推荐系统的因果推断:Causal Inference for Recommender Systems(RecSys,2020)
文章目录
- 说明
- 1. 推荐和因果
- 2. 理论做法
-
- 2.1. 符号说明
- 2.2. 潜在结果下的矩阵分解
- 2.3. 忽略性假设
- 2.4. 经典因果推断
- 3. 去混杂因素推荐器
-
- 3.1. 曝光模型
- 3.2. 结果模型
- 3.3. 为何有效?
- 3.4. 算法
- 4. 实验
-
- 4.1. 评价指标
- 【参考】
- 【修改记录】
说明
这篇博客是一篇论文的学习笔记。
1. 推荐和因果
推荐系统(Recommender System),大家都很熟悉了。
推荐系统的任务为预测 “用户偏好”和“用户评分”。
因果推断(Causal Inference)是确定作为更大系统组成部分的特定现象的独立实际影响的过程。
那么,推荐是如何和因果推断产生关系的呢?
作者认为:
推荐是因果推断!
因为:在预测时,推荐系统尝试回答
“如果一个用户看了一部电影,那么她会怎么评价呢?”
如果我们让用户接触(不接触)电影,评分会是多少?这就是一个关于干预的问题。那么就引出了因果推断问题中的干预(Intervention) 问题。这种因果推断中的关键挑战是未观察到的混杂因素(unobserved confounders),这些变量会影响用户决定与哪些项目进行交互以及他们如何评价它们。
举个例子:
由于用户观看了特定导演的许多电影,因此他们可能经常被推荐该导演的电影并且也倾向于观看和喜欢这些电影。导演是一个使推论产生偏差的混杂因素;它会影响用户被推荐的电影以及他们是否观看和喜欢它们。
简单理解,如果不处理混杂因素,那么得出的推荐是有偏差的,也即是不可信的。
2. 理论做法
2.1. 符号说明
首先给出下面描述需要用到的符号以及它们的意义:
| 符号 | 意义 |
|---|---|
| u u u | 某一个用户 |
| i i i | 某一部电影 |
| a u i a_{ui} aui | u u u 是否对 i i i 评分的标志 |
| y u i ( 1 ) y_{ui}(1) yui(1) | 如果 u u u 看过 i i i, u u u 对 i i i 的评分。这个评分仅当 u u u 看过并且评价过 i i i 时是可观察到的;否则就是未观察到的。 |
| y u i ( 0 ) y_{ui}(0) yui(0) | 如果 u u u 没有看过 i i i, u u u 对 i i i 的评分。通常, y u i ( 0 ) = 0 y_{ui}(0) = 0 yui(0)=0 |
| ( y u i ( 0 ) , y u i ( 1 ) ) \left( y_{ui}(0), y_{ui}(1) \right) (yui(0),yui(1)) | 潜在结果 |
| { a u i , u = 1 , … , U , i = 1 , … , I } \{a_{ui}, u = 1,\dots,U, i = 1, \dots, I \} {aui,u=1,…,U,i=1,…,I} | 包含(二元)曝光的数据集。它指示了谁看了什么 |
| { y u i ( a u i ) ∣ ( u , i ) , a u i = 1 } \{y_{ui}(a_{ui}) \mid (u, i), a_{ui} = 1 \} {yui(aui)∣(u,i),aui=1} | 用户看过的电影评分数据集 |
2.2. 潜在结果下的矩阵分解
在推荐系统的矩阵分解中,将原始评分矩阵 R R R 分解为用户偏好矩阵 X X X 和项目属性矩阵 Y Y Y,即:
R U × I ≈ X U × K Y K × I . R_{U \times I} \approx X_{U \times K} Y_{K \times I}. RU×I≈XU×KYK×I.
