DeepLearning:训练神经网络—学习率及BatchSize
训练神经网络—学习率及batchSize
文章目录
- 训练神经网络—学习率及batchSize
-
- 1、学习率(Learning Rate)
-
- 定义
- 调整策略
-
- 人工调整策略
- 策略调整学习率
-
- 固定学习率衰减
-
- 分段减缓
- 分数减缓
- 指数减缓
- 余弦周期减缓
- 自适应学习率衰减
- Pytorch实现
-
- 1.lr_scheduler.StepLR
- 2.lr_scheduler.MultiStepLR
- 3.lr_scheduler.ExponentialLR
- 4.lr_scheduler.CosineAnnealingLR
- 5.lr_scheduler.ReduceLROnPlateau
- 6.lr_scheduler.LambdaLR
- 2、BatchSize
-
- BatchSize选择
- 学习率和BatchSize的关系
本文参考:
炼丹手册——学习率设置、
【AI不惑境】学习率和batchsize如何影响模型的性能?、
PyTorch 学习笔记(八):PyTorch的六个学习率调整方法
1、学习率(Learning Rate)
定义
学习率是梯度下降公式中的超参数,代表了在训练神经网络时,随时间推移,信息累积的速度。学习率是最影响性能的超参数之一,选择最优学习率是很重要的,因为它决定了神经网络是否可以收敛到全局最小值,不同学习率对比如下图:
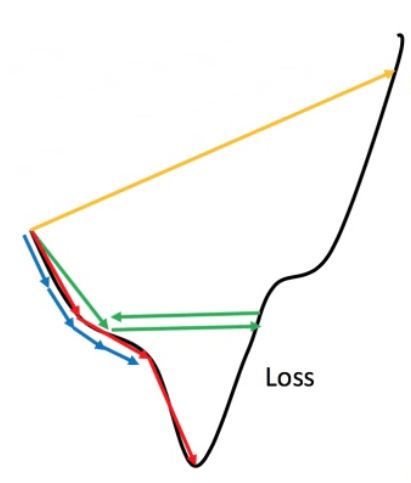
从上面两个图中我们可以看出:
- 蓝线:若学习率设置的过小,训练收敛较慢,此时需要更多的epoch才能到达一个较好的局部最小值。
- 绿线:若学习率设置的较大,训练可能会在接近局部最优点附近震荡,无法达到局部最优点。
- 黄线:若学习率设置的特别大,那么会在山间“跳跃”难以下山。
- 红线:合适的学习率。
调整策略
在实际中我们可以在开始时大跨步下山,后期使用小学习率来精耕细作,我们可以在训练初期采用大学习率,后期采用小学习率。想要达到这个目的有两种策略:人工调整或策略调整。
人工调整策略
一般是根据我们的经验值来调整,通过实践我也发现,在整个神经网络的训练过程种学习率不可能一直是同一个固定的值,初期我会将学习率设置为0.1或0.01以观察训练阶段的train_loss,具体遵循以下准则:
①如果开始时train_loss出现梯度爆炸,说明初始学习率偏大,这样就缩小学习率,再次运行。
②如果开始时train_loss下降缓慢,说明初始学习率偏小,我们可以扩大学习率,再次运行。
③在训练过程中如果发现train_loss下降缓慢或者出现震荡现象,可能进入了局部最小值点或者鞍点附近。若为局部最小值附近,需要降低学习率,精耕细作。如果处于鞍点附近,需要适当增加学习率跳出鞍点。
策略调整学习率
策略调整学习率包括固定策略的学习衰减和自适应学习率衰减。由于学习率的变化,在相似训练数据下训练参数更新速度也会放慢,相当于减小了训练数据对模型训练结果的影响,编程中,我们通常是以epoch为单位衰减学习率。
固定学习率衰减
分段减缓
指定每N轮学习率发生变化(如减半)或者在不同训练阶段设置不同的学习率,便于精细的调参。
分数减缓
将学习率随着epoch的轮数以分数的形式进行衰减,具体公式如下:
α = 1 ( 1 + d e c a y _ r a t e ∗ e p o c h ) ∗ l r \alpha =\frac{1}{\left( 1+decay\_\mathrm{rate}*epoch \right)}*lr α=(1+decay_rate∗epoch)1∗lr
指数减缓
将学习率随着epoch的轮数以指数的形式进行减缓,具体公式如下:
α = g a m m a e p o c h ∗ l r \alpha =gamma^{epoch}*lr α=gammaepoch∗lr
其中gamma代表的是指数的底(通常会设置为接近于1的数值,如0.95。
余弦周期减缓
也称余弦退火学习率,不同于传统的学习率,随着epoch的增加,学习率先急速下降,在快速上升,不断重复这个过程,这样就能有极大概率跳出局部最优点。
与前三种方法不同,余弦退火学习率由于急速下降,所以模型会迅速踏入局部最优点,然后恢复到一个较大值,逃离当前的局部最优点并寻找新的最优点。
自适应学习率衰减
