19位算法工程师总结:机器学习项目成功落地的三条秘诀

文 | 天于刀刀
又是一年金九银十,前几天小编刀刀在一次电话面试过程中被HR 的一个问题问得差点闪了腰。
当时情况是这样的,在流利地介绍完之前的几个项目后,招聘小姐姐打断了我后续的(忽悠)节奏,郑重其事地反问了一句:
"请问您的这些项目都已经落地了吗?"
当时我只觉得莫名其妙,这别不是来套方案的吧。

落地?这当然落地了啊!
随后我就挑着框架性的东西和小姐姐解释了一番后,这个问题也算是过关了,顺利进入下一轮。
转眼间这场面试已经过去几天,我也逐渐遗忘了其中的大部分细节,直到最近一个 twitter 上热议的话题 [1][2] 刷新了我之前浅薄的观点。

只有完成从数据收集、模型实现、评估部署和在线检测这四个循环步骤的机器学习任务才算是真正的落了地!
简而言之,在业务上落地的工作也包含了后续迭代的能力和相关的扩展性。
而这份工作被称作为 Machine Learning Operations (MLOps),由企业中的 Machine Learning Engineers (MLEs) 完成。
读完全文,小编非常推荐之前没有模型部署和落地经验的新同学去学习一下其中的方法论和概念。或许这个不能帮你在老板面前 show off,但是快速入门则完全没有问题。
此外对于有经验的从业者,你也能从文中丰富的受访者案例中收获一些同感。
在文中作者采访了19位来自不同公司不同机器学习岗位的工程师,将他们日常工作中的一些流程和方法论进行了归纳,总结出能让机器学习真正落地取得成功的三点要素:
敏捷开发( Velocity )
系统验证( Validation )
多个版本( Versioning )
首先,敏捷开发可能相当一部分工作的小伙伴都有所耳闻(加班泪),它的核心要素就是尽可能地缩短需求到交付之间的时间成本。
而在机器学习任务中大多数的 bad case 改进和 idea 的实现都需要做实验来最终确定是否有效,因此作者认为在落地环节中,迭代是非常重要的一块工作。常见的迭代技巧有:数据迭代、灰度测试等。
受访者 P11:我往往会从一个已经存在的模型开始训练,因为这意味着更快速的迭代。通常,从我们的经验来看,数据能够帮助突破瓶颈......显然这并不是说“永远不会修改模型”,只是这不应该是我们在处理实际问题时的第一步。
其次,一个动态的、规范的、多样的和紧贴实际业务的验证集是非常有必要的。构建一个完备的验证集,我们往往希望它:(1)尽可能地贴近业务的数据分布;(2)加入代表性的数据防止 bad case 再次出现。
一位来自小公司的 NLP 岗位受访者在文中提到,他会专门收集业务中遇到的“失败”案例,形成并维护一个专门的验证集,并且在未来的模型升级运维过程中反复地使用它。
同时验证集中的指标也应该尽可能地和业务产品挂钩——工作!=科研,老板也不一定是 AI 技术人员。
我们需要业务导向的 KPI 设计,例如对于机器翻译任务,在2020新冠元年,相对于和老板报告 BLEU 又提升了多少多少,你还不如早点确保“新冠”别再被翻译成“new crown”来得实在。
受访者 P11:将模型的表现定为 KPI 是一件非常重要的事。但这件事的重点是,你需要指出真正重要的是什么。坦白地说我认为这才是人们进行 AI 工作的方法。不是简单的:“嘿!让我们搞点实验整点好看的 precision 和 recall 给老板展示吧!”而是:“嘿,让我们讨论下每个人各自负责的业务指标吧!”
最后,维护一个模型需要深思熟虑的软件工程和组织性的实践。这意味着 MLOps 需要不停地标注新数据,并且周期性地基于新数据训练新模型。
此外,一个针对生产环境中模型的审查系统也应该被建立,用于监控在线模型的表现。
通过对比离线实验数据的模型效果和在线生产模型的效果,我们应当能够回答“为什么模型表现降低了?哦,这也许是因为用户数据和训练数据之间存在漂移(data swift)”。
受访者 P7:...所以我可以通过分析研究后告诉别人模型效果为什么(在生产环境中)下降。那么我能不能提前避免此类问题呢?应该不行。那么我的分析算是有用的吗?可能不是。
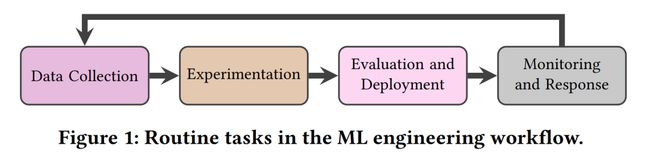
直白地说,模型运维( MLOps )的工作都是一些“琐碎的脏活累活”,并且目前看来存在着许多的问题:
不科学的训练集设置可能会导致数据泄露等问题;
开发时极度依赖 Jupyter Notebook,需要花费精力进行 pipeline 重构迁移;
不太好做 code review,因为可能存在一些拍脑袋的操作。
可以看到,在工作中不仅仅需要涉及到大量的数据维护、模型试验、A/B测试等一系列不那么 AI 的工作,同时还会面临标注团队的管理、产品团队的刁难和测试团队的质疑。
而在一些小公司里,顶着“算法工程师” title 的同学甚至可能会身兼数职,既是数分又干产品,偶尔标个数据写个测试程序啥的也不在话下。
这些就导致了这个岗位要求一个能打通上下游任务的机器学习抗压全才,同时还极有可能因为某一个未知的小错随时被 pua 。(虽说是否需要抗压取决于公司文化,但是我想应该没有人喜欢自己的模型在之前没想到的地方出岔子)