其中, K K K 为指定的维度, K ≪ U , I K \ll U, I K≪U,I。
在潜在结果下,重组矩阵分解。输出模型如下:
y u i ( a ) = θ u T β i ⋅ a + ϵ u i , ϵ u i ∼ N ( 0 , σ 2 ) (1) \qquad \qquad y_{ui}(a) = \theta_u^{\rm{T}}\beta_i \cdot a + \epsilon_{ui}, \quad \epsilon_{ui} \sim \mathcal{N}(0, \sigma^2) \qquad \textbf{(1)} yui(a)=θuTβi⋅a+ϵui,ϵui∼N(0,σ2)(1)
其中, θ u \theta_u θu 是用户偏好, β i \beta_i βi 是项目属性。
- 当 a = 1 a = 1 a=1 时( u u u 看过 i i i),该模型表示评分来自高斯分布,其均值结合了 θ u \theta_u θu 和 β i \beta_i βi。
E [ y u i ( a ) ] = E [ y u i ( 1 ) ] = E [ θ u T β i + ϵ u i ] = E [ θ u T β i ] + E [ ϵ u i ] = θ u T β i . \begin{aligned} \mathbb{E}\left[ y_{ui}(a) \right] &= \mathbb{E} \left[ y_{ui}(1) \right] \\ &=\mathbb{E} \left[\theta_u^{\rm{T}}\beta_i + \epsilon_{ui} \right] \\ &= \mathbb{E} \left[\theta_u^{\rm{T}}\beta_i \right] + \mathbb{E}\left[ \epsilon_{ui} \right] \\ &= \theta_u^{\rm{T}}\beta_i \end{aligned}. E[yui(a)]=E[yui(1)]=E[θuTβi+ϵui]=E[θuTβi]+E[ϵui]=θuTβi. - 当 a = 0 a = 0 a=0 时,评分是零均值高斯。
E [ y u i ( a ) ] = E [ y u i ( 0 ) ] = E [ ϵ u i ] = 0. \mathbb{E}\left[ y_{ui}(a) \right] = \mathbb{E} \left[ y_{ui}(0) \right] = \mathbb{E}\left[ \epsilon_{ui} \right] = 0. E[yui(a)]=E[yui(0)]=E[ϵui]=0.
拟合方程 (1) 对观察到的数据恢复了经典的概率矩阵分解。它的对数似然只涉及观察到的评分;它忽略未曝光的项目。
2.3. 忽略性假设
方程 (1) 并没有给出 y u i ( 1 ) y_{ui}(1) yui(1) 的无偏因果推断。潜在结果理论告诉我们,只有在忽略性(ignorability)假设下估计 y u i ( 1 ) y_{ui}(1) yui(1)。对于所有的用户 u u u,忽略性要求 { y u ( 0 ) , y u ( 1 ) } ⊥ ⊥ a u \{\bm{y_u}(0), \bm{y_u}(1) \} \perp\!\!\! \perp \bm{a}_u {yu(0),yu(1)}⊥⊥au,其中 y u ( a ) = ( y u 1 ( a ) , … , y u I ( a ) ) \bm{y_u}(a) =\left(y_{u1}(a),\dots,y_{uI}(a) \right) yu(a)=(yu1(a),…,yuI(a)), a u = ( a u 1 , … , a u I ) \bm{a}_u=\left(a_{u1},\dots,a_{uI} \right) au=(au1,…,auI)。也就是说,用户观看的电影向量 a u \bm{a}_u au 和如果她看完了所有电影并且如何评分 y u ( 1 ) \bm{y}_u(1) yu(1) (如果都没看的话,就是 y u ( 0 ) \bm{y}_u(0) yu(0))之间相互独立。
很显然,忽略性假设并不满足。
2.4. 经典因果推断
将推荐框架化为因果问题与传统方法不同。传统方法从观察到的评分数据构建模型,通常是矩阵分解,然后使用该模型来预测看不见的评分。
如果用户随机观看电影,在上述干预意义上,这种策略才能提供有效的因果推断。(类似于临床随机试验,不现实的试验条件。)
