一种改进的鲸鱼优化算法-附代码
一种改进的鲸鱼优化算法
文章目录
- 一种改进的鲸鱼优化算法
-
- 1.鲸鱼优化算法
- 2. 改进鲸鱼优化算法
-
- 2.1 准反向学习初始化种群
- 2.2 非线性收敛因子
- 2.3 自适应权重策略与随机差分法变异策略
- 3.实验结果
- 4.参考文献
- 5.Matlab代码
- 6.Python代码
摘要: 针对鲸鱼优化算法( whale optimization algorithm,WOA) 容易陷入局部最优和收敛精度低的问题进行了研究,提出一种改进的鲸鱼优化算法( IWOA) 。该算法通过准反向学习方法来初始化种群,提高种群的多样性;然后将线性收敛因子修改为非线性收敛因子,有利于平衡全局搜索和局部开发能力; 另外,通过增加自适应权重改进鲸鱼优化算法的局部搜索能力,提高收敛精度; 最后,通过随机差分变异策略及时调整鲸鱼优化算法,避免陷入局部最优。
1.鲸鱼优化算法
基础鲸鱼算法的具体原理参考,我的博客:https://blog.csdn.net/u011835903/article/details/107559167
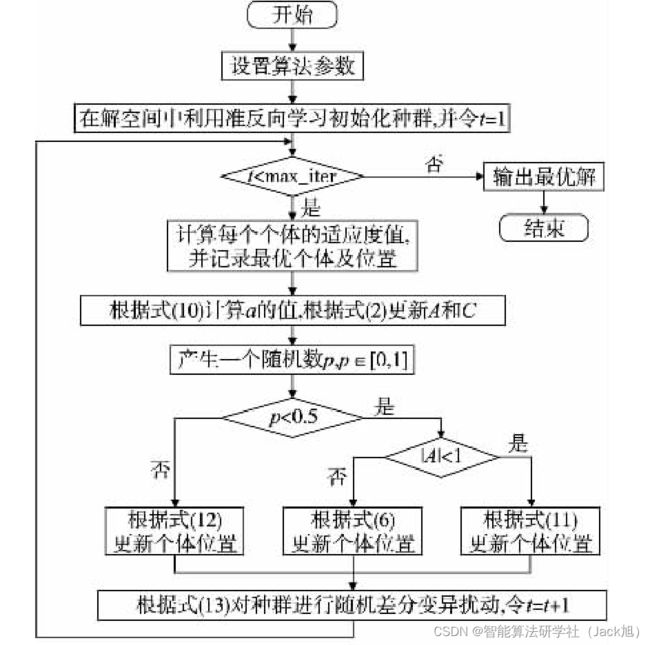
2. 改进鲸鱼优化算法
2.1 准反向学习初始化种群
Gondro 等人 [ 8 ] { }^{[8]} [8] 指出高质量的初始化种群对算法的求解精 度和收敛速度等性能有很大的帮助。然而, 基本的鲸鱼优化算 法采用的是随机初始化的方法, 该方法随机性很大, 不能保证 初始种群的多样性。为了保证初始化种群的多样性, 采用了反 向学习的改进方法, 即准反向学习来初始化种群。
反向学习 [ 6 , 9 , 10 ] { }^{[6,9,10]} [6,9,10] 是在明确变量的范围边界, 通过按照一定 的规则来求其对应的反向解, 其详细内容如下:
假设鲸鱼种群的规模为 N N N, 搜索空间为 d d d 维, 第 i i i 只鲸鱼 在第 d d d 维空间中的位置可以表示为 X i = ( x i 1 , x i 2 , ⋯ , x i d ) ( i = 1 \boldsymbol{X}_{i}=\left(x_{i}^{1}, x_{i}^{2}, \cdots, x_{i}^{d}\right)(i=1 Xi=(xi1,xi2,⋯,xid)(i=1, 2 , ⋯ , N ) , x i j ∈ [ a i j , b i j ] ( j = 1 , 2 , ⋯ , d ) , a i j 2, \cdots, N), x_{i}^{j} \in\left[a_{i}^{j}, b_{i}^{j}\right](j=1,2, \cdots, d), a_{i}^{j} 2,⋯,N),xij∈[aij,bij](j=1,2,⋯,d),aij 和 b i j b_{i}^{j} bij 分别表示 x i j x_{i}^{j} xij 的 下界和上界,其对应反向解如下:
x ^ i j = a i j + b i j − x i j (7) \hat{x}_{i}^{j}=a_{i}^{j}+b_{i}^{j}-x_{i}^{j} \tag{7} x^ij=aij+bij−xij(7)
在实际应用中, 反向解的效果并不一定很好, 本文为了解 决这一问题采用了准反向解的方法, 该方法可以根据式 (7) 演 变得到:
x i j ^ = { rand ( avg i j , x ^ i j ) x i j ⩽ avg i j rand ( x ^ i j , avg i j ) x i j > avg i j (8) \hat{x_{i}^{j}}= \begin{cases}\operatorname{rand}\left(\operatorname{avg}_{i}^{j}, \hat{x}_{i}^{j}\right) & x_{i}^{j} \leqslant \operatorname{avg}_{i}^{j} \\ \operatorname{rand}\left(\hat{x}_{i}^{j}, \operatorname{avg}_{i}^{j}\right) & x_{i}^{j}>\operatorname{avg}_{i}^{j}\end{cases} \tag{8} xij^=⎩ ⎨ ⎧rand(avgij,x^ij)rand(x^ij,avgij)xij⩽avgijxij>avgij(8)
其中: avg i j = b i j − a i j 2 ; ( a , b ) \operatorname{avg}_{i}^{j}=\frac{b_{i}^{j}-a_{i}^{j}}{2} ;(a, b) avgij=2bij−aij;(a,b) 代表在 a 、 b a 、 b a、b 之间的随机数。
随机产生的 N N N 个初始个体和准反向学习 [ 9 ] { }^{[9]} [9] 求得的 N N N 个准 反向解将其合并, 然后通过一种种群多样性最大化的篮选机 制, 从这 2 N 2 N 2N 个个体中选择种群多样性最大化的 N N N 个个体。
