sklearn笔记:调参
1 介绍
- 超参数是不直接在估计器中学习的参数。 在 scikit-learn 中,它们作为参数传递给估计器类的构造函数。
- 需要搜索超参数空间以获得最佳交叉验证分数。
- scikit-learn 中提供了两种通用的参数搜索方法:
- 对于给定的值,GridSearchCV 会详尽地考虑所有参数组合
- RandomizedSearchCV 可以从具有指定分布的参数空间中采样给定数量的候选者。
- 这两个工具都有连续的减半对应搜索方法 HalvingGridSearchCV 和 HalvingRandomSearchCV,它们可以更快地找到一个好的参数组合。
1.1 查找指定估计其的所有超参数
要查找给定估计器的所有参数的名称和当前值,需要使用get_params()
import numpy as np
from sklearn.svm import SVC
X = np.array([[-3, -7], [-2, -10], [1, 1], [2, 5]])
y = np.array([1, 1, 2, 2])
#数据部分
clf=SVC(kernel='linear')
clf.fit(X, y)
#fit数据
clf.get_params()
'''
{'C': 1.0,
'break_ties': False,
'cache_size': 200,
'class_weight': None,
'coef0': 0.0,
'decision_function_shape': 'ovr',
'degree': 3,
'gamma': 'scale',
'kernel': 'linear',
'max_iter': -1,
'probability': False,
'random_state': None,
'shrinking': True,
'tol': 0.001,
'verbose': False}
'''2 Grid Search
- GridSearchCV 提供的网格搜索从 param_grid 参数指定的参数值网格中详尽地生成候选者。
- 例如,以下 param_grid 指定应探索两个网格:
- 一个具有线性内核和 [1, 10, 100, 1000] 中的 C 值
- 一个具有 RBF 内核,C 值的范围为 [1, 10, 100, 1000],γ值的范围为 [0.001, 0.0001]。
param_grid = [
{'C': [1, 10, 100, 1000], 'kernel': ['linear']},
{'C': [1, 10, 100, 1000], 'gamma': [0.001, 0.0001], 'kernel': ['rbf']},
]当“拟合”到数据集上时,所有可能的参数值组合都会被评估并保留最佳组合。
2.1 构造函数使用方法
class sklearn.model_selection.GridSearchCV(
estimator,
param_grid,
*,
scoring=None,
n_jobs=None,
refit=True,
cv=None,
verbose=0,
pre_dispatch='2*n_jobs',
error_score=nan,
return_train_score=False)2.1.1 主要参数说明
| estimator | 估计器 |
| param_grid |
|
| scoring | 模型评价标准,默认None,使用estimator的误差估计函数。根据所选模型不同,评价准则不同 |
| refit | 默认为True,即在搜索参数结束后,用最佳参数结果再次fit一遍全部数据集 |
| cv | 交叉验证参数,默认None,使用5折交叉验证 |
2.1.2 举例
from sklearn import svm, datasets
from sklearn.model_selection import GridSearchCV
iris = datasets.load_iris()
parameters = {'kernel':('linear', 'rbf'), 'C':[1, 10]}
svc = svm.SVC()
clf = GridSearchCV(svc, parameters)
#对svc进行grid search,其中参数范围是parameters中的两两组合
clf.fit(iris.data, iris.target)
#将训练数据和label输入进去,进行拟合
import pandas as pd
pd.DataFrame(clf.cv_results_)
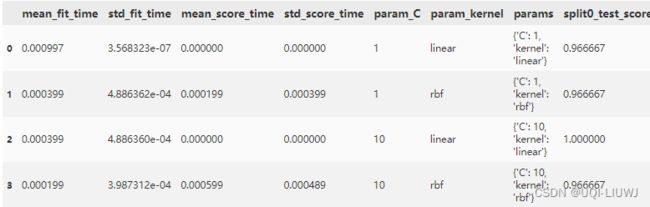
 2.1.3 类属性
2.1.3 类属性