用户(通常)不会随机看电影,因此从观察的评分数据中回答因果问题具有挑战性。问题是可能存在影响处理分配(用户观看哪些电影)和结果(他们如何评价它们)的混杂因素(confounders)。
当可忽略性不成立时,经典因果推断要求我们测量和控制混杂因素。这些是影响曝光和评分的变量。以用户的位置为例,它会影响他们看的电影以及(也许)他们喜欢什么样的电影。
假设我们测量了每个用户的混杂因素 w u w_u wu,满足 { y u ( 0 ) , y u ( 1 ) } ⊥ ⊥ a u ∣ w u \left\{\bm{y}_u(0), \bm{y}_u(1) \right\} \perp\!\!\! \perp \bm{a}_u | w_u {yu(0),yu(1)}⊥⊥au∣wu。
结果模型为:
y u i ( a ) = θ u T β i ⋅ a + η T w u + ϵ u i , ϵ u i ∼ N ( 0 , σ 2 ) . y_{ui}(a)=\theta_u^{\rm{T}}\beta_i \cdot a + \eta^{\rm{T}}w_u + \epsilon_{ui}, \quad \epsilon_{ui} \sim \mathcal{N}(0, \sigma^2). yui(a)=θuTβi⋅a+ηTwu+ϵui,ϵui∼N(0,σ2).
但是上述模型要求测量所有的混杂因素,这种假设也被称为强忽略性(strong ignorability)。然而,这是不现实的。
3. 去混杂因素推荐器
作者提出了一种为未观察到的混杂纠正经典矩阵分解的去混杂推荐器(deconfounded recommender)。
去混淆推荐器建立在推荐数据中的两个信息源之上:每个用户决定观看哪些电影以及用户对这些电影的评分。
它假设这两种类型的信息来自不同的模型——曝光数据来自用户发现要观看的电影的模型; 评分数据来自用户决定他们喜欢哪些电影的模型。
评分数据涉及两种类型的信息——用户只对他们看过的电影进行评分——因此经典矩阵分解受到曝光模型的影响,即用户不是随机接触电影的。
去混淆推荐器试图纠正这种偏见。去混淆推荐器包含两个模型。第一个模型使用曝光数据来评估一个用户可能考虑的电影模型。接着使用这个曝光模型来估计一个不可观察混杂因素的替代品。其次,它使评价模型适合考虑替代混淆因素。
关键思想是推荐系统的因果推理是一个多重因果推理问题:有多种处理方法。每个用户对每部电影 a u i a_{ui} aui 的二元曝光是一种处理;因此,每个用户都有 I I I 种治疗方法。评分向量 y u ( 1 ) \bm{y}_u(1) yu(1) 是输出;这是一个 I I I 维向量,其中的部分是可观察的。处理的多样性使带未观察到的混杂因素的因果推断成为可能。
3.1. 曝光模型
第一步是将模型拟合到曝光数据。我们使用泊松分解 (Poisson Factorization,PF) 模型。PF 假定数据来自于:
a u i ∣ π u , λ i ∼ Poisson ( π u T λ i ) , ∀ u , i (2) \qquad a_{ui} \mid \pi_u, \lambda_i \sim \text{Poisson}(\pi_u^{\rm{T}}\lambda_i), \qquad \qquad \forall u, i \quad \textbf{(2)} aui∣πu,λi∼Poisson(πuTλi),∀u,i(2)
其中, π u ∼ i i d Gamma ( c 1 , c 2 ) \pi_u \sim^{iid} \text{Gamma}(c_1, c_2) πu∼iidGamma(c1,c2), λ i ∼ i i d Gamma ( c 3 , c 4 ) \lambda_i \sim^{iid} \text{Gamma}(c_3,c_4) λi∼iidGamma(c3,c4)。
用户向量 π u \pi_u πu 捕获了用户偏好,而项目向量 λ i \lambda_i λi 捕获了项目属性。
使用拟合的 PF 模型,去混杂的推荐器计算未观察到的混杂因素的替代品。它从 PF 拟合重建曝光矩阵 a ^ \hat{a} a^:
a ^ u i = E PF [ π u T λ i ∣ a ] , (3) \qquad \qquad \quad \hat{a}_{ui}=\mathbb{E}_{\text{PF}} \left[ \pi_u^{\rm{T}} \lambda_i \mid \bm{a} \right], \qquad \qquad \qquad \textbf{(3)} a^ui=EPF[πuTλi∣a],(3)