为了使种群获得比较好的初始化种群, 本文将随机解与其 对应的准反向解进行取优化处理, 这样既保证了种群的多样性, 同时又能使种群较快地收敛到全局最优解。其数学模型如下:
fit ( X ) > fit ( V ∨ ) ? X , X V (9) \text { fit }(X)>\text { fit }(\stackrel{\vee}{V}) ? X, \stackrel{V}{X} \tag{9} fit (X)> fit (V∨)?X,XV(9)
其中: fit 为适应度函数; X X X 和 X X X 分别表示随机产生的个体和准 反向学习产生的个体。
2.2 非线性收敛因子
与其他群体智能优化算法类似, 鲸鱼优化算法在寻优过程 中同样会遇到全局搜索能力和局部开发能力不平衡的现象。 在基本鲸鱼优化算法中, 其掌握鲸鱼进行全局搜索还是局部搜 索的是参数 ∣ A ∣ |A| ∣A∣, 当参数 ∣ A ∣ ⩾ 1 |A| \geqslant 1 ∣A∣⩾1 时, 算法以 0.5 0.5 0.5 的概率进行随 机全局搜索, 当 ∣ A ∣ < 1 |A|<1 ∣A∣<1 时, 算法进行局部开发。由于收玫因子 a a a 进行线性变化并不能很好地调节全局搜索能力和局部开发 能力, 因此本文提出来一种非线性收敛因子 [ 5 , 11 , 12 ] { }^{[5,11,12]} [5,11,12] 为
a = 2 − 2 sin ( μ t m a x i t e r π + φ ) (10) a=2-2 \sin \left(\mu \frac{t}{{ max_iter }} \pi+\varphi\right) \tag{10} a=2−2sin(μmaxitertπ+φ)(10)
其中: max_iter 为最大迭代次数; t t t 为当前迭代次数; μ \mu μ 和 φ \varphi φ 是其 表达式相关参数, 选取 μ = 1 2 , φ = 0 \mu=\frac{1}{2}, \varphi=0 μ=21,φ=0 。
2.3 自适应权重策略与随机差分法变异策略
鲸鱼优化算法在后期局部开发时易陷入局部最优, 出现早 熟收敛的现象, 为了使算法能够保持种群的多样性并且能够及 时跳出局部最优, 提出来一种自适应权重策略和随机差分变异策略
自适应权重策略数学表达式如下:
ω = 1 − e t max iter − 1 e − 1 , X ( t + 1 ) = ω ⋅ X p ( t ) − A ⋅ D (11) \omega=1-\frac{e^{\frac{t}{\max \text { iter }}-1}}{e-1}, \boldsymbol{X}(t+1)=\omega \cdot \boldsymbol{X}_{p}(t)-\boldsymbol{A} \cdot \boldsymbol{D} \tag{11} ω=1−e−1emax iter t−1,X(t+1)=ω⋅Xp(t)−A⋅D(11)
X ( t + 1 ) = ω ⋅ X p ( t ) + D ⋅ e b l ⋅ cos ( 2 π l ) (12) \boldsymbol{X}(t+1)=\omega \cdot \boldsymbol{X}_{p}(t)+\boldsymbol{D} \cdot e^{b l} \cdot \cos (2 \pi l) \tag{12} X(t+1)=ω⋅Xp(t)+D⋅ebl⋅cos(2πl)(12)
随机差分变异策略如下:
X ( t + 1 ) = r 1 × ( X p ( t ) − X ( t ) ) + r 2 × ( X ′ ( t ) − X ( t ) ) (13) \boldsymbol{X}(t+1)=r_{1} \times\left(\boldsymbol{X}_{p}(t)-\boldsymbol{X}(t)\right)+r_{2} \times\left(\boldsymbol{X}^{\prime}(t)-\boldsymbol{X}(t)\right) \tag{13} X(t+1)=r1×(Xp(t)−X(t))+r2×(X′(t)−X(t))(13)
其中: r 1 r_{1} r1 和 r 2 r_{2} r2 为 [ 0 , 1 ] [0,1] [0,1] 的随机数, X ′ ( t ) X^{\prime}(t) X′(t) 为种群中随机选取的个体。
每个个体都要经过包围捕食、螺旋更新、搜索猎物阶段, 当 个体进行包围捕食或螺旋更新时采用自适应权重策略去更新位置,之后个体需要通过随机差分变异策略对其再次更新,取其变化前后的最优位置,加快了种群的收敛,有效地防止了种群陷入局部最优。种群通过这两种策略协同工作,使得算法具有更好的寻优效果。
3.实验结果

4.参考文献
[1]武泽权,牟永敏.一种改进的鲸鱼优化算法[J].计算机应用研究,2020,37(12):3618-3621.