为了解决这个问题,作者提出了或许可以设计一个专门的 ML 运维平台,去减少一些工程师的重复性劳动。
例如平台可以轻松地维护不同版本的数据集和对应的模型,帮助工程师进行代码审查,以及完成后续在线生产环境中实时的指标监控。
同时平台最好也能支持多个数据集或多模型并行训练、开发和部署的能力,从而减少工程师浪费的重复工作,帮助他们直接获取一个想法的端到端收益。
受访者 P18:产品的指标是会随着公司规划而变化的。也许之前公司关心的是多少收益率,但现在可能他们更希望有更多的装机量。公司和产品的目标一直在变,如何将其量化为模型的指标也是一个问题。
在本文的最后,小编打算分享一下受访者 P1 大哥的几个让我感同身受的案例。P1 是一家大型公司的机器学习管理者,他在论文里分享了许多工作中遇到的轶事。
受访者 P1:我记得有一个 PR,它添加了许多数据增强相关的代码和资源。但如果不是当时有人在代码审查中因为好奇随手点开了数据加载的源码,之后几乎不可能发现其实数据中的 ground truth 被翻转过了。如果这个问题没被识别,那么也许最后模型的准确率只会稍稍下跌。
受访者 P1:还有个例子,我们的 AI 团队花费了大量的精力和成本用于优化模型,但是最终产品的表现却几乎没有什么提升。所有人都很沮丧,直到一个非 AI 团队的人在工作流中调整了一个不影响模型的参数,这个产品的运行一下子变得顺畅很多。没有人知道为什么。
受访者 P1:很多人在做机器学习的时候都声称他们了解原理,知道为什么要做某件事,并且为什么它有效。但事实上人们只是通过直觉尝试了所有的东西,然后补充了一些好听的解释来让别人相信他确实是有效的。因此我产出最多的同事往往是那个实验速度最快的人——他总是在做实验,什么都尝试。

卖萌屋作者:天于刀刀
注重 WLB 的工业界反卷斗士,未进化的 NLP 咸鱼一条。专注于研究在各个场景中算法模型的落地情况,希望自己编写的算法有朝一日可以改变世界。目前的兴趣点在于:假新闻检测、深度学习模型可解释性等。
作品推荐
1.腾讯薪酬改革来了!晋升≠加薪?员工到底为何工作?
2.从 Google AI 离职了,这里让我爱不起来
3.百万悬赏!寻找“模型越大,效果越差”的奇葩任务!
4.想通这点,治好 AI 打工人的精神内耗
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜广推与求职讨论群

[1] [Twitter] Operationalizing Machine Learning: An Interview Study, https://twitter.com/sh_reya/status/1572273917640970241?s=21&t=aSP2MK4BndRVjpQAEvYLeQ
[2] [Paper] Operationalizing Machine Learning: An Interview Study, https://arxiv.org/abs/2209.09125