PyTorch学习—17.正则化之weight_decay与dropout
文章目录
-
-
- 一、正则化与偏差-方差分解
- 二、pytorch中的L2正则项—weight decay(权值衰减)
- 三、Dropout概念
- 四、dropout抑制过拟合的工作原理
- 五、dropout内部是怎么实现只让部分信号通过并不更新其余部分
- 六、Dropout的注意事项
- 七、PyTorch中的Dropout网络层
-
- 1.PyTorch中Dropout的实现细节
-
一、正则化与偏差-方差分解
正则化方法是机器学习(深度学习)中重要的方法,它目的在于减小方差。下面借助周志华老师西瓜书中的对于方差、偏差的定义来进行理解。
泛化误差可分解为:偏差、方差与噪声之和。
- 偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力
- 方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响
- 噪声则表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界

正则化方法就是减小方差的策略。常见的过拟合就会导致高方差,因此,人们常用正则化降低方差来解决过拟合。
正则化有L1正则化与L2正则化,通常就是损失函数加上正则项。
= + R e g u l a r i z a t i o n T e r m = + Regula riza tion Term Obj=Cost+RegularizationTerm
L1 Regularization Term: ∑ i N ∣ w i ∣ \sum_i^N|w_i| ∑iN∣wi∣
L2 Regularization Term: ∑ i N w i 2 \sum_i^Nw_i^2 ∑iNwi2
关于L1正则化与L2正则化面试中常涉及到如下问题:百面机器学习—13.L1正则化与稀疏性
二、pytorch中的L2正则项—weight decay(权值衰减)
加入L2正则项后,目标函数:
O b j = L o s s + λ 2 ∗ ∑ i N w i 2 w i + 1 = w i − ∂ O b j ∂ w i = w i ( 1 − λ ) − ∂ L o s s ∂ w i Obj=Loss + \frac{\lambda}{2}*\sum_i^Nw_i^2\\w_{i+1}=w_i-\frac{\partial{Obj}}{\partial{w_i}}=w_i(1-\lambda)-\frac{\partial{Loss}}{\partial{w_i}} Obj=Loss+2λ∗i∑Nwi2wi+1=wi−∂wi∂Obj=wi(1−λ)−∂wi∂Loss
0 < λ < 1 0<\lambda<1 0<λ<1,L2正则项又称为权值衰减。
下面通过一个小例子来试验weight decay。
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from torch.utils.tensorboard import SummaryWriter
n_hidden = 200
max_iter = 2000
disp_interval = 200
lr_init = 0.01
# ============================ step 1/5 数据 ============================
def gen_data(num_data=10, x_range=(-1, 1)):
w = 1.5
train_x = torch.linspace(*x_range, num_data).unsqueeze_(1)
train_y = w*train_x + torch.normal(0, 0.5, size=train_x.size())
test_x = torch.linspace(*x_range, num_data).unsqueeze_(1)
test_y = w*test_x + torch.normal(0, 0.3, size=test_x.size())
return train_x, train_y, test_x, test_y
train_x, train_y, test_x, test_y = gen_data(x_range=(-1, 1))
# ============================ step 2/5 模型 ============================
class MLP(nn.Module):
def __init__(self, neural_num):
super(MLP, self).__init__()
# 三层的全连接网络
self.linears = nn.Sequential(
nn.Linear(1, neural_num),
nn.ReLU(inplace=True),
nn.Linear(neural_num, neural_num),
nn.ReLU(inplace=True),
nn.Linear(neural_num, neural_num),
nn.ReLU(inplace=True),
