注意力汇聚:Nadaraya-Watson 核回归
文章目录
-
- 注意力汇聚:Nadaraya-Watson 核回归
-
- 生成数据集
- 平均汇聚
- 非参数注意力汇聚
- 带参数注意力汇聚
- 批量矩阵乘法
- 定义模型
- 训练
- 小结
注意力汇聚:Nadaraya-Watson 核回归
上节我们介绍了框架下的注意力机制的主要成分: 查询(自主提示)和键(非自主提示)之间的交互形成了注意力汇聚, 注意力汇聚有选择地聚合了值(感官输入)以生成最终的输出。 在本节中,我们将介绍注意力汇聚的更多细节, 以便从宏观上了解注意力机制在实践中的运作方式。 具体来说,1964年提出的Nadaraya-Watson核回归模型 是一个简单但完整的例子,可以用于演示具有注意力机制的机器学习。
import torch
from torch import nn
from d2l import torch as d2l
生成数据集
简单起见,考虑下面这个回归问题:给定的成对的“输入-输出”数据集 { ( x 1 , y 1 ) , … , ( x n , y n ) } \{(x_1, y_1), \ldots, (x_n, y_n)\} {(x1,y1),…,(xn,yn)},如何学习 f f f来预测任意新输入 x x x的输出 y ^ = f ( x ) \hat{y} = f(x) y^=f(x)?
根据下面的非线性函数生成一个人工数据集,其中加入的噪声项为 ϵ \epsilon ϵ:
y i = 2 sin ( x i ) + x i 0.8 + ϵ , y_i = 2\sin(x_i) + x_i^{0.8} + \epsilon, yi=2sin(xi)+xi0.8+ϵ,
其中 ϵ \epsilon ϵ服从均值为 0 0 0和标准差为 0.5 0.5 0.5的正态分布。我们生成了 50 50 50个训练样本和 50 50 50个测试样本。为了更好地可视化之后的注意力模式,我们将训练样本进行排序。
n_train = 50 #训练样本数
x_train, _ = torch.sort(torch.rand(n_train) * 5) #排序后的训练样本
def f(x):
return 2 * torch.sin(x) + x ** 0.8
#定义训练集的标签,即训练样本的输出
y_train = f(x_train) + torch.normal(0, 0.5, (n_train,))
x_test = torch.arange(0, 5, 0.1) #测试样本数据集
y_truth = f(x_test) #测试样本的标签
n_test = len(x_test) #测试样本的长度
n_test
50
下面的函数将绘制所有的训练样本(样本由圆圈表示), 不带噪声项的真实数据生成函数 f f f(标记为“Truth”), 以及学习得到的预测函数(标记为“Pred”)。
def plot_kernel_reg(y_hat):
d2l.plot(x_test, [y_truth, y_hat], 'x', 'y', legend=['Truth', 'Pred'],
xlim=[0, 5], ylim=[-1, 5])
d2l.plt.plot(x_train, y_train, 'o', alpha=0.5)
平均汇聚
我们先使用最简单的估计器来解决回归问题,基于平均汇聚层来计算所有训练样本输出值的平均值:
f ( x ) = 1 n ∑ i = 1 n y i f(x) = \frac{1}{n}\sum\limits_{i=1}^{n}y_{i} f(x)=n1i=1∑nyi
如下图所示,这个估计器确实不够聪明:真实函数 f f f(“Truth”) 和预测函数(“Pred”)相差很大。
y_hat = torch.repeat_interleave(y_train.mean(), n_test)
plot_kernel_reg(y_hat)

非参数注意力汇聚
# X_repeat的形状:(n_test, n_train)
# 每一行都包含着相同的测试输入(例如:同样的查询)
X_repeat = x_test.repeat_interleave(n_train).reshape((-1, n_train))
