少。
from sklearn.cluster import DBSCAN
y_pred = DBSCAN(eps=0.1, min_samples = 10).fit_predict(X)孤立森林Isolation Forest
孤立森林是无监督异常检测算法。
孤立森林的基本原理:异常样本相较普通样本可以通过较少次数的随机特征分割被孤立出来。
算法步骤:每次取随机超平面对一个数据空间进行切割,切一次可以生成两个子空间;再继续随机选取超平面,来切割第一步得到的两个子空间,以此循环下去,直到每子空间里面只包含一个数据点为止。
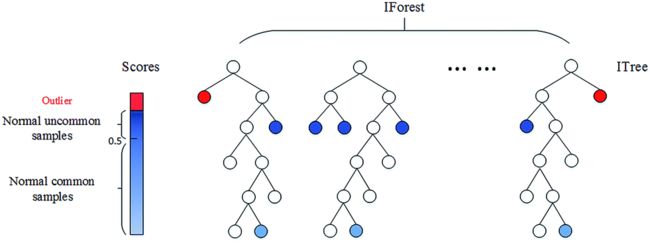
孤立森林的创新点包括以下四个:
- Partial models:在训练过程中,每棵孤立树都是随机选取部分样本;
- No distance or density measures:不同于 KMeans、DBSCAN 等算法,孤立森林不需要计算有关距离、密度的指标,可大幅度提升速度,减小系统开销;
- Linear time complexity:因为基于 ensemble,所以有线性时间复杂度。通常树的数量越多,算法越稳定;
- Handle extremely large data size:由于每棵树都是独立生成的,因此可部署在大规模分布式系统上来加速运算。
from sklearn.ensemble import IsolationForest
df = pd.DataFrame({'salary':[4,1,4,5,3,6,2,5,6,2,5,7,1,8,12,33,4,7,6,7,8,55]})
model = IsolationForest(n_estimators=100,
max_samples='auto',
contamination=float(0.1),
max_features=1.0)
model.fit(df[['salary']])
# 预测 decision_function 可以得出 异常评分
df['scores'] = model.decision_function(df[['salary']])
# predict() 函数 可以得到模型是否异常的判断,-1为异常,1为正常
df['anomaly'] = model.predict(df[['salary']])
OCSVM (One Class SVM)
ocsvm是半监督异常检测算法。
ocsvm基本原理如下:其输入的数据只需要有正常数据及其标签即可,在训练过程中,ocsvm会学习正常观测值的决策边界(svm中划分正负样本的超平面),同时考虑一些离群值,如果奇异值(模型未见过的新数据点)落在决策边界内,则模型将其认为是正常的,反之认为其是异常的。
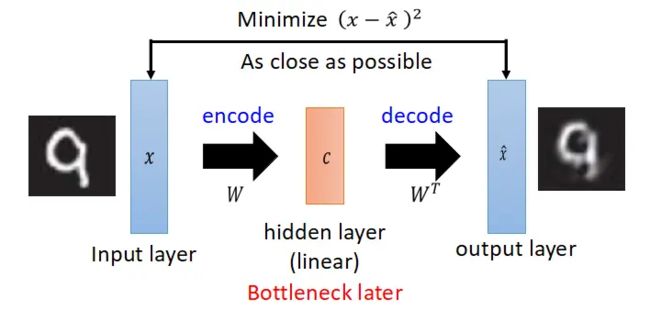
自编码器(Auto-Encoder)
自编码器,是一种无监督式学习模型。其将数据压缩后还原判断与原本相似程度。
- 优点:泛化性强,无监督不需要数据标注
- 缺点:针对异常识别场景,训练数据需要为正常数据。
自编码器AutoEncoder解决异常检测问题_码猿小菜鸡的博客-CSDN博客_autoencoder异常检测
【深度学习】 自编码器(AutoEncoder) - 知乎
PCA
PCA 应用于异常检测,大体上有两种套路:(1)将原始数据映射到低维特征空间,然后在低维空间里查看每一个点跟其他数据点的偏离程度;(2)将原始数据映射到低维特征空间,然后由低维特征空间重新映射回原空间,尝试用低维特征重构原始数据,看重构误差的大小。
DAGMM
DAGMM将AE自编码器和GMM高斯混合模型结合在一起的无监督异常检测模型
DAGMM基于这俩的套路:自编码器中间隐藏层特征和最后的重构误差对于识别异常都是有用的。
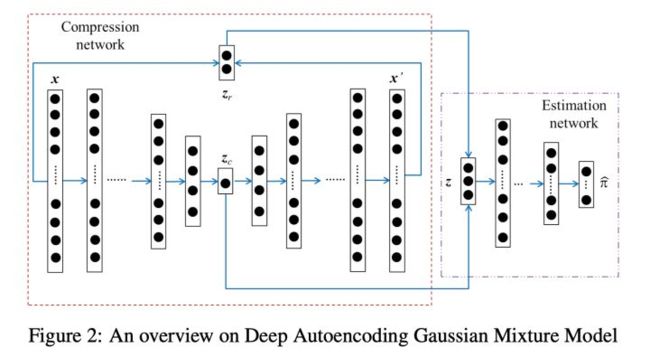
DAGMM构成:
- Compression Network压缩网络: 学习高维输入的降维表示,同时充分考虑到重建损失(reconstruction error),目的是为了防止降维造成的信息损失。关于重构误差,文章中建议了两种方式来计算,欧式距离和余弦相似度。
- Estimation Network估计网络: 结构上只是常规的多层神经网络,但其实是 GMM(高斯混合模型)的“替代品”,用于模拟 GMM 的结果。具体的,假设 GMM 中 gaussian component 的个数为 k,则估计网络的输出 p 经过 softmax 层可以得到样本分别归属 k 个 component 的概率。得到 N 个样本分别归属不同 component 的概率之后,我们可以用来估计 GMM 的几个重要参数:均值、方差、协方差矩阵。(更新 GMM 的参数,计算得到似然函数E(z),优化目标函数)