nn.Linear(neural_num, 1),
)
# 前向传播
def forward(self, x):
return self.linears(x)
# 网络实例化
net_normal = MLP(neural_num=n_hidden)
net_weight_decay = MLP(neural_num=n_hidden)
# ============================ step 3/5 优化器 ============================
optim_normal = torch.optim.SGD(net_normal.parameters(), lr=lr_init, momentum=0.9)
optim_wdecay = torch.optim.SGD(net_weight_decay.parameters(), lr=lr_init, momentum=0.9, weight_decay=1e-2)
# ============================ step 4/5 损失函数 ============================
loss_func = torch.nn.MSELoss()
# ============================ step 5/5 迭代训练 ============================
writer = SummaryWriter(comment='_test_tensorboard', filename_suffix="12345678")
for epoch in range(max_iter):
# forward
pred_normal, pred_wdecay = net_normal(train_x), net_weight_decay(train_x)
loss_normal, loss_wdecay = loss_func(pred_normal, train_y), loss_func(pred_wdecay, train_y)
# 梯度清零
optim_normal.zero_grad()
optim_wdecay.zero_grad()
# 反向传播
loss_normal.backward()
loss_wdecay.backward()
# 模型逐步更新
optim_normal.step()
optim_wdecay.step()
if (epoch+1) % disp_interval == 0:
# 可视化-统计直方图分布
for name, layer in net_normal.named_parameters():
writer.add_histogram(name + '_grad_normal', layer.grad, epoch)
writer.add_histogram(name + '_data_normal', layer, epoch)
for name, layer in net_weight_decay.named_parameters():
writer.add_histogram(name + '_grad_weight_decay', layer.grad, epoch)
writer.add_histogram(name + '_data_weight_decay', layer, epoch)
# 测试
test_pred_normal, test_pred_wdecay = net_normal(test_x), net_weight_decay(test_x)
# 绘图
plt.scatter(train_x.data.numpy(), train_y.data.numpy(), c='blue', s=50, alpha=0.3, label='train')
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='red', s=50, alpha=0.3, label='test')
plt.plot(test_x.data.numpy(), test_pred_normal.data.numpy(), 'r-', lw=3, label='no weight decay')
plt.plot(test_x.data.numpy(), test_pred_wdecay.data.numpy(), 'b--', lw=3, label='weight decay')
plt.text(-0.25, -1.5, 'no weight decay loss={:.6f}'.format(loss_normal.item()), fontdict={'size': 15, 'color': 'red'})
plt.text(-0.25, -2, 'weight decay loss={:.6f}'.format(loss_wdecay.item()), fontdict={'size': 15, 'color': 'red'})
plt.ylim((-2.5, 2.5))
plt.legend(loc='upper left')
plt.title("Epoch: {}".format(epoch+1))
plt.show()
plt.close()