| cv_results_ | 各参数组合交叉验证的结果, (转化成DataFrame后的结果 可见2.1.2例子输出部分) |
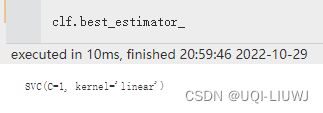
| best_estimator_ | 搜索选择的估计器,即在数据集上给出最高分数的估计器。
|
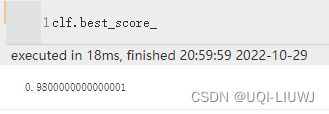
| best_score_ | 最佳估计器的平均交叉验证结果
|
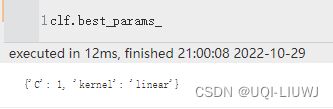
| best_params_ | 最佳参数组合
|
| classes_ | 类别的label
|
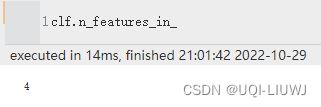
| n_features_in_ | 输入的参数维度
|

2.1.4 方法
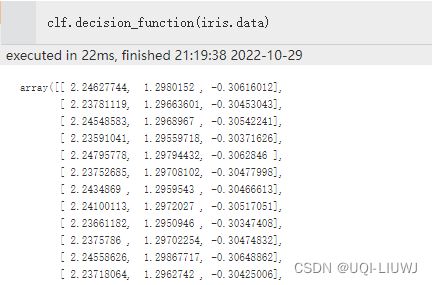
| decision_function(X) | 对于X中的数据,计算他们在最优估计器上的数值
|
| fit(X,y) | |
| get_params | |
| predict(X) | |
| score(X,Y) | |
| transform(X) |
3 Random Search
- RandomizedSearchCV 实现了对参数的随机搜索,其中每个设置都是从可能的参数值的分布中采样的。
3.1 主要使用方法
class sklearn.model_selection.RandomizedSearchCV(
estimator,
param_distributions,
*,
n_iter=10,
scoring=None,
n_jobs=None,
refit=True,
cv=None,
verbose=0,
pre_dispatch='2*n_jobs',
random_state=None,
error_score=nan,
return_train_score=False)3.1.2 主要参数说明
| estimator | 估计器 |
| param_distributions |
|
| n_iter | 采样的参数设置数。 n_iter 权衡运行时间与解决方案的质量。 |
| scoring | 模型评价标准,默认None,使用estimator的误差估计函数。根据所选模型不同,评价准则不同 |
| refit | 默认为True,即在搜索参数结束后,用最佳参数结果再次fit一遍全部数据集 |
| cv | 交叉验证参数,默认None,使用5折交叉验证 |
3.1.3 举例
from sklearn import svm, datasets
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import uniform
iris = datasets.load_iris()
distributions = {'kernel':('linear', 'rbf'), 'C':uniform(loc=0, scale=400)}
svc = svm.SVC()
clf = RandomizedSearchCV(svc, distributions)
#对svc进行random search,其中参数是从distributions中的分布中随机选择的
clf.fit(iris.data, iris.target)
import pandas as pd
pd.DataFrame(clf.cv_results_)
3.1.4 类属性
| cv_results_ | 各参数组合交叉验证的结果, (转化成DataFrame后的结果 可见3.1.3例子输出部分) |
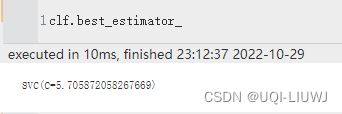
| best_estimator_ | 搜索选择的估计器,即在数据集上给出最高分数的估计器。
|
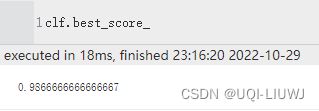
| best_score_ | 最佳估计器的平均交叉验证结果
|
| best_params_ | 最佳参数组合
|
| classes_ | 类别的label
|
| n_features_in_ | 输入的参数维度
|
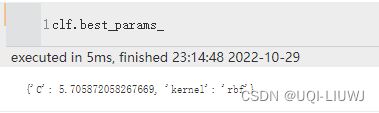
3.1.5方法
| decision_function(X) | 对于X中的数据,计算他们在最优估计器上的数值
|
| fit(X,y) | |
| get_params | |
| predict(X) | |
| score(X,Y) | |
| transform(X) |