- 在测试过程中,可以通过模型计算E(z)的值,我们希望值越小越好(似然函数前添加了负号),值越大,越有可能异常,我们可以根据训练集中的数据获得先验阈值,来判断预测样本是否发生异常。
GitHub - tnakae/DAGMM: DAGMM Tensorflow implementation https://github.com/tnakae/DAGMM
https://github.com/tnakae/DAGMM
import tensorflow as tf
from dagmm import DAGMM
# Initialize
model = DAGMM(
comp_hiddens=[32,16,2], comp_activation=tf.nn.tanh,
est_hiddens=[16.8], est_activation=tf.nn.tanh,
est_dropout_ratio=0.25
)
# Fit the training data to model
model.fit(x_train)
# Evaluate energies
# (the more the energy is, the more it is anomary)
energy = model.predict(x_test)
# Save fitted model to the directory
model.save("./fitted_model")
# Restore saved model from dicrectory
model.restore("./fitted_model")II. 时间序列异常检测
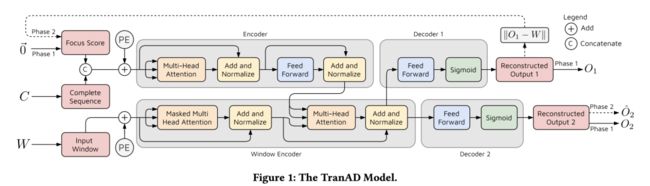
TranAD: tranformer+GAN(2022)
GitHub - imperial-qore/TranAD: [VLDB'22] Anomaly Detection using Transformers, self-conditioning and adversarial training. https://github.com/imperial-qore/tranad
https://github.com/imperial-qore/tranad
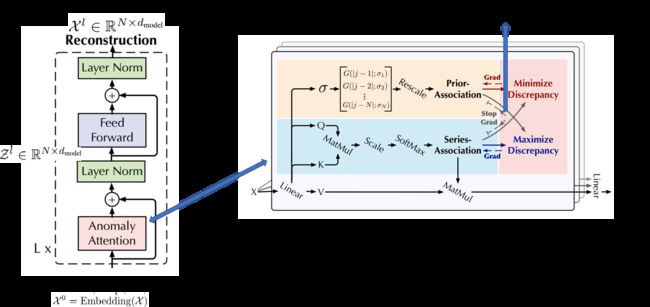
Anomaly-Transformer(2022)
提出动机:
- 数据标注困难,因此专注于无监督设置下的时间序列异常检测
- RNN重建或预测误差是逐点计算的,不能提供对时间上下文的全面描述
- 向量自回归模型和状态空间模型,很难学习信息表示和建模细粒度的关联。
- GNN局限于单个时间点,对于复杂的时间模式来说不够
模型特点:
- 先验关联(prior-association):邻接归纳的偏差(可学习的高斯核来计算相对时间距离)
- 序列关联 series-association:序列之间的偏差关系
- 极大极小策略:放大关联差异(Association Discrepancy)的 normal-abnormal 可分性
- 特殊设计的停止梯度机制(灰色箭头),以约束先验关联和序列关联,获得更可区分的关联差异。
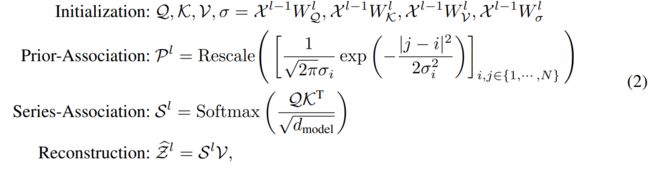
III. 图像异常检测
2021综述


One Class 一类分类器
DSVDD
【论文精读】一类分类器(一)—DSVDD_calm-one的博客-CSDN博客_一类分类器
https://ieeexplore.ieee.org/ielx7/66/8704169/08634922.pdf
Deep-SVDD论文研读 - 知乎 (zhihu.com)
代码
GitHub - nuclearboy95/Anomaly-Detection-Deep-SVDD-Tensorflow: Tensorflow Implementation of Deep SVDD
(PDF) One-Class Classification for Wafer Map using Adversarial Autoencoder with DSVDD Prior (researchgate.net)
OC-GAN(2019)
PatchCore(2021)
PatchCore对SPADE,PaDiM等一系列基于图像Patch的无监督异常检测算法工作进行了扩展,主要解决了SPADE测试速度太慢的问题,并且在特征提取部分做了一些探索。