AdaGrad、 RMSprop、 AdaDelta等optimizers,具体讲解:DeepLearning:训练神经网络—梯度下降优化器(optimizers)
Pytorch实现
1.lr_scheduler.StepLR
class torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
功能: 等间隔调整学习率,调整倍数为gamma倍,调整间隔为step_size。间隔单位是step。需要注意的是,step通常是指epoch,不要弄成iteration了。
参数:
step_size(int): 学习率下降间隔数,若为30,则会在30、60、90…个step时,将学习率调整为lr*gamma。
gamma(float): 学习率调整倍数,默认为0.1倍,即下降10倍。
last_epoch(int):上一个epoch数,这个变量用来指示学习率是否需要调整。当last_epoch符合设定的间隔时,就会对学习率进行调整。当为-1时,学习率设置为初始值。
2.lr_scheduler.MultiStepLR
class torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)
功能: 按设定的间隔调整学习率。这个方法适合后期调试使用,观察loss曲线,为每个实验定制学习率调整时机。
参数:
milestones(list):一个list,每一个元素代表何时调整学习率,list元素必须是递增的。如 milestones=[30,80,120]
3.lr_scheduler.ExponentialLR
class torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1)
功能: 按指数衰减调整学习率,调整公式: lr = lr * gamma**epoch
参数:
gamma: 学习率调整倍数的底,指数为epoch,即 gamma**epoch
4.lr_scheduler.CosineAnnealingLR
class torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1)
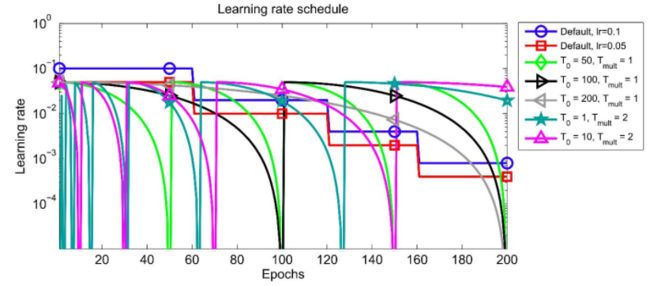
功能: 以余弦函数为周期,并在每个周期最大值时重新设置学习率。具体如下图所示:
参数:
T_max(int):一次学习率周期的迭代次数,即T_max个epoch之后重新设置学习率。
eta_min(float):最小学习率,即在一个周期中,学习率最小会下降到eta_min,默认值为0。
学习率调整公式为:
η t = η min + 1 2 ( η max − η min ) ( 1 + cos ( T c u r T max π ) ) \eta _t=\eta _{\min}+\frac{1}{2}\left( \eta _{\max}-\eta _{\min} \right) \left( 1+\cos \left( \frac{T_{cur}}{T_{\max}}\pi \right) \right) ηt=ηmin+21(ηmax−ηmin)(1+cos(TmaxTcurπ))
可以看出是以初始学习率为最大学习率,以2*Tmax为周期,在一个周期内先下降,后上升。
5.lr_scheduler.ReduceLROnPlateau
class torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)
功能: 当某指标不再变化(下降或升高),调整学习率,这是非常实用的学习率调整策略。例如,当验证集的loss不再下降时,进行学习率调整;或者监测验证集的accuracy,当accuracy不再上升时,则调整学习率。
参数:
mode(str):模式选择,有 min和max两种模式,min表示当指标不再降低(如监测loss),max表示当指标不再升高(如监测accuracy)。
factor(float):学习率调整倍数(等同于其它方法的gamma),即学习率更新为 lr = lr * factor patience(int)- 直译——“耐心”,即忍受该指标多少个step不变化,当忍无可忍时,调整学习率。注,可以不是连续5次。