可以发现:随着训练轮数的增加,有权值衰减的模型的泛化能力越强。
未权值衰减的权值变化为:

权值衰减的权值变化为:

权值衰减控制权值逐渐减小,以至于模型不复杂,从而不会产生非常严重的过拟合。
下面,我们看一下pytorch中的权值衰减是如何实现的?
def step(self, closure=None):
"""Performs a single optimization step.
Arguments:
closure (callable, optional): A closure that reevaluates the model
and returns the loss.
"""
loss = None
if closure is not None:
with torch.enable_grad():
loss = closure()
for group in self.param_groups:
weight_decay = group['weight_decay']
momentum = group['momentum']
dampening = group['dampening']
nesterov = group['nesterov']
for p in group['params']:
if p.grad is None:
continue
d_p = p.grad
if weight_decay != 0:
d_p = d_p.add(p, alpha=weight_decay)
if momentum != 0:
param_state = self.state[p]
if 'momentum_buffer' not in param_state:
buf = param_state['momentum_buffer'] = torch.clone(d_p).detach()
else:
buf = param_state['momentum_buffer']
buf.mul_(momentum).add_(d_p, alpha=1 - dampening)
if nesterov:
d_p = d_p.add(buf, alpha=momentum)
else:
d_p = buf
p.add_(d_p, alpha=-group['lr'])
return loss
核心代码为:
for group in self.param_groups:
weight_decay = group['weight_decay']
momentum = group['momentum']
dampening = group['dampening']
nesterov = group['nesterov']
for p in group['params']:
if p.grad is None:
continue
d_p = p.grad
if weight_decay != 0:
d_p = d_p.add(p, alpha=weight_decay)
if momentum != 0:
param_state = self.state[p]
即
d p = d p + p ∗ w e i g h t d e c a y d_p=d_p+p*weight_decay dp=dp+p∗weightdecay
三、Dropout概念
Dropout可以总结为四个字:随机失活。失活可以理解为权值为0。从对特征的依赖性角度来讲,假设某个神经元接受上一层的5个神经元,如果其特别依赖第一个神经元,比如权重是5,剩余4个权重都是0.0001,那么,这个神经元就非常依赖权重为5的神经元。如果第一个神经元出现,则这个神经元激活,否则,可能不被激活。如果加入Dropout后,当前的神经元就不会知道上一层的神经元哪些神经元会出现,所以就不会对某些神经元进行过度依赖。减轻神经元对某些特征的过度依赖性,提高了特征的鲁棒性,实现了正则化。
Dropout是指在深度网络的训练中,以一定的概率 p p p随机地“临时丢弃”一部分神经元节点(即以一定概率使部分神经元节点随机失活)。具体来讲,Dropout作用于每份小批量训练数据,由于其随机丢弃部分神经元的机制,相当于每次迭代都在训练不同结构的神经网络。Dropout在小批量级别上的操作,提供了一种轻量级的 Bagging 集成近似,能够实现指数级数量神经网络的训练与评测。
Dropout可被认为是一种实用的大规模深度神经网络的模型集成算法。这是由于传统意义上的Bagging涉及多个模型的同时训练与测试评估,当网络与参数规模庞大时,这种集成方式需要消耗大量的运算时间与空间。
四、dropout抑制过拟合的工作原理
Dropout的具体实现中,要求某个神经元节点激活值以一定的概率p被“丢弃”,即该神经元暂时停止工作。

因此,对于包含 N N N个神经元节点的网络,在 Dropout的作用下可看作为 2 N 2^N 2N个模型的集成。这 2 N 2^N 2N个模型可认为是原始网络的子网络,它们共享部分权值,并且具有相同的网络层数,而模型整体的参数数目不变,这就大大简化了运算。对于任意神经元,每次训练中都与一组随机挑选的不同的神经元集合共同进行优化,这个过程会减弱全体神经元之间的联合适应性,减少过拟合的风险,增强泛化能力。
五、dropout内部是怎么实现只让部分信号通过并不更新其余部分
标准网络与Dropout网络对比如下:
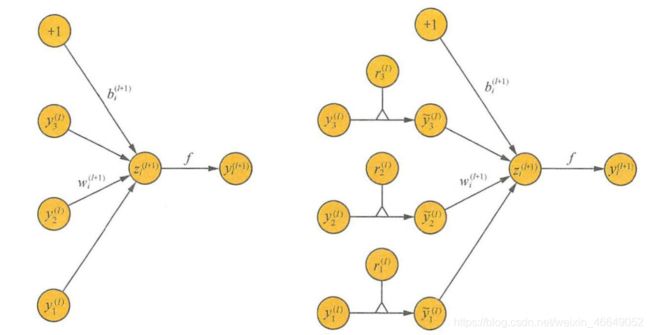
原始网络对应的前向传播公式为:
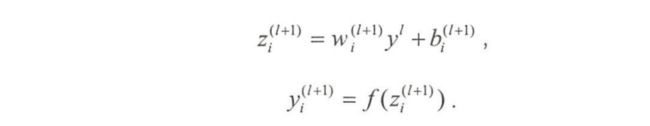
Dropout网络对应的前向传播公式为:

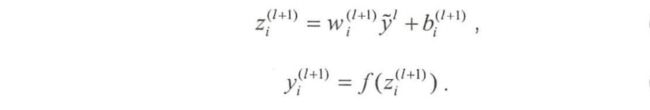
上面的 Bernoulli 函数的作用是以概率系数p随机生成一个取值为0或1的向量,代表每个神经元是否需要被丢弃。如果取值为0,则该神经元将不会计算梯度或参与后面的误差传播。
六、Dropout的注意事项
深度学习中常见的正则化方法—Dropout,Dropout是简洁高效的正则化方法,但需要注意其在实现过程中的权值数据尺度问题。在测试时,所有权重乘以 1 − d r o p _ p r o b 1-drop\_prob 1−drop_prob,这个在《Dropout: A simple way to prevent neural networks from overfitting》论文中被提到。在写代码时要注意到将训练时的数据尺度与测试时的数据尺度保持一致。比如: d r o p _ p r o b = 0.3 drop\_prob=0.3 drop_prob=0.3,那么训练时的数据尺度为测试时的数据尺度的0.7,所以需要在测试时,所有权重乘以 1 − d r o p _ p r o b 1-drop\_prob 1−drop_prob。
七、PyTorch中的Dropout网络层
torch.nn.Dropout(p=0.5, inplace=False)
功能:Dropout层
参数:
- p:被舍弃概率,失活概率
下面我们通过代码来观察Dropout的影响
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from torch.utils.tensorboard import SummaryWriter
n_hidden = 200
max_iter = 2000
disp_interval = 400
lr_init = 0.01
# ============================ step 1/5 数据 ============================
def gen_data(num_data=10, x_range=(-1, 1)):
w = 1.5
train_x = torch.linspace(*x_range, num_data).unsqueeze_(1)
train_y = w*train_x + torch.normal(0, 0.5, size=train_x.size())
test_x = torch.linspace(*x_range, num_data).unsqueeze_(1)
test_y = w*test_x + torch.normal(0, 0.3, size=test_x.size())
return train_x, train_y, test_x, test_y
train_x, train_y, test_x, test_y = gen_data(x_range=(-1, 1))
# ============================ step 2/5 模型 ============================
class MLP(nn.Module):
def __init__(self, neural_num, d_prob=0.5):
super(MLP, self).__init__()
self.linears = nn.Sequential(
nn.Linear(1, neural_num),
nn.ReLU(inplace=True),
nn.Dropout(d_prob),
nn.Linear(neural_num, neural_num),
nn.ReLU(inplace=True),
nn.Dropout(d_prob),
nn.Linear(neural_num, neural_num),
nn.ReLU(inplace=True),
nn.Dropout(d_prob),
nn.Linear(neural_num, 1),
)
def forward(self, x):
# 采用Sequential可以一步实现forward
return self.linears(x)
# 模型实例化
net_prob_0 = MLP(neural_num=n_hidden, d_prob=0.)
net_prob_05 = MLP(neural_num=n_hidden, d_prob=0.5)
# ============================ step 3/5 优化器 ============================
optim_normal = torch.optim.SGD(net_prob_0.parameters(), lr=lr_init, momentum=0.9)
optim_reglar = torch.optim.SGD(net_prob_05.parameters(), lr=lr_init, momentum=0.9)
# ============================ step 4/5 损失函数 ============================
loss_func = torch.nn.MSELoss()
# ============================ step 5/5 迭代训练 ============================
writer = SummaryWriter(comment='_test_tensorboard', filename_suffix="12345678")
for epoch in range(max_iter):
pred_normal, pred_wdecay = net_prob_0(train_x), net_prob_05(train_x)
loss_normal, loss_wdecay = loss_func(pred_normal, train_y), loss_func(pred_wdecay, train_y)
optim_normal.zero_grad()
optim_reglar.zero_grad()
loss_normal.backward()
loss_wdecay.backward()
optim_normal.step()
optim_reglar.step()
if (epoch+1) % disp_interval == 0:
# 由于dropout的训练与测试是不一样的,eval()表示设置当前网络采用测试的状态,而不是训练的状态
net_prob_0.eval()
net_prob_05.eval()
# 可视化
for name, layer in net_prob_0.named_parameters():
writer.add_histogram(name + '_grad_normal', layer.grad, epoch)
writer.add_histogram(name + '_data_normal', layer, epoch)
for name, layer in net_prob_05.named_parameters():
writer.add_histogram(name + '_grad_regularization', layer.grad, epoch)
writer.add_histogram(name + '_data_regularization', layer, epoch)
# 测试,在测试前,需要将模型设置为测试状态
test_pred_prob_0, test_pred_prob_05 = net_prob_0(test_x), net_prob_05(test_x)
# 绘图
plt.clf()
plt.scatter(train_x.data.numpy(), train_y.data.numpy(), c='blue', s=50, alpha=0.3, label='train')
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='red', s=50, alpha=0.3, label='test')
plt.plot(test_x.data.numpy(), test_pred_prob_0.data.numpy(), 'r-', lw=3, label='d_prob_0')
plt.plot(test_x.data.numpy(), test_pred_prob_05.data.numpy(), 'b--', lw=3, label='d_prob_05')
plt.text(-0.25, -1.5, 'd_prob_0 loss={:.8f}'.format(loss_normal.item()), fontdict={'size': 15, 'color': 'red'})
plt.text(-0.25, -2, 'd_prob_05 loss={:.6f}'.format(loss_wdecay.item()), fontdict={'size': 15, 'color': 'red'})
plt.ylim((-2.5, 2.5))
plt.legend(loc='upper left')
plt.title("Epoch: {}".format(epoch+1))
plt.show()
plt.close()
# 在测试完后,需要将网络重新恢复到训练状态
net_prob_0.train()
net_prob_05.train()