# x_train包含着键。attention_weights的形状为: (n_test, n_train)
# 每一行都包含着要在给定的每个查询的值(y_train)之间分配的注意力机制
attention_weights = nn.functional.softmax(-(X_repeat - x_train)**2 /2 , dim=1)
# y_hat的每个元素都是值得加权平均值, 其中得权重是注意力权重
y_hat = torch.matmul(attention_weights, y_train)
plot_kernel_reg(y_hat)

显然,平均汇聚忽略了输入 x i x_i xi。于是Nadaraya[Nadaraya.1964]和Watson[Watson.1964]提出了一个更好的想法,根据输入的位置对输出 y i y_i yi进行加权:
f ( x ) = ∑ i = 1 n K ( x − x i ) ∑ j = 1 n K ( x − x j ) y i , f(x) = \sum_{i=1}^n \frac{K(x - x_i)}{\sum_{j=1}^n K(x - x_j)} y_i, f(x)=i=1∑n∑j=1nK(x−xj)K(x−xi)yi,
其中 K K K 是核(kernel)。上面公式所描述的估计器被称为Nadaraya-Watson核回归(Nadaraya-Watson kernel regression)。这里我们不会深入讨论核函数的细节,但受此启发,我们可以从注意力机制框架的角度出发重新思考,得到一个更加通用的注意力汇聚(attention pooling) 公式:
f ( x ) = ∑ i = 1 n α ( x , x i ) y i , f(x) = \sum_{i=1}^n \alpha(x, x_i) y_i, f(x)=i=1∑nα(x,xi)yi,
其中 x x x 是查询, ( x i , y i ) (x_i, y_i) (xi,yi) 是键值对。查询 x x x 和键 x i x_i xi 之间的关系建模为 注意力权重(attention weight) α ( x , x i ) \alpha(x, x_i) α(x,xi),这个权重将被分配给每一个对应值 y i y_i yi 。对于任何查询,模型在所有键值对注意力权重都是一个有效的概率分布:
它们是非负的,并且总和为1。
为了更好地理解注意力汇聚,我们考虑一个高斯核(Gaussian kernel),其定义为:
K ( u ) = 1 2 π exp ( − u 2 2 ) . K(u) = \frac{1}{\sqrt{2\pi}} \exp(-\frac{u^2}{2}). K(u)=2π1exp(−2u2).
将高斯核代入,可以得到:
f ( x ) = ∑ i = 1 n α ( x , x i ) y i = ∑ i = 1 n exp ( − 1 2 ( x − x i ) 2 ) ∑ j = 1 n exp ( − 1 2 ( x − x j ) 2 ) y i = ∑ i = 1 n s o f t m a x ( − 1 2 ( x − x i ) 2 ) y i . \begin{aligned} f(x) &=\sum_{i=1}^n \alpha(x, x_i) y_i\\ &= \sum_{i=1}^n \frac{\exp\left(-\frac{1}{2}(x - x_i)^2\right)}{\sum_{j=1}^n \exp\left(-\frac{1}{2}(x - x_j)^2\right)} y_i \\&= \sum_{i=1}^n \mathrm{softmax}\left(-\frac{1}{2}(x - x_i)^2\right) y_i. \end{aligned} f(x)=i=1∑nα(x,xi)yi=i=1∑n∑j=1nexp(−21(x−xj)2)exp(−21(x−xi)2)yi=i=1∑nsoftmax(−21(x−xi)2)yi.