verbose(bool): 是否打印学习率信息, print(‘Epoch {:5d}: reducing learning rate’ ’ of group {} to {:.4e}.’.format(epoch, i, new_lr))
threshold(float): Threshold for measuring the new optimum,配合threshold_mode使用,默认值1e-4。作用是用来控制当前指标与best指标的差异。
threshold_mode(str): 选择判断指标是否达最优的模式,有两种模式,rel和abs。 当threshold_mode = rel,并且mode = max时,dynamic_threshold = best * ( 1 + threshold ); 当threshold_mode = rel,并且mode = min时,dynamic_threshold = best * ( 1 - threshold ); 当threshold_mode = abs,并且mode = max时,dynamic_threshold = best + threshold ; 当threshold_mode = rel,并且mode = max时,dynamic_threshold = best - threshold
cooldown(int):“冷却时间“,当调整学习率之后,让学习率调整策略冷静一下,让模型再训练一段时间,再重启监测模式。
min_lr(float or list):学习率下限,可为float,或者list,当有多个参数组时,可用list进行设置。
eps(float):学习率衰减的最小值,当学习率变化小于eps时,则不调整学习率。
6.lr_scheduler.LambdaLR
class torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)
功能: 为不同参数组设定不同学习率调整策略。调整规则为,lr = base_lr * lmbda(self.last_epoch) 。
参数:
lr_lambda(function or list): 一个计算学习率调整倍数的函数,输入通常为step,当有多个参数组时,设为list。
last_epoch(int):上一个epoch数,这个变量用来指示学习率是否需要调整。当last_epoch符合设定的间隔时,就会对学习率进行调整。当为-1时,学习率设置为初始值。
2、BatchSize
当训练结束后,如果我们想进一步的提升模型性能,batchsize就会成为一个十分重要的参数。
BatchSize选择
大BatchSize的优点:减少训练时间,提高稳定性
在相同的epoch里,增加batchsize的值就会减少batch的数目,就可以减少训练时间,此外,大的batch_size梯度计算更加稳定,模型训练曲线会更加平滑,在微调的时候,大的batch_size会有更好的结果。
大BatchSize的缺点:模型泛化能力下降
大的batchsize性能下降是因为训练时间不够长,本质上并不是batchsize的问题,在同样的epochs下的参数更新变少了,因此需要更长的迭代次数。
学习率和BatchSize的关系
通常当我们增加batchsize为原来的N倍时,要保证经过同样的样本后更新的权重相等,按照线性缩放规则,学习率应该增加为原来的N倍。但是如果要保证权重的方差不变,则学习率应该增加为原来的sqrt(N)倍,目前这两种策略都被研究过,使用前者的明显居多。
其他结论:
-
衰减学习率可以通过增加batchsize来实现类似的效果
-
对于一个固定的学习率,存在一个最优的batchsize能够最大化测试精度
建议:
- 如果增加了学习率,那么batch size最好也跟着增加,这样收敛更稳定。
- 尽量使用大的学习率,因为很多研究都表明更大的学习率有利于提高泛化能力。 如果真的要衰减,可以尝试其他办法,比如增加batch size,学习率对模型的收敛影响真的很大,慎重调整。
似的效果**
- 对于一个固定的学习率,存在一个最优的batchsize能够最大化测试精度
建议:
- 如果增加了学习率,那么batch size最好也跟着增加,这样收敛更稳定。
- 尽量使用大的学习率,因为很多研究都表明更大的学习率有利于提高泛化能力。 如果真的要衰减,可以尝试其他办法,比如增加batch size,学习率对模型的收敛影响真的很大,慎重调整。