其中 a \bm{a} a 是观察到的所有用户的曝光,并且期望取自 PF 模型计算的后验。
这是 π u T λ i \pi_u^{\rm{T}}\lambda_i πuTλi 的后验预测平均值,用作替代混杂因素。
最后,去混杂的推荐器建立了一个以替代混杂因素 a ^ \hat{a} a^ 为条件的结果模型,
y u i ( a ) = θ u T β i ⋅ a + γ u ⋅ a ^ u i + ϵ u i , ϵ u i ∼ N ( 0 , σ 2 ) (4) y_{ui}(a)=\theta_u^{\rm{T}}\beta_i \cdot a +\gamma_u \cdot \hat{a}_{ui} + \epsilon_{ui}, \quad \epsilon_{ui} \sim \mathcal{N}(0, \sigma^2) \quad \textbf{(4)} yui(a)=θuTβi⋅a+γu⋅a^ui+ϵui,ϵui∼N(0,σ2)(4)
其中 γ u \gamma_u γu 是一个用户特定的系数,描述了替代混杂因素 a ^ \hat{a} a^ 对评分的贡献程度。
去混淆推荐器将此结果模型与观察到的数据相匹配;它通过最大化后验估计(maximum a posteriori,MAP) 估计推断出 θ u \theta_u θu、 β i \beta_i βi、 γ u \gamma_u γu。方程中 (4) 的系数 θ u \theta_u θu, β i \beta_i βi 只适合观察到的用户评分(即 a u i = 1 a_{ui} = 1 aui=1),因为 a u i = 0 a_{ui} = 0 aui=0 会将涉及他们的项置零;相反,系数 γ u \gamma_u γu 适合所有电影( a u i = 0 a_{ui} = 0 aui=0 和 a u i = 1 a_{ui} = 1 aui=1),因为 a ^ u i \hat{a}_{ui} a^ui 总是非零。
为了形成推荐,去混淆推荐器使用拟合的 θ u \theta_u θu, β i \beta_i βi, γ u \gamma_u γu 计算所有潜在评分 y u i ( 1 ) y_{ui}(1) yui(1)。然后它对未看过的电影的潜在评分进行排序。这些是因果推荐。
3.2. 结果模型
推荐器包含两个模型,一个用于曝光,一个用于输出。
PF 作为暴光模型和概率矩阵分解作为结果模型。
矩阵分解的一般形式:
y u i ( a ) ∼ p ( ⋅ ∣ m ( θ u T β i , a ) , v ( θ u T β i , a ) ) (5) \qquad \qquad y_{ui}(a)\sim p\left(\cdot \big| m(\theta_u^{\rm{T}}\beta_i, a), v(\theta_u^{\rm{T}}\beta_i, a) \right) \qquad \qquad \textbf{(5)} yui(a)∼p(⋅∣∣m(θuTβi,a),v(θuTβi,a))(5)
其中, m ( θ u T β i , a ) m(\theta_u^{\rm{T}}\beta_i, a) m(θuTβi,a) 和 v ( θ u T β i , a ) v(\theta_u^{\rm{T}}\beta_i, a) v(θuTβi,a) 分别表征评分 y u i ( a ) y_{ui}(a) yui(a) 的均值和方差。
这种形式包含许多分解模型,包括概率、加权和泊松矩阵分解。
然后,去混淆的推荐器拟合一个增强的结果模型 M Y M_Y MY 。这个结果模型 M Y M_Y MY 包括替代混杂因素:
y u i ( a ) ∼ p ( ⋅ ∣ m ( θ u T β i , a ) + γ u a ^ u i + β 0 , v ( θ u T β i , a ) ) (6) y_{ui}(a) \sim p\left(\cdot \big| m(\theta_u^{\rm{T}}\beta_i, a) + \gamma_u \hat{a}_{ui} + \beta_0, v(\theta_u^{\rm{T}}\beta_i, a) \right) \qquad \textbf{(6)} yui(a)∼p(⋅∣∣m(θuTβi,a)+γua^ui+β0,v(θuTβi,a))(6)
其中,参数 γ u \gamma_u γu 是用户特定的系数;对于每个用户,它表征替代混杂因素 a ^ \hat{a} a^ 对评分的贡献程度。
这些去混淆的结果模型可以通过 MAP 估计来拟合。
3.3. 为何有效?