在上式中,如果一个键 x i x_i xi 越是接近给定的查询 x x x,那么分配给这个键对应值 y i y_i yi 的注意力权重就会越大,也就“获得了更多的注意力”。
值得注意的是,Nadaraya-Watson核回归是一个非参数模型。因此上式是非参数的注意力汇聚(nonparametric attention pooling)模型。接下来,我们将基于这个非参数的注意力汇聚模型来绘制预测结果,并会发现新的模型预测线是平滑的,并且比平均汇聚的预测更接近真实。
现在,我们来观察注意力的权重。 这里测试数据的输入相当于查询,而训练数据的输入相当于键。 因为两个输入都是经过排序的,因此由观察可知“查询-键”对越接近, 注意力汇聚的注意力权重就越高。
d2l.show_heatmaps(attention_weights.unsqueeze(0).unsqueeze(0),
xlabel='Sorted training inputs',
ylabel='Sorted testing inputs')

nn.functional.softmax(-(X_repeat - x_train)**2 /2, dim=1)
tensor([[1.0210e-01, 9.4943e-02, 9.4741e-02, ..., 8.3491e-07, 7.0730e-07,
6.7147e-07],
[9.5087e-02, 9.0765e-02, 9.0618e-02, ..., 1.2435e-06, 1.0571e-06,
1.0046e-06],
[8.8242e-02, 8.6458e-02, 8.6364e-02, ..., 1.8454e-06, 1.5741e-06,
1.4975e-06],
...,
[1.6301e-06, 5.1712e-06, 5.2874e-06, ..., 5.1045e-02, 5.0768e-02,
5.0669e-02],
[1.0890e-06, 3.5461e-06, 3.6277e-06, ..., 5.4534e-02, 5.4423e-02,
5.4376e-02],
[7.2476e-07, 2.4224e-06, 2.4794e-06, ..., 5.8039e-02, 5.8119e-02,
5.8130e-02]])
带参数注意力汇聚
非参数的Nadaraya-Watson核回归具有一致性(consistency)的优点: 如果有足够的数据,此模型会收敛到最优结果。 尽管如此,我们还是可以轻松地将可学习的参数集成到注意力汇聚中。
此时与上式略有不同, 在下面的查询和键之间的距离乘以可学习参数:
f ( x ) = ∑ i = 1 n α ( x , x i ) y i = ∑ i = 1 n exp ( − 1 2 ( ( x − x i ) w ) 2 ) ∑ j = 1 n exp ( − 1 2 ( ( x − x j ) w ) 2 ) y i = ∑ i = 1 n s o f t m a x ( − 1 2 ( ( x − x i ) w ) 2 ) y i . \begin{aligned}f(x) &= \sum_{i=1}^n \alpha(x, x_i) y_i \\&= \sum_{i=1}^n \frac{\exp\left(-\frac{1}{2}((x - x_i)w)^2\right)}{\sum_{j=1}^n \exp\left(-\frac{1}{2}((x - x_j)w)^2\right)} y_i \\&= \sum_{i=1}^n \mathrm{softmax}\left(-\frac{1}{2}((x - x_i)w)^2\right) y_i.\end{aligned} f(x)=i=1∑nα(x,xi)yi=i=1∑n∑j=1nexp(−21((x−xj)w)2)exp(−21((x−xi)w)2)yi=i=1∑nsoftmax(−21((x−xi)w)2)yi.
下面我们将通过训练这个模型来学习注意力汇聚的参数。
批量矩阵乘法
为了更有效地计算小批量数据的注意力,我们可以利用深度学习开发框架中提供的批量矩阵乘法。
假设第一个小批量数据包含 n n n个矩阵 X 1 , … , X n \mathbf{X}_1,\ldots, \mathbf{X}_n X1,…,Xn,形状为 a × b a\times b a×b,第二个小批量包含 n n n个矩阵 Y 1 , … , Y n \mathbf{Y}_1, \ldots, \mathbf{Y}_n Y1,…,Yn,
形状为 b × c b\times c b×c。它们的批量矩阵乘法得到 n n n个矩阵 X 1 Y 1 , … , X n Y n \mathbf{X}_1\mathbf{Y}_1, \ldots, \mathbf{X}_n\mathbf{Y}_n X1Y1,…,XnYn,形状为 a × c a\times c a×c。因此,假定两个张量的形状分别是 ( n , a , b ) (n,a,b) (n,a,b)和 ( n , b , c ) (n,b,c) (n,b,c),它们的批量矩阵乘法输出的形状为 ( n , a , c ) (n,a,c) (n,a,c)。
X = torch.ones((2, 1, 4))
Y = torch.ones((2, 4, 6))
torch.bmm(X, Y), torch.bmm(X, Y).shape
(tensor([[[4., 4., 4., 4., 4., 4.]],
[[4., 4., 4., 4., 4., 4.]]]),
torch.Size([2, 1, 6]))
在注意力机制的背景中,我们可以使用小批量矩阵乘法来计算小批量数据中的加权平均值。
weights = torch.ones((2, 10)) * 0.1