Dropout与weight_decay一样,同样使得权重尺度发生变化。下面通过TensorBoard来观察线性层的权值区别
未dropout的权值:

dropout的权值:

下面分析pytorch中的eval()与train()实现了什么功能?
def train(self: T, mode: bool = True) -> T:
r"""Sets the module in training mode.
This has any effect only on certain modules. See documentations of
particular modules for details of their behaviors in training/evaluation
mode, if they are affected, e.g. :class:`Dropout`, :class:`BatchNorm`,
etc.
Args:
mode (bool): whether to set training mode (``True``) or evaluation
mode (``False``). Default: ``True``.
Returns:
Module: self
"""
self.training = mode
for module in self.children():
module.train(mode)
return self
def eval(self: T) -> T:
r"""Sets the module in evaluation mode.
This has any effect only on certain modules. See documentations of
particular modules for details of their behaviors in training/evaluation
mode, if they are affected, e.g. :class:`Dropout`, :class:`BatchNorm`,
etc.
This is equivalent with :meth:`self.train(False) `.
Returns:
Module: self
"""
return self.train(False)
self.training是False,则表示模型是测试状态;self.training是True,则表示模型是训练状态。
1.PyTorch中Dropout的实现细节
为了在测试时,测试更简单,训练时权重均乘以 1 1 − \frac{1}{1−} 1−p1 ,即除以 1 − p 1-p 1−p;此时,测试时,所有权重就不需要乘以 1 − d r o p _ p r o b 1-drop\_prob 1−drop_prob。两者抵消。
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self, neural_num, d_prob=0.5):
super(Net, self).__init__()
self.linears = nn.Sequential(
nn.Dropout(d_prob),
nn.Linear(neural_num, 1, bias=False),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.linears(x)
# 输入张量
input_num = 10000
x = torch.ones((input_num, ), dtype=torch.float32)
net = Net(input_num, d_prob=0.5)
# 权重设置为1
net.linears[1].weight.detach().fill_(1.)
# train模式
net.train()
y = net(x)
print("output in training mode", y)
# eval模式
net.eval()
y = net(x)
print("output in eval mode", y)
output in training mode tensor([9956.], grad_fn=<ReluBackward1>)
output in eval mode tensor([10000.], grad_fn=<ReluBackward1>)
如果对您有帮助,麻烦点赞关注,这真的对我很重要!!!如果需要互关,请评论或者私信!