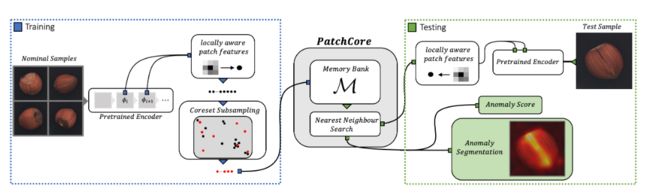
相比SPADE,PaDiM,PatchCore 仅使用stage2、stage3的特征图进行建模,通过增加窗口大小为3、步长为1、padding为1的平均池化AvgPool2d增大感受野后拼接,使用KNN Greedy CoreSet 采样选取最具代表性的特征点(选择与其他特征点最远的点以实现尽可能平衡的采样,效果类似泊松圆盘),构建特征向量记忆池,只保留1%~10%的特征数,进而实现高效的特征筛选并用于异常检测。并提出采用了re-weighting策略计算Image-Level的异常得分代替此前的最大值异常得分。
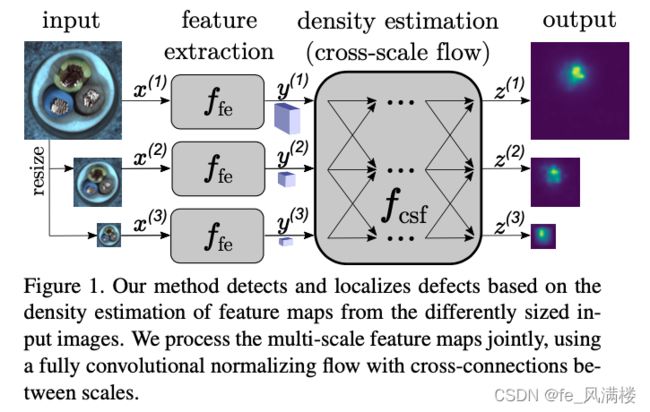
CS-Flow(2021)
fully convolutional cross-scale normalizing flow (CS-Flow) 模型,是基于real-NVP的流模型
CS-Flow能同时处理不同尺度的特征图,处理时将多种尺度的特征图并行传入流模型,并且让它们之间相互作用。
IV. 图数据异常检测
图模型可以对复杂的拓扑关系进行建模。因为其强大的表达能力,图模型最近被广泛用于推荐系统,生物制药等领域,并在很多领域上都有对应的开源工具库(推荐系统:GNN-RecSys,生物制药:DGL-LifeSci)。
作为数据挖掘中的经典问题,异常检测技术在图数据上的应用也逐渐受到关注。其主要应用方向有:虚假信息检测、金融欺诈检测,系统安全监测等
PyGOD库
GitHub - pygod-team/pygod: A Python Library for Graph Outlier Detection (Anomaly Detection)https://github.com/pygod-team/pygod图数据上的异常检测工具库,集成了超过10个重要的图数据异常检测模型。
补充:统计方法
绝对中位差Median Absolute Deviation, MAD
MAD是一种采用计算各观测值与平均值的距离总和的检测离群值的方法。

绝对中位差是一种统计离差的测量。而且,MAD是一种鲁棒统计量,比标准差更能适应数据集中的异常值。对于标准差,使用的是数据到均值的距离平方,所以大的偏差权重更大,异常值对结果也会产生重要影响。对于MAD,少量的异常值不会影响最终的结果。
由于MAD是一个比样本方差或者标准差更鲁棒的度量,它对于不存在均值或者方差的分布效果更好,比如柯西分布。
def c_except(x,thresh=3.5):
'''
使用绝对中位差消除异常
:return:
'''
if len(x)<=1:
return
me=np.median(x)
abs=np.absolute(x-me)
abs_me=np.median(abs)
score=norm.ppf(0.75)*abs/abs_me
return scorePyod包:
from pyod.models.mad import MAD
model = MAD().fit(data)
score = model.decision_function(data)Python集成库
Anomalib库

GitHub - openvinotoolkit/anomalib: An anomaly detection library comprising state-of-the-art algorithms and features such as experiment management, hyper-parameter optimization, and edge inference.https://github.com/openvinotoolkit/anomalib
工业异常检测
支持模型包括:
- Patchcore
- Padim
- DFKDE
- DFM
- CFlow
- Ganomaly
- STFPM
- FastFlow
- DREAM
- Reverse Distillation
链接
Anomaly Detection | Papers With Code
References
异常检测方法总结 - 知乎
2.7-新奇点和离群点检测 - sklearn中文文档
【时间序列异常检测】Anomaly-Transformer_理心炼丹的博客-CSDN博客
时间序列异常检测算法综述 – 标点符
[论文笔记] 高斯混合模型GMM与神经网络结合的异常检测任务:DAGMM - 知乎