PF 从曝光矩阵 a u i a_{ui} aui 中学习一个每个用户的潜变量 π u \pi_u πu,作为替代混杂因素。
证明这种方法的理由是 PF 承认一个特殊的条件独立结构:以 π u \pi_u πu 为条件,处理 a u i a_{ui} aui 是独立的(等式 (2))。如果曝光模型 PF 很好地拟合了数据,那么每个用户的潜在变量 π u \pi_u πu(或它的函数,如 a ^ u i \hat{a}_{ui} a^ui)捕获了多重处理混杂因素,即与多次曝光和评分向量相关的变量。我们注意到真正的混杂机制不需要与 PF 一致,真正的混杂机制也不需要与 π u \pi_u πu 一致。相反,PF 会产生一个替代混杂因素,足以消除混杂因素。
3.4. 算法
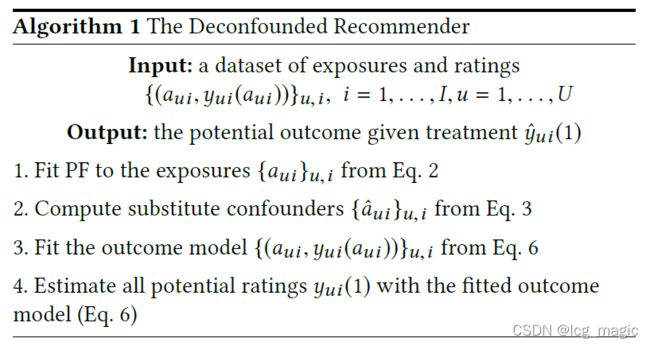
4. 实验
4.1. 评价指标
Recall:召回率
NDCG:
err rand = 1 U ∑ u = 1 U l ( { y ^ u i } i ∈ I u , { y u i ( 1 ) } i ∈ I u ) \text{err}_{\text{rand}} = \frac{1}{U} \sum_{u=1}^U l \left(\left\{\hat{y}_{ui} \right\}_{i \in \mathcal{I}_u} , \left\{y_{ui}(1) \right\}_{i \in \mathcal{I}_u} \right) errrand=U1u=1∑Ul({y^ui}i∈Iu,{yui(1)}i∈Iu)
其中 l l l 是损失函数,例如均方误差 (mean squared error,MSE) 或归一化贴现累积增益 (normalized discounted cumulative gain,NDCG);从所有项目中随机选择的子集 I u \mathcal{I}_u Iu。
【参考】
- YixinWang, Dawen Liang, Laurent Charlin, and David M. Blei. Causal inference for recommender systems. Proceedings of the fourteenth ACM conference on recommender systems (RecSys ’20). 2020: 426–431.
- Wikipedia: Recommender System.
- Wikipedia: Causal Inference.
【修改记录】
| 时间 | 内容 |
|---|---|
| 2022年4月20日16:30:05 | 参考文献格式 |