values = torch.arange(20.0).reshape((2, 10))
torch.bmm(weights.unsqueeze(1), values.unsqueeze(-1))
tensor([[[ 4.5000]],
[[14.5000]]])
weights.shape
torch.Size([2, 10])
weights.unsqueeze(1).shape, values.unsqueeze(-1).shape
(torch.Size([2, 1, 10]), torch.Size([2, 10, 1]))
定义模型
基于上式中的 带参数的注意力汇聚,使用小批量矩阵乘法, 定义Nadaraya-Watson核回归的带参数版本为:
class NWKernelRegression(nn.Module):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.w = nn.Parameter(torch.rand(1,), requires_grad=True)
def forward(self, queries, keys, values):
#queries和attention_weights的形状为(查询个数,“键-值”个数)
queries = queries.repeat_interleave(keys.shape[1]).reshape((-1, keys.shape[1]))
self.attention_weights = nn.functional.softmax(
-((queries - keys) * self.w)**2 / 2, dim=1)
# values的形状为(查询个数,”键-值“对个数)
return torch.bmm(self.attention_weights.unsqueeze(1),
values.unsqueeze(-1)).reshape(-1)
训练
接下来,将训练数据集变换为键和值用于训练注意力模型。 在带参数的注意力汇聚模型中, 任何一个训练样本的输入都会和除自己以外的所有训练样本的“键-值”对进行计算, 从而得到其对应的预测输出。
# X_tile的形状:(n_train, n_train),每一行都包含着相同的训练输入
X_tile = x_train.repeat((n_train, 1))
# Y_tile的形状: (n_train, n_train),每一行都包含着相同的训练输出
Y_tile = y_train.repeat((n_train, 1))
# keys的形状: ('n_train', 'n_train'-1)
keys = X_tile[(1 - torch.eye(n_train)).type(torch.bool)].reshape((n_train, -1))
# values的形状: ('n_train', 'n_train'-1)
values = Y_tile[(1 - torch.eye(n_train)).type(torch.bool)].reshape((n_train, -1))
训练带参数的注意力汇聚模型时,使用平方损失函数和随机梯度下降。
net = NWKernelRegression()
loss = nn.MSELoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=0.5)
animator = d2l.Animator(xlabel='epoch', ylabel='loss', xlim=[1, 5])
for epoch in range(5):
trainer.zero_grad() #清理梯度
l = loss(net(x_train, keys, values), y_train) #计算损失
l.sum().backward() #后向传播
trainer.step() #更新梯度
print(f'epoch {epoch + 1}, loss {float(l.sum()):.6f}')
animator.add(epoch + 1, float(l.sum())) #实时进行绘图

如下所示,训练完带参数的注意力汇聚模型后,我们发现: 在尝试拟合带噪声的训练数据时, 预测结果绘制的线不如之前非参数模型的平滑。
# keys的形状:(n_test, n_train),每一行包含着相同的训练输入(例如,相同的键)
keys = x_train.repeat((n_test, 1))
# values的形状:(n_test, n_train)
values = y_train.repeat((n_test, 1))
y_hat = net(x_test, keys, values).unsqueeze(1).detach()
plot_kernel_reg(y_hat)
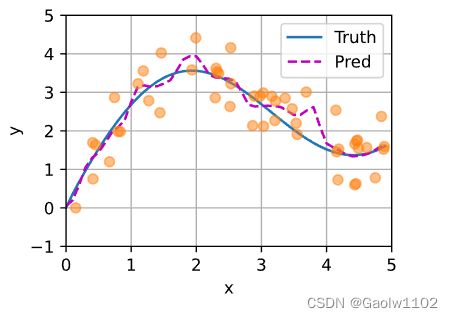
为什么新的模型更不平滑了呢? 我们看一下输出结果的绘制图: 与非参数的注意力汇聚模型相比, 带参数的模型加入可学习的参数后, 曲线在注意力权重较大的区域变得更不平滑。
d2l.show_heatmaps(net.attention_weights.unsqueeze(0).unsqueeze(0),
xlabel='Sorted training inputs',
ylabel='Sorted testing inputs')

小结
1、Nadaraya-Watson核回归是具有注意力机制的机器学习范例。
2、Nadaraya-Watson核回归的注意力汇聚是对训练数据中输出的加权平均。从注意力的角度来看,分配给每个值的注意力权重取决于将值所对应的键和查询作为输入的函数。
4、注意力汇聚可以分为非参数型和带参数型。